分类预测 | MATLAB实现CNN-BiGRU-Attention多输入单输出分类预测
目录
- 分类预测 | MATLAB实现CNN-BiGRU-Attention多输入单输出分类预测
- 预测效果
- 基本介绍
- 模型描述
- 程序设计
- 参考资料
预测效果







基本介绍
Matlab实现CNN-BiGRU-Attention多特征分类预测,卷积双向门控循环单元结合注意力机制分类预测。
1.data为数据集,格式为excel,12个输入特征,输出4类标签;
2.MainCNN_BiGRU_AttentionNC.m为主程序文件,运行即可;
3.可视化展示分类准确率,可在下载区获取数据和程序内容;
注意程序和数据放在一个文件夹,运行环境为Matlab2020b及以上。
模型描述
注意力机制模块:
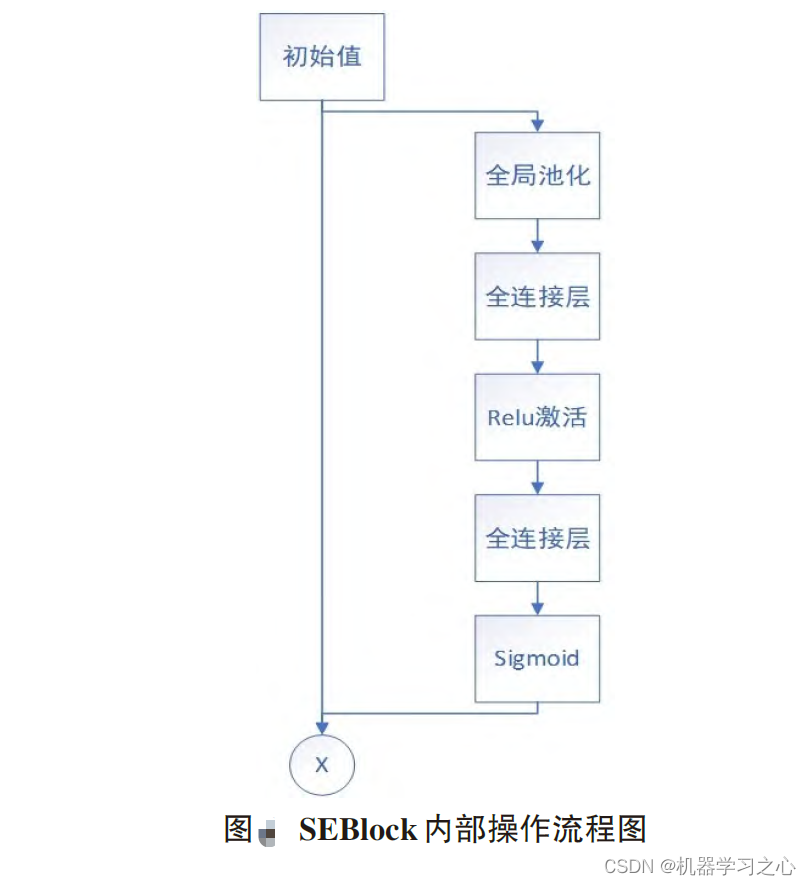
SEBlock(Squeeze-and-Excitation Block)是一种聚焦于通道维度而提出一种新的结构单元,为模型添加了通道注意力机制,该机制通过添加各个特征通道的重要程度的权重,针对不同的任务增强或者抑制对应的通道,以此来提取有用的特征。该模块的内部操作流程如图,总体分为三步:首先是Squeeze 压缩操作,对空间维度的特征进行压缩,保持特征通道数量不变。融合全局信息即全局池化,并将每个二维特征通道转换为实数。实数计算公式如公式所示。该实数由k个通道得到的特征之和除以空间维度的值而得,空间维数为H*W。其次是Excitation激励操作,它由两层全连接层和Sigmoid函数组成。如公式所示,s为激励操作的输出,σ为激活函数sigmoid,W2和W1分别是两个完全连接层的相应参数,δ是激活函数ReLU,对特征先降维再升维。最后是Reweight操作,对之前的输入特征进行逐通道加权,完成原始特征在各通道上的重新分配。
程序设计
- 完整程序和数据获取方式1:同等价值程序兑换;
- 完整程序和数据获取方式2:私信博主回复 CNN-BiGRU-Attention多输入分类预测获取。
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = double(reshape(p_train, f_, 1, 1, M));
p_test = double(reshape(p_test , f_, 1, 1, N));
t_train = double(t_train)';
t_test = double(t_test )';%% 数据格式转换
for i = 1 : MLp_train{i, 1} = p_train(:, :, 1, i);
endfor i = 1 : NLp_test{i, 1} = p_test( :, :, 1, i);
end%% 建立模型
lgraph = layerGraph(); % 建立空白网络结构tempLayers = [sequenceInputLayer([f_, 1, 1], "Name", "sequence") % 建立输入层,输入数据结构为[f_, 1, 1]sequenceFoldingLayer("Name", "seqfold")]; % 建立序列折叠层
lgraph = addLayers(lgraph, tempLayers); % 将上述网络结构加入空白结构中tempLayers = convolution2dLayer([3, 1], 32, "Name", "conv_1"); % 卷积层 卷积核[3, 1] 步长[1, 1] 通道数 32
lgraph = addLayers(lgraph,tempLayers); % 将上述网络结构加入空白结构中
%% 赋值
L2Regularization =abs(optVars(1)); % 正则化参数
InitialLearnRate=abs(optVars(2)); % 初始学习率
NumOfUnits = abs(round(optVars(3))); % 隐藏层节点数%% 输入和输出特征个数
inputSize = size(input_train, 1); %数据输入x的特征维度
numResponses = size(output_train, 1); %数据输出y的维度%% 设置网络结构
opt.layers = [ ...sequenceInputLayer(inputSize) %输入层,参数是输入特征维数%% 设置网络参数
opt.options = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 100, ... % 最大训练次数,推荐180'GradientThreshold', 1, ... %梯度阈值,防止梯度爆炸'ExecutionEnvironment','cpu',... %对于大型数据集合、长序列或大型网络,在 GPU 上进行预测计算通常比在 CPU 上快。其他情况下,在 CPU 上进行预测计算通常更快。'InitialLearnRate', InitialLearnRate, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod',120, ... % 训练80次后开始调整学习率'LearnRateDropFactor',0.2, ... % 指定初始学习率 0.005,在 100 轮训练后通过乘以因子 0.2 来降低学习率。'L2Regularization', L2Regularization, ... % 正则化参数'Verbose', 0, ... % 关闭优化过程'Plots', 'none'); % 不画出曲线
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129679476?spm=1001.2014.3001.5501
[2] https://blog.csdn.net/kjm13182345320/article/details/129659229?spm=1001.2014.3001.5501
[3] https://blog.csdn.net/kjm13182345320/article/details/129653829?spm=1001.2014.3001.5501







)






--某课网登录)
【Redis】)



