Fred.Brooks在1987年就提出:没有银弹。没有任何一项技术或方法可以能让软件工程的生产力在十年内提高十倍。
我无意挑战这个理论,只想讨论一个方案,一个可能大幅提高业务系统开发效率的方案。
方案描述
我管这个方案叫做“由基线扩展业务线的方案”。从名字就可以看出,它至少包括两部分:基线;业务线。其实还有一部分隐藏在动词后面:扩展点。这三部分及相互之间的关系大体上是这样的: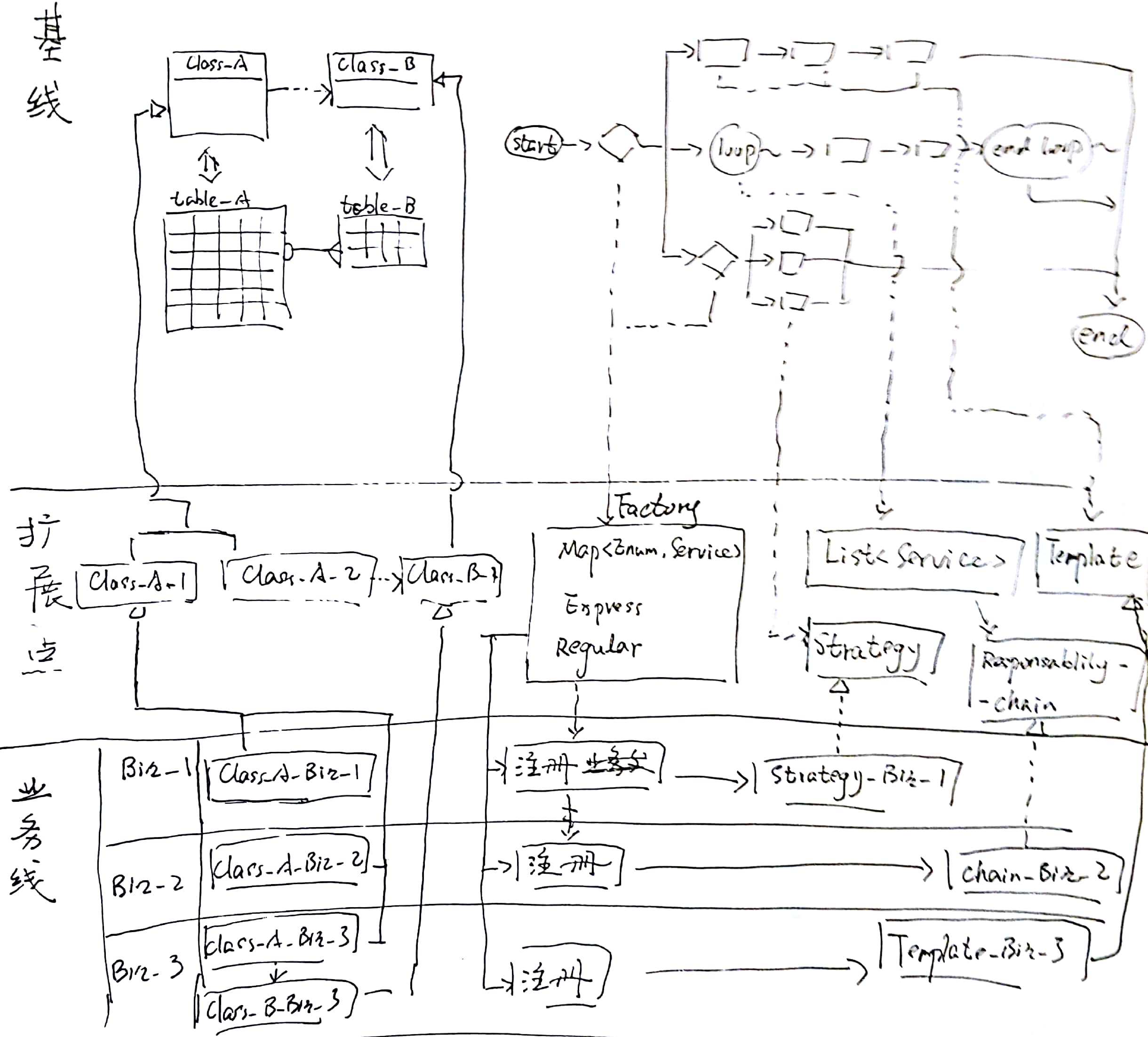
基线
基线是一套领域模型、流程框架,但不包含任何业务的实际逻辑——即使是某种“通用”的、“默认”的逻辑。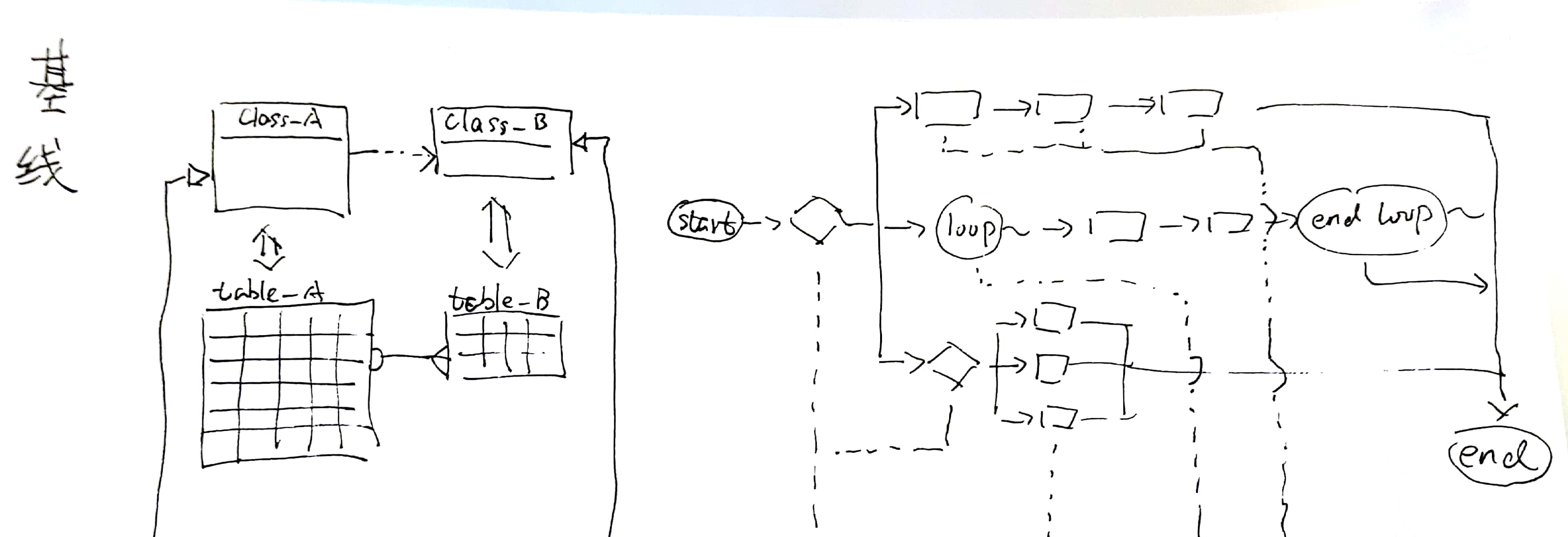
基线中绝对不能混入业务逻辑,这是为了避免系统框架的“特化”。而系统一旦为了某种业务而进行“特化”,那么一定会在某一次业务变化中,系统要么像三叶虫、恐龙那样陷入死胡同;要么像总鳍鱼、库克逊蕨一样,大幅改造自己。无论哪一种都是代价昂贵、难以接受的。因此,基线中绝对不能混入业务逻辑。
业务基线中不做业务逻辑,做什么?领域模型和流程框架。
领域模型描述的是这个业务系统关注哪些数据,这些数据之间有什么样的关系、约束、依赖,必须在业务模型中描述清楚。这是整个业务系统的基石、首要问题:我们要做什么样的业务。就像人类仰望星空时的第一问“我是谁”一样,如何回答这个问题,决定了我们如何实现系统。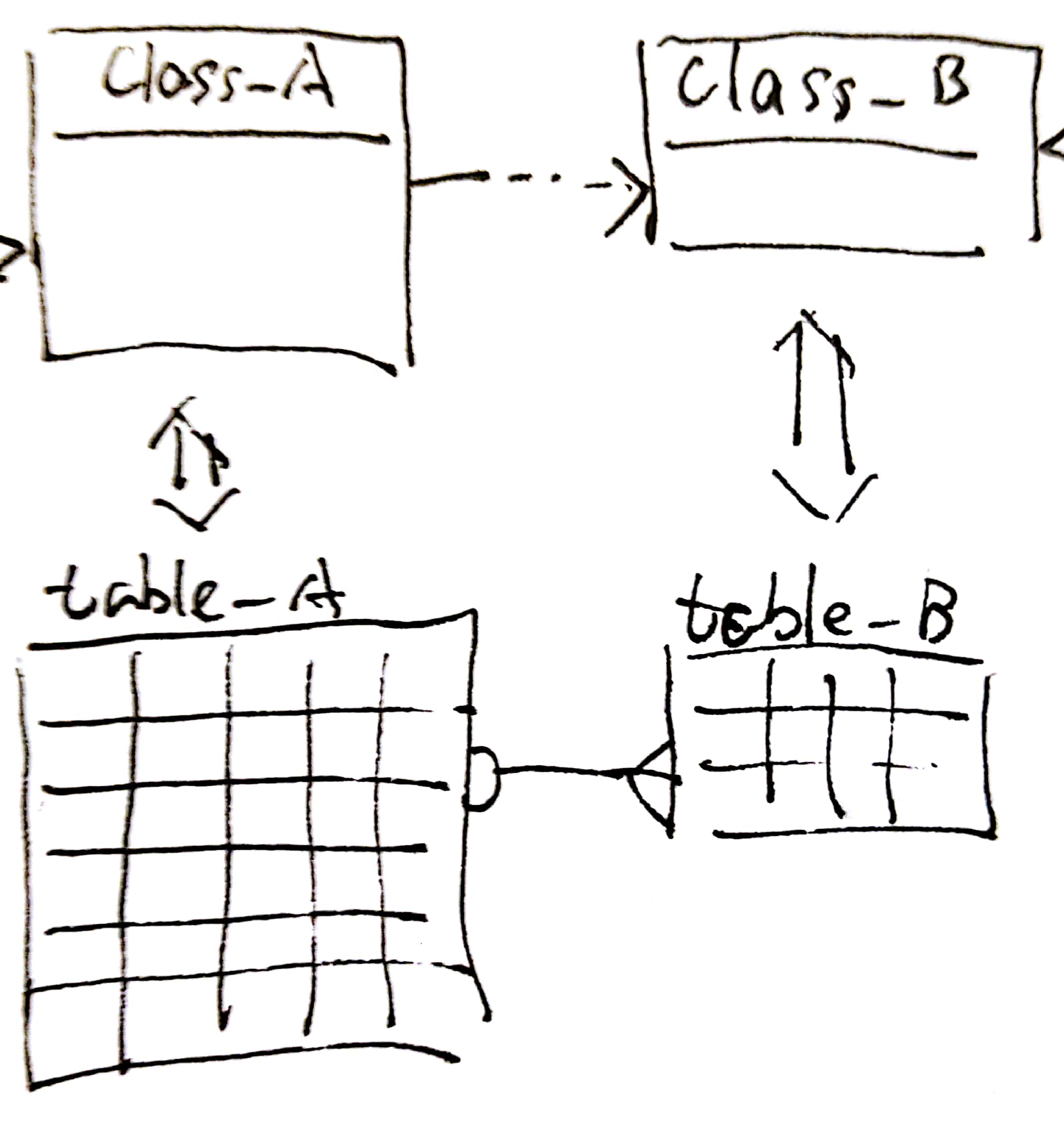
流程框架描述的是系统如何将数据组织、流转起来,使之成为我们期望的业务。这个流程可以是一级分发、二级分发、实际处理;可以是校验、预处理、核心逻辑、后处理;也可以是迭代、是递归、是链式、是并发……等等,这些都可以具体问题具体分析。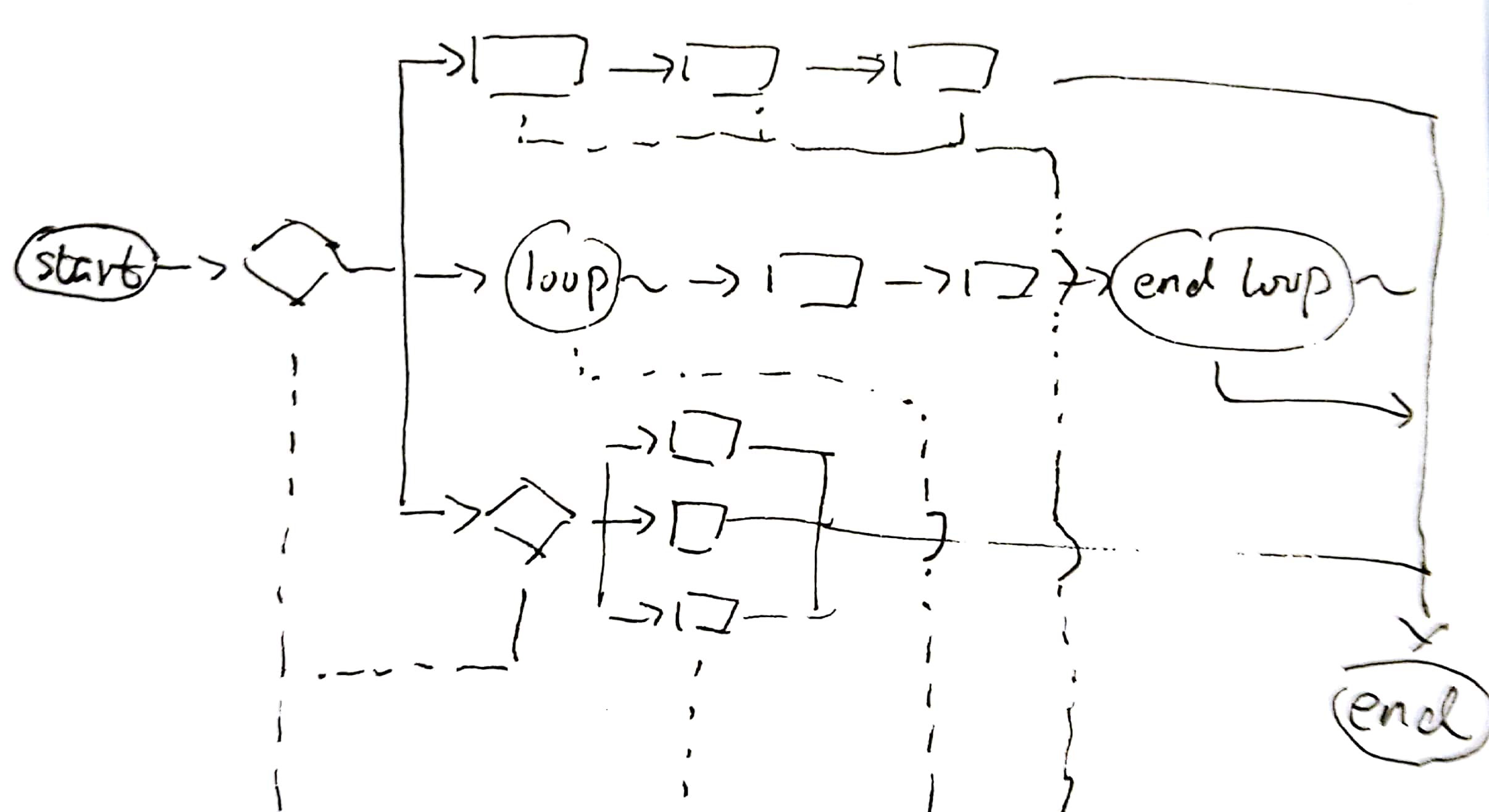
但是,尽管可以具体问题具体分析,无论是数据结构、还是流程框架,在实现上一定要保证高度的扩展性。这就是这个设计方案的第二部分:扩展点所重点关注的目标。
扩展点
由于基线中并不包含业务逻辑,我们必须在基线中埋入若干扩展点。否则,业务逻辑就无法按照基线中的流程来运转。
借助于面向对象的继承和泛型等特性,我们可以很便捷的扩展领域模型中的数据结构。但是流程框架中的扩展点,要更复杂一些。
从最简单的方面来考虑,我们同样可以利用继承、泛型和多态,以及各种设计模式,来将原有的一套代码扩展为另一套新的代码。然而,我们如何让基线代码执行到某个扩展点时,流转到特定的业务代码上去呢?
详细的解决办法可以有很多,比如我之前总结的分发模式。一般来说,都是利用一些依赖倒置(例如SpringIOC)或者服务注册等方式,在适当的位置上让业务流程走向不同的代码分支。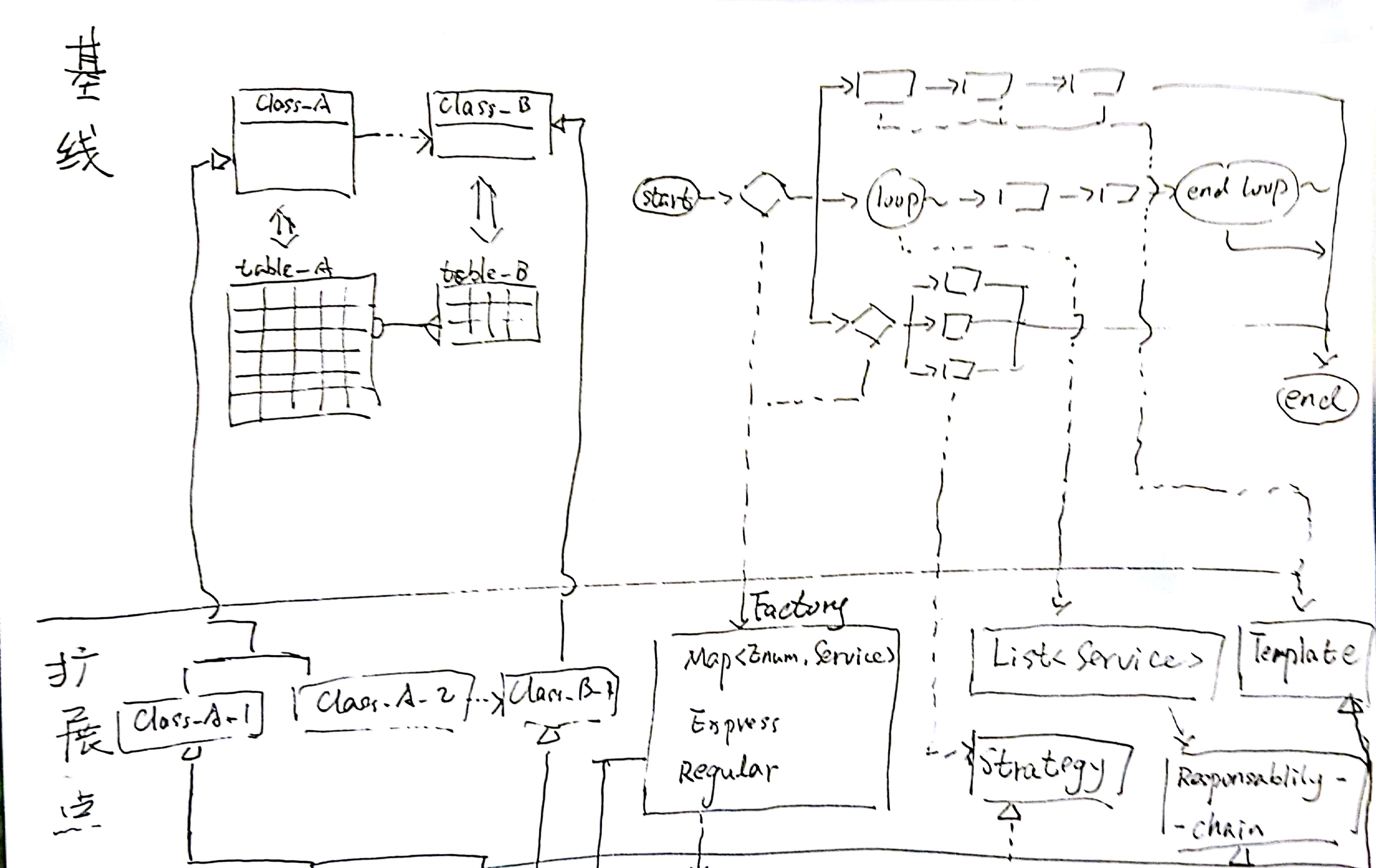
例如上图中,基线右侧的流程框架被分为三条分支。其中最上方的流程分为三个步骤;中间的流程以循环方式,依次执行两个逻辑;最下方的流程又再次被分为三个分支。
那么,这条基线的扩展点,就可以是一个工厂+策略(对应三个分支的分叉点)、一个模板(对应最上方流程)、一个责任链(对应中间流程)、以及又一个工厂+策略(对应最下方流程)。
其中,这两个分支判断所需工厂的具体实现,可以是Map<Enum,Service>、或者Express-Service、抑或Regular-Service。这些机制可以轻松地把我们为某个业务而扩展出来的Service注册、插入到由基线定义的流程框架中。
总之,有了扩展点,我们就可以把具体的业务代码加入到基线流程中,使之成为一条独立的业务线了。
业务线
就代码而言,业务线实际上并不是一条“线”。它往往只是针对一两个扩展点而开发的代码。实际上,只有在这些代码注册到基线中之后,它才能成为一条“业务线”。
尽管如此,我还是把它单独地画在了整个方案的最下方(扩展点的下方),就像这样: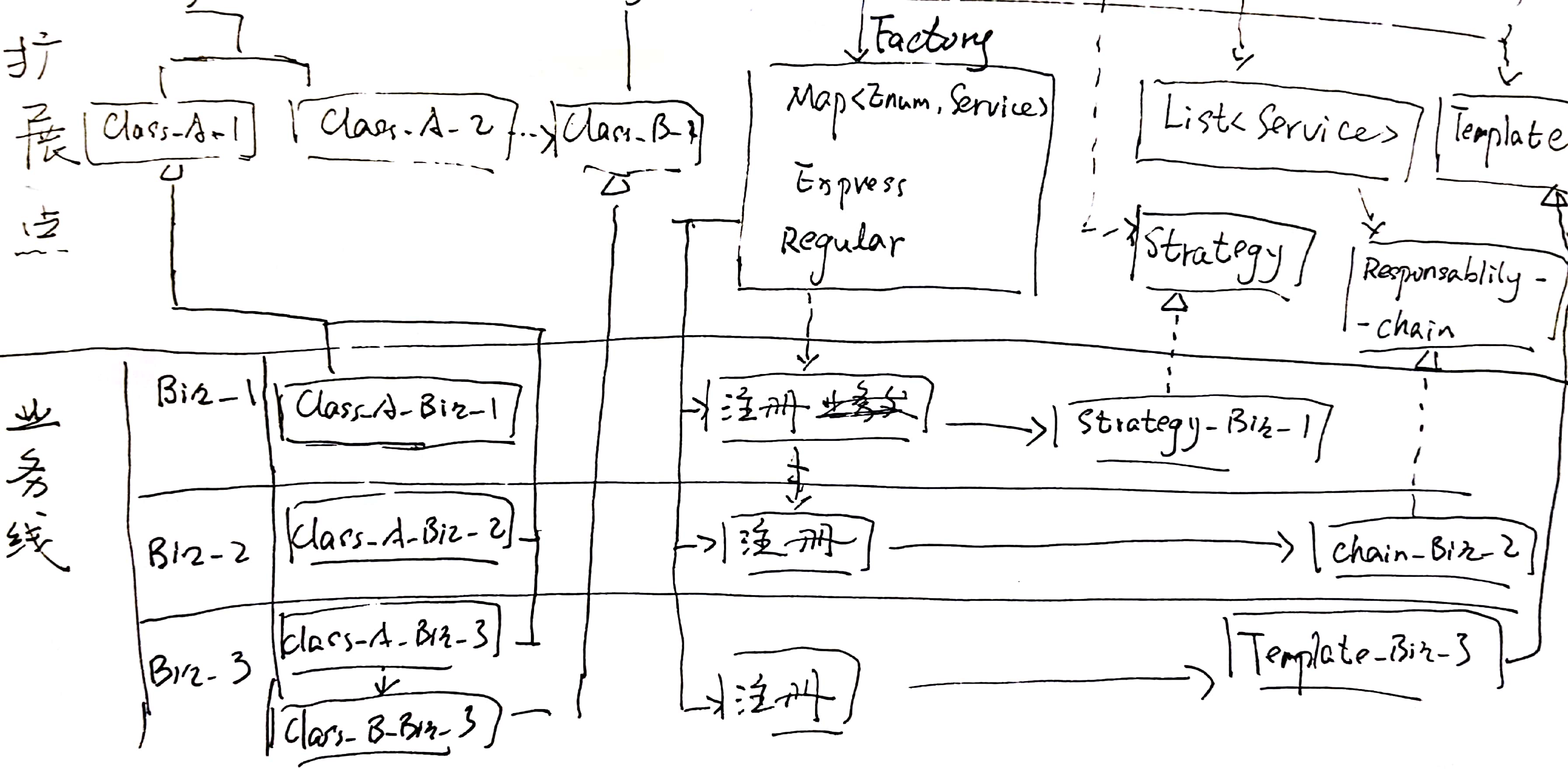
上图中展示了三条业务线分别扩展基线、并注册到基线中去的情况。如果再有新的业务线加入其中,可以依样画葫芦。
实践
实际上,这个方案是我在xx公司参加一个业务系统的改造开发过程中,逐步整理、积累出来的。所以,在这个业务系统中,我实践了这套方案的大部分想法。
没有实现的想法主要是基线中不能包含业务逻辑。一方面,基线的业务流程中包含有业务逻辑:这是一套“默认”逻辑。也就是说,如果一条业务线没有任何特殊的地方,那么它就会按照基线中的“默认”逻辑进行处理。但是,这导致了后期大量的业务代码以“默认逻辑”的名义涌入基线中,使得基线越来越特化、退化为一条“业务线”——尽管它是“默认”业务线。另一方面,领域模型中没有配置扩展点。这导致一套数据结构中包含了所有业务线所需数据。这也是“默认逻辑”不断扩大的一个“元凶”:数据结构中的每个字段都必须有“默认”值。
分析
“由基线扩展业务线”,这个方案的内容基本就是这样。这个方案的优缺点都有哪些呢?这里简单分析一下。
优点
这个方案的优点,基本都来自于它的高内聚低耦合特性。
高内聚低耦合
尽管高内聚低耦合在很多团队中只是一句口号,但是这个设计实实在在地践行了这一理念。基线对业务封闭,对扩展点开放;业务线对彼此封闭,对新业务开放。这样高度的封闭与有限的开放保证了基线和业务线自身的高内聚和相互的低耦合。
完整的业务模型
由于基线中包含了完整的领域模型和流程框架,它就能代表系统的业务模型。这是这个方案能成功的一个前提;同时,这也是使这个方案出类拔萃的一个产出。
在我们的实践中,这一点带来了很大的好处。在改造之前,系统中的业务非常混乱。产品不知道完整业务流程,经常出现需求只覆盖到一小部分流程、因而不断进行修改,甚至出现前后矛盾的需求。开发也不知道完整的代码流程,这导致了一个更严重的问题:产品怎么说开发怎么做,完全没有技术上的考虑和设计。测试同事反而是最熟悉完整流程的人,但是测试阶段太靠后,发现问题时往往为时已晚。
而完成改造后,变化首先出现在开发身上。开发人员对业务有了全局的掌控,开始和产品讨论、甚至是争论;此后产品给出的需求描述也更加准确、完善。
项目管理可控
项目管理的四个要点:范围、工期、成本、质量,都可以在高内聚、低耦合的特性下得到有力的控制。
这是我们的实践中改进最大的一点。在改造之前,产品提出需求之后,会问这样几个问题:开发同事们估计要改哪些地方?大概要多久?我们开发只能回答不知道,回去翻翻代码再说、问问老同事再说。在改造之前,我们代码质量非常糟糕,无数的巨型Java类、重复代码、超长的switch-case……
改造之后,我们对照基线梳理一遍,就能够清楚地知道需要写那些代码、大约需要多久。而且,基线和扩展点大量运用设计模式、泛型、接口等编程方式,有效的提高了代码质量。
技术易于演进
高内聚低耦合带来的是高度的模块化。在这样的模块化结构下,技术演进可以很轻松的推进。
在我们的实践中,基线中的一个内部模块前后经历过四次重构和优化,包括同步改异步(后来又改回了同步)、对接外部系统、SQL优化、以及数据库结构变更。尽管这个模块负责系统核心业务,但它每一次变化都没有影响到任何一个业务,并且都能顺利地达成目标。尤其是SQL优化这项工作:在改造之前我们就曾经尝试过,但因为代码质量太差、模块耦合度过高而放弃。
缺点
这个方案的缺点主要来自于它对业务模型的高要求。
建立和维护业务模型
建立模型本身就是一件困难的工作;让团队成员接受和理解这个模型,则是一项技术之外的工作;而让团队在后续的开发中维护这个模型,这几乎只能靠上帝保佑了。
这三个问题中,只有建模可以称得上技术工作;其它两项主要是团队中的组织和沟通工作。在这点上,“外科手术”式的团队也许比敏捷团队要更好一些。毕竟,“众不可户说”,将与模型有关的问题交给一两个人来决定,其他人只需参谋和执行,这样能减少一些建立和维护模型的问题。不过,如果能够像敏捷团队那样,每个人都“自组织”地接受、理解、维护甚至优化模型,那简直是求之不得的好事。
在我们的实践中,团队更类似于“外科手术”式。问题在于:团队内的两名权威——职级上的权威和技术上的权威——没有对模型达成根本上的一致。这导致了团队成员对模型的怀疑、误解,更导致了模型以及代码、系统的迅速腐化:基线中的业务代码越来越多;业务线不断突破彼此的边界;新代码的质量也大不如前。
代码流程不连贯
尽管我私底下认为,这个问题的根本原因是开发人员不了解模型及其中业务的运作方式,或者是开发人员不理解“面向接口”、“面向对象”等编程思想。但是,鉴于这个问题在我们的实践中被反复地提出,我还是把它记录下来吧。
在这个模型下,实现业务的代码会零散的分布在业务线、扩展点和基线中。这会给我们阅读代码、断点追踪和trouble shooting带来一些麻烦。
束缚创新思维
这是一顶很大的帽子。一个业务模型规定了这项业务的处理方式——如何组织数据和流程。然而,这项业务就只能按照这种方式来处理吗?显然不是。然而,如果我们一味的泥于现有的业务模型,那么,迟早会出现这么一天:我们必须花费三倍、十倍的,才能把新的业务“塞进”这个模型中。这个问题已经很头疼了,更不用说当我们需要主动地对业务进行全面创新(而不仅仅是升级换代)时,这样“重”的一套模型会是多么大的一个负担。
幸运的是,我们的实践还完全没有走到这一步。悲观点想,也许根本就走不到这一步。
后记
我绝没有真的自大到认为这真的是一枚“银弹”,因为它甚至没能把我们团队的软件开发生产力提高三倍。
但我仍然认为这是一个好的思路。不是银弹——也许真的没有银弹——但是至少可以当颗大蒜。
本文转自 斯然在天边 51CTO博客,原文链接:http://blog.51cto.com/winters1224/1959644,如需转载请自行联系原作者


)


.doc)





)




 协议概述)

)
