
Hadoop是一个开源的分布式框架,是Apache下的一个开源项目。Hadoop运行可以在成千上万个普通机器节点组成的集群上,通过分布式的计算模型和存储模型来处理大数据集。Hadoop具有高容错性、工作在普通的机器节点上扩展性强等众多的优点,是企业选择处理大数据集工具的不二“人”选。
这个框架是另一个大项目的一部分,有数据库管理专家Mike Cafarella与开源技术的支持者DougCutting所构建。两人创建了一个名叫Nutch的网络爬虫与分析系统,该系统使用集群运算同时执行多项任务。之后Nutch演化成两个系统,其中之一就是Hadoop分布式管理系统。
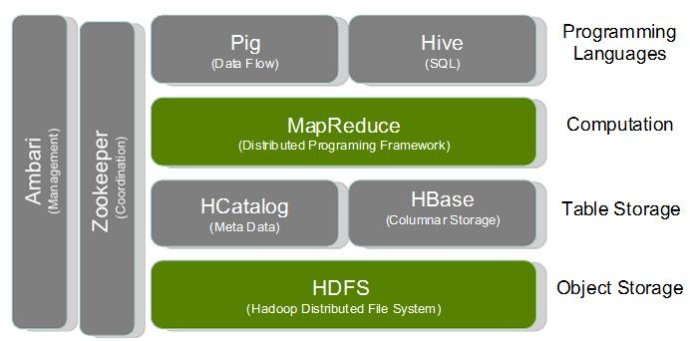
Hadoop核心组成部分
- Hadoop Common:包括函数库与工具功能,对Hadoop的其他模块提供支持。
- Hadoop分布式文件系统(HDFS):基于Java,具有高扩展性,允许在未经预先安排的多台计算机上存储数据——本质上是打造一个类似单文件系统运作的节点社区。
- MapReduce:Hadoop的一个处理大数据集的分布式计算框架,可处理结构化与非结构化数据集,具有可靠性与高容错性。
- Yarn(另一种资源协调方式):是一种资源管理框架,用来处理多个分布式架构发送的资源请求调度。
一个HDFS集群主要由Namenode和Datanode组成,其中Namenode只有一个,主要用于管理存储数据的元数据,而Datanode可以有多个,主要用于直接存储数据。
常用数据存取部分
- pig:专为数据分析设计的编程语言,无需花费大量时间构建映射和化简操作,即可处理任何类型的数据。
- Hive:类似SQL的查询语言——HQL,将sql语句编译到MapReduce中,再跨集群分发出去。
- Flume:从应用中收集大量数据,并将它们转入HDFS文件系统中。
- Spark:开源集群运算系统,在某些情况下进行数据分析时比MapReduce块100倍。
- Sqoop:数据传输工具,可以提取、加载并转换结构化数据。
- Hbase:NoSQL数据库一种,可在HDFS上运行。








,表的外键)










