对Xpath 获取子标签下所有文本的方法详解
在爬虫中遇见这种怎么办

想提取名称, 但是 名称不在一个标签里
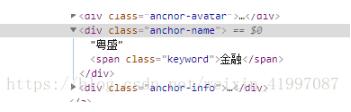
使用xpath string()方法
例如
data.xpath("string(path)")
path -- 你xpath提取的路径 这里提取到父标签
string() 方法会提取子标签多有的文本内容。
以上这篇对Xpath 获取子标签下所有文本的方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
时间: 2018-12-31

前言 本来打算写的标题是XPath语法,但是想了一下Python中的解析库lxml,使用的是Xpath语法,同样也是效率比较高的解析方法,所以就写成了XPath语法和lxml库的用法 XPath 即为 XML 路径语言,它是一种用来确定 XML(标准通用标记语言的子集)文档中某部分位置的语言. XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力. XPath 同样也支持HTML. XPath 是一门小型的查询语言. python 中 lxml库 使用的是 Xpath 语法,是
今天用xpath获取的元素下面text 是被几个b标签分割开的,我想要一次性全部获取,参考了其他人的博客是如下的做法: value_ls = html.xpath("//tr/td[7]") value = value_ls[0].xpath('string(.)').extract()[0] 但是因为我用的是 lxml, 系统报错,lxml元素没有extract() 这个方法,去掉这个方法后,可以正常使用.所以要根据自己的情况选择要不要用.extract() value_ls = h
python的xpath没有获取div标签内html内容的功能,也就是获取div或a标签中的innerhtml,写了个小程序实现一下: 源代码 [webadmin@centos7 csdnd4q] #162> vim /mywork/python/csdnd4q/z040.py #去掉最外层标签,保留其内的所有html标记和文本 def getinnerhtml(data): return data[data.find(">")+1:data.rfind("<
代码 使用方法见注释 #-*- coding: UTF-8 -*- from lxml import etree source = u'''
测试数据1
测试数据2
本文分享了js中利用tagname和id获取元素的3种方法,供大家参考,具体内容如下 方法一:整体法,先获取所有的元素,再通过ai+-b的方法来算出需要的元素 方法二:数组法,在全局环境下建立空数组,遇到需要循环的结构时,在循环中获取元素,并放入数组 方法三:函数法,遇到相同的几组元素时,只操作一组元素,并用函数传参来实现所有的效果 具体代码如下
如下所示: list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] slice = random.sample(list, 5) #从list中随机获取5个元素,作为一个片断返回 print slice print list #原有序列并没有改变. print random.randint(12, 20) #生成的随机数n: 12 <= n <= 20 print random.randint(20, 20) #结果永远是20 #print random.randint(
原生JS有3种方式来获取元素: getElementById('id') getElementsByName('name') getElementsByTagName('tag') getElementById是获取元素最快的方式,但我们不能给每个HTML元素都加以ID吧,所以我们需要一个很方便的通过className来获取元素 function getElementsByClassName(className,tagName){ var ele=[],all=document.getEleme
本文实例讲述了python实现判断数组是否包含指定元素的方法.分享给大家供大家参考.具体如下: python判断数组是否包含指定的元素的方法,直接使用in即可,python真是简单易懂 print 3 in [1, 2, 3] # membership (1 means true inventory = ["sword", "armor", "shield", "healing potion"] if "healin
常见的获取元素的方法有3种,分别是通过元素ID.通过标签名字和通过类名字来获取. getElementById DOM提供了一个名为getElementById的方法,这个方法将返回一个与之对应id属性的节点对象.使用的时候请注意区分大小写. 它是document对象特有的函数,只能通过其来调用该方法.其使用的方法如下: 复制代码 代码如下: document.getElementById('demo') //demo是元素对应的ID 该方法兼容主流浏览器,甚至包括IE6+,可以大胆使用. ge
在web开发中,经常会用到iframe,难免会碰到需要在父窗口中使用iframe中的元素.或者在iframe框架中使用父窗口的元素 js 在父窗口中获取iframe中的元素 1. 格式:window.frames["iframe的name值"].document.getElementById("iframe中控件的ID").click(); 实例:window.frames["ifm"].document.getElementById("
用关键字 in 和not in 来 如下: qwe =[1,2,3,4,5] if 2 in qwe: print 'good!' else: print 'not good' 666 以上这篇Python 查看list中是否含有某元素的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
python根据字典的键来删除元素的方法: 可以利用pop()方法来进行删除. pop()方法可以删除字典定键key及对应的值,并返回被删除的值. 具体使用方法如:[site.pop('name')]. Python 字典 pop() 方法删除字典给定键 key 及对应的值,返回值为被删除的值.key 值必须给出. 否则,返回 default 值. 语法: pop(key[,default]) 参数: key: 要删除的键值 default: 如果没有 key,返回 default 举例: #!
本文实例讲述了Python实现解析BitTorrent种子文件内容的方法.分享给大家供大家参考,具体如下: 有很多种子文件,有时候记不清里面都是什么东西,又不想一个一个的拖放到迅雷或BT软件里头看, 上网查了一下Python的脚本,自己也稍微修改了一下,代码如下,粘贴到文本编辑器中: 保存成py后缀的,直接运行 import re def tokenize(text, match=re.compile("([idel])|(/d+):|(-?/d+)").match): i = 0 w

:react之状态)




:react之状态二)


:react之状态三)




:react条件渲染实现登录)


:react条件渲染实现登录二)

