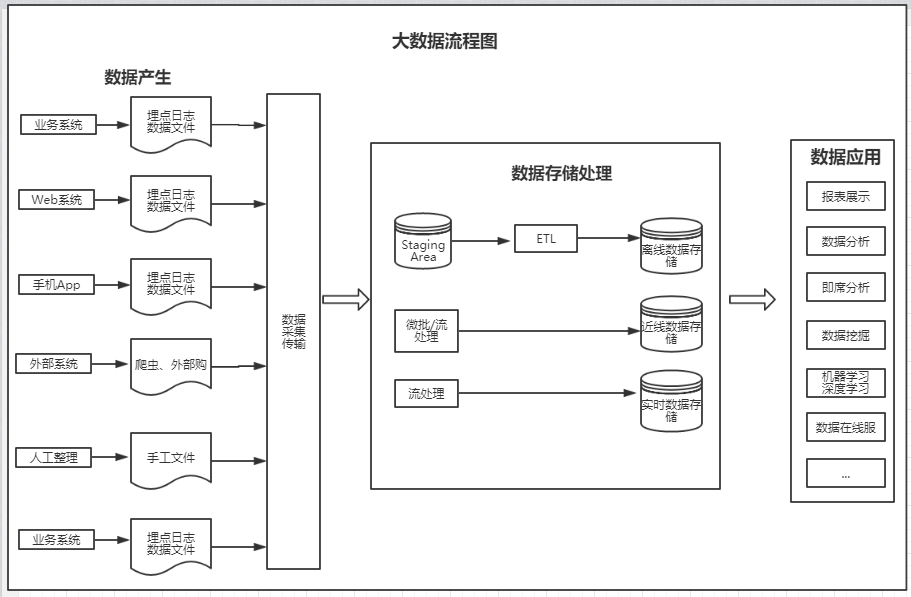
1、大数据流程图
2、大数据各个环节主要技术
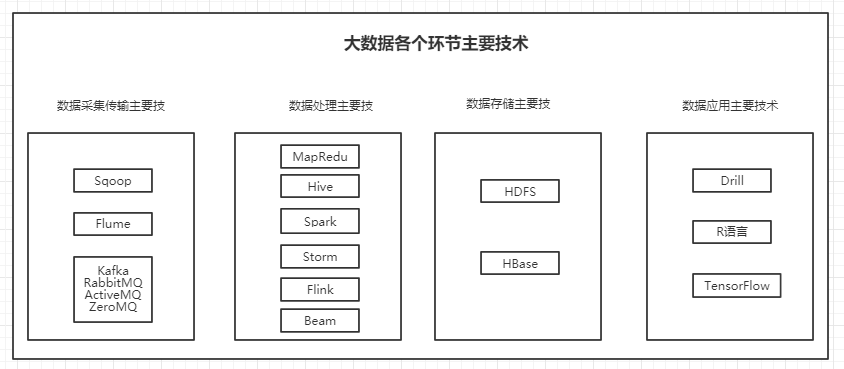
2.1、数据处理主要技术
Sqoop:(发音:skup)作为一款开源的离线数据传输工具,主要用于Hadoop(Hive) 与传统数据库(MySql,PostgreSQL)间的数据传递。它可以将一个关系数据库中数据导入Hadoop的HDFS中,
也可以将HDFS中的数据导入关系型数据库中。
Flume:实时数据采集的一个开源框架,它是Cloudera提供的一个高可用用的、高可靠、分布式的海量日志采集、聚合和传输的系统。目前已经是Apache的顶级子项目。使用Flume可以收集诸如日志、时间等数据
并将这些数据集中存储起来供下游使用(尤其是数据流框架,例如Storm)。和Flume类似的另一个框架是Scribe(FaceBook开源的日志收集系统,它为日志的分布式收集、统一处理提供一个可扩展的、高容错的简单方案)
Kafka:通常来说Flume采集数据的速度和下游处理的速度通常不同步,因此实时平台架构都会用一个消息中间件来缓冲,而这方面最为流行和应用最为广泛的无疑是Kafka。它是由LinkedIn开发的一个分布式消息系统,
以其可以水平扩展和高吞吐率而被广泛使用。目前主流的开源分布式处理系统(如Storm和Spark等)都支持与Kafka 集成。
Kafka是一个基于分布式的消息发布-订阅系统,特点是速度快、可扩展且持久。与其他消息发布-订阅系统类似,Kafka可在主题中保存消息的信息。生产者向主题写入数据,消费者从主题中读取数据。
作为一个分布式的、分区的、低延迟的、冗余的日志提交服务。和Kafka类似消息中间件开源产品还包括RabbiMQ、ActiveMQ、ZeroMQ等。
MapReduce:
MapReduce是Google公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度抽象为两个函数:map和reduce。MapReduce最伟大之处在于其将处理大数据的能力赋予了普通开发人员,
以至于普通开发人员即使不会任何的分布式编程知识,也能将自己的程序运行在分布式系统上处理海量数据。
Hive: MapReduce将处理大数据的能力赋予了普通开发人员,而Hive进一步将处理和分析大数据的能力赋予了实际的数据使用人员(数据开发工程师、数据分析师、算法工程师、和业务分析人员)。
Hive是由Facebook开发并贡献给Hadoop开源社区的,是一个建立在Hadoop体系结构上的一层SQL抽象。Hive提供了一些对Hadoop文件中数据集进行处理、查询、分析的工具。它支持类似于传统RDBMS的SQL语言
的查询语言,一帮助那些熟悉SQL的用户处理和查询Hodoop在的数据,该查询语言称为Hive SQL。Hive SQL实际上先被SQL解析器解析,然后被Hive框架解析成一个MapReduce可执行计划,
并按照该计划生产MapReduce任务后交给Hadoop集群处理。
Spark:尽管MapReduce和Hive能完成海量数据的大多数批处理工作,并且在打数据时代称为企业大数据处理的首选技术,但是其数据查询的延迟一直被诟病,而且也非常不适合迭代计算和DAG(有限无环图)计算。
由于Spark具有可伸缩、基于内存计算能特点,且可以直接读写Hadoop上任何格式的数据,较好地满足了数据即时查询和迭代分析的需求,因此变得越来越流行。
Spark是UC Berkeley AMP Lab(加州大学伯克利分校的 AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,它拥有Hadoop MapReduce所具有的优点,但不同MapReduce的是,
Job中间输出结果可以保存在内存中,从而不需要再读写HDFS ,因此能更好适用于数据挖掘和机器学习等需要迭代的MapReduce算法。
Spark也提供类Live的SQL接口,即Spark SQL,来方便数据人员处理和分析数据。
Spark还有用于处理实时数据的流计算框架Spark Streaming,其基本原理是将实时流数据分成小的时间片段(秒或几百毫秒),以类似Spark离线批处理的方式来处理这小部分数据。
Storm:MapReduce、Hive和Spark是离线和准实时数据处理的主要工具,而Storm是实时处理数据的。
Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架。Storm对于实时计算的意义相当于Hadoop对于批处理的意义。Hadoop提供了Map和Reduce原语,使对数据进行批处理变得非常简单和优美。
同样,Storm也对数据的实时计算提供了简单的Spout和Bolt原语。Storm集群表面上和Hadoop集群非常像,但是在Hadoop上面运行的是MapReduce的Job,而在Storm上面运行的是Topology(拓扑)。
Storm拓扑任务和Hadoop MapReduce任务一个非常关键的区别在于:1个MapReduce Job最终会结束,而1一个Topology永远运行(除非显示的杀掉它,),所以实际上Storm等实时任务的资源使用相比离线
MapReduce任务等要大很多,因为离线任务运行完就释放掉所使用的计算、内存等资源,而Storm等实时任务必须一直占有直到被显式的杀掉。
Storm具有低延迟、分布式、可扩展、高容错等特性,可以保证消息不丢失,目前Storm, 类Storm或基于Storm抽象的框架技术是实时处理、流处理领域主要采用的技术。
Flink:在数据处理领域,批处理任务和实时流计算任务一般被认为是两种不同的任务,一个数据项目一般会被设计为只能处理其中一种任务,例如Storm只支持流处理任务,而MapReduce, Hive只支持批处理任务。
Apache Flink是一个同时面向分布式实时流处理和批量数据处理的开源数据平台,它能基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。Flink在实现流处理和批处理时,
与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来。Flink完全支持流处理,批处理被作为一种特殊的流处理,只是它的数据流被定义为有界的而已。基于同一个Flink运行时,
Flink分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
Beam:Google开源的Beam在Flink基础上更进了一步,不但希望统一批处理和流处理,而且希望统一大数据处理范式和标准。Apache Beam项目重点在于数据处理的的编程范式和接口定义,并不涉及具体执行引擎
的实现。Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上。
Apache Beam主要由Beam SDK和Beam Runner组成,Beam SDK定义了开发分布式数据处理任务业务逻辑的API接口,生成的分布式数据处理任务Pipeline交给具体的Beam Runner执行引擎。Apache Flink
目前支持的API是由Java语言实现的,它支持的底层执行引擎包括Apache Flink、Apache Spark和Google Cloud Flatform。
2.2、数据存储主要技术
HDFS:Hadoop Distributed File System,简称FDFS,是一个分布式文件系统。它有一定高度的容错性和高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS提供了一个高容错性和高吞吐量的海量数据存储解决方案。
在Hadoop的整个架构中,HDFS在MapReduce任务处理过程在中提供了对文件操作的和存储的的支持,MapReduce在HDFS基础上实现了任务的分发、跟踪和执行等工作,并收集结果,两者相互作用,共同完成了
Hadoop分布式集群的主要任务。
HBase:HBase是一种构建在HDFS之上的分布式、面向列族的存储系统。在需要实时读写并随机访问超大规模数据集等场景下,HBase目前是市场上主流的技术选择。
HBase技术来源于Google论文《Bigtable :一个结构化数据的分布式存储系统》。如同Bigtable利用了Google File System提供的分布式数据存储方式一样,HBase在HDFS之上提供了类似于Bigtable的能力。
HBase解决了传递数据库的单点性能极限。实际上,传统的数据库解决方案,尤其是关系型数据库也可以通过复制和分区的方法来提高单点性能极限,但这些都是后知后觉的,安装和维护都非常复杂。
而HBase从另一个角度处理伸缩性的问题,即通过线性方式从下到上增加节点来进行扩展。
HBase 不是关系型数据库,也不支持SQL,它的特性如下:
1、大:一个表可以有上亿上,上百万列。
2、面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3、稀疏:为空(null)的列不占用存储空间,因此表可以设计的非常稀疏。
4、无模式::每一行都有一个可以排序的主键和任意多的列。列可以根据需求动态增加,同一张表中不同的行可以有截然不同的列。
5、数据多版本:每个单元的数据可以有多个版本,默认情况下,版本号字段分开,它是单元格插入时的时间戳。
6、数据类型单一:HBase中数据都是字符串,没有类型。
2.3、数据应用主要技术
数据有很多应用方式,如固定报表、即时分析、数据服务、数据分析、数据挖掘和机器学习等。下面说下即时分析Drill框架、数据分析R语言、机器学习TensorFlow框架。
Drill:Apache Drill是一个开源实时大数据分布式查询引擎,目前已成为Apache的顶级项目。Drill开源版本的Google Dremel。Dremel是Google的“交互式”数据分析系统,可以组建成规模上千的集群,处理PB级别的数据。
MapReduce处理数据一般在分钟甚至小时级别,而Dremel将处理时间缩短至秒级,即Drill是对MapReduce的有力补充。Drill兼容ANSI SQL语法作为接口,支持本地文件、HDFS、Hive、HBase、MongoDb作为
存储的数据查询。文件格式支持Parquet、CSV、TSV以及Json这种无模式(schema-free)数据。所有这些数据都像传统数据库的表查询一样进行快速实时查询。
R语言:R是一种开源的数据分析解决方案。R流行原因如下:
1、R是自由软件:完全免费、开源。可在官方网站及其镜像中下载任何有关的安装程序、源代码、程序包及其源代码、文档资料,标准的安装文件自身就带有许多模块和内嵌统计函数,安装好后可以直接实现许多
常用的统计功能。
2、R是一种可编程的语言:作为一个开放的统计编程环境,R语言的语法通俗易懂,而且目前大多数新的统计方法和技术都可以在R中找到。
3、R具有很强的互动性:除了图形输出在另外的窗口,它的熟入输出都是在一个窗口进行的,输入语法中如果有错马上会在窗口中给出提示,对以前输入过的命令有记忆功能,可以随时再现、编辑、修改以满足
用户的需要,输出的图形可以直接保存为JPG、BMP、PNG等图片格式,还可以直接保存为PDF文件。此外,R语言和其它编程语言和数据库直接有很好的接口。
TensorFlow:TensorFlow是一个非常灵活的框架,它能够运行在个人电脑或服务器的单个/多个cpu和GPU上,甚至是移动设备上,它最早是为了研究机器学习和深度神经网络而开发的,后来因为通用而开源。
TensorFlow是基于数据流图的处理框架,TensorFlow节点表示数学运算,边表示运算节点之间的数据交互。TensorFlow从字母意义上来讲有两层含义:一是Tensor代表的是节点之间传递的数据,通常这个数据
是一个多维度矩阵(multidimensional data arrays)或一维向量;二是Flow指的数据流,形象理解就是数据按照流的形式进入数据运算图的各个节点。
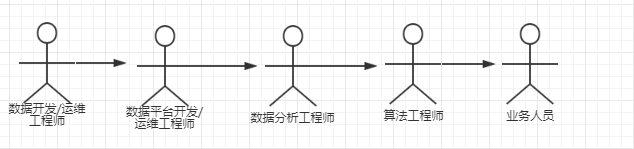
3、数据相关从业者和角色
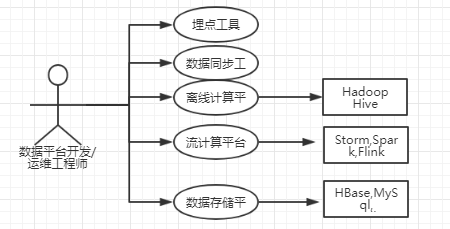
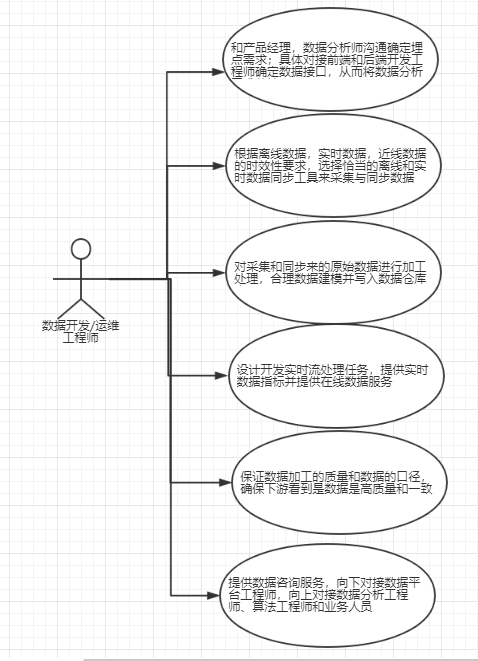
4、数据埋点
后台数据库和日志文件一般只能满足常规的统计分析,对于具体的产品和项目来说,一般还要根据项目的目标和分析需求进行针对性的“数据埋点”工作,所谓埋点:就是在额外的正常功能逻辑上添加针对性的逻辑统计,即期望的
事件是否发生,发生后应该记录那些信息,比如用户在当前页面是否用鼠标滚动页面、有关的页面区域是否曝光了、当前的用户操作的的时间是多少、停留时长多少、这些都需要前端工程师进行针对性的埋点才能满足有关的分析需求。
数据埋点工作一般由产品经理和分析师预先确定分析需求,然后由数据开发团队对接前端和后端开发完成具体的埋点工作。
参考资料:《离线和实时大数据开发实战》




![[TOOLS] 移动端调试进行时 - whistle](http://pic.xiahunao.cn/[TOOLS] 移动端调试进行时 - whistle)




)





的算法研究)



