菜菜呀,由于公司业务不断扩大,线上分布式缓存服务器扛不住了呀
 程序员主力 Y总
程序员主力 Y总
如果加硬件能解决的问题,那就不需要修改程序
 菜菜
菜菜
我是想加服务器来解决这个问题,但是有个问题呀
程序员主力 Y总???
菜菜你忘了去年分布式缓存服务器也扩容过一次,很多请求都穿透了,DB差点扛不住呀,这次再扩容DB估计就得挂了
程序员主力 Y总为什么会有这么多请求穿透呢?公司的缓存策略是什么?
菜菜很简单,根据缓存数据key的哈希值然后和缓存服务器个数取模,即:服务器信息=hash(key)%服务器数量
程序员主力 Y总这样的话,增加一台服务器,岂不是大部分的缓存几乎都命中不了了?
菜菜给你半天,把这个机制优化一下,你要加油呀
程序员主力 Y总工资能不能涨一点?
菜菜将来公司发达了,给你发股票......
程序员主力 Y总心想:呸!!
菜菜又是一个没有开工红包的公司!!!
问题分析
过以上对话,各位是否能够猜到所有缓存穿透的原因呢?回答之前我们先来看一下缓存策略的具体代码:
这里还要多说一句,key的取值可以根据具体业务具体设计。比如,我想要做负载均衡,key可以为调用方的服务器IP;获取用户信息,key可以为用户ID;等等。
在服务器数量不变的情况下,以上设计没有问题。但是要知道,程序员的现实世界是悲惨的,唯一不变的就是业务一直在变。我本无奈,只能靠技术来改变这种状况。
假如我们现在服务器的数量为10,当我们请求key为6的时候,结果是4,现在我们增加一台服务器,服务器数量变为11,当再次请求key为6的服务器的时候,结果为5.不难发现,不光是key为6的请求,几乎大部分的请求结果都发生了变化,这就是我们要解决的问题, 这也是我们设计分布式缓存等类似场景时候主要需要注意的问题。
我们终极的设计目标是:在服务器数量变动的情况下
1. 尽量提高缓存的命中率(转移的数据最少)
2. 缓存数据尽量平均分配
解决方案
通过以上的分析我们明白了,造成大量缓存失效的根本原因是公式分母的变化,如果我们把分母保持不变,基本上可以减少大量数据被移动
如果基于公式:缓存服务器IP=hash(key)%服务器数量 我们保持分母不变,基本上可以改善现有情况。我们选择缓存服务器的策略会变为:
N的数值选择,可以根据具体业务选择一个满足情况的值。比如:我们可以肯定将来服务器数量不会超过100台,那N完全可以设定为100。那带来的问题呢?
目前的情况可以认为服务器编号是连续的,任何一个请求都会命中一个服务器,还是以上作为例子,我们服务器现在无论是10还是增加到11,key为6的请求总是能获取到一台服务器信息,但是现在我们的策略公式分母为100,如果服务器数量为11,key为20的请求结果为20,编号为20的服务器是不存在的。
以上就是简单哈希策略带来的问题(简单取余的哈希策略可以抽象为连续的数组元素,按照下标来访问的场景)
为了解决以上问题,业界早已有解决方案,那就是一致性哈希。
一致性哈希具体的特点,请各位百度,这里不在详细介绍。至于解决问题的思路这里还要强调一下:
 1. 首先求出服务器(节点)的哈希值,并将其配置到环上,此环有2^32个节点。
1. 首先求出服务器(节点)的哈希值,并将其配置到环上,此环有2^32个节点。
2. 采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
3. 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过2^32仍然找不到服务器,就会保存到第一台服务器上
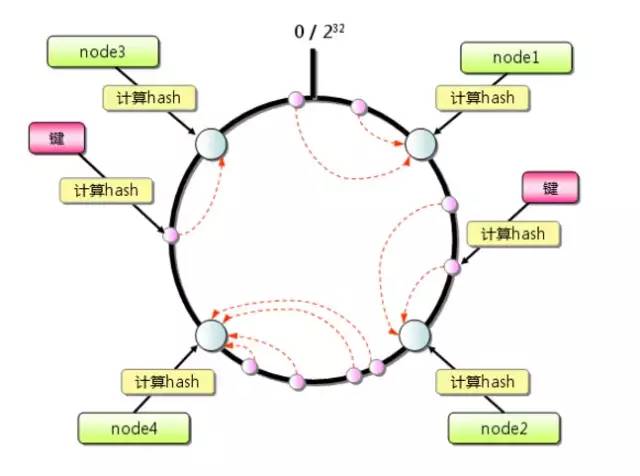
当增加新的服务器的时候会发生什么情况呢?
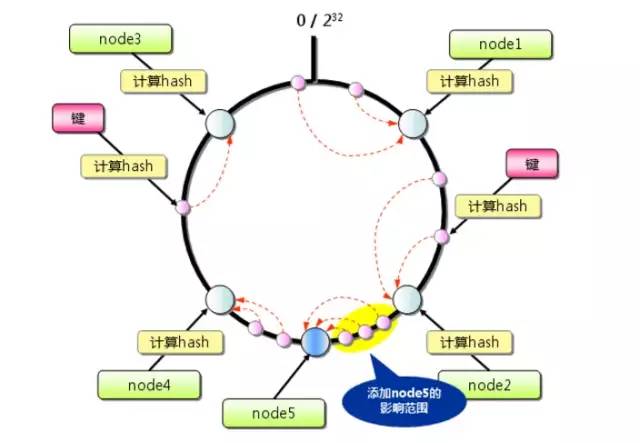
通过上图我们可以发现发生变化的只有如黄色部分所示。删除服务器情况类似。
通过以上介绍,一致性哈希正是解决我们目前问题的一种方案。解决方案千万种,能解决问题即为好
优化方案
到目前为止方案都看似完美,但现实是残酷的。以上方案虽好,但还存在瑕疵。假如我们有3台服务器,理想状态下服务器在哈希环上的分配如下图:
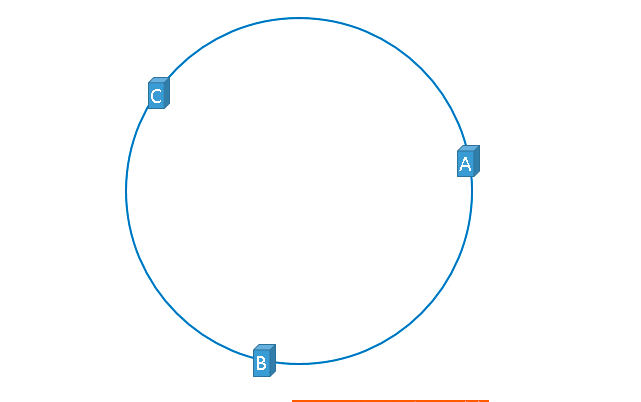
但是现实往往是这样:

这就是所谓的哈希环偏斜。分布不均匀在某些场景下会依次压垮服务器,实际生产环境一定要注意这个问题。为了解决这个问题,虚拟节点应运而生。
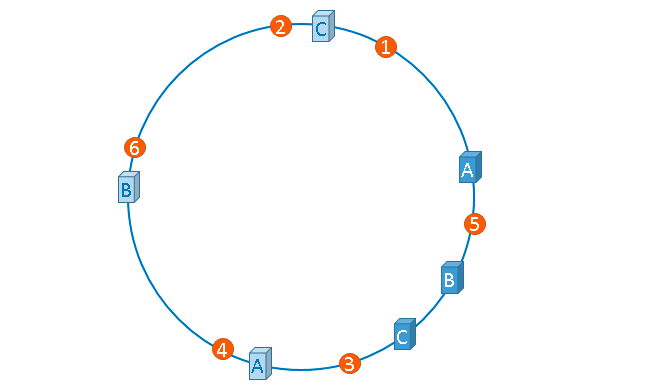
如上图,哈希环上不再是实际的服务器信息,而是服务器信息的映射信息,比如:ServerA-1,ServerA-2 都映射到服务器A,在环上是服务器A的一个复制品。这种解决方法是利用数量来达到均匀分布的目的,随之需要的内存可能会稍微大一点,算是空间换取设计的一种方案。
扩展阅读
 1. 既然是哈希就会有哈希冲突,那多个服务器节点的哈希值相同该怎么办呢?我们可以采用散列表寻址的方案:从当前位置顺时针开始查找空位置,直到找到一个空位置。如果未找到,菜菜认为你的哈希环是不是该扩容了,或者你的分母参数是不是太小了呢。
1. 既然是哈希就会有哈希冲突,那多个服务器节点的哈希值相同该怎么办呢?我们可以采用散列表寻址的方案:从当前位置顺时针开始查找空位置,直到找到一个空位置。如果未找到,菜菜认为你的哈希环是不是该扩容了,或者你的分母参数是不是太小了呢。
2. 在实际的业务中,增加服务器或者减少服务器的操作要比查找服务器少的多,所以我们存储哈希环的数据结构的查找速度一定要快,具体说来本质是:自哈希环的某个值起,能快速查找第一个不为空的元素。
3. 如果你度娘过你就会发现,网上很多介绍虚拟哈希环节点个数为2^32(2的32次方),千篇一律。难道除了这个个数就不可以吗?在菜菜看来,这个数目完全必要这么大,只要符合我们的业务需求,满足业务数据即可。
4. 一致性哈希用到的哈希函数,不止要保证比较高的性能,还要保持哈希值的尽量平均分布,这也是一个工业级哈希函数的要求,一下代码实例的哈希函数其实不是最佳的,有兴趣的同学可以优化一下。
5. 有些语言自带的GetHashCode()方法应用于一致性哈希是有问题的,例如c#。程序重启之后同一个字符串的哈希值是变动的。所有需要一个更加稳定的字符串转int的哈希算法

一致性哈希解决的本质问题是:相同的key通过相同的哈希函数,能正确路由到相同的目标。像我们平时用的数据库分表策略,分库策略,负载均衡,数据分片等都可以用一致性哈希来解决。




理论结合实际才是真谛(NetCore代码)
以下代码经过少许修改可直接应用于中小项目生产环境。
//真实节点的信息
public abstract class NodeInfo
{
public abstract string NodeName { get; }
}
测试程序所用节点信息:
class Server : NodeInfo
{
public string IP { get; set; }
public override string NodeName
{
get => IP;
}
}
以下为一致性哈希核心代码:
/// <summary>
/// 1.采用虚拟节点方式 2.节点总数可以自定义 3.每个物理节点的虚拟节点数可以自定义
/// </summary>
public class ConsistentHash
{
//哈希环的虚拟节点信息
public class VirtualNode
{
public string VirtualNodeName { get; set; }
public NodeInfo Node { get; set; }
}
//添加元素 删除元素时候的锁,来保证线程安全,或者采用读写锁也可以
private readonly object objLock = new object();
//虚拟环节点的总数量,默认为100
int ringNodeCount;
//每个物理节点对应的虚拟节点数量
int virtualNodeNumber;
//哈希环,这里用数组来存储
public VirtualNode[] nodes = null;
public ConsistentHash(int _ringNodeCount = 100, int _virtualNodeNumber = 3)
{
if (_ringNodeCount <= 0 || _virtualNodeNumber <= 0)
{
throw new Exception("_ringNodeCount和_virtualNodeNumber 必须大于0");
}
this.ringNodeCount = _ringNodeCount;
this.virtualNodeNumber = _virtualNodeNumber;
nodes = new VirtualNode[_ringNodeCount];
}
//根据一致性哈希key 获取node信息,查找操作请业务方自行处理超时问题,因为多线程环境下,环的node可能全被清除
public NodeInfo GetNode(string key)
{
var ringStartIndex = Math.Abs(GetKeyHashCode(key) % ringNodeCount);
var vNode = FindNodeFromIndex(ringStartIndex);
return vNode == null ? null : vNode.Node;
}
//虚拟环添加一个物理节点
public void AddNode(NodeInfo newNode)
{
var nodeName = newNode.NodeName;
int virtualNodeIndex = 0;
lock (objLock)
{
//把物理节点转化为虚拟节点
while (virtualNodeIndex < virtualNodeNumber)
{
var vNodeName = $"{nodeName}#{virtualNodeIndex}";
var findStartIndex = Math.Abs(GetKeyHashCode(vNodeName) % ringNodeCount);
var emptyIndex = FindEmptyNodeFromIndex(findStartIndex);
if (emptyIndex < 0)
{
// 已经超出设置的最大节点数
break;
}
nodes[emptyIndex] = new VirtualNode() { VirtualNodeName = vNodeName, Node = newNode };
virtualNodeIndex++;
}
}
}
//删除一个虚拟节点
public void RemoveNode(NodeInfo node)
{
var nodeName = node.NodeName;
int virtualNodeIndex = 0;
List<string> lstRemoveNodeName = new List<string>();
while (virtualNodeIndex < virtualNodeNumber)
{
lstRemoveNodeName.Add($"{nodeName}#{virtualNodeIndex}");
virtualNodeIndex++;
}
//从索引为0的位置循环一遍,把所有的虚拟节点都删除
int startFindIndex = 0;
lock (objLock)
{
while (startFindIndex < nodes.Length)
{
if (nodes[startFindIndex] != null && lstRemoveNodeName.Contains(nodes[startFindIndex].VirtualNodeName))
{
nodes[startFindIndex] = null;
}
startFindIndex++;
}
}
}
//哈希环获取哈希值的方法,因为系统自带的gethashcode,重启服务就变了
protected virtual int GetKeyHashCode(string key)
{
var sh = new SHA1Managed();
byte[] data = sh.ComputeHash(Encoding.Unicode.GetBytes(key));
return BitConverter.ToInt32(data, 0);
}
#region 私有方法
//从虚拟环的某个位置查找第一个node
private VirtualNode FindNodeFromIndex(int startIndex)
{
if (nodes == null || nodes.Length <= 0)
{
return null;
}
VirtualNode node = null;
while (node == null)
{
startIndex = GetNextIndex(startIndex);
node = nodes[startIndex];
}
return node;
}
//从虚拟环的某个位置开始查找空位置
private int FindEmptyNodeFromIndex(int startIndex)
{
while (true)
{
if (nodes[startIndex] == null)
{
return startIndex;
}
var nextIndex = GetNextIndex(startIndex);
//如果索引回到原地,说明找了一圈,虚拟环节点已经满了,不会添加
if (nextIndex == startIndex)
{
return -1;
}
startIndex = nextIndex;
}
}
//获取一个位置的下一个位置索引
private int GetNextIndex(int preIndex)
{
int nextIndex = 0;
//如果查找的位置到了环的末尾,则从0位置开始查找
if (preIndex != nodes.Length - 1)
{
nextIndex = preIndex + 1;
}
return nextIndex;
}
#endregion
}
测试生成的节点
ConsistentHash h = new ConsistentHash(200, 5);
h.AddNode(new Server() { IP = "192.168.1.1" });
h.AddNode(new Server() { IP = "192.168.1.2" });
h.AddNode(new Server() { IP = "192.168.1.3" });
h.AddNode(new Server() { IP = "192.168.1.4" });
h.AddNode(new Server() { IP = "192.168.1.5" });
for (int i = 0; i < h.nodes.Length; i++)
{
if (h.nodes[i] != null)
{
Console.WriteLine($"{i}===={h.nodes[i].VirtualNodeName}");
}
}
输出结果(还算比较均匀):
2====192.168.1.3#4
10====192.168.1.1#0
15====192.168.1.3#3
24====192.168.1.2#2
29====192.168.1.3#2
33====192.168.1.4#4
64====192.168.1.5#1
73====192.168.1.4#3
75====192.168.1.2#0
77====192.168.1.1#3
85====192.168.1.1#4
88====192.168.1.5#4
117====192.168.1.4#1
118====192.168.1.2#4
137====192.168.1.1#1
152====192.168.1.2#1
157====192.168.1.5#2
158====192.168.1.2#3
159====192.168.1.3#0
162====192.168.1.5#0
165====192.168.1.1#2
166====192.168.1.3#1
177====192.168.1.5#3
185====192.168.1.4#0
196====192.168.1.4#2
测试一下性能
Stopwatch w = new Stopwatch();
w.Start();
for (int i = 0; i < 100000; i++)
{
var aaa = h.GetNode("test1");
}
w.Stop();
Console.WriteLine(w.ElapsedMilliseconds);
输出结果(调用10万次耗时657毫秒):
657
以上代码实有优化空间
1. 哈希函数
2. 很多for循环的临时变量
有兴趣优化的同学可以留言哦!!


●程序员修仙之路--高性能排序多个文件
●程序员修仙之路--把用户访问记录优化到极致
●程序员修仙之路--设计一个实用的线程池●程序员修仙之路--数据结构之CXO让我做一个计算器●程序猿修仙之路--数据结构之设计高性能访客记录系统●程序猿修仙之路--算法之快速排序到底有多快●程序猿修仙之路--数据结构之你是否真的懂数组?●程序猿修仙之路--算法之希尔排序!
●程序员修仙之路--算法之插入排序!
●程序员修仙之路--算法之选择排序!
互联网之路,菜菜与君一同成长
长按识别二维码关注


听说转发文章
会给你带来好运


![[2021-09-02 contest]CF1251C,可达性统计(bitset优化dp),Boomerang Tournament(状压dp),小蓝的好友(mrx)(treap平衡树)](https://img-blog.csdnimg.cn/2e140b1a6ee74107bcb6daa0ebcde559.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAaWt2cnh0,size_20,color_FFFFFF,t_70,g_se,x_16)