文章连接
Flash flood susceptibility modeling using an optimized fuzzy rule based feature selection technique and tree based ensemble methods - ScienceDirect
解决问题
在洪水评估过程中,主要需要成功解决三个方面的问题。
首先,需要提供总体框架,在该框架内对洪水现象演变背后的机制形成合理的解释;
其次,找到最佳变量集;
第三,估计它们的影响。
模型分类
经验模型是基于数据和数学公式的面向观察的模型。它们可以被认为是黑盒模型,例如基于人工神经网络的模型,它们没有充分考虑水文系统的特征和过程,然而这样的模型生成具有高预测能力的模型
经验模型主要基于定性或定量技术;前者依赖于专家知识,后者依赖于分析数据识别独立的洪水相关变量和洪水之间的关系。层次分析法和模糊逻辑是洪水敏感性评估中常用的主要定性技术统计和概率方法,例如频率定量 (FR) ,权重-证据(WOE)和逻辑回归(LR)被广泛用作定量方法
概念模型使用半经验方程模型的参数不仅通过现场数据进行评估,还通过校准过程进行评估,概念模型简单、易于实施,但需要大量的水文和气象数据。
基于物理的模型,使用有限差分方程模拟水运动的水文过程,需要大量的水文和气象数据进行校准以及评估描述集水区物理特征的参数
为什么要选定机器学习进行建模
由于流域的非线性和动态结构难以评估和建模,洪水现象涉及复杂的过程,因此非线性机器学习算法具有已被提议用于洪水建模
最近,已经引入了几种基于结合各种基分类器的模型进行预测的混合和集成方法,作为洪水评估的替代工具。混合和集成方法能够提高预测性能并以更稳健的方式处理复杂的高维问题
混合方法的特征示例是使用基于自适应网络模糊推理系统 (ANFIS) 的模型以及进化和元启发式优化算法,例如遗传算法(GA) ,粒子群优化(PSO),基于生物地理学的优化(BBO),蝙蝠算法(BA),蚁群优化( ACO) 和萤火虫算法 (FA)
最优变量集
特征选择方法(FSM)是最常用的方法。FSM 可以帮助排除与低预测能力无关的变量,从而降低模型的复杂性并生成更简单的模型。一种常见的 FSM,称为包装器方法,是应用学习算法并评估算法在具有不同变量子集的数据集上的预测性能
该论文的新颖之处
本研究的新颖性以及与先前研究的主要区别在于洪水敏感性评估中的 FSM 是基于模糊规则的学习分类器和基于种群的进化算法的使用。新颖的 FSM 与洪水敏感性评估中使用的其他 FSM 方法不同,因为它可以提供更灵活的分类边界并允许分类基于整套规则。
模糊无序规则归纳算法 (FURIA) 被用作属性评估器 ,而为了缩小搜索解决方案的空间,还考虑使用强大且稳健的搜索技术,GA 被用作更合适的全局搜索方法
开发一种新的山洪敏感性建模方法
用遗传算法优化模糊规则特征选择技术
FURIA-GA 特征选择技术产生了一个高度预测的变量子集。
基于树的集合模型在山洪敏感性建模中表现良好。
与集成模型相比,基于 FURIA-GA 的集成模型具有更高的准确性
建模步骤
第一阶段
涉及数据选择和分类程序、山洪清单图的构建和非洪水区的识别。
最终数据库包含 654 个洪水点和 654 个非洪水点。
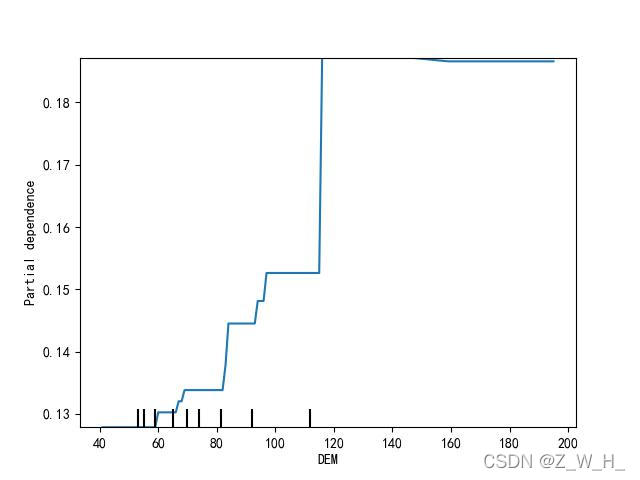
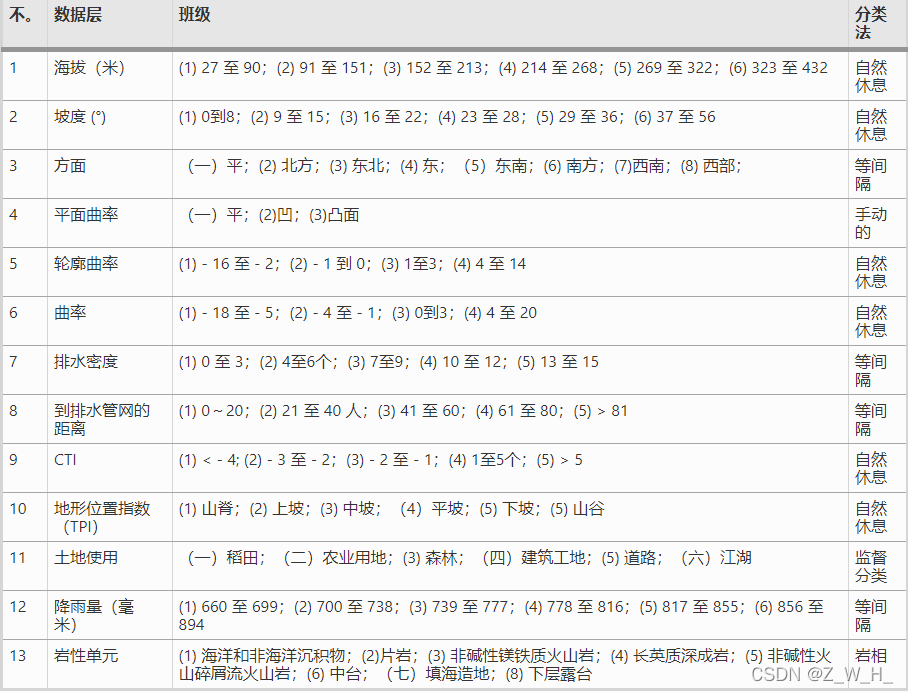
分析了12个洪水相关变量,即:海拔(8)、坡度(10)、坡向(9)、曲率(7)、地形湿度指数(TWI)(7)、河流功率指数(SPI)(7)、地形阴影(9)、河流密度(7)、降雨量(6)、归一化植被指数(NDVI)(8)、土壤类型覆盖度和岩性覆盖层,每个与山洪相关的变量主要取决于专家知识和遵循山洪评估中类似研究提供的指导方针
海拔和坡度对洪水的发生有显着影响,坡度越陡,水流越快,而平坦的低地更容易发生洪水。
坡向,因为它会影响一个地区的水文条件
曲率 显着影响一个地区的地表径流和入渗能力
TWI 和 SPI 是 DEM 的二次导数,可以被视为描述一个地区的水文环境的变量,因为高 TWI 值表示易受饱和地表影响的地区和可能产生地表溢流的地区,而 SPI 代表侵蚀方面的水流
Toposhade 对应于可能影响水流收敛的山坡的阴影和长度
流域的河流密度对洪水的范围和强度有显着影响,因为河网和河流周边地区极易发生洪水事件
NDVI 是描述一个地区的植被特征的量度,这些特征会影响一个地区的地表径流和入渗能力,植被较少的地区被认为更容易发生洪水关于 NDVI 变量的使用及其在非雨季的估计,我们承认有两个原因。第一个原因与需要捕获干燥环境中的植被覆盖率有关,这可以作为有关受植被存在与否影响的下游水运动强度的信息来源。这可以确定最易受洪水影响的区域。第二个原因与避免雨季可能出现的云层影响有关
岩性覆盖被认为是一个重要的山洪相关变量,因为它极大地影响了土地渗透率和地表径流等水文和水文地质条件
第二阶段
包括实施频率定量法和洪水相关因素的归一化程序、多重共线性分析以及训练和验证数据集的构建。
第一阶段
使用频率比法来产生权重系数,频率定量法用于估计因变量和自变量之间的概率关系,并为每一类洪水相关变量分配权重系数值
第二阶段
对洪水相关因素进行归一化过程,
第三阶段
执行多重共线性分析,
使用方差膨胀因子(VIF)和容差(TOL)指标估计山洪变量之间的相关性,VIF值大于10,值为TOL <0.1 表示严重的多重共线性
第四阶段
构建训练和验证数据集。7:3
第三阶段
涉及使用 FURIA 和GA实施新的特征选择,估计山洪变量的相对重要性,
模糊无序规则归纳算法(FURIA)用于基于FURIA实现的准确性评估属性子集,而遗传算法(GA)用作搜索方法。
第四阶段
包括实施三种集成方法,以及验证和比较它们的结果.








![[读书笔记]TCP/IP详解V1读书笔记-1](https://pic002.cnblogs.com/images/2011/318536/2011091823165431.jpg)