com编程创建快捷方式中文
Recently, I was in need of an image for our blog and wanted it to have some wow effect or at least a better fit than anything typical we’ve been using. Pondering over ideas for a while, word cloud flashed in my mind. 💡Usually, you would just need a long string of text to generate one, but I thought of parsing our entire blog data to see if anything interesting pops out and to also get the holistic view of the keywords our blog uses in its entirety. So, I took this as a weekend fun project for myself.
最近,我在博客中需要一个图片,希望它具有一定的效果或至少比我们一直在使用的典型图片更适合 。 思考了一会儿,词云在我脑海中闪过。 💡通常,您只需要一个长文本字符串即可生成一个文本字符串,但是我想解析整个博客数据,以查看是否弹出了一些有趣的东西,并获得我们博客整体使用的关键字的整体视图。 因此,我将此作为自己的周末娱乐项目。
PS: Images have a lot of importance in marketing. Give it quality!👀
PS:图像在营销中非常重要。 给它质量!👀
弄脏您的手: (Getting your hands dirty:)
Our blog is hosted on Ghost and it allows us to export all the posts and settings into a single, glorious JSON file. And, we have in-built json package in python for parsing JSON data. Our stage is set. 🤞
我们的博客托管在Ghost上 并且它允许我们将所有帖子和设置导出到一个光荣的JSON文件中。 并且,我们在python中有内置的json包,用于解析JSON数据。 我们的舞台已经准备好了。 🤞
For other popular platforms like WordPress, Blogger, Substack, etc. it could be one or many XML files, you might need to switch the packages and do the groundwork in python accordingly.
对于其他流行的平台,例如WordPress,Blogger,Substack等,它可能是一个或多个XML文件,您可能需要切换软件包并相应地在python中做基础。
Before you read into that JSON in python, you should get the idea of how it’s structured, what you need to read, what you need to filter out, etc. For that, use some JSON processor to pretty print your json file, I’d used jqplay.org and it helped me figure out where my posts are located ➡ data['db'][0]['data']['post']
在用python阅读JSON之前,您应该了解它的结构,需要阅读的内容,需要过滤的内容等。为此,使用一些JSON处理器漂亮地打印JSON文件,我d使用了jqplay.org ,它帮助我弄清楚了我的帖子所在的位置➡data data['db'][0]['data']['post']
Next, you’d like to call upon pd.json.normalize() to convert your data into a flat table and save it as a data frame.
接下来,您想调用pd.json.normalize()将数据转换为平面表并将其保存为数据框。
👉 Note: You should have updated version of pandas installed for
pd.json.normalize()to work as it has tweaked names in older versions.Also, keep the encoding as UTF-8, as otherwise, you’re likely to run into UnicodeDecodeErrors. (We have these bad guys: ‘\xa0’ , ‘\n’, and ‘\t’ etc.)👉注意:您应该已安装pandas的更新版本,以便
pd.json.normalize()可以正常运行,因为它已对旧版本中的名称进行了调整。此外,请保持编码为UTF-8,否则可能会遇到UnicodeDecodeErrors。 (我们有这些坏家伙:'\ xa0','\ n'和'\ t'等)
import pandas as pd
import jsonwith open('fleetx.ghost.2020-07-28-20-18-49.json', encoding='utf-8') as file:
data = json.load(file)
posts_df = pd.json_normalize(data['db'][0]['data']['posts'])
posts_df.head()Looking at the dataframe you can see that ghost is keeping three formats of the posts we created, mobiledoc (simple and fast renderer without an HTML parser), HTML and plaintext, and range of other attributes of the post. I choose to work with the plaintext version as it would require the least cleaning.
查看数据框,您可以看到ghost保留了我们创建的帖子的三种格式, mobiledoc (没有HTML解析器的简单快速渲染器),HTML和纯文本以及帖子的其他属性范围。 我选择使用纯文本版本,因为它需要最少的清理。
清洁工作: (The Cleaning Job:)
- Drop missing values (any blank post you might have) to not handicap your analysis while charting at some point later. We had one blog post in drafts with nothing in it. 🤷♂️ 删除丢失的值(您可能有任何空白的帖子),以便稍后在进行图表绘制时不会影响您的分析。 我们的草稿中只有一篇博文,没有任何内容。 ♂♂️
The plaintext of the posts had almost every possible unwanted character from spacing and tabs (\n, \xao, \t), to 14 marks from grammar punctuations (dot, comma, semicolon, colon, dash, hyphen,s etc.) and even bullet points. Replace all of them with whitespace.
帖子的纯文本几乎包含从空格和制表符(\ n,\ xao,\ t)到语法标点的14个标记(点,逗号,分号,冒号,破折号,连字符等)以及几乎所有可能不需要的字符,并且甚至是要点。 将它们全部替换为空格。
Next, I split up the words in each blog post under the plaintext column and then joined the resulting lists from each cell to have a really long list of words. This resulted in 34000 words; we have around 45 published blogs each having 700 words on average and a few more in drafts, so this works out 45*700=31500 words. Consistent!🤜
接下来,我将每个博客帖子中的单词都以纯文本形式拆分 列,然后将每个单元格的结果列表加入其中,以获得非常长的单词列表。 结果是34000个单词; 我们大约有45个已发布的博客,每个博客平均包含700个单词,草稿中还有几个单词,因此得出的结果是45 * 700 = 31500个单词。 一致!🤜
posts_df.dropna(subset=['plaintext'], axis=0, inplace=True)posts_df.plaintext = posts_df.plaintext.str.replace('\n', ' ')
.str.replace('\xa0',' ').str.replace('.',' ').str.replace('·', ' ')
.str.replace('•',' ').str.replace('\t', ' ').str.replace(',',' ')
.str.replace('-', ' ').str.replace(':', ' ').str.replace('/',' ')
.str.replace('*',' ')posts_df.plaintext = posts_df.plaintext.apply(lambda x: x.split())
words_list =[]
for i in range(0,posts_df.shape[0]):
words_list.extend(posts_df.iloc[i].plaintext)If you’re eager for results now, you can run collections.Counter on that words_list and get the frequency of each word to get an idea of how your wordcloud might look like.
如果您现在渴望获得结果,则可以在words_list上运行collections.Counter并获取每个单词的出现频率,以了解单词云的外观。
import collectionsword_freq = collections.Counter(words_list)
word_freq.most_common(200)Any guesses on what could be the most used word for a blog? 🤞If you said ‘the’, you’re right. For really long texts, the article ‘the’ is going to take precedence over any other word. And, not just ‘the’ there were several other prepositions, pronouns, conjunction, and action verbs in the top frequency list. We certainly don’t need them and, to remove them, we must first define them. Fortunately, wordcloud library that we will use to generate the wordcloud comes with default stopwords of its own but it’s rather conservative and has only 192 words. So, let’s head over to the libraries in Natural Language Processing (NLP) that do huge text processing and are dedicated to such tasks. 🔎
关于博客最常用的词有什么猜想? 🤞如果您说“ the”,那是对的。 对于非常长的文本,文章“ the”将优先于其他任何单词。 而且,不仅仅是“ the”,在最常见的频率列表中还有其他几个介词,代词,连词和动作动词。 我们当然不需要它们,并且要删除它们,我们必须首先定义它们。 幸运的是,我们将用于生成wordcloud的wordcloud库带有自己的默认停用词,但它相当保守,只有192个单词。 因此,让我们进入自然语言处理(NLP)中的库,这些库可以进行大量的文本处理并致力于此类任务。 🔎
- National Language Toolkit library (NLTK): It has 179 stopwords, that’s even lower than wordcloud stopwords collection. Don’t give it an evil eye for this reason alone, this is the leading NLP library in python. 国家语言工具包库(NLTK):它有179个停用词,甚至比wordcloud停用词集合还低。 不要仅仅因为这个原因就对它视而不见,这是python中领先的NLP库。
- Genism: It has 337 stopwords in its collection. Genism:它的集合中有337个停用词。
- Sci-kit learn: They also have a stopword collection of 318 words. 科学工具学习:他们也有318个单词的停用词集合。
- And, there is Spacy: It has 326 stopwords. 而且,还有Spacy:它有326个停用词。
I went ahead with the Spacy, you can choose your own based on your preferences.
我使用Spacy,您可以根据自己的喜好选择自己的。
但…。 😓 (But…. 😓)
This wasn’t enough! Still, there were words that won’t look good from a marketing standpoint, also we didn’t do the best cleaning possible. So, I’d put them in a text file (each word on a new line) and then read it and joined with the spacy’s stopwords list.
这还不够! 不过,从营销的角度来看,有些话看起来不太好,而且我们也没有做到最好的清洁效果。 因此,我将它们放在一个文本文件中(每个单词都换行),然后阅读并与spacy的停用词列表一起加入。
Instructions on setting up Spacy.
有关设置Spacy的说明 。
import spacynlp=spacy.load('en_core_web_sm')
spacy_stopwords = nlp.Defaults.stop_wordswith open("more stopwords.txt") as file:
more_stopwords = {line.rstrip() for line in file}final_stopwords = spacy_stopwords | more_stopwords设置设计工作室: (Setting up the design shop:)
Now that we have our re-engineered stopwords list ready, we’re good to invoke the magic maker ➡ the wordcloud function. Install the wordcloud library with pip command via Jupyter/CLI/Conda.
现在我们已经准备好重新设计的停用词列表,现在可以调用魔术制作器word wordcloud函数了。 通过Jupyter / CLI / Conda使用pip命令安装wordcloud库。
pip install wordcloudimport matplotlib.pyplot as plt
import wordcloud#Instantiate the wordcloud objectwc = wordcloud.WordCloud(background_color='white', max_words=300, stopwords=final_stopwords, collocations=False, max_font_size=40, random_state=42)# Generate word cloud
wc=wc.generate(" ".join(words_list).lower())# Show word cloud
plt.figure(figsize=(20,15))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# save the wordcloud
wc.to_file('wordcloud.png');Much of the above code block would be self-explanatory for python users, though let’s do a brief round of introduction:
上面的许多代码块对于python用户来说都是不言而喻的,尽管让我们做一轮简短的介绍:
background_color: background of your wordcloud, black and white is most common.background_color:您的wordcloud背景, 黑色和白色最为常见。max_words: maximum words you would like to show up in the wordcloud, default is 200.max_words:您想在wordcloud中显示的最大单词数,默认值为200。stopwords: set of stopwords to be eliminated from wordcloud.stopwords:从wordcloud中消除的停用stopwords集。collocations: Whether to include collocations (bigrams) of two words or not, default is True.collocations:是否包含两个单词的搭配词(字母组合图),默认值为True。
什么是二元组? (What are Bigrams?)
These are sequences of two adjacent words. Take a look at the below example.
这些是两个相邻单词的序列。 看下面的例子。

Note: Parse all the text to wordcloud generator in lowercase, as all stopwords are defined in lowercase. It won’t elimiate uppercase stopwords.
注意:将所有文本以小写形式解析到wordcloud生成器,因为所有停用词均以小写形式定义。 它不会消除大写停用词。
Alright, so the output is like this:
好了,所以输出是这样的:
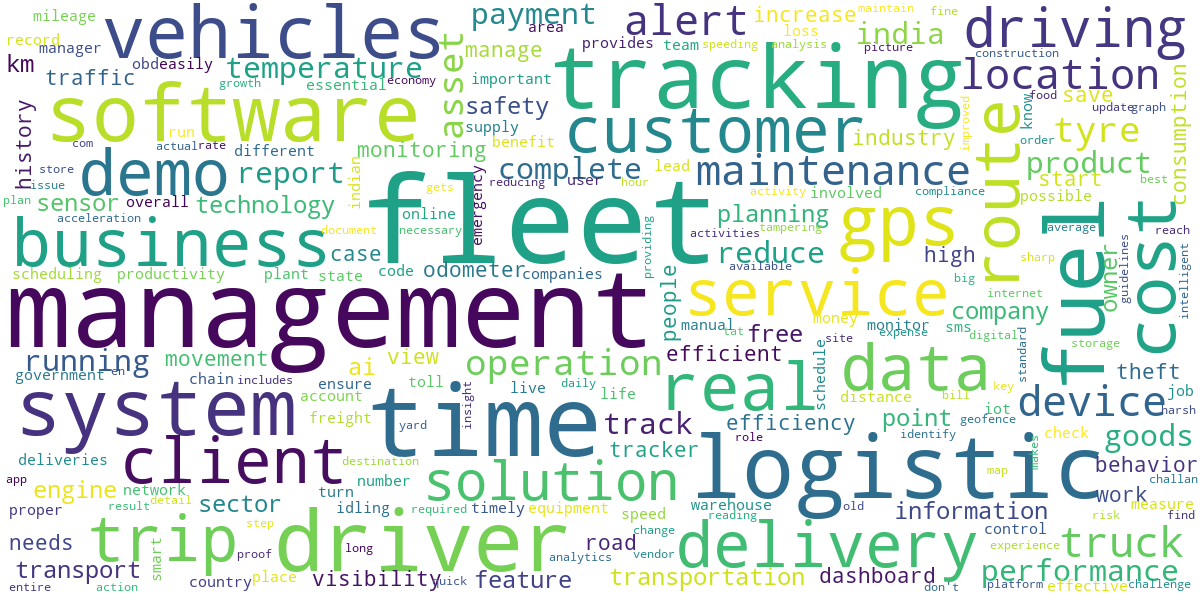
For a company doing fleet management, it’s spot on! The keyword fleet management has heavy weightage than anything else.
对于进行车队管理的公司而言,它就来了! 关键字“ 车队管理”比其他任何东西都重要。
Though, the above image misses the very element all this is about: the vehicle. Fortunately, you can mask the above wordcloud on an image of your choice with the wordcloud library. So, let’s do this.
虽然,上面的图像错过了所有这一切的要素:车辆。 幸运的是,您可以使用wordcloud库将上述wordcloud屏蔽在您选择的映像上。 所以,让我们这样做。
Choose a vector image of your choice. I’d picked my image from Vecteezy.
选择您想要的矢量图像。 我是从Vecteezy挑选图像的。
You would also need to import the
您还需要导入
Pillow and NumPy library this time to read and convert the image into a NumPy array.
这次使用Pillow和NumPy库读取图像并将其转换为NumPy数组。
- Below is the commented code block to generate the masked wordcloud, much of which is the same as before. 下面是注释的代码块,用于生成被屏蔽的词云,其中大部分与以前相同。
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import os# Read your image and convert it to an numpy array.
truck_mask=np.array(Image.open("Truck2.png"))# Instantiate the word cloud object.
wc = wordcloud.WordCloud(background_color='white', max_words=500, stopwords=final_stopwords, mask= truck_mask, scale=3, width=640, height=480, collocations=False, contour_width=5, contour_color='steelblue')# Generate word cloud
wc=wc.generate(" ".join(words_list).lower())# Show word cloud
plt.figure(figsize=(18,12))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.show()# save the masked wordcloud
wc.to_file('masked_wsordcloud.png');这是输出: (Here’s the output:)

Voila! We produced our wordcloud programmatically! 🚚💨
瞧! 我们以编程方式产生了wordcloud! 🚚💨
Thank you for reading this far! 🙌
感谢您阅读本文! 🙌
参考: (Ref:)
https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html
https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html
https://nlp.stanford.edu/fsnlp/promo/colloc.pdf
https://nlp.stanford.edu/fsnlp/promo/colloc.pdf
翻译自: https://towardsdatascience.com/how-to-make-a-wordcloud-of-your-blog-programmatically-6c2bad1baa4
com编程创建快捷方式中文
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/388168.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

ETL技术入门之ETL初认识
 的内部运行机制分析)
ActiveSupport::Concern 和 gem 'name_of_person'(300✨) 的内部运行机制分析

Python 3.8.0a2 发布,面向对象编程语言

基于plotly数据可视化_如何使用Plotly进行数据可视化

关于Oracle实时数据库的优化思路

【转】使用 lsof 查找打开的文件


数据科学与大数据是什么意思_什么是数据科学?

C#制作、打包、签名、发布Activex全过程

用Python创建漂亮的交互式可视化效果

CCF 201809-1 买菜


Hadoop 2.0集群配置详细教程

php如何减缓gc_管理信息传播-使用数据科学减缓错误信息的传播
![[UE4]删除UI:Remove from Parent](http://pic.xiahunao.cn/[UE4]删除UI:Remove from Parent)
[UE4]删除UI:Remove from Parent

MySQL基础部分总结

BZOJ2503: 相框

泰坦尼克号 数据分析_第1部分:泰坦尼克号-数据分析基础

Imperva开源域目录控制器,简化活动目录集成
)