前言
最近看到了好多卡通角色的肢体驱动的东东,感觉是时候发挥一下读研时候学的东西了,而且虽然现在不炼丹了,但是还是得保持吃丹的技能。这个项目找了很多很多代码进行测试,最终集成了一个3D姿态估计和人脸关键点提取的代码。
国际惯例,参考博客:
2D姿态估计HRNet
3D姿态估计SemGCN
人脸检测mtcnn
68人脸关键点提取
人头方向估算
Unity官方文档BS的获取和控制
再加和本博文所实现功能类似的demo网址:
效果超级好:上传视频输出同样动作的FBX模型
开源:基于单目摄像头的3D人体和手部姿态估计附带卡通角色驱动
开源:之前解析过的卡通角色驱动算法,内嵌到unity中了
开源:BS表情驱动案例
简介
先放两张结果图表明最终实现功能,分别是卡通角色肢体驱动、表情驱动。以下视频为了上传,采用了抽帧处理。


完整视频DEMO可以点击如下链接:
- 卡通角色身体驱动:链接: https://pan.baidu.com/s/1o87W9EMDWvGboqOxjXxaiQ 提取码: rgj7
- 卡通角色表情驱动:链接: https://pan.baidu.com/s/1R75q7wu48LwJr54BWe-RVw 提取码: 2dr6
实现方案
本文算法主要涉及两大模块:
- 肢体驱动部分:深度学习做3D姿态估计、unity做骨骼驱动(注意动力学相关内容)
- 表情驱动部分:深度学习做人脸关键点检测和人头方向估算以及表情系数,
unity做BlendShape表情驱动
找了一些方法将深度学习算法嵌入到unity中,发现有点复杂,很多库而且不宜扩展;即想到采用python+flask部署的方法将深度学习作为后台接受unity发过来的请求;而unity则是前端,发送各种请求,比如请求将视频中人的3D姿态或者人脸表情计算出来,返回结果到unity中。
流程图可以戳这里查看:https://www.processon.com/view/link/5fe5556007912910e478a6d2
服务端
主要是深度学习模块,所采用的模型全部在参考博客,但是本人做了一下合成,分别设计了四个接口:
- 接收视频:因为算法实时性不太好,所以采用服务端上传视频,然后使用算法处理对应功能的方法
- 3D关键点提取:结合2D姿态估计和3D姿态估计算法,直接端到端,输入视频输出3D关节坐标,目前结合的算法在2060上能达到5-10FPS,大部分时间耗费在人体检测上,用的faster-rcnn
- 2D人脸关键点提取:最开始使用2D人脸关键点检测,发现效果不是特别好,所以加入了
mtcnn进行人脸框检测,然后再输入到关键点检测模型中去,最后根据关键点计算头部的表情和方向,大约10FPS,主要耗费在人脸框检测上 - 2D人脸关键点实时检测:当时为了测试人脸关键点与unity交互的实时性,留了一个接口,unity端不需要上传视频,直接将每帧图片发送到服务端预测,发现这样非常卡,可能交互也花费时间了,或者其他原因
客户端
主要是unity展示端和驱动端,分为三个模块:
- 开始界面:输入请求地址、选择上传视频功能、选择肢体/表情驱动功能,选择对应功能后将会在服务端处理数据,最后返回到客户端
- 肢体驱动界面:根据客户端接收到的关节3D数据,结合unity的
lookat函数和简单的动力学修正进行肢体驱动 - 表情驱动界面:有离线和在线的,离线版和肢体驱动一样从服务端拿到对应的表情数据后对人头进行驱动,利用颈部关节旋转量和
BlendShape表情系数控制
难点技术
整个工程的设计花费了接近一个月的时间才搭起来,毕竟996嘛,你们懂得,每天还得熬会夜。
其中还是有一些技术难点的,分为深度学习部分和驱动部分。
深度学习算法部分
本来是奔着实时驱动去的,结果发现很难找到实时性较高且效果稳定的算法,最后实在没办法,抛弃了实时功能(但是保留了接口,便于大佬们测试),采用上传视频,处理视频,返回整个视频结果的模式进行交互。
难点有两块:
-
2D姿态估计和3D姿态估计算法的集成:找算法的时候发现很多3D姿态估计的算法是在假设2D关键点坐标提供的情况下估算3D坐标的,所以必须去尝试寻找2D姿态估计算法,有的算法直接通过视频估算人体坐标如openpose,而有的是检测到人体框再去估算人体方向如最近的HRNet;但是我觉得还是先检测到人体框再去估算会靠谱点,但是速度应该没有直接端到端快。最终采用了HRNet+SemGCN的方法从视频中提取3D关节坐标
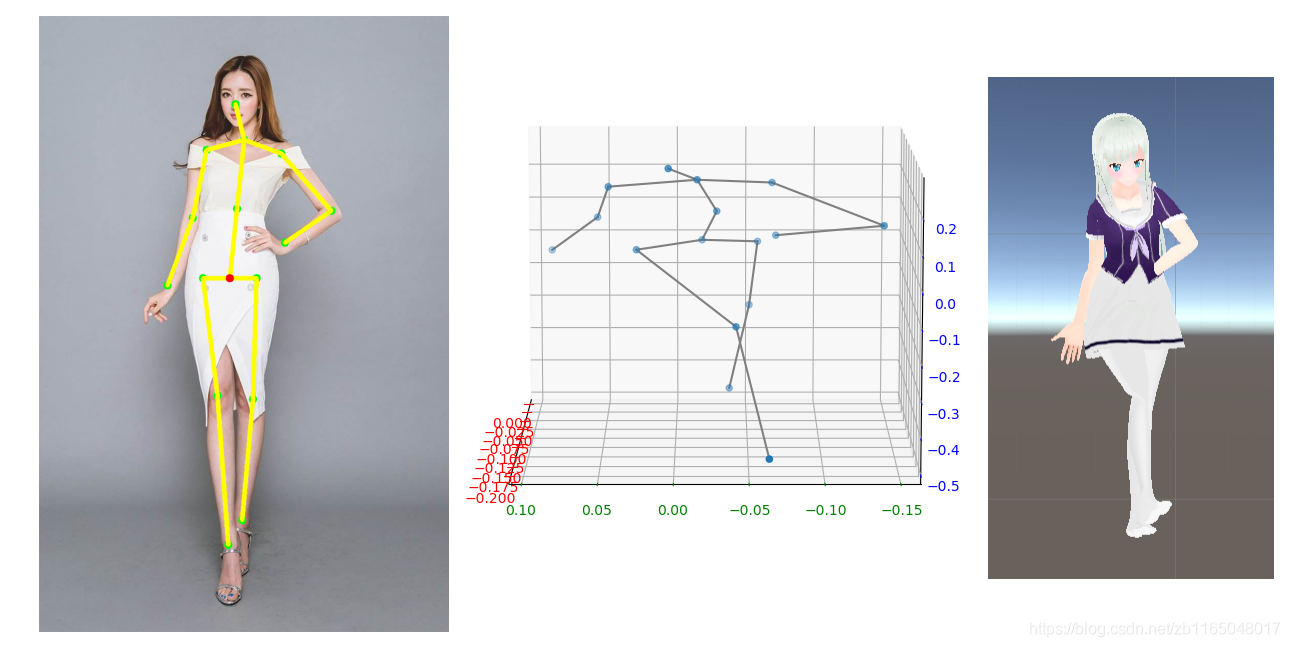
-
人脸表情:因为表情动画通常使用BS来驱动,每个BS通常代表动画的某个表情,多个BS加上不同的系数能组合出不同的表情,但是直接做表情识别的泛化性太差了,不如直接用关键点计算,所以使采用mtcnn+HRNet进行视频中人脸关键点的提取;然后网上又有很多基于关键点去计算人头朝向的算法,随便找了一个;还有就是表情,仅仅做了简单的睁眼闭眼、张嘴程度的计算,具体方法可以看源码。
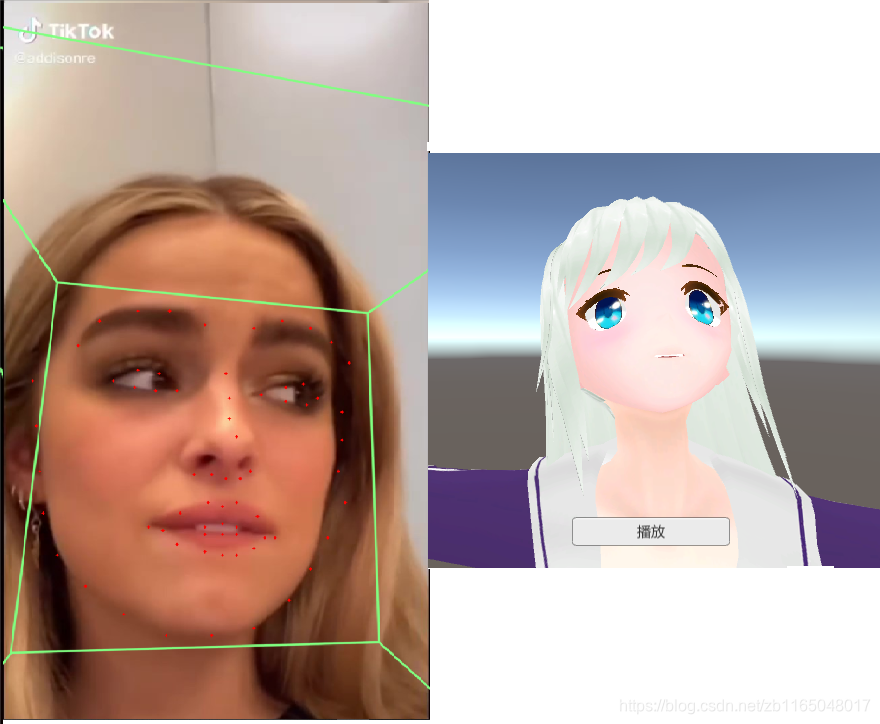
驱动部分
分为肢体驱动和表情驱动,所以也是两个难点:
- 肢体驱动:最开始打算用
unity自带的IK来做,但是它只能用来控制关节末端如双手双脚,无法控制肘部等中间关节,然后想到先把中间关节位置调整好,再去用IK控制末端,结果发现调整中间关节会影响到Ik的计算;实在没辙,直接全部手动控制,采用lookat函数,让每根骨骼的方向与真人的对应骨骼方向保持一致,但是人体运动不仅仅是骨骼方向一致,还要符合人体动力学,所以对每个关节的自转又进行了控制,下图就是未矫正和矫正后的肘关节案例;可能模型看的不太清楚,大概意思就是肘部不能直接朝上弯曲,必须让大臂转动一点以后再去弯曲才比较自然。

- 表情驱动:这个相对来说比较简单,需要注意的是利用
solvePnP、Rodrigues、decomposeProjectionMatrix计算得到的欧拉角和unity中可能有点区别,注意尝试变换一下就行了,可能是定义的标准3D模型和人脸刚好相反的原因,导致正常情况下的人头扭转角度接近180度。表情部分因为没太多的BS可控制,不然还能根据关键点细分一下各种其他的表情进行驱动。
待优化点
- 找点好用的深度学习模型
- 利用FABRIK动力学算法替代
lookat - 尝试实时驱动
- 导出BVH动作文件
与开源ThreeDPoseTracker的区别
最终效果看起来会比threeD开源效果差;但是优势如下:
- 代码清晰度提高,threed的代码一般人很难看懂(当然我有解析博客可辅助理解threed源码)
- 不同功能区分度高,threed的代码将深度学习和模型驱动都放到unity中造成复杂操作,我将深度学习封装到python,保留unity中的骨骼驱动,不同的人群可以优化不同内容(主要考虑同时懂深度学习和unity的人不多)
- 代码简化了很多,threed的代码几千行,我的代码条理清晰做了很多简化,只需几百行,提供了可理解空间和优化空间
如何提升效果比ThreeDPoseTracker好
- 自行加入平滑算法(我的其它博客有解析平滑算法),懂unity的在unity中加,懂python的在python中加,不冲突
- 懂深度学习的,将深度学习替换为最新且效果稳定点的算法模型
后记
整个项目的内容看似少,但是细节很多,各种深度学习算法的集成、测试;unity中lookat在关节上的应用;动力学矫正;unity+flask通信等。
所有功能可以按照博客介绍的流程和算法完整复现,所以本工程代码打算便宜付费开源,找到的算法LICENSE均允许商用,后续打算攒够钱买个Kinect玩玩驱动,还有手指部分也想用买个设备试试;大家别怪我,毕竟我之前所有的博客都是免费开源的;等钱够了设备到了,再来开源其它更好玩的算法。
当然,开发过程中涉及到的知识点我会不断在博客中更新尽请关注公众号,目前打算把公众号的基础知识部分补充完毕再来折腾这篇博客涉及到的知识。
源码获取请关注微信公众号,发送“卡通角色驱动”,或者直接在CSDN上下载:卡通角色驱动的代码,若接受19.9元付费购买源码,可在https://download.csdn.net/download/zb1165048017/13693467下载,如有问题请加公众号回复的微信。
代码运行说明
环境
已测试运行环境:
Unity:2019.13.f1c1
python:3.7.6
关于python各种包的版本,可以查看piplist.txt
运行
先去\Server\HRNet\pytorch\pose_coco文件夹按照web.txt下载用于2D姿态估计的权重文件。
然后运行run_client.bat运行本地服务端。
最后进入unity运行FirstScene
如果你的client在本地运行,那么可以直接用IP地址:127.0.0.1和端口6666作为交互网址 如果是局域网内其它电脑,可以使用在服务端用ipconfig查看IP地址,一般是192.168.xx.xx。
有三个功能:
肢体驱动:需要先上传视频,当前状态显示为选择功能时,可以点击肢体驱动按钮,即可通过服务端自动计算肢体数据,然后自动进入肢体驱动界面,点击播放。
表情驱动(实时):填入视频地址后,无需点击上传视频,然后点击表情驱动(实时)按钮,进入实时表情驱动,但是这个目前很卡,因为每一帧视频都是从客户端传递给服务器计算表情相关数据再返回,算法实时性不太好
表情驱动(非实时):和肢体驱动类似,也是先上传视频,然后再进行驱动。
不负责教学python入门,不负责教学unity和C#入门,这俩语言工具不会不愿学的请绕道。



)













: File /data/hadoop-roo)
