👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——卷积神经网络(LeNet)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
现在多多少少是打下了一点基础了,因为我的本科毕业论文是NLP方向的,所以现在需要赶忙打好NLP模型所需要的知识,然后实现一些NLP方向的科研项目,用于我的9月份预推免。就剩一个月就要开始预推免了,大家一起加油!
序列模型
- 引入
- 统计工具
- 自回归模型
- 马尔可夫模型
- 因果关系
- 训练
- 预测
- 总结
引入
对于一部电影,随着时间的推移,人们对电影的看法会发生很大的变化。也就是说,因为时间上的连续性,一些事情的发生也是会互相影响的,如果这些序列重排就会失去意义。有几个例子:
1、音乐、语音、文本和视频都是连续的。
2、地震具有很强的相关性,即大地震发生后,很可能会有几次小余震。
3、人类之间的互动也是连续的,比如微博上互相打口水仗。
4、预测明天的股价要比过去的股价更困难(先见之明比时候诸葛亮要更难)。
统计工具
我们可以通过下式来进行预测:
x t 符合 P ( x t ∣ x t − 1 , . . . , x 1 ) x_t符合P(x_t|x_{t-1},...,x_1) xt符合P(xt∣xt−1,...,x1)
其中,x是非独立同分布的,因为时间上具有连续性,导致不同时间上的预测可能也会有相关性
自回归模型
从上面的式子可以看出,数据的数量随着t而变化:输入数据的数量这个数字将会随着我们遇到的数据量的增加而增加。因此我们需要使得这个计算更加简单,有两种策略:
1、自回归模型
假设显示情况下,相当长的序列
x t − 1 , . . . , x 1 x_{t-1},...,x_1 xt−1,...,x1
可能不是必要的,我们只需要满足某个长度τ的时间跨度,即使用观测序列
x t − 1 , . . . , x t − τ x_{t-1},...,x_{t-τ} xt−1,...,xt−τ
这样的好处是参数的数量总是不变的,至少在t>τ的时候是这样的,既然都是固定长度,那么我们就可以训练之前讲过的几乎所有模型了(线性模型,或者多层感知机等等)。这种模型被称为自回归模型,因此总是队自己执行回归。
2、潜变量自回归模型
如下图所示:
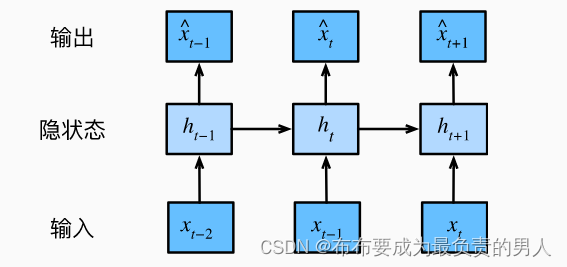
该图体现出,我们需要保留和更新对过去观测的总结:
h t h_t ht
并且同时更新预测
x t ^ \hat{x_t} xt^
这就产生了基于
x t ^ = P ( x t ∣ h t ) \hat{x_t}=P(x_t|h_t) xt^=P(xt∣ht)
的估计,以及公式
h t = g ( h t − 1 , x t − 1 ) h_t=g(h_{t-1},x_{t-1}) ht=g(ht−1,xt−1)
更新的模型。
而由于h从未被观测到,所以这类模型也叫作潜变量自回归模型。
而整个序列的估计值都将通过以下方式获得:
P ( x 1 , . . . , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 , . . . , x 1 ) P(x1,...,x_T)=\prod_{t=1}^TP(x_t|x_{t-1},...,x_1) P(x1,...,xT)=t=1∏TP(xt∣xt−1,...,x1)
马尔可夫模型
我们之前在估计的时候,选择的是在当前时序的前τ个数,只要和当前时序之前的所有数计算得来的结果近似,就说序列满足马尔可夫条件。特别是当τ=1时,得到一个一阶马尔可夫模型:
P ( x ) = P ( x 1 , . . . , x T ) = ∏ t = 1 T P ( x t ∣ x t − 1 ) 当 P ( x 1 ∣ x 0 ) = P ( x 1 ) P(x)=P(x_1,...,x_T)=\prod_{t=1}^TP(x_t|x_{t-1})当P(x_1|x_0)=P(x_1) P(x)=P(x1,...,xT)=t=1∏TP(xt∣xt−1)当P(x1∣x0)=P(x1)
因果关系
原则上,将P(x)倒序展开也没啥问题,可以基于条件概率公式写成:
P ( x 1 , . . . , x T ) = ∏ t = T 1 P ( x t ∣ x t + 1 , . . . , x T ) P(x_1,...,x_T)=\prod_{t=T}^1P(x_t|x_{t+1},...,x_T) P(x1,...,xT)=t=T∏1P(xt∣xt+1,...,xT)
但是在物理上这并不好实现,毕竟理论上一般没有根据未来的事情推测过去的事情。
训练
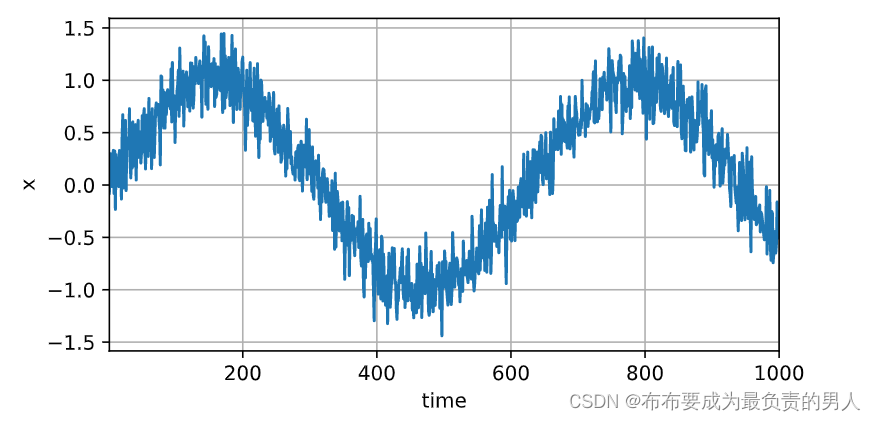
首先生成一些数据,使用正弦函数和一些可加性噪声来生成序列数据。(现在开始用notebook了)
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2lT = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))
接下来,将该序列转换为特征-标签对,这里我们使用前600个“特征-标签”对进行训练:
tau = 4
features = torch.zeros((T - tau, tau))
for i in range(tau):features[:, i] = x[i: T - tau + i]
labels = x[tau:].reshape((-1, 1))batch_size, n_train = 16, 600
# 只有前n_train个样本用于训练
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),batch_size, is_train=True)
在这里,我们使用一个相当简单的架构训练模型: 一个拥有两个全连接层的多层感知机,ReLU激活函数和平方损失。
# 初始化网络权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)# 一个简单的多层感知机
def get_net():net = nn.Sequential(nn.Linear(4, 10),nn.ReLU(),nn.Linear(10, 1))net.apply(init_weights)return net# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')
下面开始训练模型:
def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr) # 一种内置的优化器,可自行去了解for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, 'f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')net = get_net()
train(net, train_iter, loss, 5, 0.01)
运行结果:
epoch 1, loss: 0.061968
epoch 2, loss: 0.054118
epoch 3, loss: 0.051940
epoch 4, loss: 0.050062
epoch 5, loss: 0.050939
预测
训练损失看起来不大,那我们可以开始进行单步预测(也就是检查模型预测下一个时间步的能力):
onestep_preds = net(features)
d2l.plot([time, time[tau:]],[x.detach().numpy(), onestep_preds.detach().numpy()], 'time','x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))
结果:
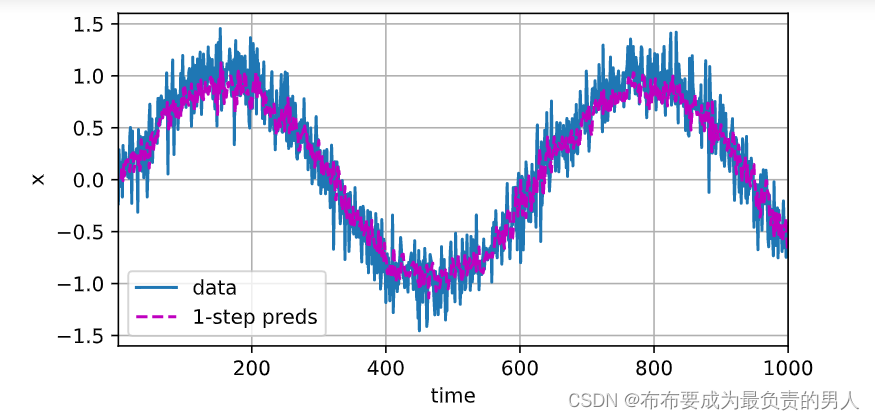
单步预测的效果不错,即便预测的时间步超过了600+4(n_train+tau),结果看起来也还是可以的,但是如果我们继续向前迈进,那么接下来的预测值就要基于之前的预测值和原本值或者完全基于之前的预测值,即:
x ^ 605 = f ( x 601 , x 602 , x 603 , x 604 ) x ^ 606 = f ( x 602 , x 603 , x 604 , x ^ 605 ) x ^ 607 = f ( x 603 , x 604 , x ^ 605 , x ^ 606 ) x ^ 608 = f ( x 604 , x ^ 605 , x ^ 605 , x ^ 607 ) x ^ 609 = f ( x ^ 605 , x ^ 606 , x ^ 607 , x ^ 608 ) \hat{x}_{605}=f(x_{601},x_{602},x_{603},x_{604})\\ \hat{x}_{606}=f(x_{602},x_{603},x_{604},\hat{x}_{605})\\ \hat{x}_{607}=f(x_{603},x_{604},\hat{x}_{605},\hat{x}_{606})\\ \hat{x}_{608}=f(x_{604},\hat{x}_{605},\hat{x}_{605},\hat{x}_{607})\\ \hat{x}_{609}=f(\hat{x}_{605},\hat{x}_{606},\hat{x}_{607},\hat{x}_{608}) x^605=f(x601,x602,x603,x604)x^606=f(x602,x603,x604,x^605)x^607=f(x603,x604,x^605,x^606)x^608=f(x604,x^605,x^605,x^607)x^609=f(x^605,x^606,x^607,x^608)
因此我们必须使用我们自己的预测(而不是原始数据)来进行多步预测:
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))d2l.plot([time, time[tau:], time[n_train + tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train + tau:].detach().numpy()], 'time','x', legend=['data', '1-step preds', 'multistep preds'],xlim=[1, 1000], figsize=(6, 3))
结果:

预测不理想的原因是:预测误差不断累加。这种现象就像是24小时天气预报,超过24小时以后,精度会迅速下降。
总结
1、时序模型中,当前数据与之前观察到的数据相关
2、自回归模型使用自身过去数据预测未来
3、马尔可夫模型假设当前只跟最近少数数据相关,从而简化模型
4、潜变量模型使用潜变量来概括历史信息








)








)

