
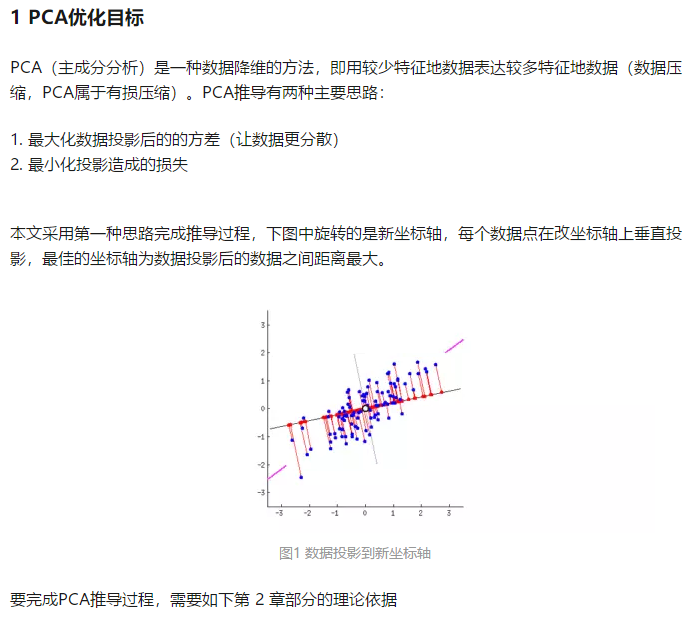





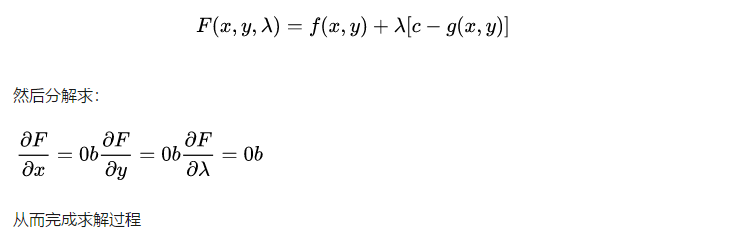


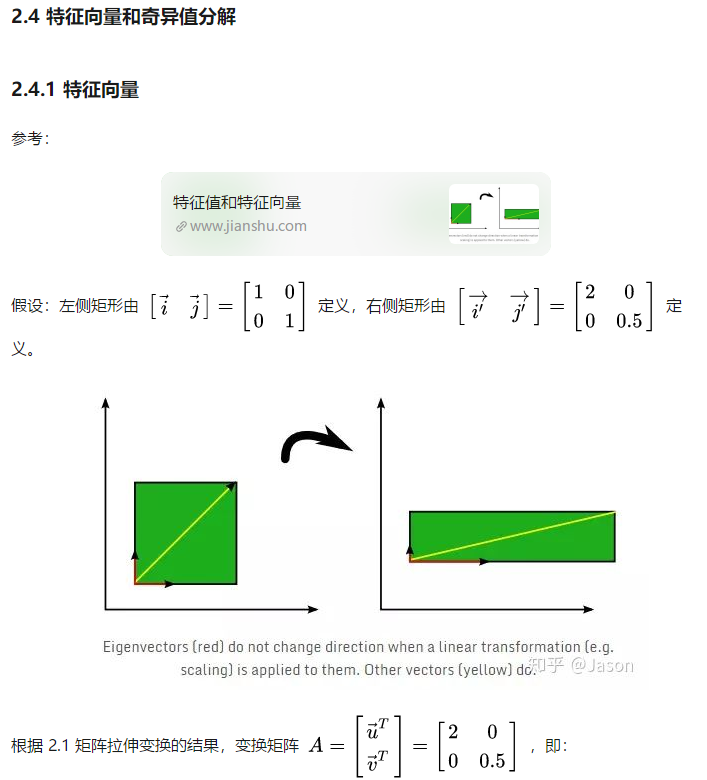










输入数据矩阵->计算每条记录的平均值和标准差->计算协方差矩阵->得到协方差矩阵的所有特征值和特征向量->对特征值进行从大到小的排序,并且得到与之对应的特征向量

PCA是无监督的。没有标签也可以做,是基于方差的。
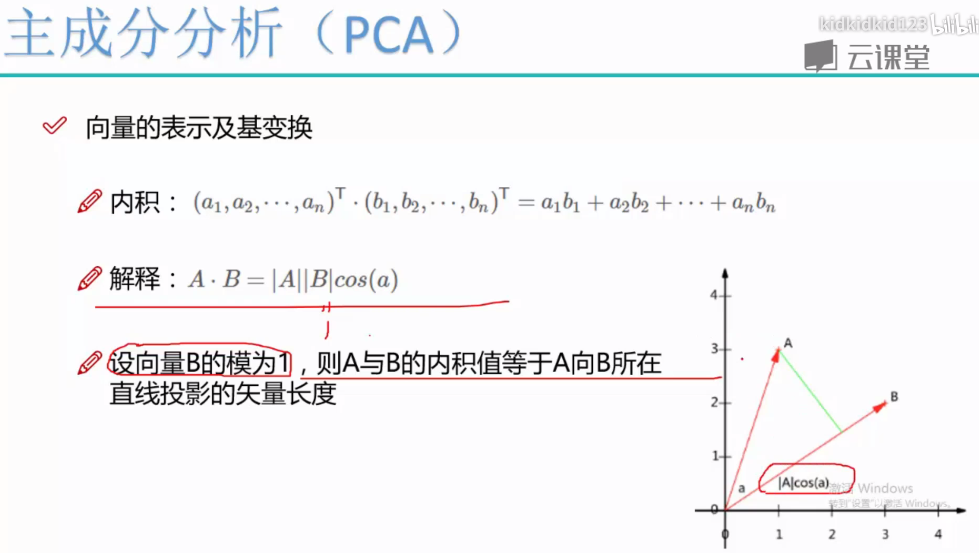






精髓在于将协方差矩阵进行相似对角化,是主对角线上的值尽可能的大,其余位置尽可能的小。



输入数据矩阵->计算每条记录的平均值和标准差->计算协方差矩阵->得到协方差矩阵的所有特征值和特征向量->对特征值进行从大到小的排序,并且得到与之对应的特征向量
PCA是无监督的。没有标签也可以做,是基于方差的。
精髓在于将协方差矩阵进行相似对角化,是主对角线上的值尽可能的大,其余位置尽可能的小。
转载于:https://www.cnblogs.com/invisible2/p/11457671.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/247021.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!

)
)
)

深度学习(Deep Learning)资料)


到图卷积(Graph Convolution):漫谈图神经网络模型 (三))
)








