The Rendering Pipeline
渲染表现差有可能取决于CPU端(CPU Bound)也有可能取决于GPU(GPU Bound).调查CPU-bound的问题相对简单,因为CPU端的工作就是从硬盘或者内存中加载数据并且调用图形APU指令。想找到GPU-bound的原因会困难很多,因为在渲染管线中很多地方都有可能是引起问题的原因。解决GPU 瓶颈的问题我们甚至可能得使用猜测法和排除法。
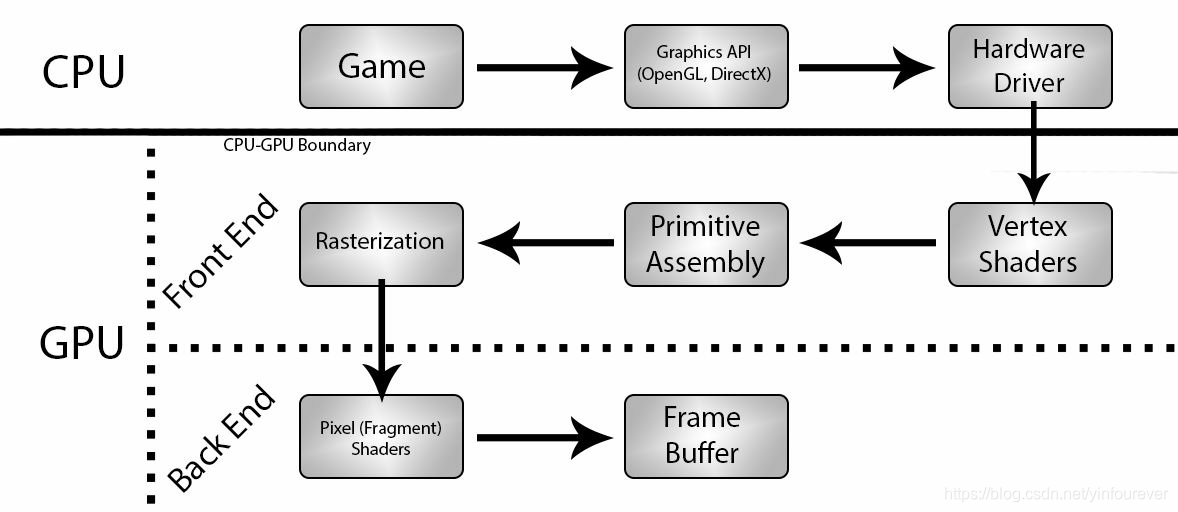
图中第一行展示了CPU所做的工作,包括了通过硬件驱动调用图形API以及把渲染指令传输到GPU中(通过Command Buffer)
下边的两行展示了GPU所做的工作,还可以再细分为Frond End 和 Back End两部分。
The GPU Front End
Front End是渲染管线中处理顶点(vertex)数据的部分。它从cpu接收mesh数据和Draw Call请求。GPU随后会收集所有vertex数据并且把它们传入到Vertex Shaders中。在Vertex Shader中可以对顶点数据进行修改和处理,最后输出的数据数量和输入时保持1比1的比例(就是比如输入100个顶点,处理后输出的数据也是100个)。接下来顶点数据会组装成片元(最常见的是三角形片元)并进行光栅化,根据顶点的位置和摄像机的视野会决定哪些像素会出现在最终的渲染结果中。这个过程输出的是一个pixels的list,也就是常说的fragments,它将会用于Back End 的处理阶段。
Vertex Shaders的输出还可以用于Tessellation,它是在几何着色器中处理(Geometry Shaders)。Geometry Shaders和Vertex Shaders 类似,但是它是1对多的关系,也因此可以产生更多的几何细节。
总结下就是对于Front End:Vertex Shaders -- Geometry Shaders(如果有) -- 光栅化 -- 输出fragments给Back End处理。
The GPU Back End
Back End是渲染管线中处理Fragments的过程。每个Fragment将会传入Fragment Shader中,这些Shader比Vertex Shader会复杂许多,比如可以包含Depth test(深度测试),alpha test(透明度测试),图片采样,光照计算,阴影计算等等。
经过这个过程处理后的数据就会传入Frame Buffer中,通常渲染API中会有两个Frame Buffer,一个用于显示当前的,另一个会在GPU完成渲染指令后用于存储下一帧要显示的内容。当GPU接收到Swap Buffer指令(每一帧CPU发送的最后一个指令)后,连个frame buffer会交换,这样新的一帧会被渲染出来,这个过程会在应用程序渲染的过程中不断重复。
在Back End部分,会有两个因素很有可能成为瓶颈:Fill Rate(填充率) 和 Memory Bandwidth(内存带宽)
Fill Rate
Fill rate和GPU渲染fragments的速度相关。一个fragment仅仅是有可能会最终成为一个像素,如果它在fragment shader中某个test过程失败了,就会被舍弃,这种方式能给性能带来极大的提升,因为渲染管线就可以略过这个fragment后边的操作,去直接处理下一个fragment。
各种test的一个例子就是 Z-testing。它用于检查一个fragment是否被另一个更靠近摄像机的fragment遮挡住。如果被遮挡住,就会被舍弃,如果没有,就会被处理成一个像素,这会消耗fill rate中的一个fill。想象下,成千上万的物体,每个物体又产生几百几千个fragments,很容易就会导致每帧需要处理几百万个fragemnt。
显卡制造商把Fill Rate做为显卡性能的一个参数,通常是以Gigapixels per-second衡量,但是更准确的说法应该是 Gigafragments per-second(因为最终的像素是屏幕固定的,但实际处理的是fragment)。不管咋说,反正这个值越大越好,说明处理能力越强。比如一个30Gigapixels每秒的显卡,目标帧率是60hz,则 我们每帧能处理的fragment上限为:30,000,000,000/60 = 500
million。这对于分辨率为2560 x 1440,最理想状态下每个像素只渲染一次的话,我们可以将整个场景渲染125次。
但是现实不是完美的,Fill Rate也会被其他渲染功能所消耗,比如阴影和后处理,他们都需要将同一个fragement数据在各自pass中处理多次。初次之外,我们通常也需要重复渲染同个像素多次,这个现象可以叫做Overdraw,它可以用于衡量我们是否有效的利用了Fill Rate。
Overdraw
通过additive alpha blending模式,我们可以很直观的看到有多少OverDraw。越亮的地方代表着OverDraw越严重,因为同一个像素被渲染了更多的次数。通过Scene window的Overdraw Shading模式即可查看:
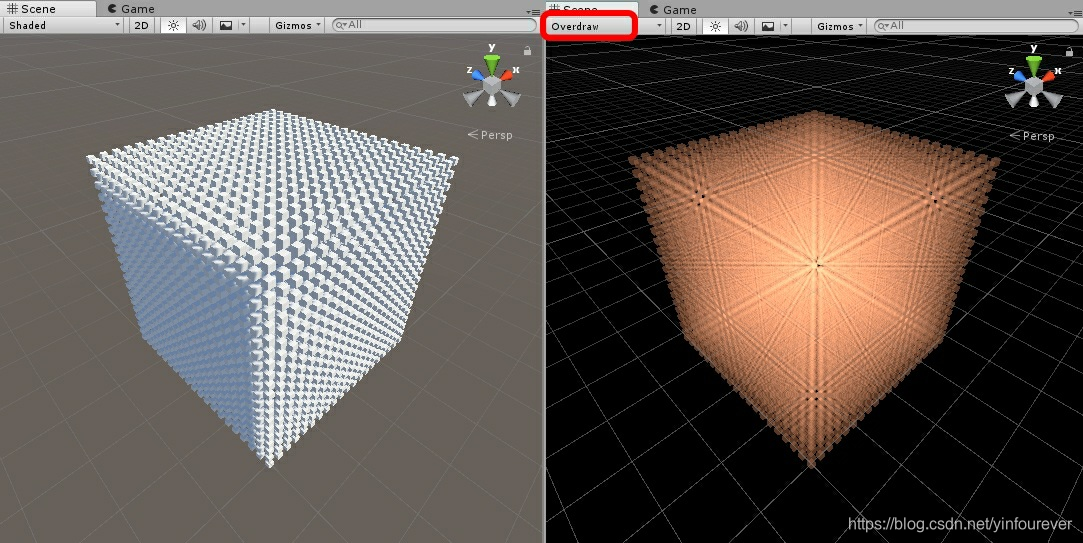
OverDraw越多,Fill Rate浪费越多,有一些技巧可以降低OverDraw,之后我们会讨论。
值得注意的一点是渲染中有不同的队列(queues),可以分为两类:Opaque(不透明)和Transparent(透明),Opaque队列中渲染的物体可以通过之前介绍的Z-testing方法剔除fragments,但是Transparent队列中渲染的物体则不行,这会导致很多OverDraw。Unity 的 UI总是使用Transparent队列渲染,所以UI经常成为OverDraw的重灾区。
Memory Bandwidth
GPU 核心中有一个local texture Cache,它存储了GPU最近使用的textures。这个cache和CPU内存的cache设计非常像,它处理速度非常快但是非常小,它使得texture的采样开销变小速度变快。
如果当一张textrue已经存储在这个local texture Cache中,采样速度会快如闪电,如果没有,在采样前则必须从VRAM中拉取这个texture,此时就是缓存没有命中,这会花费时间去从VRAM中寻找并且获取想要的那张texture。这个过程就会消耗Memory Bandwith,消耗的大小为VRAM中存储这个texture的大小(但是可能并不是这张图原始大小,因为GPU有压缩技术)。
当Memory Bandwidth成为瓶颈的时候,GPU不断的寻找所需的textures,而cache会不断的在等待所需的数据,GPU在Cache提供所需的数据之前,就没法将渲染好的数据及时传入到Frame Buffer中,从而导致帧率下降。
假设显卡的Memory Bandwidth为 96 GBs每秒,目标帧率为60hz,则每帧可处理的texture数据量为1.6 GBs (96/60)。虽然这么算不精确,但是可以提供大致的估算。
要特别注意的是这个值并不是说工程中贴图总量的最大值,也不是CPU 内存中贴图总量的值,也不是GPU显存中的贴图总量的值。因为每一帧中有可能会不断的切换texture,有可能一个texture渲染多次,这取决于有多少Shader需要这些texture以及物体的渲染顺序,有可能虽然只有几张图也会把Memory Bandwith消耗光。Shader中使用大量的texture会更有可能导致没有命中缓存从而导致Memory Bandwith出现问题,当大量物体需要不同的各种高质量贴图(法线贴图,Emission贴图等等)进行渲染时,就很容易触发这种情况。
)

)

实践(1)– 基本概念)
)
 Shader优化)
执行力背后的行为心理学)
)
 和为s的连续正数序列)





单线多拨实现网速叠加)

沟通背后的行为心理学)

