一般线性模型和混合线性模型
生命科学的数学统计和机器学习 (Mathematical Statistics and Machine Learning for Life Sciences)
This is the eighteenth article from the column Mathematical Statistics and Machine Learning for Life Sciences where I try to explain some mysterious analytical techniques used in Bioinformatics and Computational Biology in a simple way. Linear Mixed Model (also called Linear Mixed Effects Model) is widely used in Life Sciences, there are many tutorials showing how to run the model in R, however it is sometimes unclear how exactly the Random Effects parameters are optimized in the likelihood maximization procedure. In my previous post How Linear Mixed Model Works I gave an introduction to the concepts of the model, and in this tutorial we will derive and code the Linear Mixed Model (LMM) from scratch applying the Maximum Likelihood (ML) approach, i.e. we will use plain R to code LMM and compare the output with the one from lmer and lme R functions. The goal of this tutorial is to explain LMM “like for my grandmother” implying that people with no mathematical background should be able to understand what LMM does under the hood.
这是生命科学的数学统计和机器学习专栏中的第18条文章,我试图以一种简单的方式来解释一些在生物信息学和计算生物学中使用的神秘分析技术。 线性混合模型 (也称为线性混合效应模型)在生命科学中被广泛使用,有许多教程展示了如何在R中运行模型,但是有时不清楚在似然最大化过程中如何精确优化随机效应参数。 在我以前的文章《线性混合模型的工作原理》中,我介绍了模型的概念,在本教程中,我们将使用最大似然(ML)方法从头获得并编码线性混合模型(LMM),即我们将使用普通R编码LMM并将输出与lmer和lme R函数的输出进行比较。 本教程的目的是“像祖母一样”解释LMM,这意味着没有数学背景的人应该能够理解LMM 在幕后的工作 。
玩具数据集 (Toy Data Set)
Let us consider a toy data set which is very simple but still keeps all necessary elements of the typical setup for Linear Mixed Modelling (LMM). Suppose we have only 4 data points / samples: 2 originating from Individual #1 and the other 2 coming from Individual #2. Further, the 4 points are spread between two conditions: untreated and treated. Let us assume we measure a response (Resp) of each individual to the treatment, and would like to address whether the treatment resulted in a significant response of the individuals in the study. In other words, we are aiming to implement something similar to the paired t-test and assess the significance of treatment. Later we will relate the outputs from LMM and paired t-test and show that they are indeed identical. In the toy data set, 0 in the Treat column implies “untreated”, and 1 means “treated”. First, we will use a naive Ordinary Least Squares (OLS) linear regression that does not take relatedness between the data points into account.
让我们考虑一个非常简单的玩具数据集 ,但它仍然保留了线性混合建模(LMM)典型设置的所有必要元素。 假设我们只有4个数据点 /样本 :2 个数据源于#1个人 ,另外2 个数据源于#2个人 。 此外,这四个点分布在两个条件之间: 未处理和已处理 。 让我们假设我们测量了每个个体对治疗的React( Resp ),并想说明治疗是否导致研究中个体的显着React。 换句话说,我们的目标是实施类似于 配对t检验的方法,并评估治疗的重要性。 稍后,我们将把LMM和配对t检验的输出相关联,并证明它们确实是 相同的 。 在玩具的数据集,0在款待列意味着“未处理”,1分表示“经处理的”。 首先,我们将使用朴素的普通最小二乘(OLS) 线性回归 ,该回归不考虑数据点之间的相关性。
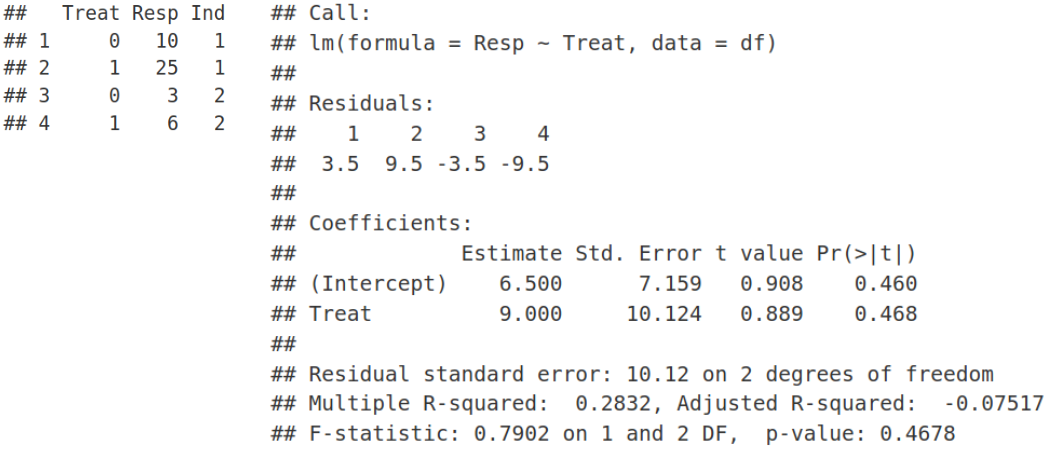
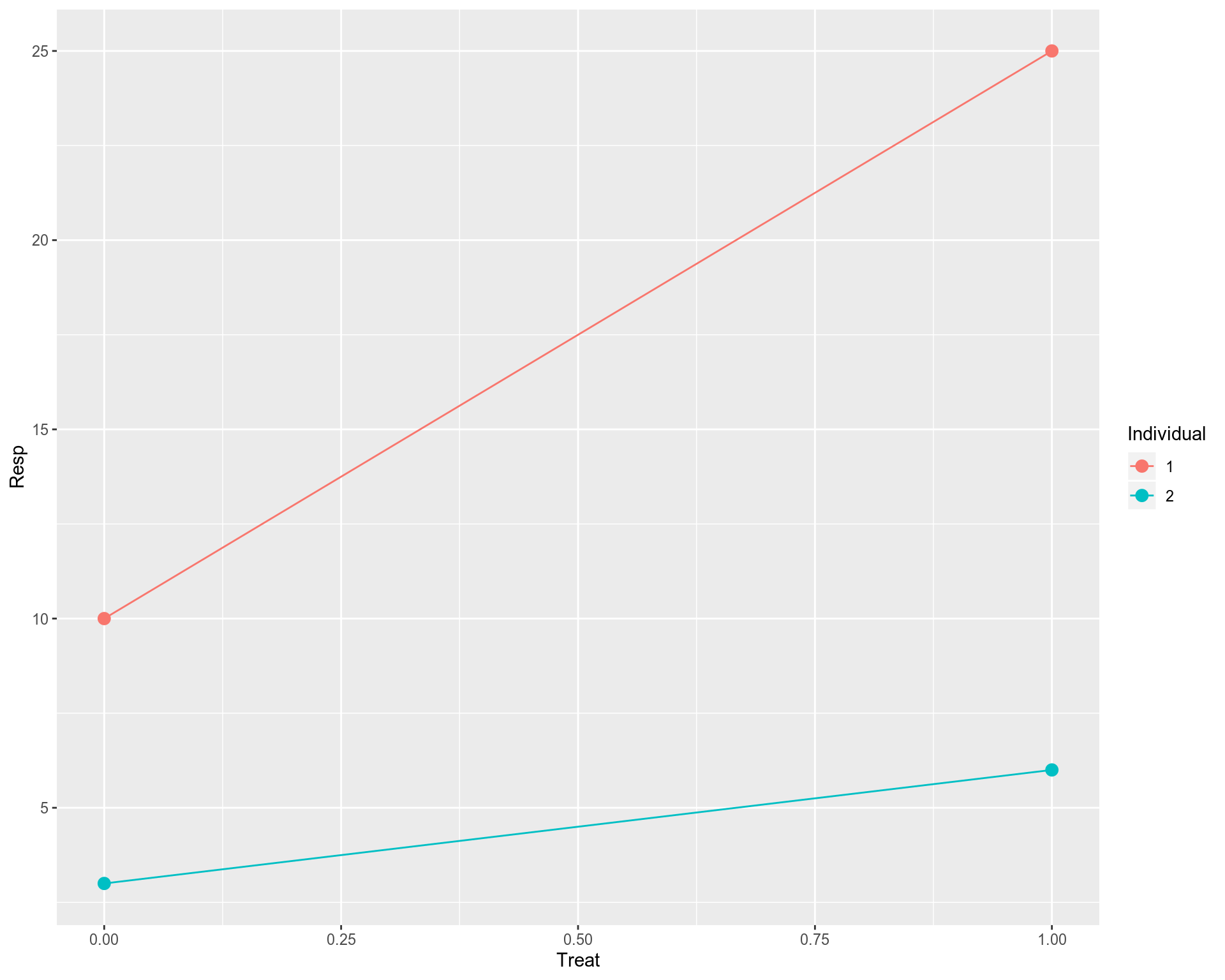
Technically it works, however, this is not a good fit, we have a problem here. Ordinary Least Squares (OLS) linear regression assumes that all observations (data points on the plot) are independent, that should result in uncorrelated and hence normally distributed residuals. However, we know that the data points on the plot belong to 2 individuals, i.e. 2 points for each individual. In principal, we can fit a linear model for each individual separately. However, this is not a good fit either. We have two points for each individual, so too few to make a reasonable fit for each individual. In addition, as we saw previously individual fits do not say much about the overall / population profile as some of them may have opposite behavior compared to the rest of individual fits.
从技术上讲,它可以正常工作,但是,这不是一个很好的选择, 我们 在这里 遇到了问题 。 普通最小二乘(OLS)线性回归假设所有观测值(图中的数据点)都是独立的 ,这将导致不相关且因此呈正态分布的残差 。 但是,我们知道图中的数据点属于2个个体,即每个个体2个点。 原则上,我们可以为每个人 分别拟合线性模型。 但是,这也不是一个很好的选择。 每个人都有两个要点,因此太少而不能合理地适合每个人。 此外,正如我们之前看到的那样,个体拟合并没有对总体/人口状况说太多,因为与其他个体拟合相比,其中一些可能具有相反的行为。
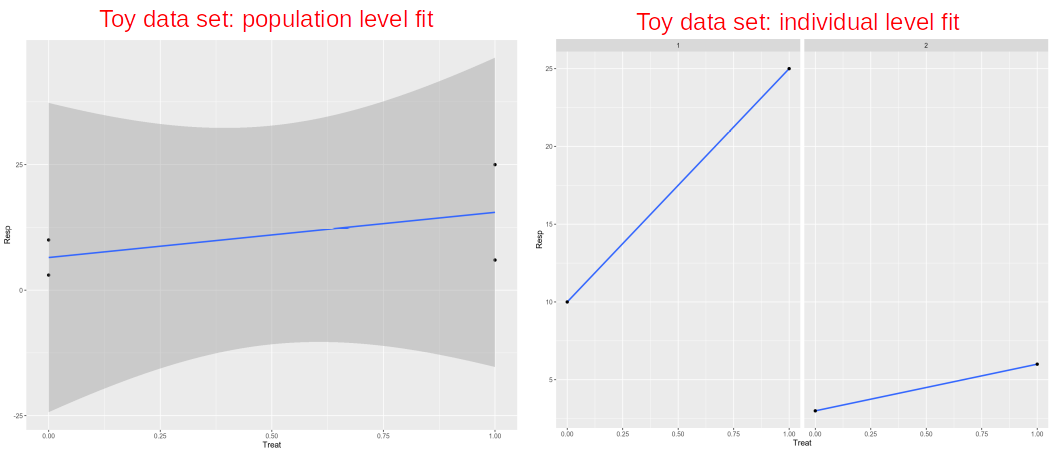
In contrast, if we want to fit all the four data points together we will need to somehow account for the fact that they are not independent, i.e. two of them belong to the Individual #1 and two belong to the Individual #2. This can be done within the Linear Mixed Model (LMM) or a paired test, e.g. paired t-test (parametric) or Mann-Whitney U test (non-parametric).
相反,如果我们想将所有四个数据点 拟合 在一起 ,则需要以某种方式说明它们不是独立的 ,即其中两个属于个人#1,两个属于个人#2。 这可以在线性混合模型(LMM)或配对检验中完成,例如配对t检验 (参数)或Mann-Whitney U检验 (非参数)。
具有Lmer和Lme的线性混合模型 (Linear Mixed Model with Lmer and Lme)
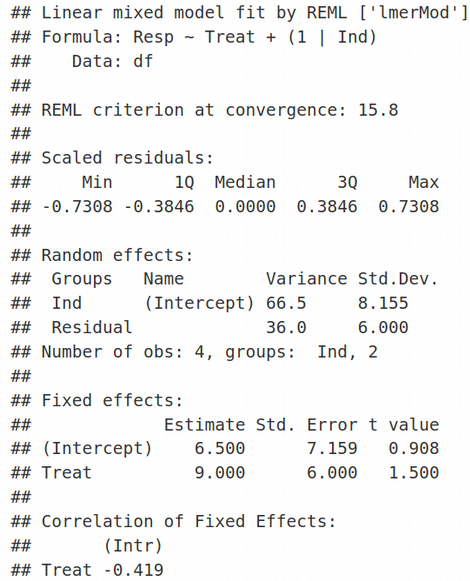
We use LMM when there is a non-independence between observations. In our case, the observations cluster within individuals. Let us apply LMM with Fixed Effects for slopes and intercepts and Random Effects for intercepts, this will result in adding a (1 | Ind) term to the Resp ~ Treat formula:
当观测值之间存在非独立性时,我们使用LMM。 在我们的案例中,观察结果聚集在个人内部。 让我们将LMM与“固定效应”应用于斜率和截距,将“ 随机效应”应用于截距 ,这将导致在Resp〜Treat公式中添加(1 | Ind)项:
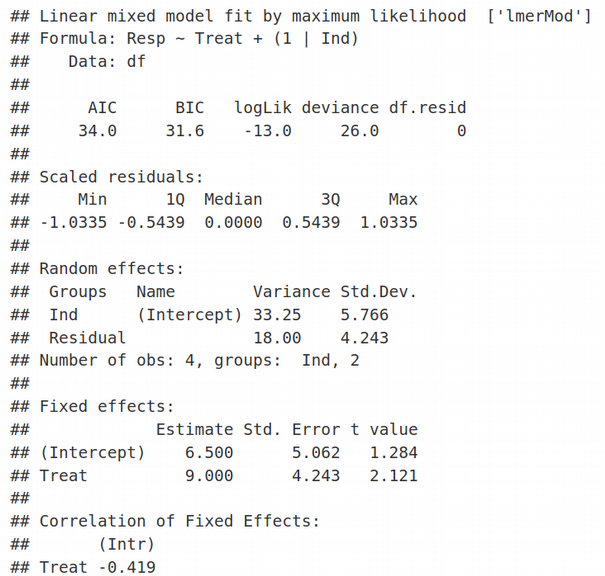
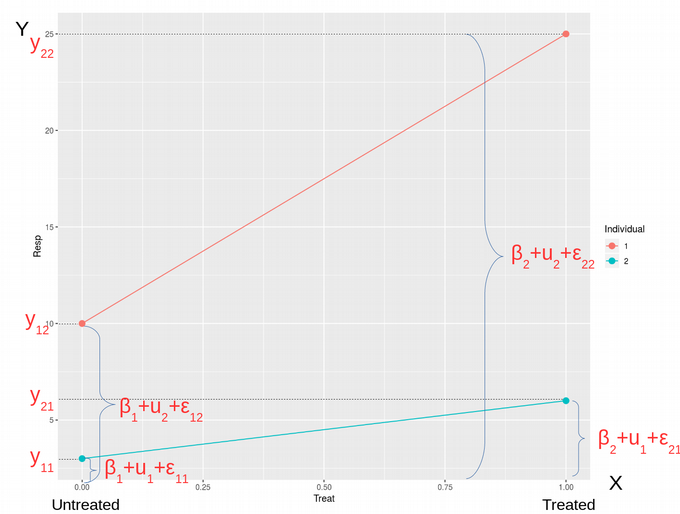
Here REML=FALSE simply means that we are using the traditional Maximum Likelihood (ML) optimization and not Restricted Maximum Likelihood (we will talk about REML another time). In the Random Effects section of the lmer output, we see estimates for 2 parameters of minimization: residual variance corresponding to the standard deviation (Std.Dev.) of 4.243, and the random effects (shared between individuals) variance associated with the Intercept with the standard deviation of 5.766. Similarly, in the Fixed Effects section of the lmer output we can see two estimates for: 1) Intercept equal to 6.5, and 2) Slope / Treat equal to 9. Therefore, we have 4 parameters of optimization that correspond to 4 data points. The values of Fixed Effects make sense if we look at the very first figure in the Toy Data Set section and realize that the mean of two values for untreated samples is (3 + 10) / 2 =6.5, we will denote it as β1, and the mean of treated samples is (6 + 25) / 2 = 15.5, let us denote it as β2. The latter would be equivalent to 6.5 + 9, i.e. the estimate for the Fixed Effect of Intercept (=6.5) plus the estimate for the Fixed Effect of Slope (=9). Here, we pay attention to the exact values of Random and Fixed effects because we are going to reproduce them later when deriving and coding LMM.
这里REML = FALSE只是意味着我们使用的是传统的最大似然(ML)优化,而不是受限的最大似然 (我们将在下一次讨论REML)。 在lmer输出的“随机效应”部分中,我们看到了两个最小化参数的估计值:与4.243的标准偏差(Std.Dev。)相对应的剩余方差 ,以及与截距相关的随机效应(在个体之间共享)方差标准偏差为5.766。 同样,在lmer输出的“固定效果”部分中,我们可以看到两个估计值:1)截距等于6.5,和2)斜率/对待等于9。因此,我们有4个优化参数对应于4个数据点。 如果我们看一下“玩具数据集”部分的第一个数字,并且意识到未处理的样本的两个值的平均值为(3 + 10)/ 2 = 6.5,则固定效果的值就有意义,我们将其表示为β1 ,并且处理后样本的平均值为(6 + 25)/ 2 = 15.5,我们将其表示为β2 。 后者等于6.5 + 9,即截距固定效应的估计值(= 6.5)加上坡度固定效应的估计值(= 9)。 在这里,我们注意随机和固定效果的确切值 ,因为稍后将在派生和编码LMM时重现它们。
By default, lme4 R package and lmer R function do not provide measures of statistical significance such as p-values, however if you still would like to have a p-value of your LMM fit, it is possible to use lme function from the nlme R package:
默认情况下, lme4 R包和lmer R函数不提供统计意义的度量 ,例如p值,但是,如果您仍然希望LMM拟合的p值 ,则可以使用nlme中的 lme函数R包:
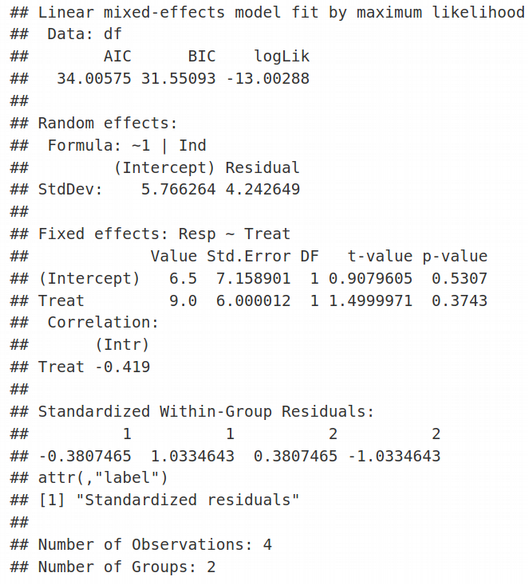
Again, here we have Random Effects for Intercept (StdDev = 5.766264) and Residual (StdDev = 4.242649), and Fixed Effects for Intercept (Value = 6.5) and Slope / Treat (Value = 9). Quite interesting, the standard errors of Fixed Effects and hence their t-values (t-value=1.5 for Treat) do not agree between lmer and lme. However, if we demand REML=TRUE in the lmer function, the Fixed Effects statistics including t-values are identical between lme and lmer, however the Random Effects statistics are different.
再次,这里我们具有截取的随机效应( StdDev = 5.766264 )和残差( StdDev = 4.242649 ),以及截距的固定效应(值= 6.5)和斜率/治疗(值= 9)。 非常有趣的是,固定效应的标准误差及其t值(“治疗”的t值= 1.5)在lmer和lme之间不一致。 但是,如果我们在lmer函数中要求REML = TRUE,则lme和lmer之间的固定效应统计量(包括t值)是相同的 ,但是随机效应统计量却不同。
This is the difference between the Maximum Likelihood (ML) and Restricted Maximum Likelihood (REML) approaches that we will cover next time.
这是下一次我们将讨论的最大可能性(ML)和受限最大可能性(REML)方法之间的差异。
LMM和配对T检验之间的关系 (Relation Between LMM and Paired T-Test)
Previously, we said that LMM is a more complex form of a simple paired t-test. Let us demonstrate that for our toy data set they do give identical outputs. On the way, we will also understand the technical difference between paired and un-paired t-tests. Let us first run the paired t-test between the treated and un-treated groups of samples taking into account the non-independence between them:
之前,我们说过LMM是简单配对t检验的更复杂形式。 让我们证明,对于我们的玩具数据集,它们确实提供了相同的输出。 在途中,我们还将了解配对和非配对t检验之间的技术差异。 考虑到样本之间的非独立性,让我们首先在已处理样本组和未处理样本组之间进行配对t检验:

We can see that the t-value=1.5 and p-value = 0.3743 reported by the paired t-test are identical to the ones obtained by LMM using the nlme function or lmer with REML = TRUE. The reported by the paired t-test statistic “mean of the differences = 9” also agrees with the Fixed Effect estimates from lmer and nlme, remember we had the Treat Estimate = 9 that was simply the difference between the means of the treated and untreated samples.
我们可以看到,配对t检验报告的t值= 1.5和p值= 0.3743 与LMM使用nlme函数或lmer的REML = TRUE获得的值相同。 配对t检验统计数据所报告的“差异均值= 9”也与lmer和nlme的“固定效应”估算值一致,请记住,我们的“治疗估算值” = 9,这仅仅是治疗与未治疗方法之间的差异样品。
Now, what is the paired t-test exactly doing? Well, the idea of the paired t-test is to make the setup look like a one-sample t-test where values in one group are tested for significant deviation from zero, which is a sort of the mean of the second group. In other words, we can view a paired t-test as if we shift the intercepts of the individual fits (see the very first figure) or the mean values of the untreated group down to zero. In a simple way, this would be equivalent to subtracting untreated Resp values from the treated ones, i.e. transforming the Resp variable to Resp_std (standardized Response) as shown below, and then performing an un-paired t-test on the Resp_std variable instead of Resp:
现在,配对t检验到底在做什么? 好吧,配对t检验的想法是使设置看起来像一个单样本t检验 ,其中一组中的值被测试是否与零显着偏离 ,这是第二组的平均值。 换句话说,我们可以查看成对的t检验,就好像我们将各个拟合的截距(参见第一个数字)或未处理组的平均值减小到零一样 。 以一种简单的方式,这等效于从已处理的值中减去未处理的Resp值,即如下所示将Resp变量转换为Resp_std (标准响应),然后对Resp_std变量执行未配对的t检验,而不是响应:

We observe that the values of Response became 0 for Treat = 0, i.e. untreated group, while the Response values of the treated group (Treat=1) are reduced by the values of the untreated group. Then we simply used the new Resp_std variable and ran an un-paired t-test, the result is equivalent to running paired t-test on the original Resp variable. Therefore, we can summarize that LMM reproduces the result of the paired t-test but allows for much more flexibility, for example, not only two (like for t-test) but multiple groups comparison etc.
我们观察到,对于Treat = 0(即未治疗组),Response的值变为0,而治疗组(Treat = 1)的Response值减少了未经治疗组的值。 然后,我们只需使用新的Resp_std变量并运行未配对的t检验,结果就相当于在原始Resp变量上运行配对的t检验。 因此,我们可以总结出,LMM再现了配对t检验的结果,但是允许更大的灵活性,例如,不仅两个(像t检验一样),而且可以进行多组比较等。
线性混合模型背后的数学 (Math Behind Linear Mixed Model)
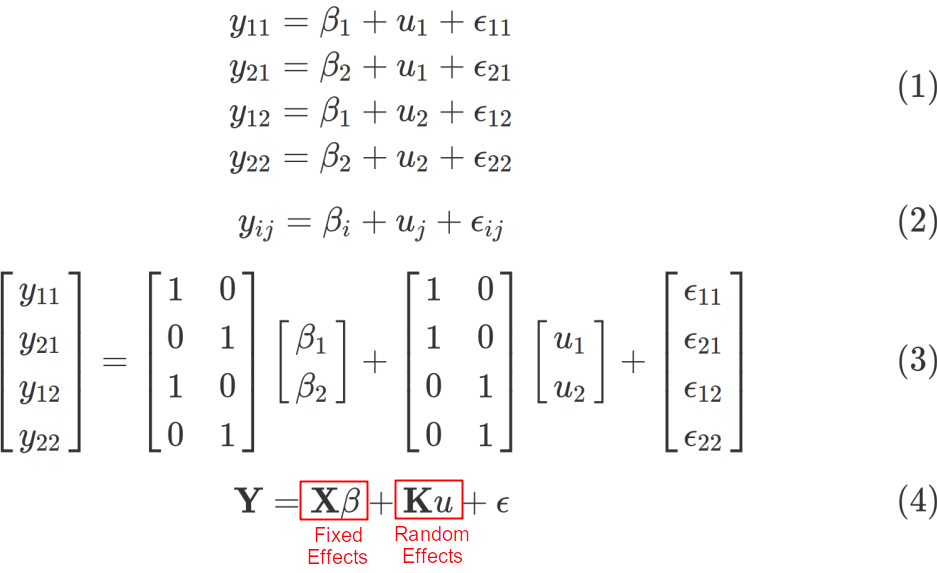
Let us now try to derive a few LMM equations using our toy data set. We will again have a look at the 4 data points and make some mathematical notations accounting for treatment effects, β, which is nothing else than Fixed Effects, and the block-wise structure u due to points clustering within two individuals, which is actually the Random Effects contribution. We are going to express the Response (Resp) coordinates y in terms of β and u parameters.
现在让我们尝试使用玩具数据集导出一些LMM方程 。 我们将再次看看4个数据点,并提出一些数学符号占治疗效果,β,这只不过是固定效应一样 ,并逐块结构U由于分两个个体内成簇, 而这 实际上 是 随机效应贡献 。 我们将根据β和u参数来表示响应(Resp)坐标y 。
Here, β1 is the Response of the individuals in the Untreated state, while β2 is the Response on the Treatment. One can also say, that β1 is the mean of the untreated samples while β2 is the mean of the treated samples. The variables u1 and u2 are block variables accounting for effects specific to Individual #1 and Individual #2, respectively. Finally, ϵij ∼ N(0, σ²) is the Residual error, i.e. the error we can’t model and can only try to minimize it as the goal of the Maximum Likelihood optimization problem. Therefore, we can write down the Response variable y as a combination of parameters β, u, i.e. Fixed and Random Effects, and ϵ as Eq. (1). In a general form, this system of algebraic equations can be rewritten as Eq. (2), where the index i = 1, 2 corresponds to treatment effects and j = 1, 2 describes individual effects. We can also express this system of equations in the matrix form Eq. (3). Therefore we arrive to the following famous matrix form of LMM which is shown in all textbooks but not always properly explained, Eq. (4).
在此, β1是未治疗状态的个体的React,而β2是对治疗的React 。 也可以说, β1是未处理样品的平均值,而β2是已处理样品的平均值。 变量u1和u2是块变量,分别说明特定于个人#1和个人#2的影响。 最后, ϵij〜N(0,σ²)是残差误差 ,即我们无法建模的误差,只能将其最小化作为最大似然优化问题的目标。 因此,我们可以将Response变量y记为参数 β , u的组合 ,即固定 效应和随机效应 ,以及ϵ 如式 (1)。 通常,该代数方程组可以重写为等式。 (2),其中索引i = 1、2对应于治疗效果,而j = 1、2描述单个效果。 我们还可以以矩阵形式Eq表示此方程组。 (3)。 因此,我们得出以下著名的LMM矩阵形式,该形式在所有教科书中均已显示,但并非总是正确解释。 (4)。
Here, X is called the design matrix and K is called the block matrix, it codes the relationship between the data points, i.e. whether they come from related individuals or even from the same individual like in our case. It is important to note that the treatment is modeled as a fixed effect because the levels treated-untreated exhaust all possible outcomes of treatment. In contrast, the block-wise structure of the data is modeled as a Random Effect since the individuals were sampled from population, and might not correctly represent the entire population of individuals. In other words, there is an error associated with the random effects, i.e. uj ∼ N(0, σs²), while fixed affects are assumed to be error free. For example, sex is usually modeled as a Fixed Effect because it is usually assumed to have only two levels (males, females), while batch-effects in Life Sciences should be modeled as Random Effects because potentially additional experimental protocols or labs would produce many more, that is many levels, systematic differences between samples that confound the data analysis. As a rule of thumb one could think that Fixed Effects should not have many levels, while Random Effects are typically multi-level categorical variables where the levels represent just a sample of all possibilities but not all of them.
在这里, X称为设计矩阵 , K称为块矩阵 ,它对数据点之间的关系进行编码,即数据点是来自相关个人,还是像我们一样来自同一个人。 重要的是要注意,将治疗建模为固定效果,因为未经处理的水平会耗尽所有可能的治疗结果。 相比之下,数据的逐块结构被建模为随机效应,因为个体是从总体中采样的 ,因此可能无法正确代表整个个体。 换句话说,存在与随机效应相关的误差,即uj〜N(0,σs²) ,而固定效应则假定为无误差。 例如,通常将性别建模为固定效应,因为通常假定性别只有两个级别(男性,女性) ,而生命科学中的批量效应应建模为随机效应,因为可能会通过其他实验方案或实验室产生很多效应更重要的是,样本之间存在许多层次上的系统差异,这混淆了数据分析。 根据经验,固定效应不应有多个级别,而随机效应通常是多级类别变量,其中级别仅代表所有可能性的样本,但并不代表所有可能性。
Let us proceed with deriving the mean and the variance of the data points Y. Since both the Random Effect error and the Residual error come from Normal distribution with zero mean, while the non-zero component in E[Y] originates from the Fixed Effect, we can express the expected value of Y as Eq. (5). Next, the variance of the Fixed Effect term is zero, as Fixed Effects are assumed to be error free, therefore, for the variance of Y we obtain Eq. (6).
让我们继续推导数据点 Y的均值和方差 。 由于随机效应误差和残余误差均来自均值为零的正态分布,而E [ Y ]中的非零分量源自固定效应,因此我们可以将Y的期望值表示为Eq。 (5)。 接下来,固定效果项的方差为零,因为固定效果被假定为无误差,因此,对于Y的方差,我们得到等式。 (6)。
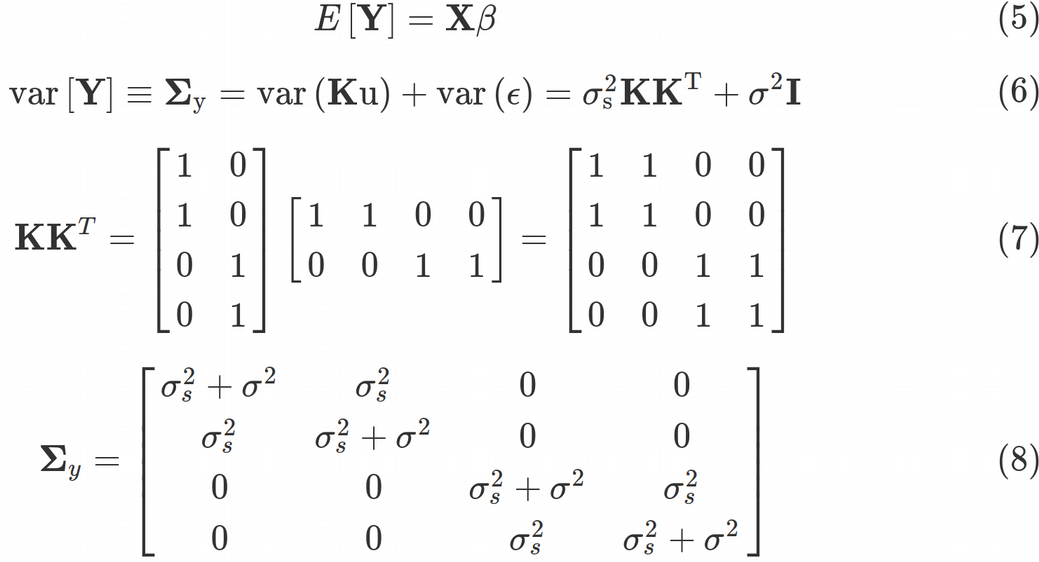
Eq. (6) was obtained by taking into account that var(Ku)=K*var(u)*K^T and var(ϵ) = σ²*I and var(u)= σs²*I, where I is a 4 x 4 identity matrix. Here, σ² is the Residual variance (unmodeled/unreduced error), and σs² is the random Intercept effects (shared across data points) variance. The matrix in front of σs² is called the kinship matrix and is given by Eq. (7). The kinship matrix codes all relatedness between data points. For example, some data points may come from genetically related people, geographic locations in close proximity, some data points may come from technical replicates. Those relationships are coded in the kinship matrix. Thus, the variance-covariance matrix of the data points from Eq. (6) takes the ultimate form of Eq. (8). Once we have obtained the variance-covariance matrix, we can continue with optimization procedure of the Maximum Likelihood function that requires the variance-covariance.
等式 (6)通过考虑到变种(K U)= K *变种(U)* K ^ T和VAR(ε)=σ²* I和变种(U)=σ秒²* I,其中I是获得一个4 x 4的单位矩阵 。 这里,σ是² 残余方差 (未建模/未还原的错误),以及强度σs²是随机拦截效果(跨数据点共享)方差 。 σs²前面的矩阵称为亲属矩阵 ,由等式给出。 (7)。 亲属关系矩阵编码数据点之间的所有相关性。 例如,某些数据点可能来自与遗传相关的人,地理位置非常接近,某些数据点可能来自技术复制。 这些关系在亲属关系矩阵中编码。 因此,来自等式的数据点的方差-协方差矩阵。 (6)采用等式的最终形式。 (8)。 一旦获得方差-协方差矩阵,我们就可以继续进行需要方差-协方差的最大似然函数的优化过程。
LMM来自最大似然(ML)原理 (LMM from Maximum Likelihood (ML) Principle)
Why did we spend so much time deriving the variance-covariance matrix and what does it have to do with the linear regression? It turns out that the whole concept of fitting a linear model, as well as many other if not all concepts of traditional Frequentist statistics, comes from the Maximum Likelihood (ML) principle. For this purpose, we need to maximize the Multivariate Gaussian distribution function with respect to parameters β1, β2, σs² and σ², Eq. (9).
为什么我们要花费大量时间来得出方差-协方差矩阵,它与线性回归有什么关系? 事实证明, 拟合线性模型的整个概念以及传统频率统计的许多其他(如果不是全部)概念都来自最大似然(ML) 原理 。 为此,我们需要针对参数β1 , β2 , σs²和σ² ,等式最大化多元高斯 分布函数 。 (9)。
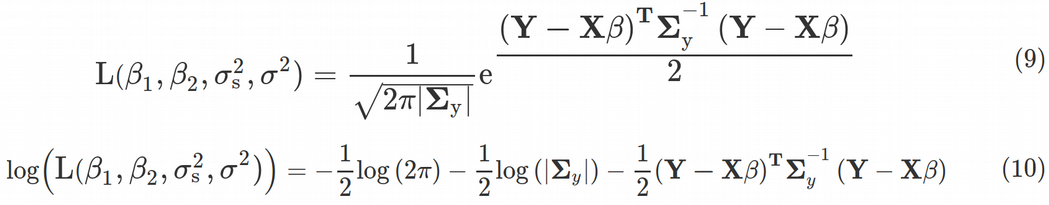
Here |Σy| denotes the determinant of the variance-covariance matrix. We see that the inverse matrix and determinant of the variance-covariance matrix are explicitly included into the Likelihood function, this is why we had to compute its expression via the random effects variance σs² and residual variance σ². Maximization of the Likelihood function is equivalent to minimization of the log-likelihood function, Eq. (10).
在这里 ΣY | 表示方差-协方差矩阵的行列式。 我们看到方差-协方差矩阵的逆矩阵和行列式明确包含在似然函数中,这就是为什么我们必须通过随机效应方差 σs²和残差方差 σ²计算其表达式的原因。 似然函数的最大化等效于对数似然函数 Eq的最小化 。 (10)。
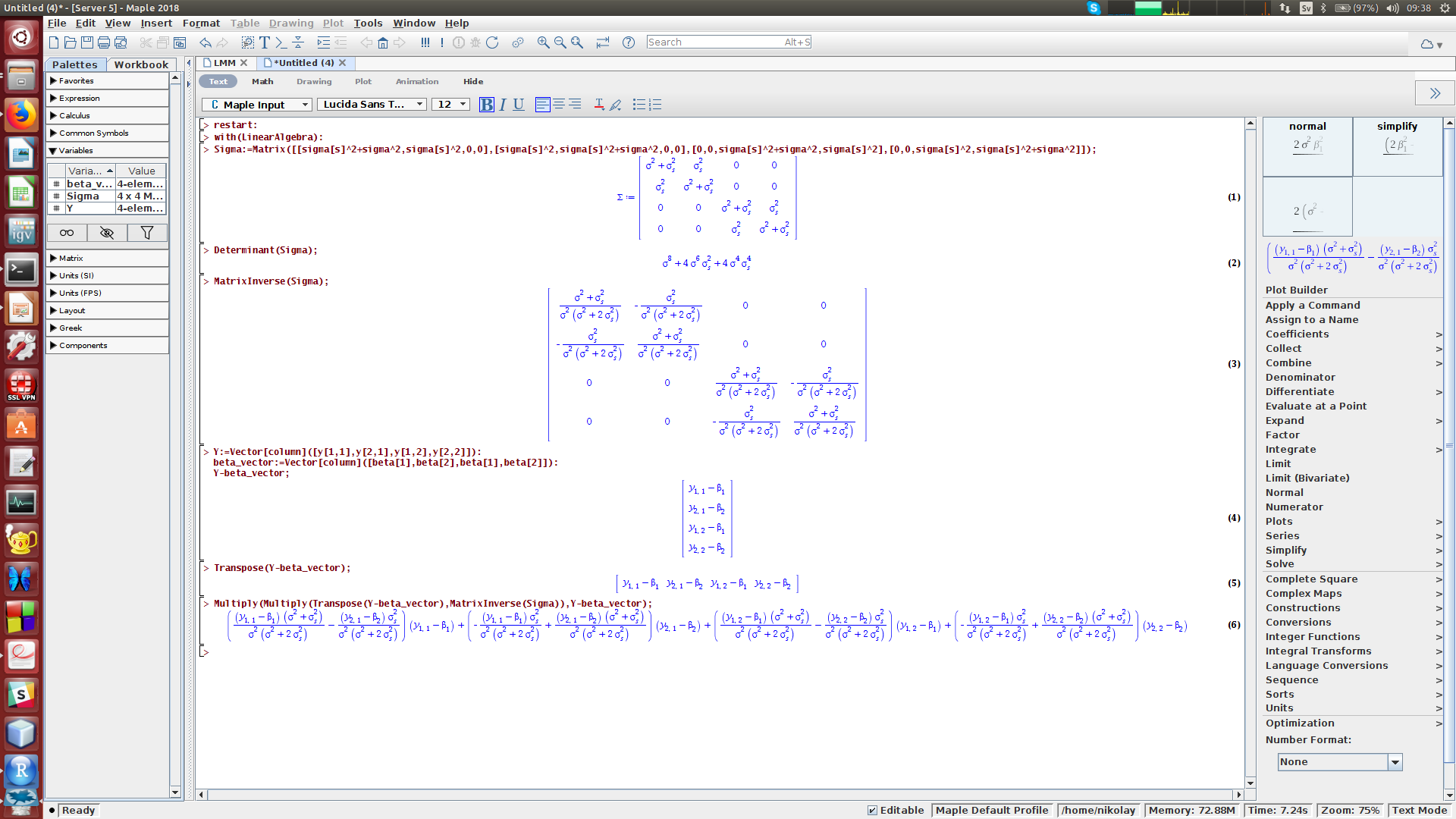
We will need to perform a tedious symbolic derivation of the determinant of the variance-covariance matrix, the inverse variance-covariance matrix and the product of the inverse variance-covariance matrix with Y−Xβ terms. To my experience, this is hard to do in R / Python, however we can use Maple (or similarly Mathematica or Matlab) for making symbolic calculations, and derive the expressions for determinant and inverse of the variance-covariance matrix:
我们将需要对方差-协方差矩阵, 逆方差-协方差矩阵和具有Y - Xβ 项的 方差-协方差矩阵的乘积执行繁琐的符号推导 。 以我的经验,这在R / Python中很难做到,但是我们可以使用Maple (或类似的 Mathematica 或 Matlab )进行符号计算,并导出方差-协方差矩阵的行列式和逆式的表达式:
Using Maple we can obtain the determinant of the variance-covariance matrix as Eq. (11). Next, the last term in Eq. (10) for log-likelihood takes the form of Eq. (12).
使用Maple,我们可以获得方差-协方差矩阵的行列式。 (11)。 接下来,等式中的最后一项。 (10)对数似然采用等式的形式。 (12)。
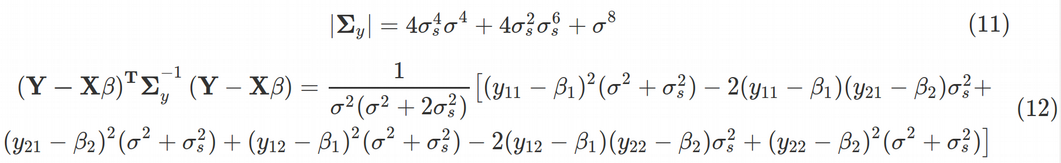
Now we are ready to perform the numeric minimization of the log-likelihood function with respect to β1, β2, σs² and σ² using the optim R function:
现在,我们准备使用优化 R函数对β1 , β2 , σs²和σ²执行对数似然函数的数值最小化:
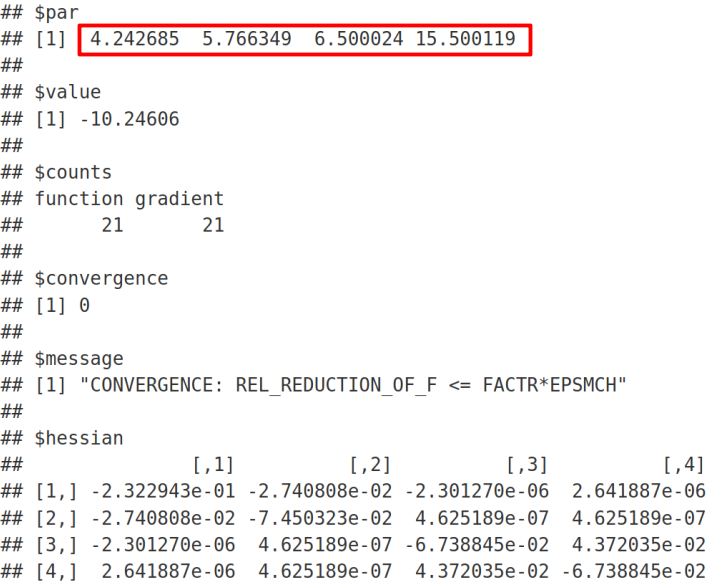
We can see that the minimization algorithm has successfully converged since we got the “convergence = 0” message. In the output, σ=4.242640687 is the residual standard deviation, which exactly reproduces the result from lme and lmer (with REML = FALSE). By analogy, σs=5.766281297 is the shared standard deviation that again exactly reproduces the corresponding Random Effects Intercept outputs from lme and lmer (with REML = FALSE) functions. As expected, the Fixed Effect β1 = 6.5 is the mean of the untreated samples in agreement with the Intercept Fixed Effect Estimate from lmer and lme. Next, β2 = 15.5 is the mean of treated samples, which is the Intercept Fixed Effect Estimate (= 6.5) plus the Slope / Treat Fixed Effect Estimate (= 9) from lmer and lme R functions.
我们可以看到,自从收到“ convergence = 0”消息以来,最小化算法已成功收敛 。 在输出中, σ= 4.242640687是残余标准偏差 ,它精确地再现了 lme和lmer 的结果 (REML = FALSE)。 以此类推, σs= 5.766281297是共享的标准偏差 ,该偏差再次精确地再现了来自lme和lmer(具有REML = FALSE)功能的相应的“随机效果拦截”输出。 正如预期的那样,固定效应β1= 6.5的平均值与固定效应估算和11聚物伦敦金属交易所拦截协议未经处理的样品。 接下来, β2= 15.5是已处理样品的平均值,它是截距固定效果估计值(= 6.5)加上来自lmer和lme R函数的斜率/处理固定效果估计值(= 9)。
Fantastic job! We have successfully reproduced the Fixed Effects and Random Effects outputs from lmer / lme functions by deriving and coding the Linear Mixed Model (LMM) from scratch!
很棒的工作! 通过从头开始推导和编码线性混合模型(LMM),我们已经成功地从lmer / lme函数复制了固定效果和随机效果输出!
摘要 (Summary)
In this article, we have learnt how to derive and code a Linear Mixed Model (LMM) with Fixed and Random Effects on a toy data set. We covered the relation between LMM and the paired t-test, and reproduced the Fixed and Random Effects parameters from lmer and lme R functions.
在本文中,我们学习了如何在 玩具数据集 上导出具有 固定和随机效应的线性混合模型(LMM)并进行编码。 我们介绍了LMM和配对t检验之间的关系,并从lmer和lme R函数复制了“固定效应”和“随机效应”参数。
In the comments below, let me know which analytical techniques from Life Sciences seem especially mysterious to you and I will try to cover them in the future posts. Check the codes from the post on my Github. Follow me at Medium Nikolay Oskolkov, in Twitter @NikolayOskolkov and do connect in Linkedin. In the next post, we are going to cover the difference between the Maximum Likelihood (ML) and Restricted Maximum Likelihood (REML) approaches, stay tuned.
在下面的评论中,让我知道生命科学的哪些分析技术对您来说似乎特别神秘 ,我将在以后的文章中尝试介绍它们。 在我的Github上检查帖子中的代码。 跟随我在中型Nikolay Oskolkov,在Twitter @NikolayOskolkov上进行连接,并在Linkedin中进行连接。 在下一篇文章中,我们将介绍 请密切关注最大可能性(ML)和限制最大可能性(REML)方法之间的差异。
翻译自: https://towardsdatascience.com/linear-mixed-model-from-scratch-f29b2e45f0a4
一般线性模型和混合线性模型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/388424.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

《企业私有云建设指南》-导读

vs2005的webbrowser控件如何接收鼠标事件
![[TimLinux] Python 迭代器(iterator)和生成器(generator)](http://pic.xiahunao.cn/[TimLinux] Python 迭代器(iterator)和生成器(generator))
[TimLinux] Python 迭代器(iterator)和生成器(generator)

太原冶金技师学院计算机系,山西冶金技师学院专业都有什么

海南首例供港造血干细胞志愿者启程赴广东捐献

如何击败Python的问题

KindEditor解决上传视频不能在手机端显示的问题

湖北经济学院的计算机是否强,graphics-ch11-真实感图形绘制_湖北经济学院:计算机图形学_ppt_大学课件预览_高等教育资讯网...

ARP攻击网络上不去,可以进行mac地址绑定

《独家记忆》见面会高甜宠粉 张超现场解锁隐藏技能

计算机软件技术基础fifo算法,软件技术基础真题
)
NOI 2016 优秀的拆分 (后缀数组+差分)

多元线性回归 python_Python中的多元线性回归

关于apache和tomcat集群,线程是否占用实验

爬虫之数据解析的三种方式

相对于硬件计算机软件就是,计算机的软件是将解决问题的方法,软件是相对于硬件来说的...

数据冒险控制冒险_劳动生产率和其他冒险

如何把一个java程序打包成exe文件,运行在没有java虚

Java后端WebSocket的Tomcat实现
