
了解Set集合如何使用和旗下各类比较,这篇我们继续和大家一起看看Map集合的使用机制。
Map
Map集合介绍
Map(也称为字典、关联数组)是用于保存具有映射关系的数据,保存两组值,key和value,这两组值可以是任何应用类型的数据。
Map的key不允许重复(底层Map的keySet()返回的是key的Set集合,所以key不会重复),即Map中对象的任意两个key通过equals()方法得到的都是false。而,Map的value值是可以重复的(Map的底层values()方法返回类型是Collection,可以存储重复元素),通过key总能找到唯一的value,Map中的key组成一个Set集合,所以可以通过keySet()方法返回所有key。Set底层也是通过Map实现的,只不过value都是null的Map来实现的。
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, java.io.Serializable{
static final long serialVersionUID = -5024744406713321676L;
private transient HashMap map;// Dummy value to associate with an Object in the backing Mapprivate static final Object PRESENT = new Object();public HashSet() {
map = new HashMap<>();
}public HashSet(Collection extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}public boolean add(E e) {return map.put(e, PRESENT)==null;
}
}Map实现类
Map典型的实现类是HashMap、Hashtable(HashMap子类还有LinkedHashMap)、SortedMap子接口及实现类TreeMap、WeakHashMap、IndentityHashMap等。
Map有一个内部类Entry,该类封装了key-value对,有如下三个方法:
K getKey();:获取Entry中的key值;V getValue();:获取Entry中的value值;V setValue(V value);:设置Entry中的value值,并返回新设置的value值。
Map常用方法
int size();:返回Map的key-value对的长度。boolean isEmpty();:判断该Map是否为空。boolean containsKey(Object key);:判断该Map中是否包含指定的key。boolean containsValue(Object value);:判断该Map是否包含一个或多个value。V get(Object key);:获取某个key所对应的value;若不包含该key,则返回null。V put(K key, V value);:向Map添加key-value对,当Map中有一个与该key相等的key-value对,则新的会去覆盖旧的。V remove(Object key);:移除指定的key所对应的key-value对,若成功删除,则返回移除的value值。void putAll(Map extends K, ? extends V> m);:将指定的Map中的key-value对全部复制到该Map中。void clear();:清除Map中的所有key-value对。Set keySet();:获取该Map中所有key组成的Set集合。Collection values();:获取该Map中所有value组成的Collection。Set> entrySet();:返回该Map中Entry类的Set集合。boolean remove(Object key, Object value):删除指定的key-value对,若删除成功,则返回true;否则,返回false。
HashMap
HashMap介绍
HashMap底层是数组+链表的形式,实现Map.Entry接口,数组是Entry[]数组,是一个静态内部类,Entry是key-value键值对,持有一个指向下一个元素的next引用,这就构成链表(单向链表)。
HashMap底层是数组和链表的结合体。底层是一个线性数组结构,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组。数组是Entry[]数组,静态内部类。Entry就是数组中的元素,每个 Map.Entry 其实就是一个key-value对,它持有一个指向下一个元素的引用next,这就构成了链表。
根据指定的hash值找到在table中的索引;HashMap底层数组的长度是2^n,默认是16,负载因子为0.75,所以最大容量阈值threshold = (int)(capacity * loadFactor);即16*0.75=12,当超过这个阈值的时候,开始扩容,即每次扩容增加一倍。
HashMap LoadFactor源码
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
底层读写元素原理
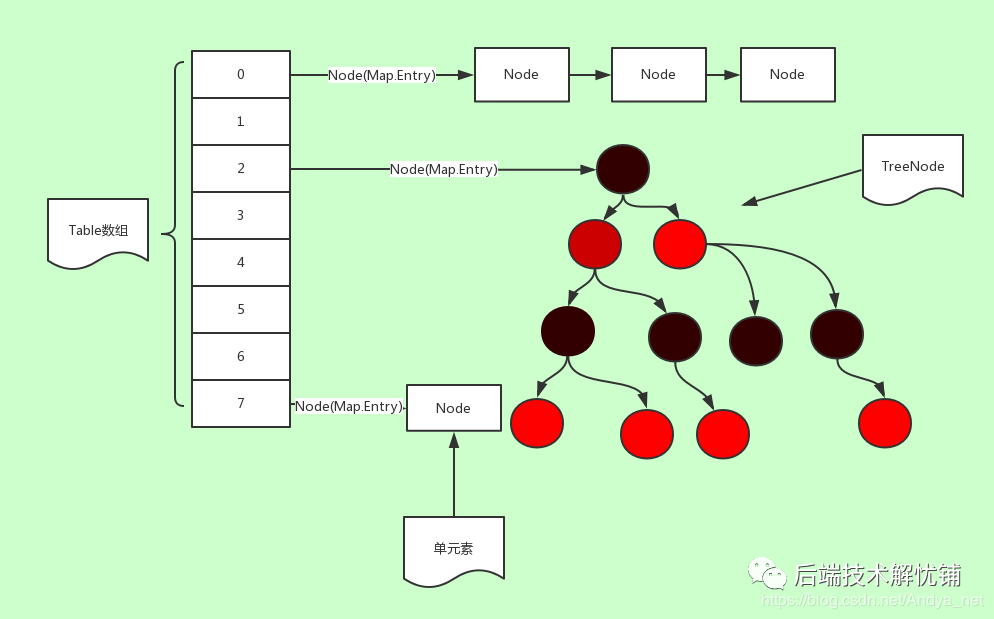
by https://www.cnblogs.com/shileibrave/p/9836731.html
put实现原理
当我们往HashMap中put元素的时候:当程序试图将一个key-value对放入HashMap中时,
- 程序首先根据该 key 的
hashCode()返回值再hash,决定该 Entry 的存储位置。(定位槽位在哪) - 若Entry的存储位置上为null,直接存储该对象;若不为空,两个 Entry 的 key 的 hashCode() 返回值相同,那它们的存储位置相同。(判断槽位是否可以呆)
- 循环遍历链表,如果这两个 Entry 的 key 通过
equals()比较返回true,新添加 Entry 的 value 将覆盖集合中原有 Entry 的value,但key不会覆盖;如果这两个 Entry 的 key 通过equals()比较返回false,将该对象放到数组中,然后将数组中原有的Entry对象链接到此对象后面。新添加的 Entry 将与集合中原有 Entry 形成Entry链,而且新添加的Entry位于 Entry 链的头部。(链式添加)
get实现原理
从HashMap中get元素时,
- 首先计算key的
hash值,通过再hash函数,找到数组中对应位置的某一元素;(定位槽位) - 然后通过key的
equals()方法(key同不同)在对应位置的链表中找到需要的元素。(判断链表位置)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
遍历Map的方式
第一种方式:Iterator的方式
Iterator> itr = map.entrySet().iterator();//等价于Set> set = map.entrySet();//Iterator> itr = set.iterator();while(itr.hasNext()){
Map.Entry entry = itr.next();
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key+" : "+value);
}第二种:增强型for循环
//使用增强型for循环
for(Map.Entry entry : map.entrySet()){
System.out.println(entry.getKey() +"=" +entry.getValue());
}HashMap示例
1)运行主类
public class DemoApplication {
public static void main(String[] args) {
Map bookMap = new HashMap<>();
bookMap.put(1,"book01");
bookMap.put(2,"book02");
bookMap.put(3,"book03");
bookMap.put(4,"book04");
bookMap.put(5,"book01");
System.out.println("原集合:" + bookMap);//获取map大小
System.out.println("size()获取map大小:" + bookMap.size());//判断map是否为空
System.out.println("isEmpty()判断是否为空:" + bookMap.isEmpty());//判断该Map中是否包含指定的key
System.out.println("containsKey()判断该Map中是否包含指定的key:" + bookMap.containsKey(2));//判断该Map是否包含一个或多个value
System.out.println("containsValue()判断该Map是否包含一个或多个value:" + bookMap.containsValue("book01"));//获取某个key所对应的value;若不包含该key,则返回null
System.out.println("获取某个key所对应的value:" + bookMap.get(2));
System.out.println("获取某个key所对应的value;若不包含该key,则返回null:" + bookMap.get(100));//put重复key,覆盖旧value;
System.out.println("put重复key:" + bookMap.put(1,"book001"));
System.out.println("新集合:" + bookMap);//移除指定的key所对应的key-value对,若成功删除,则返回移除的value值。
System.out.println("移除指定的key所对应的key-value对:" + bookMap.remove(1));//将指定的Map中的key-value对全部复制到该Map中
Map newMap = new HashMap<>();
newMap.put(10, "book10");
newMap.put(11, "book11");
System.out.println("newMap:" + newMap);
bookMap.putAll(newMap);
System.out.println("putAll()将指定的Map中的key-value对全部复制到该Map中:" + bookMap);//清除Map中的所有key-value对
newMap.clear();
System.out.println("clear()清除Map中的所有key-value对:" + newMap);//获取该Map中所有key组成的Set集合
Set keySet = bookMap.keySet();
System.out.println("keySet()获取该Map中所有key组成的Set集合:" + keySet);//获取该Map中所有value组成的Collection
Collection values = bookMap.values();
System.out.println("values()获取该Map中所有value组成的Collection:" + values);//返回该Map中Entry类的Set集合
Set> entrySet = bookMap.entrySet();
Iterator> iterator = entrySet.iterator();while (iterator.hasNext()) {
Map.Entry entry = iterator.next();
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println("key=" + key + ", value=" + value);
}//删除指定的key-value对,若删除成功,则返回true;否则,返回false。
System.out.println("删除指定的key-value对,若删除成功(存在):" + bookMap.remove(2, "book02"));
System.out.println("删除指定的key-value对,若删除成功(不存在):" + bookMap.remove(2, "book02"));
}
}2)运行结果:
原集合:{1=book01, 2=book02, 3=book03, 4=book04, 5=book01}
size()获取map大小:5
isEmpty()判断是否为空:falsecontainsKey()判断该Map中是否包含指定的key:truecontainsValue()判断该Map是否包含一个或多个value:true
获取某个key所对应的value:book02
获取某个key所对应的value;若不包含该key,则返回null:null
put重复key:book01
新集合:{1=book001, 2=book02, 3=book03, 4=book04, 5=book01}
移除指定的key所对应的key-value对:book001
newMap:{10=book10, 11=book11}
putAll()将指定的Map中的key-value对全部复制到该Map中:{2=book02, 3=book03, 4=book04, 5=book01, 10=book10, 11=book11}
clear()清除Map中的所有key-value对:{}
keySet()获取该Map中所有key组成的Set集合:[2, 3, 4, 5, 10, 11]
values()获取该Map中所有value组成的Collection:[book02, book03, book04, book01, book10, book11]
key=2, value=book02
key=3, value=book03
key=4, value=book04
key=5, value=book01
key=10, value=book10
key=11, value=book11
删除指定的key-value对,若删除成功(存在):true
删除指定的key-value对,若删除成功(不存在):false
Hashtable介绍
Hashtable是和HashMap一样,属于Map典型的实现类,区别于HashMap的是,Hashtable是线程安全的Map实现,但是性能低。Hashtable不允许使用null作为key和value;若将null值存入Hashtable,会抛出NullPointerException异常;而HashMap可以使用null作为key或value。
LinkedHashMap介绍
LinkedHashMap是HashMap的子类,使用双向链表维护key-value对的顺序(只是关注key的顺序),迭代顺序和key-value插入Map中的顺序保持一致。
Properties介绍
Properties类是Hashtable类的子类。通常作为处理属性配置文件比较好。可以将Map对象中的key-value配置写入到属性文件中,反之,也可以将属性文件中的key=value加载到Map对象中。注意,属性文件中的属性key-value只能是字符串类型。提供以下几个方法来操作Properties
synchronized Object setProperty(String key, String value):设置属性值,底层是通过put来实现。
public synchronized Object setProperty(String key, String value) {
return put(key, value);
}
String getProperty(String key):获取指定属性名的属性值,底层是通过Map的get(Object key)来实现。
public String getProperty(String key) {
Object oval = super.get(key);
String sval = (oval instanceof String) ? (String)oval : null;
return ((sval == null) && (defaults != null)) ? defaults.getProperty(key) : sval;
}
String getProperty(String key, String defaultValue):类似于getProperty(String key)方法,在此基础上多一个功能是当Properties中不存在指定的key时,该方法指定默认值去获取。synchronized void load(InputStream inStream) throws IOException:从属性文件以输入流的方式加载key-value对,并将这些key-value追加到Properties中。void store(OutputStream out, String comments):将Properties中的key-value对以输出流的方式输出到指定的属性文件中。
TreeMap介绍
TreeMap是SortedMap接口的实现类,TreeMap底层是红黑树数据结构,每个key-value作为红黑树的一个节点。TreeMap存储节点时,根据key对节点进行排序,主要是自然排序和自定义排序。类似于TreeSet。
WeakHashMap介绍
WeakHashMap用法基本和HashMap类似,不同的是WeakHashMap是对实际对象的弱引用,弱引用就是当WeakHashMap的key所引用的对象没有被其他强引用变量进行引用时,key所对应的对象就可能会被垃圾回收,WeakHashMap会自动删除该key所对应的key-value对。而HashMap的key是保留实际对象的强引用,强引用就是当HashMap对象不被销毁的时候,HashMap所有key所引用的对象就不会被垃圾回收。
IdentityHashMap介绍
IdentityHashMap也基本类似于HashMap,有一些特殊的地方在于:判断两个key相等。HashMap中判断key相等只需要判断两个key通过equals()方法比较返回true,而IdentityHashMap是仅当两个key通过(key1==key2)相等时才认为相等。IdentityHashMap同样支持null作为key和value。
EnumMap介绍
EnumMap是Map的枚举实现类,所有key都必须是单个枚举类的枚举值。创建EnumMap的时候必须显式或者隐式指定对应的枚举类。 EnumMap在内部是以数组的形式保存元素,根据key的自然顺序,即枚举值在枚举类中定义的顺序来保存key-value对的顺序。EnumMap不允许null作为key,但是可以使用null作为value。
Q&A
HashMap的扩容resize原理,如何扩容?
当HashMap内的元素对象存储的爆满时,就容易出现hash冲突的现象,这个时候就需要底层数组扩容。当然,HashMap这种扩容的操作也是比较消耗性能的,因为这需要原数组中的数据重新计算其在新数组中的位置。下面我们看看底层是如何扩容的
扩容的时机是什么?当HashMap中的元素个数超过数组大小时(即负载因子loadFactor),HashMap底层就会进行数组的扩容。loadFactor的默认值为0.75,这是一个折中的取值。
如何扩?数组大小默认为16,当HashMap中元素对象个数超过16*0.75=12时,就把数组的大小扩容到2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,因此实际使用的时候,如果我们开发人员根据业务需求,大概了解HashMap需要存储多少元素时,我们可以估计一下元素的个数去限定HashMap的大小,这样就可以提高HashMap的性能。
折中操作:负载因子loadFactor衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表空间利用率高。查找一个元素的平均时间为o(1+a),当负载因子变大的时候,空间利用率高了,但是查询效率降低;当负载因子变小的时候,元素就会稀疏,但是查询效率高,所以要折中时间和空间。
解决hash冲突的方法有哪些?
开放定址法:线性探测再散列、二次探测再散列、随机探测再散列;再哈希法:换一种哈希函数;链地址法:在数组中冲突元素后面拉一条链路,存储重复的元素;建立一个公共溢出区:其实就是建立一个表,存放那些冲突的元素。
HashMap中什么时候会产生冲突?
HashMap中调用hashCode()方法来计算hashCode。由于在Java中两个不同的对象可能有一样的hashCode,所以不同的键可能有一样hashCode,从而导致冲突的产生。
Java8中HashMap和LinkedHashMap如何解决冲突?
- 在
Java8之前,HashMap和其他基于map的类都是通过链地址法解决冲突,它们使用单向链表来存储相同索引值的元素。在最坏的情况下,这种方式会将HashMap的get方法的性能从O(1)降低到O(n)。为了解决在频繁冲突时Hashmap性能降低的问题,Java 8中使用平衡树来替代链表存储冲突的元素。这意味着我们可以将最坏情况下的性能从O(n)提高到O(logn)。 - 在
Java 8中使用常量TREEIFY_THRESHOLD来控制是否切换到平衡树来存储。目前,这个常量值是8,这意味着当有超过8个元素的索引一样时,HashMap会使用树来存储它们。 - 在Java 7中为了优化常用类对ArrayList和HashMap采用了延迟加载的机制,在有元素加入之前不会分配内存,这会减少空的链表和HashMap占用的内存。
- 这种动态解决hash冲突的特性使得HashMap
一开始使用链表,并在冲突的元素数量超过指定值时用平衡二叉树替换链表。这一特性在所有基于hash table的类中没有,例如Hashtable和WeakHashMap。只有ConcurrentHashMap,LinkedHashMap和HashMap会在频繁冲突的情况下使用平衡树。
以上就是Java中HashMap如何处理冲突。这种方法被称为链地址法,因为使用链表存储同一桶内的元素。通常情况HashMap,HashSet,LinkedHashSet,LinkedHashMap,ConcurrentHashMap,HashTable,IdentityHashMap和WeakHashMap均采用这种方法处理冲突。从JDK 8开始,HashMap,LinkedHashMap和ConcurrentHashMap为了提升性能,在频繁冲突的时候使用平衡树来替代链表。因为HashSet内部使用了HashMap,LinkedHashSet内部使用了LinkedHashMap,所以他们的性能也会得到提升。
HashMap和TreeMap区别
查询插入等用途:在Map中插入、删除和定位元素,HashMap适合;若要按顺序遍历键,则TreeMap适合。优化:HashMap可以调优初始容量和负载因子;TreeMap没有调优选项,因为树总处于平衡状态。实现接口:都实现了Cloneable接口。TreeMap实现SortMap接口,能够把它保存的记录根据键排序(默认按键的升序),HashMap继承AbstractMap;底层实现:TreeMap底层是数组+红黑树;HashMap底层是数组+链表法(从Java 8开始,HashMap,ConcurrentHashMap和LinkedHashMap在处理频繁冲突时将使用平衡树来代替链表,当同一hash桶中的元素数量超过特定的值(默认为8)便会由链表切换到平衡树,这会将get()方法的性能从O(n)提高到O(logn)。)
Hashmap和Hashset区别
&esmp;HashSet底层是通过HashMap实现的。add的时候,调用map的put方法,value始终是PRESENT,所以HashSet是所有value值都相同的HashMap。
实现接口:HashSet实现了Set集合的接口,不允许有重复的值(准确说应该是元素作为key,value是定义为final的对象),将对象存储在HashSet之前,需要确保对象已经重写了equals和hashCode方法,这样才能比较两个对象的值是否相等,确保set中没有存储相等的对象。HashMap实现了Map集合接口,对键值对进行映射。Map中不允许重复的键。存储元素:HashMap存储的是键值对,不允许有重复的键;Hashset存储的是对象,不能有重复的对象元素。添加元素方法:HashMap使用put方法将元素放入map中,HashSet使用add方法将元素放入set中。hashCode值的计算:HashMap中使用键对象计算hashcode的值,HashSet中使用成员对象来计算hashcode值。效率:HashMap比较快,因为使用唯一的键来获取对象,HashSet比HashMap慢。底层实现:HashSet是所有value值都相同的HashMap。HashSet内部使用HashMap实现,只不过HashSet里面的HashMap所有的value都是同一个object而已。private transient HashMap map;只是包含了hashmap的key。
HashMap和Hashtable异同
同:
两者都是用key-value方式获取数据。异:
null值:HashMap允许null值作为key和value;Hashtable不允许null的键值;顺序性:HashMap不保证映射的顺序不变,但是作为HashMap的子类LinkedHashMap默认按照插入顺序来进行映射的顺序;Hashtable无法保证;线程安全:HashMap是非同步的(非线程安全),效率高;Hashtable是同步的(线程安全的),效率低。(HashMap同步通过Collections.synchronizedMap()实现)快速失败机制:迭代HashMap采用fail-fast快速失败机制(快速失败机制:是一个线程或软件对于其故障做出的响应,用来即时报告可能会导致失败的任何故障情况,如果一个Iterator在集合对象上创建了,其他线程想结构化的修改该集合对象,抛出并发修改异常ConcurrentModificationException);而HashTable的enumerator迭代器不是fail-fast的(Hashtable的上下文同步:一个时间点只能有一个线程可以修改哈希表,任何线程在执行Hashtable的更新操作前需要获取对象锁,其他线程等待锁的释放;父类:HashMap继承AbstractMap,Hashtable继承Dictionary;数组默认大小:HashMap底层数组的默认大小是16,扩容是2*old;Hashtable底层数组默认是11,扩容方式是2*old+1;效率:HashMap是非线程安全的,单线程下效率高;Hashtable是线程安全的,方法都加了synchronized关键字进行同步,效率较低;计算hash方式不同:HashMap是二次hash,对key的hashCode进行二次hash,获得更好的散列值;而Hashtable是直接使用key的hashCode对table数组进行取模。
如何让HashMap同步
通过Collections集合工具类中的synchronizedMap()方法实现同步:Map map = Collections.synchronizedMap(hashMap);。Collections.synchronizedMap()实现原理是Collections定义了一个SynchronizedMap的内部类,这个类实现了Map接口,在调用方法时使用synchronized来保证线程同步,当然了实际上操作的还是我们传入的。
源码
private static class SynchronizedMap<K,V>implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map m; // Backing Mapfinal Object mutex; // Object on which to synchronize
SynchronizedMap(Map m) {this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map m, Object mutex) {this.m = m;this.mutex = mutex;
}public int size() {synchronized (mutex) {return m.size();}
}public boolean isEmpty() {synchronized (mutex) {return m.isEmpty();}
}public boolean containsKey(Object key) {synchronized (mutex) {return m.containsKey(key);}
}public boolean containsValue(Object value) {synchronized (mutex) {return m.containsValue(value);}
}public V get(Object key) {synchronized (mutex) {return m.get(key);}
}public V put(K key, V value) {synchronized (mutex) {return m.put(key, value);}
}public V remove(Object key) {synchronized (mutex) {return m.remove(key);}
}public void putAll(Map extends K, ? extends V> map) {synchronized (mutex) {m.putAll(map);}
}public void clear() {synchronized (mutex) {m.clear();}
}private transient Set keySet;private transient Set> entrySet;private transient Collection values;public SetkeySet() {synchronized (mutex) {if (keySet==null)
keySet = new SynchronizedSet<>(m.keySet(), mutex);return keySet;
}
}public Set> entrySet() {synchronized (mutex) {if (entrySet==null)
entrySet = new SynchronizedSet<>(m.entrySet(), mutex);return entrySet;
}
}public Collectionvalues() {synchronized (mutex) {if (values==null)
values = new SynchronizedCollection<>(m.values(), mutex);return values;
}
}public boolean equals(Object o) {if (this == o)return true;synchronized (mutex) {return m.equals(o);}
}public int hashCode() {synchronized (mutex) {return m.hashCode();}
}public String toString() {synchronized (mutex) {return m.toString();}
}// Override default methods in Map@Overridepublic V getOrDefault(Object k, V defaultValue) {synchronized (mutex) {return m.getOrDefault(k, defaultValue);}
}@Overridepublic void forEach(BiConsumer super K, ? super V> action) {synchronized (mutex) {m.forEach(action);}
}@Overridepublic void replaceAll(BiFunction super K, ? super V, ? extends V> function) {synchronized (mutex) {m.replaceAll(function);}
}@Overridepublic V putIfAbsent(K key, V value) {synchronized (mutex) {return m.putIfAbsent(key, value);}
}@Overridepublic boolean remove(Object key, Object value) {synchronized (mutex) {return m.remove(key, value);}
}@Overridepublic boolean replace(K key, V oldValue, V newValue) {synchronized (mutex) {return m.replace(key, oldValue, newValue);}
}@Overridepublic V replace(K key, V value) {synchronized (mutex) {return m.replace(key, value);}
}@Overridepublic V computeIfAbsent(K key,
Function super K, ? extends V> mappingFunction) {synchronized (mutex) {return m.computeIfAbsent(key, mappingFunction);}
}@Overridepublic V computeIfPresent(K key,
BiFunction super K, ? super V, ? extends V> remappingFunction) {synchronized (mutex) {return m.computeIfPresent(key, remappingFunction);}
}@Overridepublic V compute(K key,
BiFunction super K, ? super V, ? extends V> remappingFunction) {synchronized (mutex) {return m.compute(key, remappingFunction);}
}@Overridepublic V merge(K key, V value,
BiFunction super V, ? super V, ? extends V> remappingFunction) {synchronized (mutex) {return m.merge(key, value, remappingFunction);}
}private void writeObject(ObjectOutputStream s) throws IOException {synchronized (mutex) {s.defaultWriteObject();}
}
}
[每篇微语]
做人有三碗面最难吃:人面、场面、情面。
—— 杜月笙











)







