流式数据分析
The recent years have seen a considerable rise in connected devices such as IoT [1] devices, and streaming sensor data. At present there are billions of IoT devices connected to the internet. While you read this article, terabytes and petabytes of IoT data will be generated across the world. This data contains a huge amount of information and insights. However, processing such high volumes of streaming data is a challenge, and it requires advanced BigData capabilities to manage these challenges and derive insights from this data.
近年来,诸如IoT [1]设备之类的连接设备以及流式传感器数据有了显着增长。 目前,有数十亿物联网设备连接到互联网。 当您阅读本文时,将在全球范围内生成TB和PB的IoT数据。 这些数据包含大量信息和见解。 但是,处理如此大量的流数据是一个挑战,它需要高级BigData功能来管理这些挑战并从这些数据中获取见解。
At AlgoAnalytics, we have developed a powerful tool which ingests real time streaming data feeds (for example from IoT devices) to enable visualization and analytics for quicker business decisions.
在AlgoAnalytics ,我们开发了一个功能强大的工具,可提取实时流数据馈送(例如,从IoT设备获取),以实现可视化和分析,以便更快地做出业务决策。
The four steps involved underneath Streaming Big Data Analytics are as follows :
流式大数据分析所涉及的四个步骤如下:
The high level design of Streaming Big Data Analytics pipeline is illustrated in Figure 1.
图1显示了Streaming Big Data Analytics管道的高级设计。

Data Ingestion:
数据提取:
Data ingestion involves gathering data from various streaming sources (e.g. IoT sensors) and transporting them to a common data store. This essentially is transforming unstructured data from origin to a system where it can be stored for further processing. Data comes from various sources, in various formats and at various speeds. It is a critical task to ingest complete data into the pipeline without any failure.
数据摄取涉及从各种流媒体源(例如IoT传感器)收集数据并将其传输到公共数据存储。 这实质上是将非结构化数据从原始数据转换为可以存储数据以进行进一步处理的系统。 数据来自各种来源,格式和速度各异。 将完整的数据摄取到管道中而没有任何失败是至关重要的任务。
For Data Ingestion, we have used Apache Kafka [2]- a distributed messaging system which fulfills all the above requirements. We have built a high scalable fault tolerant multi-node kafka cluster which can process thousands of messages per second without any data loss and down time. Kafka Producer collects data from various sources and publishes data to different topics accordingly. Kafka Consumer consumes this data from the topics in which they are interested in.This way data from different sources is ingested in the pipeline for processing.
对于数据提取,我们使用了Apache Kafka [2]-一种满足所有上述要求的分布式消息传递系统。 我们建立了一个高度可扩展的容错多节点kafka集群,该集群可以每秒处理数千条消息,而不会造成任何数据丢失和停机时间。 Kafka Producer从各种来源收集数据,并相应地将数据发布到不同的主题。 Kafka Consumer从他们感兴趣的主题中消费此数据。这样,来自不同来源的数据就会被吸收到管道中进行处理。
2. Real Time Data Processing:
2.实时数据处理:
The data collected in the above step needs to be processed in real time before pushing it to any filesystem or database. This includes transforming unstructured data to structured data. Processing includes filtering, mapping, conversion of data types, removing unwanted data, generating simplified data from complex data,etc
在将上一步中收集的数据推送到任何文件系统或数据库之前,需要对其进行实时处理。 这包括将非结构化数据转换为结构化数据。 处理包括过滤,映射,数据类型转换,删除不需要的数据,从复杂数据生成简化数据等。
For this step we have used Spark Streaming [3] which is the best combination with Apache Kafka to build real time applications. Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Spark Streaming receives the data ingested through kafka and converts it into continuous stream of RDDs — DStreams (basic abstraction in spark streaming). Various spark transformations are applied on these DStreams to transform the data to the state from where it can be pushed to the database.
在这一步中,我们使用了Spark Streaming [3],它是与Apache Kafka的最佳组合,用于构建实时应用程序。 Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。 Spark Streaming接收通过kafka提取的数据,并将其转换为RDD的连续流-DStreams(Spark流中的基本抽象)。 在这些DStream上应用了各种spark转换,以将数据转换到可以将其推送到数据库的状态。
3. Data Storage:
3.数据存储:
The data received from source devices (such as IoT devices) is time-series data — measurements or events that are tracked, monitored, downsampled, and aggregated over time. Properties that make time series data very different from other data workloads are data lifecycle management, summarization, and large range scans of many records. A time series database (TSDB) [4] is a database optimized for such time-stamped or time series data with time as a key index which is distinctly different from relational databases . A time-series database lets you store large volumes of time stamped data in a format that allows fast insertion and fast retrieval to support complex analysis on that data.
从源设备(例如IoT设备)接收的数据是时间序列数据 -随时间跟踪,监视,下采样和聚合的测量或事件。 使时间序列数据与其他数据工作负载非常不同的属性是数据生命周期管理,摘要和许多记录的大范围扫描。 时间序列数据库(TSDB) [4]是针对时间标记或时间序列数据进行优化的数据库,其中时间作为关键索引,与关系数据库明显不同。 时间序列数据库允许您以允许快速插入和快速检索的格式存储大量带时间戳的数据,以支持对该数据进行复杂的分析。
Influxdb [5] is one such time-series database designed to handle such high write and query loads. We have set up a multi node influxdb cluster which can handle millions of writes per second and also in-memory indexing of influxdb allows fast and efficient query results. We have also set up various continuous tasks which downsample the data to lower precision, summarized data which can be kept for a longer period of time or forever. It reduces the size of data that needs to be stored as well as the query time by multiple times as compared with very high precision data.
Influxdb [5]是一种此类时间序列数据库,旨在处理如此高的写入和查询负载。 我们已经建立了一个多节点的influxdb集群,该集群可以每秒处理数百万次写入,并且influxdb的内存索引可以实现快速,有效的查询结果。 我们还设置了各种连续任务,这些任务会将数据降采样到较低的精度,汇总的数据可以保留更长的时间或永远。 与非常高精度的数据相比,它可以将需要存储的数据大小以及查询时间减少多次。
4. Visualization:
4.可视化:
To add value to this processed data it is necessary to visualize our data and make some relations between them. Data visualization and analytics provide more control over data and give us the power to control this data efficiently.
为了给处理后的数据增加价值,有必要使我们的数据可视化并在它们之间建立某种关系。 数据可视化和分析可提供对数据的更多控制,并使我们能够有效地控制此数据。
We used Grafana [6], a multi-platform open source analytics and interactive visualization web application. It provides charts, graphs, and alerts for the web when connected to supported data sources. We have created multiple dashboards for different comparisons. On these dashboards, we can visualize real time status as well as the historical data (weeks, months or even years). We can also compare data of the same type with different parameters. Several variables are defined which provide flexibility to use dashboards for multiple visualizations. For example, we can select a single device or multiple devices or even all devices at a time. We can select how to aggregate data per minute, per hour to per year.
我们使用了Grafana [6],这是一个多平台的开源分析和交互式可视化Web应用程序。 当连接到受支持的数据源时,它会为Web提供图表,图形和警报。 我们创建了多个仪表盘用于不同的比较。 在这些仪表板上,我们可以可视化实时状态以及历史数据(几周,几个月甚至几年)。 我们还可以将具有不同参数的相同类型的数据进行比较。 定义了几个变量,这些变量可灵活使用仪表板进行多个可视化。 例如,我们可以一次选择一个或多个设备,甚至所有设备。 我们可以选择如何每分钟,每小时和每年汇总数据。
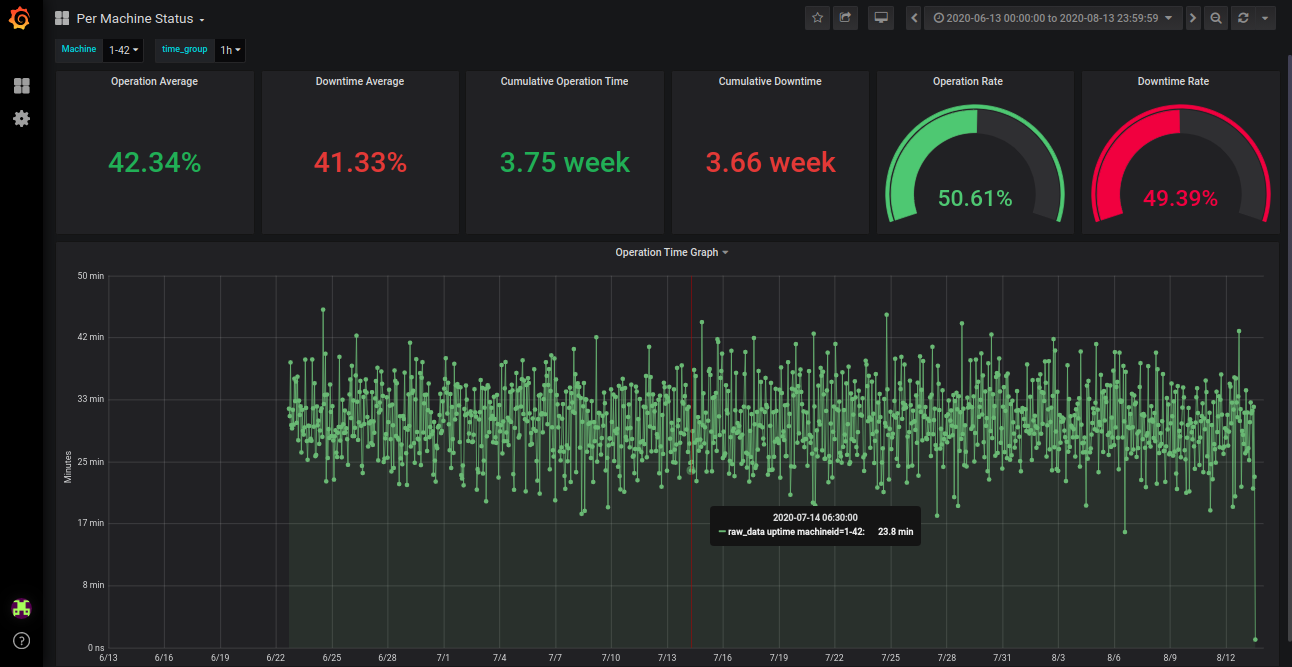
Figure 2 shows the Uptime and some parameters of a selected machine for a selected period (2 months).
图2显示了选定时间段(2个月)内选定机器的正常运行时间和一些参数。
Applications :
应用范围 :
As a large number of businesses in multiple sectors are moving to connected and smart devices, Streaming Big Data Analytics finds its applications across many verticals.
随着多个领域的众多企业正在转向互联和智能设备,Streaming Big Data Analytics在许多垂直领域都可以找到其应用程序。
Few examples include real time machine monitoring and anomaly detection in industries, sensor embedded medical devices to understand emergencies in advance, surveillance using video analytics, in Retail and Logistics to increase sale by studying customer movements, in transport sector — smart traffic control, electronic toll collections systems, in Military for surveillance, Environmental monitoring — air quality, soil conditions, movement of wildlife, etc
很少有这样的例子:行业中的实时机器监控和异常检测,传感器嵌入式医疗设备可以提前了解紧急情况,零售和物流中使用视频分析进行监控,通过研究运输行业的客户动向来提高销售量,例如交通领域,智能交通控制,电子通行费军事上用于监视,环境监测的采集系统-空气质量,土壤条件,野生动植物的移动等
For further information, please contact: info@algoanalytics.com
欲了解更多信息,请联系:info@algoanalytics.com
IoT : https://en.wikipedia.org/wiki/Internet_of_things
物联网 https://zh.wikipedia.org/wiki/Internet_of_things
Apache Kafka : https://kafka.apache.org/documentation/#gettingStarted
Apache Kafka: https : //kafka.apache.org/documentation/#gettingStarted
Spark Streaming : https://spark.apache.org/docs/latest/streaming-programming-guide.html
火花流: https : //spark.apache.org/docs/latest/streaming-programming-guide.html
Time Series Database : https://www.influxdata.com/time-series-database/
时间序列数据库: https : //www.influxdata.com/time-series-database/
InfluxDB : https://www.influxdata.com/products/influxdb-overview/
InfluxDB: https : //www.influxdata.com/products/influxdb-overview/
Grafana : https://grafana.com/docs/
Grafana: https ://grafana.com/docs/
翻译自: https://medium.com/algoanalytics/streaming-big-data-analytics-d4311ed20581
流式数据分析
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/388614.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

oracle failover 区别,Oracle DG failover 实战

Jenkins自动化CI CD流水线之8--流水线自动化发布Java项目

oracle数据泵导入很慢,impdp导入效率的问题
)
BZOJ2597 WC2007剪刀石头布(费用流)

数据科学还是计算机科学_数据科学101
)
开机流程与主引导分区(MBR)

肤色检测算法 - 基于二次多项式混合模型的肤色检测。

oracle解析儒略日,利用to_char获取当前日期准确的周数!


js有默认参数的函数加参数_函数参数:默认,关键字和任意


oracle raise_application_error,RAISE_ APPLICATION_ ERROR--之异常处理


2018大数据学习路线从入门到精通

相似邻里算法_纽约市-邻里之战

![[poj 1364]King[差分约束详解(续篇)][超级源点][SPFA][Bellman-Ford]](http://pic.xiahunao.cn/[poj 1364]King[差分约束详解(续篇)][超级源点][SPFA][Bellman-Ford])
[poj 1364]King[差分约束详解(续篇)][超级源点][SPFA][Bellman-Ford]

linux质控命令,Linux下microRNA质控-cutadapt安装

采用多播传送FIX行情数据的推荐方案
