目录
一、什么是过拟合?(overfitting)
二、过拟合的表现(判定方法)
训练集、测试集、验证集区别
测试集与验证集的区别
三、产生过拟合的原因
1、样本方面
2、模型方面
四、避免过拟合的方法
1、样本方面
1)增加样本量
2)样本筛选(特征降维、特征选择)
3)归一化数据样本
2、模型方法
1)正则化——使模型简单化、参数稀疏化
①概念——核心思想
问题1:什么是稀疏参数?什么是数据的稀疏性?
问题2:什么是范数?常用的范数函数是什么?
问题3:实现参数的稀疏有什么好处吗?
问题4:参数值越小代表模型越简单吗?
②L0正则化——正则项为非零分量的个数
③L1正则化(LASSO)——效果使w分量往0靠拢
④L2正则化(岭回归)——效果使参数减小
⑤为什么可以避免过拟合?
⑥比较L1与L2
2)归一化(Normalization)
①最小最大值归一化(min-max normalization)
②0均值标准化(Z-score standardization)
③batch normalization(BN层)
④什么情况下使用归一化方法?
⑤为什么归一化能够实现避免过拟合?
⑥BN的优点
3)dropout(随机丢弃)——随机删除一些神经元,以在不同批量上训练不同的神经网络架构。
①过程
②为什么能够避免过拟合?
4)early stopping(早停法)
①第一类停止标准
②第二类停止标准
③第三类停止标准
④选择停止标准的规则
⑤ 优缺点
一、什么是过拟合?(overfitting)
过拟合其实就是为了得到一致假设而使得假设过于地严格。使得其在训练集上的表现非常地完美,但是在训练集以外的数据集却表现不好。

如上图所示,红线就是过拟合了,虽然它在训练集上将所有的点都放在了线上,但是如果再来一个点就会不起作用,这就是过拟合,而绿线的话也比较好地拟合了点集,但是它的泛化能力相较于红线来说是更好的
二、过拟合的表现(判定方法)
1、训练集的正确率不增反减
2、验证集的正确率不再发生变化
3、训练集的error一直下降,但是验证集的error不减反增


上图所示,训练集随着训练的过程中,error一直减小,但是训练次数到了一定程度的时候,验证集的error却开始上升,这时候说明当前代数训练得到的模型对于训练集的样本表现良好,但是对于训练集以外的样本表现不太好。
训练集、测试集、验证集区别
参考:https://blog.csdn.net/kieven2008/article/details/81582591
训练集:计算梯度更新权重,用于训练得到模型
验证集:用于每次训练完一代后判断模型的训练情况,根据在验证集上的正确率来进行产参数的调整,一定程度上可以避免过拟合
测试集:用于判断最终训练出来的模型表现情况,比如给出一个accuracy以推断网络的好坏等

测试集与验证集的区别

三、产生过拟合的原因
参考:什么是「过拟合」,如何判断,常见的原因是什么?
1、样本方面
1)用于训练的样本量过于少,使得训练出来的模型不够全面以致于使用模型时错误率高
比如对于猫这类动物,如果训练数据集中只有一个正拍且坐立的猫,那么当过拟合时,模型往往有可能只能识别出这类姿态的猫,像跳跃的猫、局部捕捉的猫、反转的猫等等可能都识别不出来了
2)训练的样本量噪声大(质量不好),导致一些错误的特征错认为是学习的对象,使得训练模型不够健壮
2、模型方面
1)参数过多,模型过于复杂
2)选择的模型本身就不适用于当前的学习任务
3)网络层数过多,导致后面学习得到的特征不够具有代表性
四、避免过拟合的方法
参考:
https://blog.csdn.net/baidu_31657889/article/details/88941671
https://www.cnblogs.com/ying-chease/p/9489596.html
https://zhuanlan.zhihu.com/p/97326991
解决问题往往是从出现问题的原因入手,所以根据上面的过拟合原因来来避免过拟合
1、样本方面
1)增加样本量
深度学习中样本量一般需要在万级别才能训练出较好的模型,且样本尽可能地多样化,使得样本更加地全面。一般通过图像变换可以进行数据增强,见文章《【tensorFlow】——图像数据增强、读取图像、保存图像》
2)样本筛选(特征降维、特征选择)
参考:机器学习-->特征降维方法总结
特征降维:PCA等,根据现有的特征创造出新的特征
特征选择:选择具有代表性的特征参与训练
3)归一化数据样本
改变数据的分布,使得更集中在激活函数的敏感区,具体见下面2(2)知识点
2、模型方法
1)正则化——使模型简单化、参数稀疏化
参考:
https://blog.csdn.net/qq_20412595/article/details/81636105
①概念——核心思想
正则化其实就是在原来的损失函数后面增加了一项加数,这项加数称之为正则项,这个正则项通常由一个系数和范数的乘积的累加和构成。其主要是通过正则项来限制权重w参数的值的变化,使其尽可能的小或者尽可能地趋于0,以达到稀疏参数的效果,进而使得模型复杂度下降,避免过拟合。
问题有以下几个?
问题1:什么是稀疏参数?什么是数据的稀疏性?
稀疏参数:使得模型中参数的零分量尽可能地多;
数据的稀疏性:在特征选择中的概念,指的是在众多的特征中,有的特征对于模型的优化是无关的,这就是数据存在稀疏性,可以通过特征选择来选择有价值的特征。
但是在机器学习的参数中,由于参数众多,模型复杂度过于高的话,易出现过拟合现象,因此我们需要通过增加参数的稀疏性来降低复杂度,进而避免过拟合。
问题2:什么是范数?常用的范数函数是什么?
范数:在泛函分析中,它定义在赋范线性空间中,并满足一定的条件,即①非负性;②齐次性;③三角不等式。它常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小
问题3:实现参数的稀疏有什么好处吗?
一个好处是可以简化模型,避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数起作用,那么可以对训练数据可以预测的很好,但是对测试数据表现性能极差。另一个好处是参数变少可以使整个模型获得更好的可解释性。
问题4:参数值越小代表模型越简单吗?
是的。为什么参数越小,说明模型越简单呢,这是因为越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。反过来就是如果参数值小的话,那么异常点在这个区间里的导数就会比较小,造成预测值的波动也就小,这样就会利于模型,避免过拟合,更具有泛化能力去预测新样本。


②L0正则化——正则项为非零分量的个数
利用非零参数的个数,可以很好的来选择特征,实现特征稀疏的效果,具体操作时选择参数非零的特征即可。但因为
正则化很难求解,是个NP难问题,因此一般采用
正则化。
③L1正则化(LASSO)——效果使w分量往0靠拢
在原始的代价函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n(这里不像L2正则化项那样,需要再乘以1/2)
加上L1正则项后的损失函数:

对权重参数求导:

更新权重参数:



sgn(w)函数是w小于0时函数值为-1,等于0时为0,大于0时函数值为1
其中λ和n参数大于0,由权重参数的更新可以看出,当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
④L2正则化(岭回归)——效果使参数减小
L2正则化就是在代价函数后面再加上一个正则化项,即所有权重w的平方和,乘以λ/n需要再乘以1/2,方便后续的求导。
加上L2正则项后的损失函数:

对权重参数求导:


更新权重参数:

在不使用
正则化时,求导结果中w前系数为1,现在w前面系数为
,因为η、λ、n都是正的,所以 1-η*λ/n小于1,它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。根据奥卡姆剃刀法则可知,更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合刚刚好。
⑤为什么可以避免过拟合?
其实就是增加正则项后,使得参数变小了,模型简化,使得损失在避免过拟合和最小化损失之间进行了折中,以此来避免了过拟合。
⑥比较L1与L2
假设正则项为(p-范数):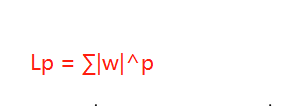

假设w向量分量由两个分量组成的,即w = w1 + w2,其中w,w1,w2均为向量,则当p取不同的值的时候就可以得到他们的曲线图,假设Lp=C,其中C为常数值,则当p取0.5,1,2,4的图如下

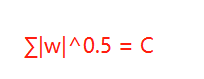


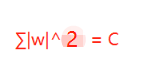
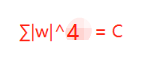
这时候我们假设原先的损失函数为:

则令其等于C,则可以绘制出曲线(平方误差项等值线):

上图是L1,L2,平方误差项取一系列的常数值C得到的(C1,C2,C3等)
当1-范数(L1)、2-范数(L2)、平方误差项都取相等的值时,我们损失函数为了取得最小的损失,因为正则化后的损失不再单单为了损失最小,而是还得考虑避免过拟合,因此需要在二者之间平衡,对应于图像中就是Lp与平方误差项曲线相交点。

蓝色的圆圈表示没有经过限制的损失函数在寻找最小值过程中,w的不断迭代(随最小二乘法,最终目的还是使损失函数最小)变化情况,表示的方法是等高线,z轴的值就是 E(w)
w∗ 最小值取到的点可以直观的理解为(帮助理解正则化),我们的目标函数(误差函数)就是求蓝圈+红圈的和的最小值(回想等高线的概念并参照式),而这个值通在很多情况下是两个曲面相交的地方
L1和平方误差项曲线相交于坐标点,即w1或w2等于0,但是L2和平方误差项曲线相较于非零点,这就说明了L1会比L2更易于得到稀疏解。但是L1曲线具有拐点,即并不是处处可导,给计算带来了很大的不便(这也是改进的方向所在)。而L2处处平滑,便于求导。
2)归一化(Normalization)
归一化就是改变数据分布,将大范围的数据限定在一个小范围,或者使其呈一定规律的分布
常用的归一化方法有:min-max normalization、Z-score standardization
①最小最大值归一化(min-max normalization)
将样本的范围限制在一定确定的小范围中,一般取【0,1】或者【-1,1】
归一化到【0,1】之间:

归一化到【-1,1】之间:


其中:max表示数据集中的最大值,min表示数据集中的最小值,mean表示数据集的均值
②0均值标准化(Z-score standardization)
参考:https://www.jianshu.com/p/26d198115908
规范了数据的分布,将数据分布改变成了标准的正态分布,即均值为0,标准差为1的分布
均值

标准差

归一化后的数值

③batch normalization(BN层)
参考:
https://www.cnblogs.com/guoyaohua/p/8724433.html
https://zhuanlan.zhihu.com/p/93643523
BN层常用于深度学习中,因为深度学习中的样本量大,一般都是分批进行训练的,即batch,因此进行归一化时是对一个batch进行归一化,而不是对整个训练集进行归一化


这里的BN其实本质就是zero-score standardization,只是这里添加了两个可以训练的参数r和β。在深度学习中,往往输入的是图像,每个batch是一部分图像,通过对这部分输入进行归一化后输入到下一层网络中,例子如下:

其中两个参数的意义?
稍微了解神经网络的读者一般会提出一个疑问:如果都通过BN,那么不就跟把非线性函数替换成线性函数效果相同了?这意味着什么?我们知道,如果是多层的线性函数变换其实这个深层是没有意义的,因为多层线性网络跟一层线性网络是等价的。这意味着网络的表达能力下降了,这也意味着深度的意义就没有了。所以BN为了保证非线性的获得,对变换后的满足均值为0方差为1的x又进行了scale加上shift操作(y=scale*x+shift),每个神经元增加了两个参数scale和shift参数,这两个参数是通过训练学习到的,意思是通过scale和shift把这个值从标准正态分布左移或者右移一点并长胖一点或者变瘦一点,每个实例挪动的程度不一样,这样等价于非线性函数的值从正中心周围的线性区往非线性区动了动。核心思想应该是想找到一个线性和非线性的较好平衡点,既能享受非线性的较强表达能力的好处,又避免太靠非线性区两头使得网络收敛速度太慢。
④什么情况下使用归一化方法?
这里主要讲BN层。在深度学习当中,每一层网络的输入都可以作为下一层网络的输入,开始的时候我们会将样本进行归一化后传输给网络,但是到了隐层,由于中间激活函数等非线性函数的映射,使得原本的归一化输入的数据分布发生了改变,这样使得下一层的输入的数据分布和上一层的数据分布是不一样的,即每一层输入的数据的分布都是变化的,这个问题称之为Internal Covariate Shift,这样就导致了训练的收敛速度变慢了。因此我们一般会在激活层之前,卷积层之后使用BN层,这样就能够保证每次输入到网络中的数据分布都是标准的正态分布,这也加快了训练的收敛速度。
⑤为什么归一化能够实现避免过拟合?
参考:https://www.cnblogs.com/guoyaohua/p/8724433.html
BN的基本思想其实相当直观:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所t以训练收敛慢,一般是整体分布逐渐往非线性函数(激活函数)的取值区间的上下限两端靠近(即梯度会逐渐趋于0,导致梯度消失,参数更新慢)(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域(也就是将最大的值),这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
THAT’S IT。其实一句话就是:对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。因为梯度一直都能保持比较大的状态,所以很明显对神经网络的参数调整效率比较高,就是变动大,就是说向损失函数最优值迈动的步子大,也就是说收敛地快。BN说到底就是这么个机制,方法很简单,道理很深刻。
可以看以下两个图:


没有归一化前
一开始没有归一化的时候数据分布是上左图蓝色曲线(第二高),这时候假设后面的激活函数是sigmoid函数(上右图第三高),可以发现大部分的数据都是分布在了sigmoid的左边部分,sigmoid的左边可以看到值逐渐趋于饱和区(即梯度趋于0),对应到下图的梯度来看,可以看到梯度值接近于0了,这时候就会使得参数的更新速度非常慢,使得模型训练的收敛速度很慢。
归一化后
而我们使用BN层后,数据分布呈均值为0方差为1的标准正态分布,这时候的数据分布如上左图的紫色所示。可见大部分数据都是集中在了sigmoid的梯度较大的部分,且关于0对称,这样一来,保证了梯度处于较大区域,梯度也就更新的快了。
怎么保证非线性(两个参数的作用)
我们不妨会有个疑问,既然每次输入到非线性层的时候要使得数据分布一致,那直接使用线性函数不就好了,但是我们需要知道的是,多层线性和一层线性的效果是一样的,这样会导致模型的表达能力不强,因此BN层为了能够得到非线性能够,又在原有的z-score归一化方法上加了两个参数r和β,就是为了能够找到一个线性和非线性的1平衡点,对应到上左图的曲线表征是,曲线变窄或变宽对应最高和最矮的曲线,这使得数据分布稍微地发生了移动,使得数据保留了一定的非线性。

⑥BN的优点
不仅仅极大提升了训练速度,收敛过程大大加快;
增加分类效果,一种解释是这是类似于Dropout的一种防止过拟合的正则化表达方式,所以不用Dropout也能达到相当的效果;
另外调参过程也简单多了,对于初始化要求没那么高,而且可以使用大的学习率等。
笔记

3)dropout(随机丢弃)——随机删除一些神经元,以在不同批量上训练不同的神经网络架构。
参考:
https://zhuanlan.zhihu.com/p/266658445
概念:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。每次迭代丢失的神经元都不一样,使得其训练得到了不一样的模型。


①过程
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图中虚线为部分临时被删除的神经元)
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
a. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
b. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
c. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
②为什么能够避免过拟合?
1、多平均模型:不同的固定神经网络会有不同的过拟合,随机丢弃训练得到不同的神经网络,多个神经网络取平均可能会抵消掉过拟合,多模型类似于多数投票取胜的策略;
2、减少神经元之间的依赖:由于两个神经元不一定同时有效,因此减少了两个神经元之间的依赖性,使得神经元更加地独立,迫使神经网络更加地鲁棒性;因为神经网络不应该对特点的特征敏感,而是对众多特征中学习规律;
3、生物进化:这个其实优点像遗传算法中采用的生物进化,为了适应新环境而会在雌雄间各取一半基因
4)early stopping(早停法)
概念:其实就是在发现验证集的正确率在下降的时候就停止训练,将最后的一组权重作为最终的参数。但是一般不会像下图这么的光滑,会出现震荡状,这时候我们可以依据相关的停止准则来进行早停
参考:https://blog.csdn.net/zwqjoy/article/details/86677030
https://blog.csdn.net/weixin_41449637/article/details/90201206


①第一类停止标准
当当前的验证集的误差比目前最低的验证集误差超过一定值时停止,这就需要记录每次迭代后的验证集误差,或者记录最小验证集误差即可

②第二类停止标准
记录当前迭代周期训练集上平均错误率相对于最低错误率的差值PK,计算第一类停止标准的值和PK的商,当商大于一定值时,停止

③第三类停止标准
连续s个周期错误率在增长时停止

④选择停止标准的规则

⑤ 优缺点





)





)

)



)


