Python Protobuf
- 1.了解Protobuf:
- 1.1 Protobuf语法介绍:
- 2. Python使用Protobuf:(windows平台上)
1.了解Protobuf:
我们在使用protobuf之前首先要了解protobuf,那么什么是protobuf呢?
官方的解释是:
protocol buffers 是一种与语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于(数据)通信协议、数据存储等。
Protocol Buffers 是一种灵活,高效,自动化机制的结构数据序列化方法-可类比 XML,但是比 XML 更小(3 ~ 10倍)、更快(20 ~ 100倍)、更为简单。
你可以定义数据的结构,然后使用特殊生成的源代码轻松的在各种数据流中使用各种语言进行编写和读取结构数据。你甚至可以更新数据结构,而不破坏由旧数据结构编译的已部署程序。
简单的来说,ProtoBuf和json、xml一样是一种结构化的数据格式,用于数据通信的传输及数据的存储。但ProtoBuf相比json和xml来说具有以下的优点:
- 性能好,效率高:是一种二进制的数据格式,比xml小3-5倍,其速度是xml的20-100倍。
- 代码生成机制,数据解析类自动生成:提供了根据proto文件生成对应的源文件代码生成机制。windows(proto.exe)、linux平台动态编译生成
- 支持向后和向前兼容:兼容以前和以后的其他版本,更新数据结构,不影响破坏原有的旧程序。
- 支持多种编译语言:提供了C++、python、java多种语言的支持。
缺点:
- 其内部格式是二进制,导致数据可读性差。
1.1 Protobuf语法介绍:
在Protobuf中,.proto文件相当于确定数据协议,数据结构中存在哪些数据,数据类型是怎么样的。先来看一个简单的.proto文件的数据结构,然后再来详细了解一下protobuf语法
syntax = "proto3";message SearchRequest {string query = 1;int32 page_number = 2;int32 result_per_page = 3;
}
- 该文件的第一行指定您正在使用
proto3语法:如果您不这样做,protobuf 编译器将假定您正在使用proto2。这必须是文件的第一个非空的非注释行。 - 所述
SearchRequest消息定义了三个字段(名称/值对),每个字段都有一个名称和类型,及唯一的数字标识符。
protobuf2中.proto文件中的数据结构由以下几部分组成:
- 关键字message:代表实体结构,由多个消息字段(field)组成。
- 消息字段: 由数据类型、字段名、字段规则、字段唯一标识、默认值组成。
- 数据类型:
- 复合型数据类型:枚举、message类型
- 标准数据类型:整型、浮点、字符串等
- 字段规则:
- required:必须初始化字段,如果没有赋值,在数据序列化时会抛出异常
- optional:可选字段,可以不赋值。如果没有赋值,会使用默认值
- repeated:表示该字段可以重复任意次数,包括0次。重复数据的顺序将会保存在protocol buffer中。
- 字段唯一标识:每个字段都有唯一的数字标识符。用于标记该字段在序列化后的二进制数据中输在的field,每个字段的唯一数字标识符在message内部都是独一无二的。
- 默认值:在定义消息字段时可以给出默认值
Potobuf3与Protobuf2不同的地方:
1、字段规则:
- 字段前取消了required和optional两个关键字,目前只保留了repeated关键字。
- 修饰消息的字段修饰符必须是singular、或repeated。
- singular:一个格式良好的消息应该有0个或者1个这种字段(但是不能超过1个)。
- repeated:在一个格式良好的消息中,这种字段可以重复任意多次(包括0次)。重复的值的顺序会被保留。
2、取消了设置默认值:
- string默认为字符串
- bytes默认为空bytes
- bool默认为false
- 数字类型默认为0
- 枚举类型默认为第一个枚举定义的第一个值。且第一个值必须为0。
3、支持的数据类型有:
double、float、int32、int64、uint32、uint64、sint32、sint64、fixed32、fixed64、sfixed32、sfixed64、bool、string、bytes
4、分配标识符:
正如上述文件格式,在消息定义中,每个字段都有唯一的一个数字标识符。这些标识符是用来在消息的二进制格式中识别各个字段的,一旦开始使用就不能够再改变。
注意:[1,15]之内的标识号在编码的时候会占用一个字节。[16,2047]之内的标识号则占用2个字节。所以应该为那些频繁出现的消息元素保留 [1,15]之内的标识号。切记:要为将来有可能添加的、频繁出现的标识号预留一些标识号。
最小的标识号可以从1开始,最大到2^29 - 1, or 536,870,911。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报错。
2. Python使用Protobuf:(windows平台上)
1. 首先下载平台对应的proto编译器,根据平台下载对应版本:
https://github.com/google/protobuf/releases
windows平台可以下win64。
然后将压缩包解压,将压缩包中bin目录下的proto.exe文件放到项目目录下,用于将来编译.proto文件。
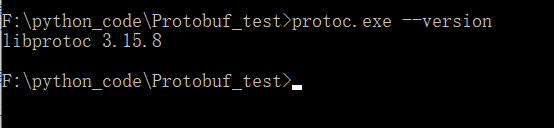
在该目录下执行:protoc.exe --version判断是否可用
然后执行:pip install protobuf 安装protobuf模块
2. 在项目目录下创建test.proto文件,定义数据结构
syntax = "proto3"; // 指定protobuf语法版本
package Protobuf_test; // 包名message AddressBook {repeated Person people = 1;
}message Person {string name = 1;int32 id = 2;string email = 3;float money = 4;bool work_status = 5;repeated PhoneNumber phones = 6;MyMessage maps = 7;}message PhoneNumber {string number = 1;PhoneType type = 2;
}enum PhoneType {MOBILE = 0;HOME = 1;WORK = 2;
}message MyMessage {map<int32, int32> mapfield = 1;
}
3. 使用proto.exe编译.proto文件,生成一个对应的.py的文件
在项目目录下执行:proto.exe --python_out = ./ test.proto
4. 接下来就可以编写python程序进行序列化和反序列化了
import test_pb2address_book = test_pb2.AddressBook()
person = address_book.people.add()person.id = 1
person.name = 'lichungang'
person.email = 'xxxxx@163.com'
person.money = 1
person.work_status = Truephone_number = person.phones.add()
phone_number.number = "123456"
phone_number.type = test_pb2.MOBILEmaps = person.maps # maps类型是singular,不是repeated类型无法使用add()
maps.mapfield[1] = 1
maps.mapfield[2] = 2# 序列化
serialize_to_string = address_book.SerializeToString()
print(serialize_to_string, type(serialize_to_string))# 反序列化
address_book.ParseFromString(serialize_to_string)for person in address_book.people:print("p_id:{},p_name:{},p_email:{},p_money:{},p_workstatu:{}".format(person.id, person.name, person.email, person.money, person.work_status))for phone_number in person.phones:print(phone_number.number, phone_number.type)for key in person.maps.mapfield:print(key, person.maps.mapfield[key])
结果:
b'\n<\n\nlichungang\x10\x01\x1a\rxxxxx@163.com%\x00\x00\x80?(\x012\x08\n\x06123456:\x0c\n\x04\x08\x01\x10\x01\n\x04\x08\x02\x10\x02' <class 'bytes'>
p_id:1,p_name:lichungang,p_email:xxxxx@163.com,p_money:1.0,p_workstatu:True
123456 0
1 1
2 2
参考:
https://www.cnblogs.com/sanshengshui/p/9739521.html
https://blog.csdn.net/caisini_vc/article/details/5599468