2022-01-25 更新:博客新地址:https://www.itbob.cn/,文章距上次编辑时间较远,部分内容可能已经过时!
文章目录
- ● 写在前面(必看)
- ● 查看网站是否被收录
- ● 百度资源平台添加网站
- ● 提交百度搜索
- ● 主动推送
- ● 自动推送
- ● sitemap
- ● 手动提交
- ● 提交谷歌搜索
● 写在前面(必看)
网站在没有提交搜索引擎收录之前,直接搜索你网站的内容是搜不到的,只有提交搜索引擎之后,搜索引擎才能收录你的站点,通过爬虫抓取你网站的东西,对于 hexo 博客来说,如果你是部署在 GitHub Pages,那么你是无法被百度收录的,因为 GitHub 禁止了百度爬虫,最常见的解决办法是双线部署到 Coding Pages 和 GitHub Pages,因为百度爬虫可以爬取到 Coding 上的内容,从而实现百度收录,如果你的 hexo 博客还没有实现双线部署,请参考:《Hexo 双线部署到 Coding Pages 和 GitHub Pages 并实现全站 HPPTS》,另外百度收录的所需的时间较长,大约半个月左右才会看到效果!
● 查看网站是否被收录
首先我们可以输入 site:域名 来查看域名是否被搜索引擎收录,如下图所示,表示没有收录:

● 百度资源平台添加网站
访问百度搜索资源平台官网,注册或者登陆百度账号,依次选择【用户中心】-【站点管理】,添加你的网站,在添加站点时会让你选择协议头(http 或者 https),如果选择 https,它会验证你的站点,大约能在一天之内完成,我的网站已经实现了全站 https,因此选择了 https 协议,但是不知道为什么始终验证失败,实在是无解,只能选择 http 协议了,如果你的站点也实现了全站 https,也可以尝试一下

之后会让你验证网站所有权,提供三种验证方式:
- 文件验证:下载给定的文件,将其放到本地主题目录 source 文件夹,然后部署上去完成验证
- HTML 标签验证:一般是给一个 meta 标签,放到首页 <head> 与 </head> 标签之间即可完成验证
- CNAME 验证:个人觉得这种方法最简单,去域名 DNS 添加一个 CNAME 记录即可完成验证


● 提交百度搜索
百度提供了自动提交和手动提交两种方式,其中自动提交又分为主动推送、自动推送和 sitemap 三种方式,以下是官方给出的解释:
-
主动推送:最为快速的提交方式,推荐您将站点当天新产出链接立即通过此方式推送给百度,以保证新链接可以及时被百度收录
-
自动推送:是轻量级链接提交组件,将自动推送的 JS 代码放置在站点每一个页面源代码中,当页面被访问时,页面链接会自动推送给百度,有利于新页面更快被百度发现
-
sitemap:您可以定期将网站链接放到sitemap中,然后将sitemap提交给百度。百度会周期性的抓取检查您提交的sitemap,对其中的链接进行处理,但收录速度慢于主动推送
-
手动提交:如果您不想通过程序提交,那么可以采用此种方式,手动将链接提交给百度
四种提交方式对比:
| 方式 | 主动推送 | 自动推送 | Sitemap | 手动提交 |
|---|---|---|---|---|
| 速度 | 最快 | —— | —— | —— |
| 开发成本 | 高 | 低 | 中 | 不需开发 |
| 可提交量 | 低 | 高 | 高 | 低 |
| 是否建议提交历史连接 | 否 | 是 | 是 | 是 |
| 和其他提交方法是否有冲突 | 无 | 无 | 无 | 无 |
个人推荐同时使用主动推送和 sitemap 方式,下面将逐一介绍这四种提交方式的具体实现方法
● 主动推送
在博客根目录安装插件 npm install hexo-baidu-url-submit --save,然后在根目录 _config.yml 文件里写入以下配置:
baidu_url_submit:count: 1 # 提交最新的多少个链接host: www.itrhx.com # 在百度站长平台中添加的域名token: your_token # 秘钥path: baidu_urls.txt # 文本文档的地址, 新链接会保存在此文本文档里
其中的 token 可以在【链接提交】-【自动提交】-【主动推送】下面看到,接口调用地址最后面 token=xxxxx 即为你的 token

同样是在根目录的 _config.yml 文件,大约第 17 行处,url 要改为在百度站长平台添加的域名,也就是你网站的首页地址:
# URL
url: https://www.itrhx.com
root: /
permalink: :year/:month/:day/:title/
最后,加入新的 deployer:
# Deployment
## Docs: https://hexo.io/docs/deployment.html
deploy:
- type: gitrepository:github: git@github.com:TRHX/TRHX.github.io.git # 这是原来的 github 配置coding: git@git.dev.tencent.com:TRHX/TRHX.git # 这是原来的 coding 配置branch: master
- type: baidu_url_submitter # 这是新加的主动推送
最后执行 hexo g -d 部署一遍即可实现主动推送,推送成功的标志是:在执行部署命令最后会显示类似如下代码:
{"remain":4999953,"success":47}
INFO Deploy done: baidu_url_submitter
这表示有 47 个页面已经主动推送成功,remain 的意思是当天剩余的可推送 url 条数
主动推送相关原理介绍:
- 新链接的产生:hexo generate 会产生一个文本文件,里面包含最新的链接
- 新链接的提交:hexo deploy 会从上述文件中读取链接,提交至百度搜索引擎
该插件的 GitHub 地址:https://github.com/huiwang/hexo-baidu-url-submit
● 自动推送
关于自动推送百度官网给出的解释是:自动推送是百度搜索资源平台为提高站点新增网页发现速度推出的工具,安装自动推送JS代码的网页,在页面被访问时,页面URL将立即被推送给百度

此时要注意,有些 hexo 主题集成了这项功能,比如 next 主题,在 themes\next\layout_scripts\ 下有个 baidu_push.swig 文件,我们只需要把如下代码粘贴到该文件,然后在主题配置文件设置 baidu_push: true 即可
{% if theme.baidu_push %}
<script>
(function(){var bp = document.createElement('script');var curProtocol = window.location.protocol.split(':')[0];if (curProtocol === 'https') {bp.src = 'https://zz.bdstatic.com/linksubmit/push.js'; }else {bp.src = 'http://push.zhanzhang.baidu.com/push.js';}var s = document.getElementsByTagName("script")[0];s.parentNode.insertBefore(bp, s);
})();
</script>
{% endif %}
然而大部分主题是没有集成这项功能的,对于大部分主题来说,我们可以把以下代码粘贴到 head.ejs 文件的 <head> 与 </head> 标签之间即可,从而实现自动推送(比如我使用的是 Material X 主题,那么只需要把代码粘贴到 \themes\material-x\layout\_partial\head.ejs 中即可)
<script>
(function(){var bp = document.createElement('script');var curProtocol = window.location.protocol.split(':')[0];if (curProtocol === 'https') {bp.src = 'https://zz.bdstatic.com/linksubmit/push.js';}else {bp.src = 'http://push.zhanzhang.baidu.com/push.js';}var s = document.getElementsByTagName("script")[0];s.parentNode.insertBefore(bp, s);
})();
</script>
● sitemap
首先我们要使用以下命令生成一个网站地图:
npm install hexo-generator-sitemap --save
npm install hexo-generator-baidu-sitemap --save
这里也注意一下,将根目录的 _config.yml 文件,大约第 17 行处,url 改为在百度站长平台添加的域名,也就是你网站的首页地址:
# URL
url: https://www.itrhx.com
root: /
permalink: :year/:month/:day/:title/
然后使用命令 hexo g -d 将网站部署上去,然后访问 你的首页/sitemap.xml 或者 你的首页/baidusitemap.xml 就可以看到网站地图了
比如我的是:https://www.itrhx.com/baidusitemap.xml 或者 https://www.itrhx.com/sitemap.xml
其中 sitemap.xml 文件是搜索引擎通用的 sitemap 文件,baidusitemap.xml 是百度专用的 sitemap 文件
然后来到百度站长平台的 sitemap 提交页面,将你的 sitemap 地址提交即可,如果成功的话状态会显示为正常,初次提交要等几分钟,sitemap.xml 相比 baidusitemap.xml 来说等待时间也会更长,如果以后你博客有新的文章或其他页面,可以点击手动更新文件,更新一下新的 sitemap

● 手动提交
手动提交不需要其他额外操作,直接把需要收录的页面的 url 提交即可,这种方法效率较低,更新较慢,不推荐使用

● 提交谷歌搜索
提交谷歌搜索引擎比较简单,在提交之前,我们依然可以使用 site:域名 查看网站是否被收录,我的网站搭建了有差不多一年了,之前也没提交过收录,不过谷歌爬虫的确是强大,即使没有提交过,现在也能看到有一百多条结果了:

接下来我们将网站提交谷歌搜索引擎搜索,进入谷歌站长平台,登录你的谷歌账号之后会让你验证网站所有权:
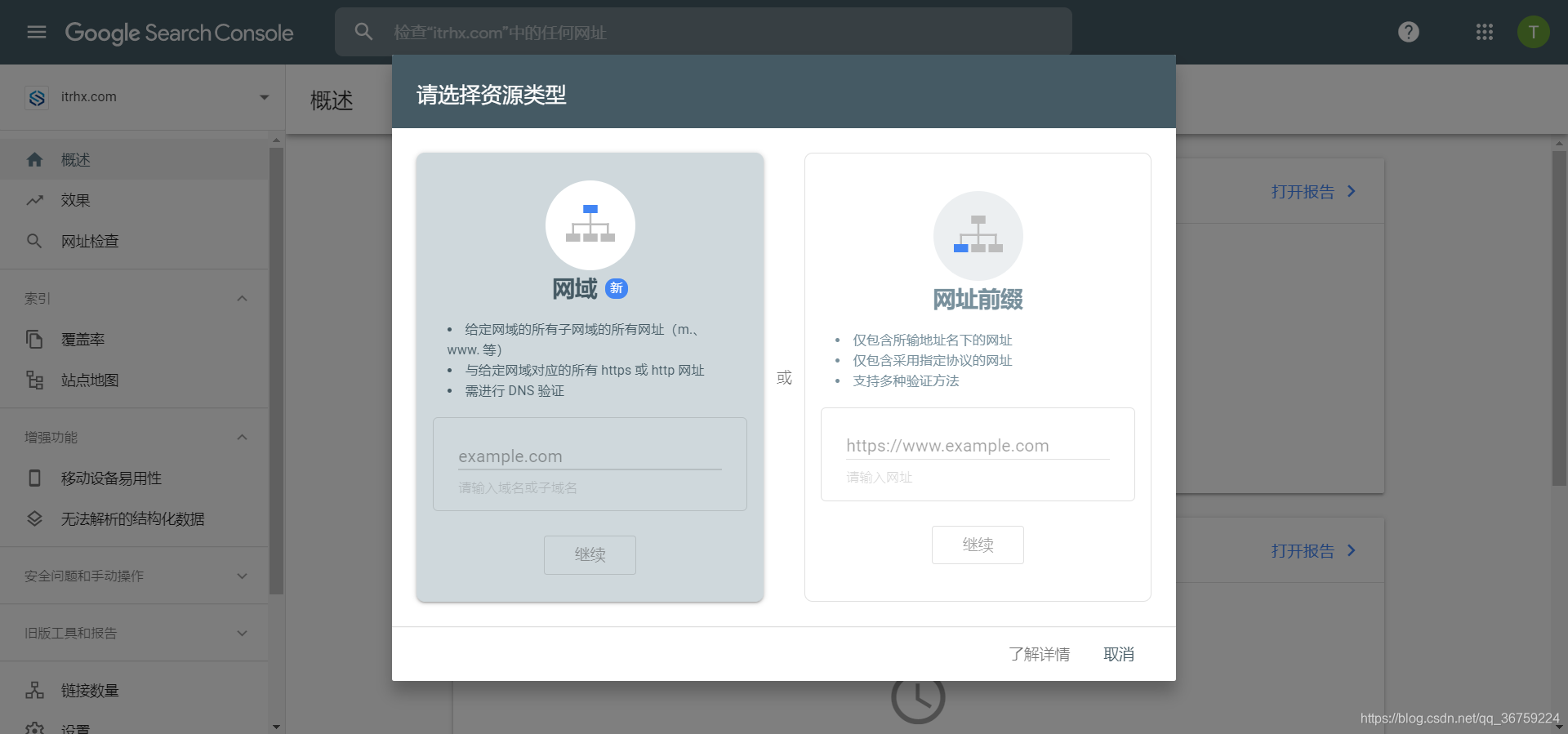
有两种验证方式,分别是网域和网址前缀,两种资源类型区别如下:
| 说明 | 仅包含具有指定前缀(包括协议 http/https)的网址。如果希望资源匹配任何协议或子网域(http/https/www./m. 等),建议改为添加网域资源。 | 包括所有子网域(m、www 等)和多种协议(http、https、ftp)的网域级资源。 |
| 验证 | 多种类型 | 仅 DNS 记录验证 |
| 示例 | 资源 http://example.com/ ✔ http://example.com/dresses/1234 X https://example.com/dresses/1234 X http://www.example.com/dresses/1234 | 资源 example.com ✔ http://example.com/dresses/1234 ✔ https://example.com/dresses/1234 ✔ http://www.example.com/dresses/1234 ✔ http://support.m.example.com/dresses/1234 |
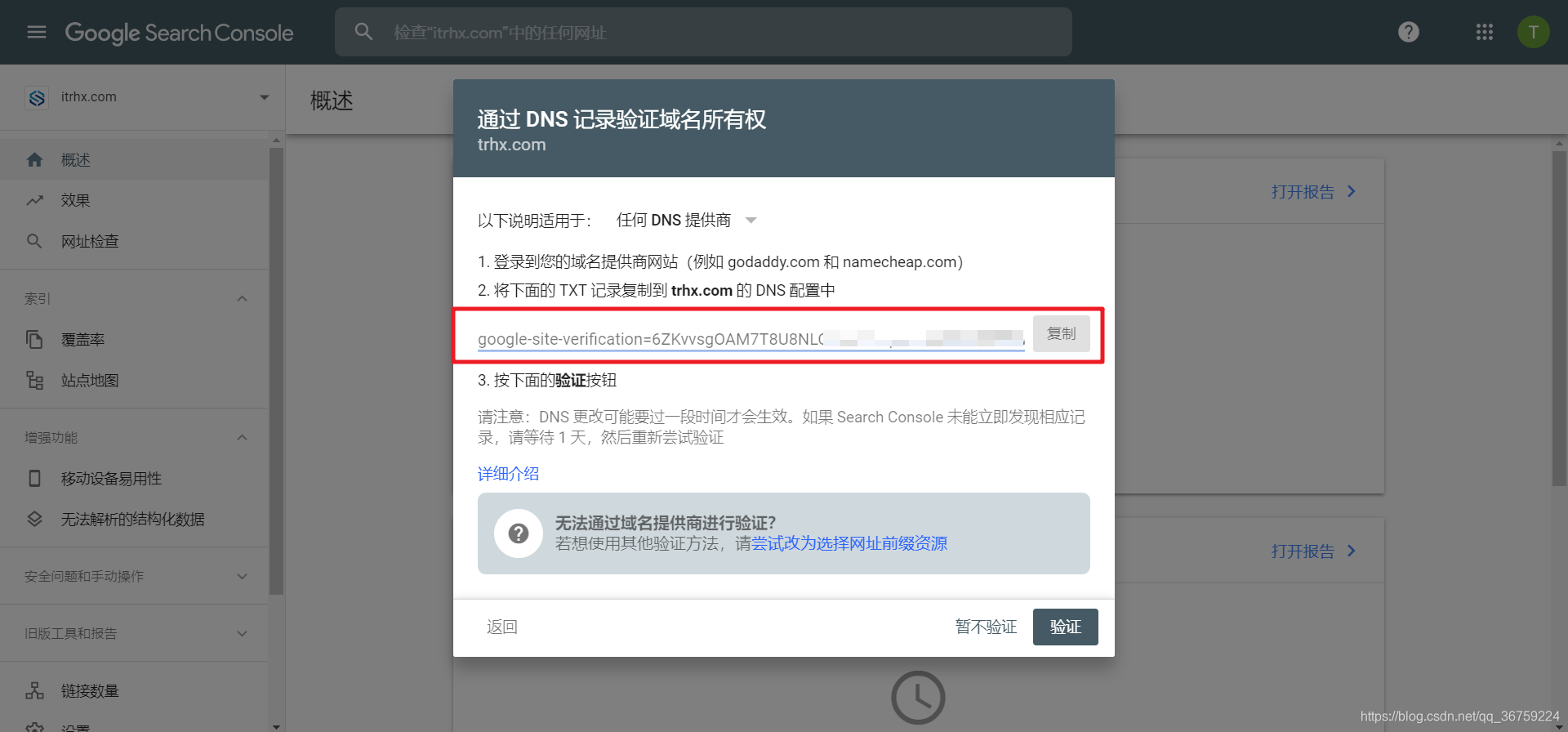
由对比可知选择网域资源验证方式比较好,只需要一个域名就可以匹配到多种格式的 URL,之后会给你一个 TXT 的记录值,复制它到你域名 DNS 增加一个 TXT 记录,点击验证即可
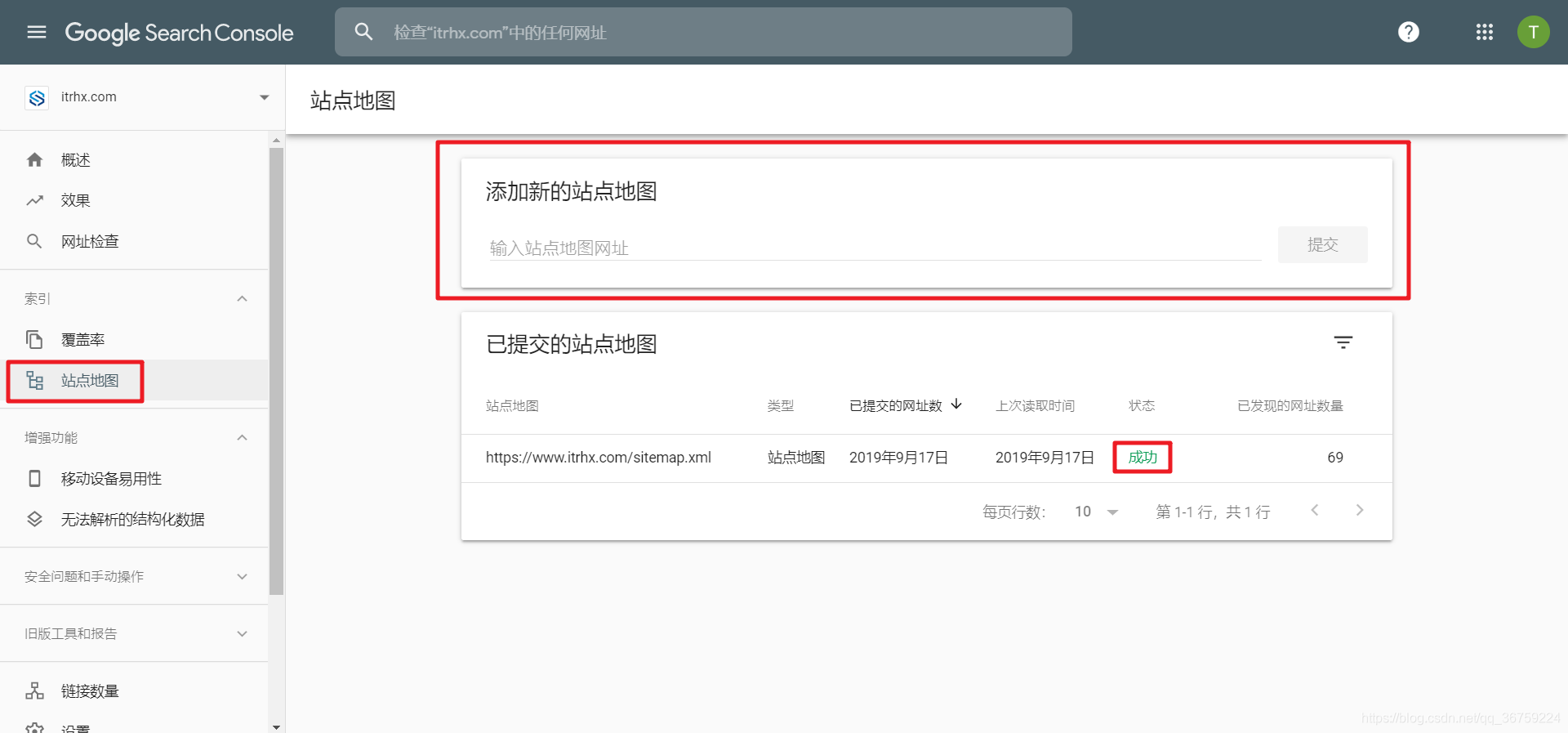
提交谷歌收录比较简单,选择站点地图,将我们之前生成的 sitemap 提交就行了,过几分钟刷新一下看到成功字样表示提交成功!








)

)





)

)
