首先引起cpu100%可能的几大原因:
1.redis连接数过高
2.数据持久化导致的阻塞
3.主从存在频繁全量同步
4.value值过大
5.redis慢查询
为了模拟redis服务器cpu100%,临时买了一台阿里云ecs,并把那天清空前的redis备份还原到服务器上。下面我们按照顺序逐个排查,
redis连接数过高?
redis的默认链接数是10000,我们并没有更改这个值,前面提到了web的承载量是1600左右,所有可以排除
数据持久化导致的阻塞?
大家知道redis是可以持久化的,而redis持久化会采取LZF算法进行压缩,这种方式会减少磁盘的存储大小,而通过这种方式是需要消耗cpu的,我们看下redis的配置
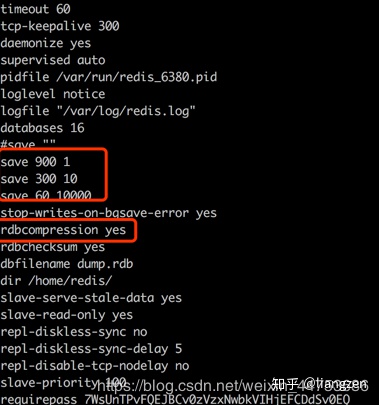
rdbcompression yes 表示压缩算法是打开的
还有3个关键的参数,这里解释一下:
save 900 1 //表示每15分钟且至少有1个key改变,就触发一次持久化
save 300 10 //表示每5分钟且至少有10个key改变,就触发一次持久化
save 60 10000 //表示每60秒至少有10000个key改变,就触发一次持久化
因为redis持久化的动作会记录日志,我们首先找出出问题的时间段里的持久化内容大小
也才75M,看起来不会是它了,为了确保,我批量的高频次写入redis进行验证(这里代码就不贴了),直接看实验结果,数据量大概是上面的4倍
写入的过程我实时的观察cpu运作情况(实验的服务器是单核的,所有直接看阿里云的监控页):
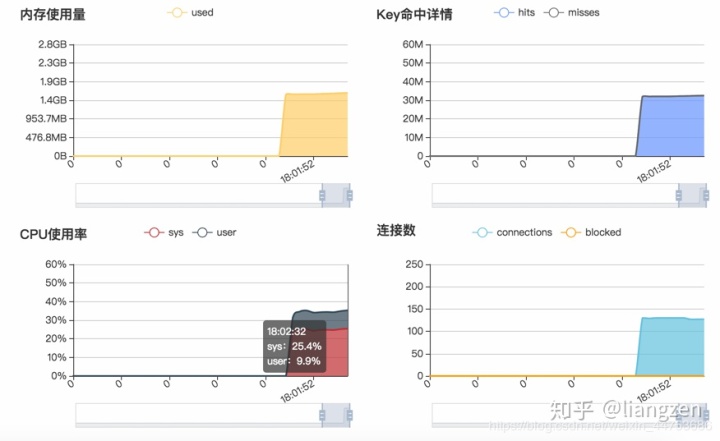
得出结论:毫无压力,所有这项也排除
主从存在频繁全量同步
因为我们是单服务器,没有做主从所以直接排除
value值过大
先看一下当时cpu时redis的key和存储量情况
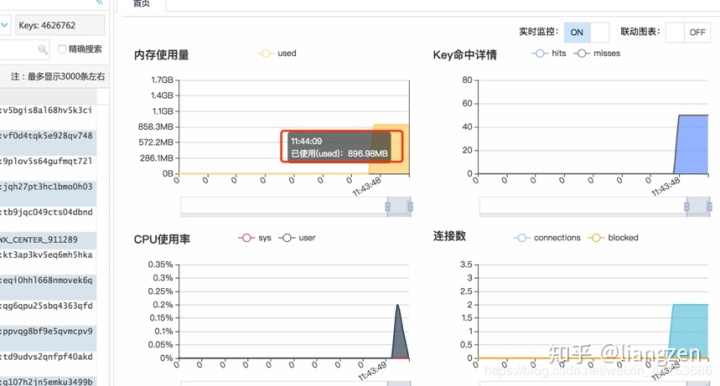
462万多的key才使用900MB左右的内容,平均一个key才0.2kb左右,基本不可能,但是抱着严谨的态度还是决定模拟写入大的value值,测试之前现进行清空,然后写了一个数据读写脚本(这里就不展示代码了):
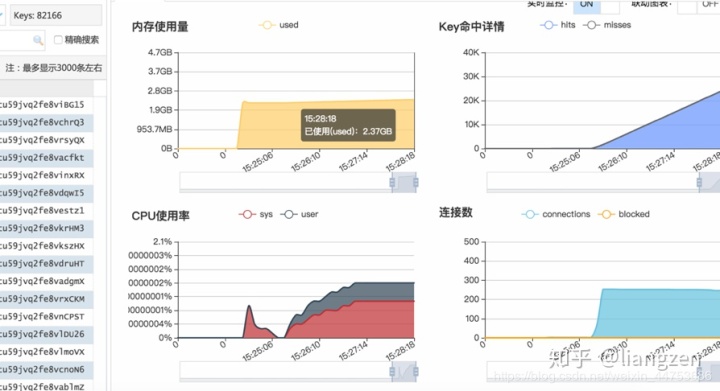
使单个key平均300KB左右提升了100多倍,cpu毫无压力,所有这个问题也可以排除。
redis慢查询
相信大家看到这里已经知道结论了,就是慢查询的问题。

一个高频访问的网页程序请求redis使用keys命令,导致每次访问接近2秒,当2秒内访问超过服务器的最高承载量时,后面请求全部需要排队,导致大量的超时(504)...
看了一下官方对keys命令的说明,已经进行警告生产环境要慎用,会产生性能问题:
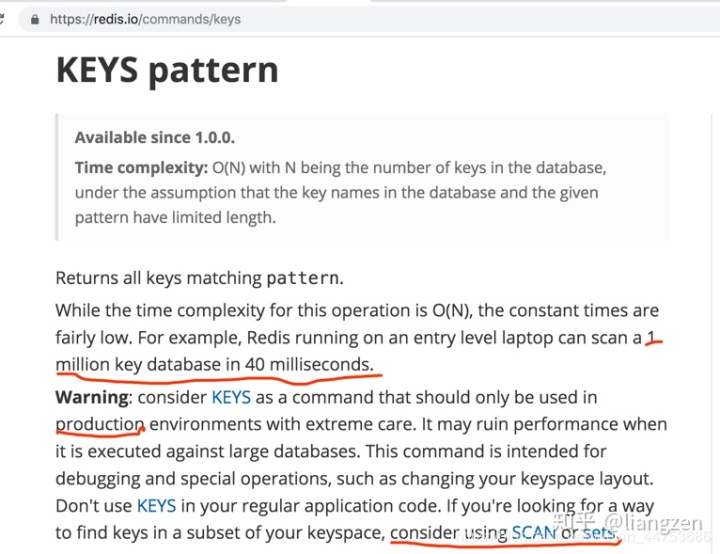
原文链接:redis服务器cpu100%的原因和解决方案_数据库_weixin_44753686的博客-CSDN博客












)

)




在x-window下图形界面简单搭建samba服务器)