
情景介绍
平时工作中,我习惯使用rz从本地上传文件到服务器,sz从服务器下载文件到本地,但对传输文件大小有限制,例如排查线上jvm的问题,需要生成了dump文件,可能有10G大,超过了限制,怎么下载呢?
拆分文件命令之split
语法
split [-<行数>][-l<行数>][-b<字节>][-C<字节>][要切割的文件][输出文件名的前缀][-a<后缀长度>]-<行数>或-l<行数>:指定每多少行切成一个小文件
-b<字节>:指定每多少字节切成一个小文件,这里也可以指定K、M、G等单位
-C<字节>:与-b<字节>类似,但在切割时会尽量维持每行的完整性
输出文件名的前缀:设置拆分后文件的名称前缀,split会自动在前缀后面加上编号,默认从aa开始
-a<后缀长度>:默认后缀长度是2,即按 aa,ab,ac的顺序排序
split命令和cat命令可以完成上面的难题,排查线上问题的现场已经没有了,所以为了演示,用dd命令(对dd命令不了解的也可以学下,因为这次重点介绍split,所以dd暂且不介绍)创建一个400MB的文件,文件名是adsearch.hprof,这里假设400MB的大小就超过了服务器的下载限制
dd if=/dev/zero bs=1024 count=409600 of=adsearch.hprof
如图所示,创建了一个400MB的文件
那我把adsearch.hprof文件按100MB大小拆分,可以拆分成4个文件
split -b 100M adsearch.hprof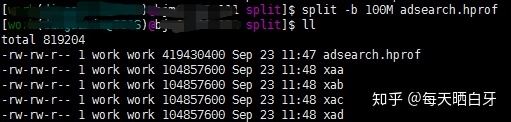
可以看到在执行完split命令后,目录下生成了四个相同大小 xaa、xab、xac、xad四个100MB的小文件。因为我们没有指定前缀,就采用了默认的前缀x,后面跟着aa、ab、ac、ad。我们也可以指定前缀,比如我把刚刚生成的四个小文件删掉,用下面的命令重新切分下
split -b 100M adsearch.hprof adsearch-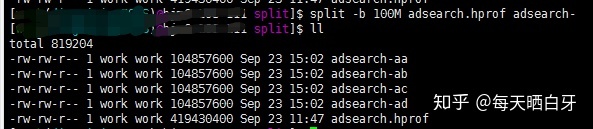
合并文件之cat
把大文件切分后,我们就可以把小文件下载到本地,然后把他们再拼接起来
// 用通配符的形式,要保证该目录下没有其他以adsearch-a为前缀的文件
cat adsearch-a* > adsearch.hprof
// 或者指定文件进行拼接
cat adsearch-aa adsearch-ab adsearch-ac adsearch-ad > adsearch.hprof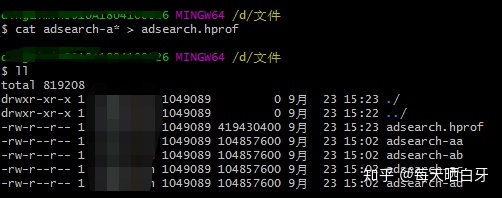
备注
上面的操作我是在win本上的gitbash操作的,有cat命令
那如果没有安装gitbash只有cmd呢?
可以使用copy /b 命令来拼接,其中 /b 代表指定以二进制格式进行复制
copy /b adsearch-aa + adsearch-ab + adsearch-ac + adsearch-ad adsearch.hprof校验
经过拆分-合并后,两个文件一样吗?这是我们主要关心的问题,我们对文件做一个md5,看结果是否相等,就可以判断文件是否一样了
原始文件的md5

合并后文件的md5(gitbash)

合并后文件的md5(cmd)
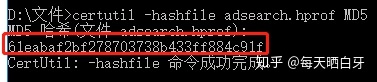
经过对前后文件的md5值比价,结果一致,说明我们的操作没有问题
小结
当我们下载或上传相对较大的文件时,可以使用split把大文件拆分成小文件,然后用cat命令把这些小文件重新拼接成大文件






)




)





控制像素点)

