原文链接:www.sqlservercentral.com/articles/Stairway+Series/72351/
Clustered Indexes: Stairway to SQL Server Indexes Level 3
By David Durant, 2013/01/25 (first published: 2011/06/22)
The Series
本文是阶梯系列的一部分:SQL Server索引的阶梯。
索引是数据库设计的基础,并告诉开发人员使用数据库大量关于设计者的意图。不幸的是,当性能问题出现时,索引常常会作为事后考虑添加。这里最后是一系列简单的文章,应该能让数据库专业人员快速地与它们同步。
前面的水平在这楼梯概述指标一般和专门的非聚集索引。它总结了以下关键的SQL服务器索引概念。当请求到达数据库时,无论是SELECT语句还是插入、UPDATE或删除语句,SQL Server只有三种可能的方式访问语句中引用的表的数据:
访问只是非聚集索引,避免访问表。只有在索引包含查询所请求的这个表的所有数据时,才有可能。
使用搜索键(s)访问索引,然后使用所选的书签访问表的各个行。
忽略索引并搜索所请求行的表。
这个级别从上面列表中的第三个选择开始,搜索表。反过来,这将引导我们讨论聚集索引;在第2级提到的主题,但没有包括在内。
初级AdventureWorks数据库表我们将在这个级别使用的是salesorderdetail表。在121317行中,它足以说明表上有聚集索引的一些好处。而且,有两个外键,它很复杂,足以说明您必须对集群索引做出的一些设计决策。
Sample Database
虽然我们已经在第1级讨论了示例数据库,但现在仍在重复。在整个楼梯中,我们将用例子来说明概念。这些例子都是基于微软的AdventureWorks示例数据库。我们专注于销售订单。表五将给我们一个很好的组合交易与非交易数据;客户、销售人员、产品、salesorderheader,和salesorderdetail。为了使事情集中,我们使用列的一个子集。因为是标准化的销售人员中,信息被分解成三个表:销售人员,员工和接触。
在整个阶梯中,我们使用以下两个术语,即一行互换的单行项:“行项目”和“订单详细信息”。前者是比较常见的业务术语;在AdventureWorks表的名称出现后。
完整的一组表及其之间的关系如图1所示。
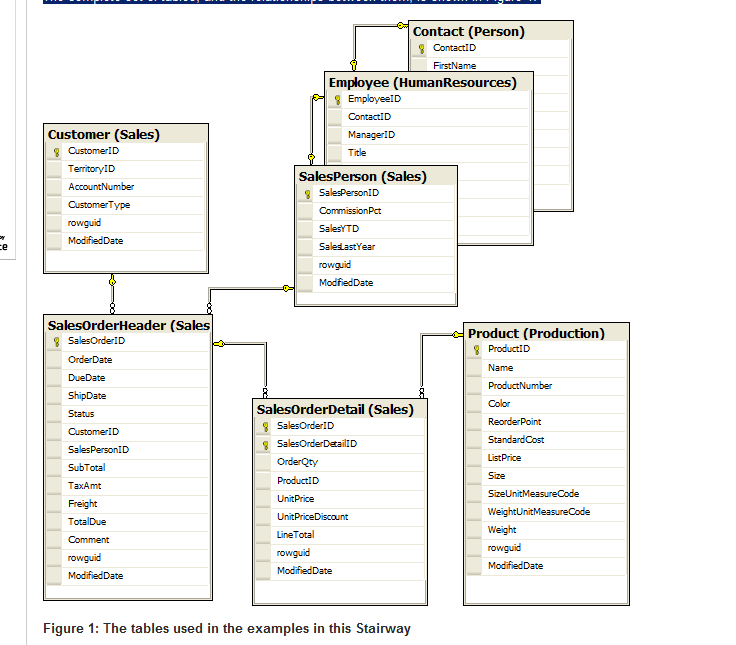
Clustered Indexes
我们开始问这样的问题:有多少工作需要找到一个排(S)表中如果非聚集索引是不使用?搜索请求行的表是否意味着扫描无序表中的每一行?或者SQL Server永久序列表中的行,它可以快速的搜索关键字访问它们,正如它快速访问搜索关键非聚集索引的条目?答案取决于是否指示SQL Server在表上创建聚集索引。
与非聚集索引,这是一个分离的对象占用的空间,聚集索引的表是一样的。通过创建聚集索引,您指示SQLServer将表的行排序为索引键序列,并在将来的数据修改期间维护该序列。即将出现的级别将查看生成的内部数据结构,以完成此任务。但是现在,将聚集索引看作是一个已排序的表。给定一行的索引键值,SQL Server可以快速访问该行,并可以从该行的表中连续地进行访问。
出于演示的目的,我们创建了两个本例表,salesorderdetail;没有指标和一个聚簇索引。对于索引的键列,我们设计师的adventureworksdatabase做出了同样的选择:SalesOrderID / salesorderdetailid。清单1中的代码对SalesOrderDetail表复印件。我们可以随时重新运行这个代码,我们希望从一个“干净的石板”开始。
IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID('dbo.SalesOrderDetail_index')) DROP TABLE dbo.SalesOrderDetail_index; GO IF EXISTS (SELECT * FROM sys.tables  WHERE OBJECT_ID = OBJECT_ID('dbo.SalesOrderDetail_noindex')) DROP TABLE dbo.SalesOrderDetail_noindex; GO
SELECT * INTO dbo.SalesOrderDetail_index FROM Sales.SalesOrderDetail;
SELECT * INTO dbo.SalesOrderDetail_noindex FROM Sales.SalesOrderDetail;
GO
CREATE CLUSTERED INDEX IX_SalesOrderDetail
ON dbo.SalesOrderDetail_index (SalesOrderID, SalesOrderDetailID)
GO
Listing 1: Create copies of the SalesOrderDetail table
所以,假设SalesOrderDetail表看起来像这样在创建聚集索引:
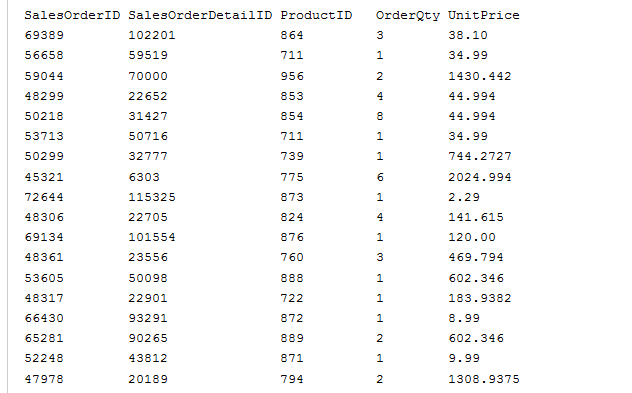
在创建上面显示的聚集索引之后,生成的表/聚集索引将如下所示:
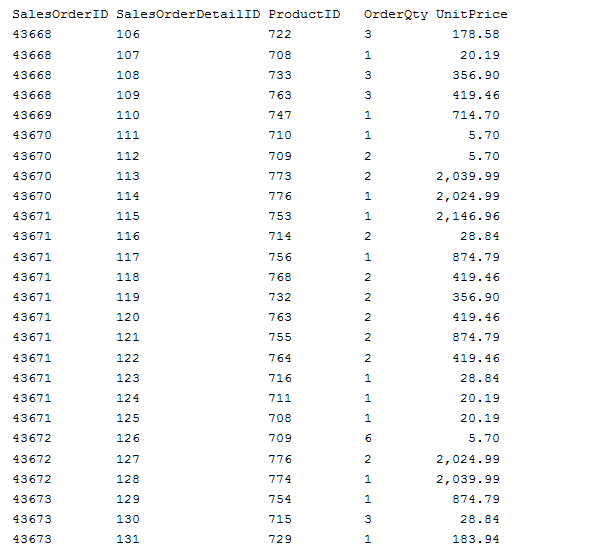
你看上面的示例数据,你会发现每个salesorderdetailid值是唯一的。Do not be confused; SalesOrderDetailID is not the primary key of the table. 对salesorderdetailid SalesOrderID /组合是表的主键;以及聚集索引的索引键。
Understanding the Basics of Clustered Indexes
每个表最多可以有一个聚集索引。表的行只能在一个序列中。您需要决定什么顺序(如果有的话)对每一个表最好,如果可能的话,在表充满数据之前,创建聚集索引。做这个决定时,要记住,排序不仅意味着订货,还意味着分组;如按销售订单分组行项。
这就是为什么在adventureworksdatabase设计师选择在SalesOrderID salesorderdetailid为SalesOrderDetail表的顺序;它是商品的自然顺序。
例如,如果用户请求一个订单的行项,他们通常会请求该订单的所有行项目。一个典型的销售订单表格告诉我们,订单的打印副本总是包含所有的行项。销售订单业务的性质是按销售订单对生产线项目进行分组。有可能从仓库想要的产品而不是销售订单行项目偶尔观要求;但大多数的请求;如从销售人员或客户,或该程序打印发票,或一个查询,计算每个订单的总价值;需要所有的行项目对于任何给定的销售订单。
然而,用户需求本身并不能决定什么是最好的聚集索引。本系列中的未来级别将涵盖索引的内部;因为索引的某些内部方面也会影响您选择的聚集索引列。
Heaps
如果表上没有聚集索引,则该表称为堆。每个表要么是堆,要么是聚集索引。所以,虽然我们经常认为每个指标分为两种类型之一,聚集或非聚集;需要注意的是,每一个表分成两个类型同样重要;它是一个聚集索引或是一堆。开发人员经常说表“有”或“没有”聚集索引,但是说表“是”或“不是”是一个更有意义的聚集索引。
有SQL Server搜索一堆当寻找行只有一个方法(不包括非聚集索引的使用),这是开始在表中的第一行并进行表直到所有的行被读取。没有序列,没有搜索键,无法快速导航到特定行。
Comparing a Clustered Index with a Heap
评价一个聚集索引和一堆的性能,使两份清单1的salesorderdetailtable。一份是堆版,另一方面,我们创造了相同的聚集索引,即对原表(SalesOrderID,SalesOrderDetailID)。既有非聚集索引的表。
我们将对表的每一个版本执行相同的三个查询;一个检索单个行,一个检索一个订单的所有行,另一个查询单个产品的所有行。我们在下面的表中展示了SQL和每个执行的结果。
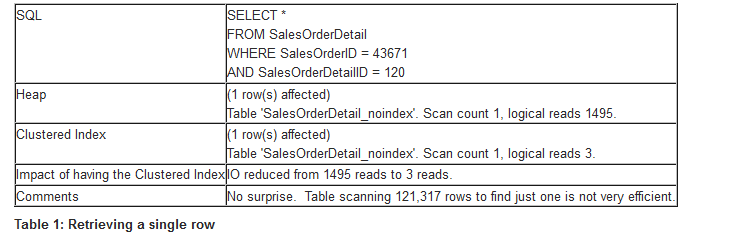
我们的第一个查询检索一行,执行细节如表1所示。
我们的第二个查询检索单个销售订单的所有行,您可以在表2中看到执行细节。

我们的第三查询检索单个产品的所有行,执行结果如表3所示。

我们的第一个查询大大受益于聚集索引的存在;第三是大致相等的。聚集索引是否有危害?答案是肯定的,它主要与插入、更新和删除行有关。就像在早期阶段遇到的索引的许多其他方面一样,它也是一个更高层次更详细地讨论的主题。
一般来说,检索的好处大于维修的危害;使聚集索引比一堆。如果在Azure数据库中创建表,则没有选择;每个表必须是一个聚集索引。
Conclusion
聚集索引是一个排序表,它在索引创建时由您指定,由SQLServer维护。该表中的任何行都可以很快地访问它的键值。索引键序列中的任何一组行,也可以在键的范围内快速访问。
每个表只能有一个聚集索引。哪些列应该是聚集索引键列的决定是您对任何表所作的最重要的索引决策。
在我们的第4级中,我们将重点从逻辑到物理,引入页面和范围,并检查索引的物理结构。
Downloadable Code
- Clustered.SQL



















