概述
ElasticSearch作为一个基于Lucene的搜索引擎被广泛应用于各种应用系统,比如电商、新闻类、咨询类网站。在使用ElasticSearch开发应用的过程中,一个非常重要的过程是将数据导入到ElasticSearch索引中建立文档。在一开始系统规模比较小时,我们可以使用logstash来同步索引。logstash的好处是开方量少,只要进行编写简单的索引模板和同步sql,就能快速搭建索引同步程序。但是随着应用数据规模的变大,索引变化变得非常频繁。logstash的缺点也随着暴露,包括(1)不支持删除,只能通过修改字段属性软删除,随着应用使用时间的增长,ElasticSearch中会留存大量的无用数据,拖慢搜索速度。(2)sql分页效率低,sql查询慢。logstash的分页逻辑是先有一个大的子查询,然后再从子查询中分页获取数据,因此效率低下,当数据库数据量大时,一个分页查询就需要几百秒。同步几千万数据可能需要1天时间。因此我们决定放弃使用logstash,而改用使用canal来搭建基于CDC技术的ElasticSearch索引同步机制。
系统架构设计
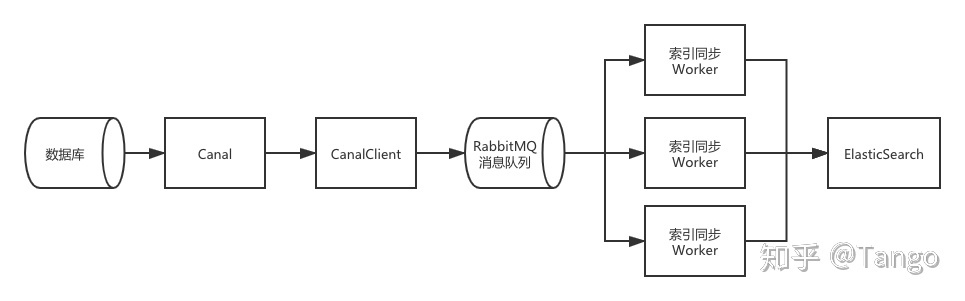
如图所示,索引同步系统由几个部分组成,下面分点介绍。
(1)数据库
原始数据数据库
(2)Canal
Canal是阿里云开源的MySql数据库增量数据订阅和消费工具。它的实现原理是将自己伪装为一个MySQL slave,向MySql master发送dump协议;MySQL master收到dump请求,开始推送binary log给slave,canal解析binary log对象。
(3)Canal Client
Canal Client是自己实现的程序,通过从Canal Server中获取经过Canal解析之后的数据库binlog日志,做相应的业务逻辑处理。在本文介绍的基于CDC的索引同步系统中,Canal Client订阅搜索相关的数据库表的binlog日志,如果跟数据搜索相关的数据发生变化时,就向Rabbit发一条消息,表明数据发生变化了,通知同步Worker从MySQL同步数据到ES。
(4)RabbitMQ
消息队列,也可以选用Kafaka等其他消息队列,根据具体业务确定。
(5)索引同步Worker
Worker从消息队列中消费数据,根据消息从MySQL获取相应的数据并同步到ElasticSearch中。
Canal Client实现
Canal Client从Canal Server中获取binlog日志,并根据业务需求进行处理。以下通过一些关键代码介绍Canal Client的实现。
(1)在pom中添加Canal client的依赖。
<dependency><groupId>com.alibaba.otter</groupId><artifactId>canal.client</artifactId><version>1.1.0</version></dependency>(2)初始化Canal连接
CanalConfig包含了Canal的配置信息。CanalConnector为canal-client包中的类,我们通过这个类来连接server,获取binlog,关闭server。该服务基于SpringBoot。因此init会在CanalClientInitializer bean被创建时被调用,preDestory会在服务关闭,CanClientInitializer被销毁时被调用。
@Component
@Slf4j
public class CanalClientInitializer {CanalConfig canalConfig;CanalConnector connector;CanalDataProcessor canalDataProcessor;public CanalClientInitializer(@Autowired CanalConfig canalConfig, @Autowired CanalDataProcessor canalDataProcessor) {this.canalConfig = canalConfig;this.canalDataProcessor = canalDataProcessor;}@PostConstructpublic void init() throws InterruptedException {connector = CanalConnectors.newSingleConnector(new InetSocketAddress(canalConfig.getIp(), canalConfig.getPort()), canalConfig.getDestination(), "", "");//建立连接connector.connect();//订阅相关的表connector.subscribe(canalConfig.getSyncTable());canalDataProcessor.process(connector);}@PreDestroypublic void preDestroy() {log.info("stop the canal client");canalDataProcessor.stopProcess();}}(3)CanalDataProcessor获取并处理binlog
@Component
@Slf4j
public class CanalDataProcessor {boolean isRunning;RabbitTemplate rabbitTemplate;TableChangeProcessor tableChangeProcessor;public CanalDataProcessor(@Autowired RabbitTemplate rabbitTemplate, @Autowired TableChangeProcessor processor) {this.rabbitTemplate = rabbitTemplate;this.tableChangeProcessor = processor;}@Asyncpublic void process(CanalConnector connector) throws InterruptedException {isRunning = true;while (isRunning) {try {//获取消息Message message = connector.getWithoutAck(100, 10L, TimeUnit.SECONDS);//业务处理逻辑processMessage(message);//消息被成功执行,向Canal Server发送ack消息通知server该message已经被处理完成connector.ack(message.getId());} catch (Exception e) {log.error("wtf", e);//当消息没被成功处理完成时进行回滚,下次能够重新获取该Messageconnector.rollback();Thread.sleep(1000);}}connector.disconnect();}public void stopProcess() {isRunning = false;}private void processMessage(Message message) {for(Entry entry : message.getEntries()) {try {tableChangeProcessor.process(entry);} catch (Exception e) {log.error("wtf", e);continue;}}}
}(4)TableChangeProcessor
TableChangeProcessor中为具体的业务逻辑,处理Message,获取跟搜索相关的数据变化,发送相应的消息到消息队列中。
注意点
(1)忽略搜索无关的数据字段变化,避免不必要的索引更新,降低服务器压力。如Products表中有一个product_weight表示商品重量发生了变化,但其实商品重量跟搜索无关,那就不要关心这个变化。
(2)对于搜索中不会出现的数据,不要写入到ES中,比如电商商品中的下架商品,另外,如果商品被下架,则要进行监听通知索引同步Worker从es中删除索引文档。这样能够降低ES中总的索引文档数量,提升搜索效率。
(3)要考虑Rabbit挂掉或者队列写满,消息无法写入的情况;首先应该在Rabbit发送消息时添加重试,其次应该在重试几次还是失败的情况下抛出异常,canal消息流回滚,下次还是能够获取到这个数据变化的Canal消息,避免数据变动的丢失。
(4)注意目前Canal只支持单Client。如果要实现高可用,则需要依赖于ZooKeeper,一个Client作为工作Client,其余Client作为冷备,当工作Client挂掉时,冷备Client监听到ZooKeeper数据变化,抢占锁成为工作Client。
Canal Worker实现
索引同步Worker从消息队列中获取Canal Client发送的跟搜索相关的数据库变化消息。举个例子,比如商品表中跟搜索相关的字段发生了变化,Canal Client会发送以下一条数据:
{"change_id": "694212527059369984","change_type": 1, //商品发生变化"change_time": "1600741397"
}在Worker中监听队列消息:
@Component
@Slf4j
public class ProductChangeQueueListener {@Autowired@Qualifier("snake")ObjectMapper om;@AutowiredChangeEventHandlerFactory changeEventHandlerFactory;@RabbitListener(queues = RabbitConfig.PRODUCT_QUEUE_NAME, containerFactory = "customRabbitListenerContainerFactory")public void onChange(Message message) {ChangeEvent event = parse(message);if(event == null) {return;}changeEventHandlerFactory.handle(event);}private ChangeEvent parse(Message message) {ChangeEvent event = null;try {event = om.readValue(new String(message.getBody()), ChangeEvent.class);} catch (Exception e) {log.error("同步失败,解析失败", e);}return event;}}ChangeEventHandlerFactory为事件处理器的工厂类。以下为一个事件处理器的实现。它监听changeType为CHANGE_TYPE_OUT_PRODUCT的事件,从数据库中获取到变动的数据,构建ES的IndexRequest,并将Request存入到RequestBulkBuffer中,等待批量同步到ES中。有些同学可能会有疑问,为何不直接从Canal中获取数据,主要原因是Canal中只包含了单表数据,但是索引文档可能包含了多表的数据,因此还需要从MySQL获取数据。如果索引文档中只包含单表数据,可以考虑在ChangeEvent中包含修改之后的数据,索引同步Woker就不用再从MySql中再获取一遍数据,提升Worker工作效率。
@Component
@Slf4j
public class OutProductEventHandler implements ChangeEventHandler {@AutowiredProductDao productDao;@AutowiredRequestBulkBuffer buffer;@AutowiredOutProductChangeRequestBuilder builder;@Override@Retryablepublic boolean handle(ChangeEvent changeEvent) {if (!match(changeEvent)) {return false;}Tuple dataTuple = productDao.getProductWithStore(changeEvent.getChangeId());if (dataTuple == null) {return true;}Product product = dataTuple.get(QProduct.product);Store store = dataTuple.get(QStore.store);IndexRequest request = null;try {request = builder.convertToUpdateQuery(getTimestampNow(), product, store);} catch (Exception e) {log.error("wtf", e);}if (request == null) {return true;}buffer.add(request);return true;}@Overridepublic boolean match(ChangeEvent changeEvent) {return ChangeEvent.CHANGE_TYPE_OUT_PRODUCT == changeEvent.getChangeType();}
}在上面的OutProductEventHandler类中,我们并不直接在该类中使用RestHighLevelClient将文档更新到ES索引,而是将IndexRequest暂存到RequestBulkBuffer中。RestBulkBuffer使用CircularFifoBuffer作为存储数据结构。
@Component
public class RequestBulkBuffer {CircularFifoBuffer buffer;public RequestBulkBuffer(CircularFifoBuffer buffer) {this.buffer = buffer;}public void add(DocWriteRequest<?> request) {buffer.add(request);}}CircularFifoBuffer是一个经过改造的环形队列实现。允许多线程写,在我们这个应用场景中只支持也只需支持单线程读->处理->移除处理完的数据。当环形队列缓存满时,借助于semaphore,写入线程将会被阻塞,在后面的Worker如何防止数据丢失中,我们来阐述为什么要这么做。
/*** 允许多线程写* 只允许单线程->读->处理->移除*/
public class CircularFifoBuffer {private Logger logger = LoggerFactory.getLogger(CircularFifoBuffer.class.getName());private transient Object[] elements;private transient int start = 0;private transient int end = 0;private transient boolean full = false;private final int maxElements;private ReentrantLock addLock;private Semaphore semaphore;public CircularFifoBuffer(int size) {if (size <= 0) {throw new IllegalArgumentException("The size must be greater than 0");}elements = new Object[size];maxElements = elements.length;addLock = new ReentrantLock();semaphore = new Semaphore(size);}public int size() {int size = 0;if (end < start) {size = maxElements - start + end;} else if (end == start) {size = (full ? maxElements : 0);} else {size = end - start;}return size;}public boolean isEmpty() {return size() == 0;}public boolean isFull() {return size() == maxElements;}public int maxSize() {return maxElements;}public void clear() {full = false;start = 0;end = 0;Arrays.fill(elements, null);}public boolean add(Object element) {if (null == element) {throw new NullPointerException("Attempted to add null object to buffer");}addLock.lock();try {semaphore.acquire();} catch (Exception e) {logger.error("RingBuffer", "线程退出,添加失败");return false;}elements[end++] = element;if (end >= maxElements) {end = 0;}if (end == start) {full = true;}addLock.unlock();return true;}public Object get() {if (isEmpty()) {return null;}return elements[start];}public Object remove() {if (isEmpty()) {return null;}Object element = elements[start];if(null != element) {elements[start++] = null;if (start >= maxElements) {start = 0;}full = false;semaphore.release();}return element;}/*** @param size the max size of elements will return*/public Object[] get(int size) {int queueSize = size();if (queueSize == 0) { //emptyreturn new Object[0];}int realFetchSize = queueSize >= size ? size : queueSize;if (end > start) {return Arrays.copyOfRange(elements, start, start + realFetchSize);} else {if (maxElements - start >= realFetchSize) {return Arrays.copyOfRange(elements, start, start + realFetchSize);} else {return ArrayUtils.addAll(Arrays.copyOfRange(elements, start, maxElements),Arrays.copyOfRange(elements, 0, realFetchSize - (maxElements - start)));}}}public Object[] getAll() {return get(size());}public Object[] remove(int size) {if(isEmpty()) {return new Object[0];}int queueSize = size();int realFetchSize = queueSize >= size ? size : queueSize;Object [] retArr = new Object[realFetchSize];for(int i=0;i<realFetchSize;i++) {retArr[i] = remove();}return retArr;}}下面这个类为缓存的消费者,它循环从buffer中获取一定数据的数据,并使用RestHighLevelClient将数据批量同步到ES。在Worker启动时,会创建一个线程调用startConsume,在服务关闭时该线程结束。
@Slf4j
public class RequestBulkConsumer {private static final int DEFAULT_BULK_SIZE = 2000;private CircularFifoBuffer buffer;private EsBulkRequestService service;private boolean isRunning = false;private int bulkSize = DEFAULT_BULK_SIZE;public RequestBulkConsumer(CircularFifoBuffer buffer, RestHighLevelClient client) {this.buffer = buffer;this.service = new EsBulkRequestService(client);}public void setBulkSize(int size) {this.bulkSize = size;}public int getBulkSize() {return bulkSize;}public boolean isRunning() {return isRunning;}public void startConsume() {if(isRunning) {return;}isRunning = true;while(true) {if(!isRunning) {break;}Object [] items = buffer.get(bulkSize);if(items.length == 0) {try {Thread.sleep(1000);} catch (InterruptedException e) {break;}} else {List<DocWriteRequest<?>> requests = convert(items);try {BulkResponse response = service.request(requests);processResponse(response);buffer.remove(items.length);if (items.length < bulkSize) {Thread.sleep(3000);}} catch (InterruptedException e) {break;} catch (IOException e) {log.error("wtf", e);} catch (Exception e) {log.error("wtf", e);buffer.remove(items.length);}}}}private List<DocWriteRequest<?>> convert(Object [] items) {return Stream.of(items).map(i -> {if(i instanceof DocWriteRequest) {return (DocWriteRequest<?>) i;} else {return null;}}).filter(Objects::nonNull).collect(Collectors.toList());}public void stop() {isRunning = false;}private void processResponse(BulkResponse bulkResponse) {BulkItemResponse [] itemResponseArr = bulkResponse.getItems();for(BulkItemResponse resp : itemResponseArr) {DocWriteResponse docWriteResponse = resp.getResponse();if(docWriteResponse instanceof IndexResponse) {IndexResponse indexResponse = (IndexResponse) docWriteResponse;if(indexResponse.getResult() != Result.CREATED && indexResponse.getResult() != Result.UPDATED) {if(indexResponse.status() == RestStatus.CONFLICT) {continue;} else {log.error("索引更新失败: {}, {}", indexResponse.getId(), resp.getFailureMessage());}}} else if(docWriteResponse instanceof DeleteResponse) {DeleteResponse deleteResponse = (DeleteResponse) docWriteResponse;if(deleteResponse.getResult() != Result.DELETED) {log.error("索引删除失败: {}, {}", deleteResponse.getId(), resp.getFailureMessage());}}}}
}以下为Worker的主要几个类的代码。在索引同步系统中,高可用并不是最重要的,因为我们的搜索本身是一个准实时系统,只需要保证最终一致性就可以了,我们主要需要避免的是数据变更的丢失。以下说明在Worker中是如何避免数据丢失的。
避免数据丢失
(1)如果Rabbit挂掉,没关系,Canal Client那边在Rabbit挂掉期间无法消费binlog,会等待Rabbit重启之后再处理数据变化。Worker只要能做到Rabbit重启之后重连就行。
(2)如果MySQL挂掉,则Worker无法从数据库中获取数据,则消息处理失败,消息会堆积在Rabbit中。等MySQL重新上线之后,消息重新开始处理,数据也不会丢失。
(3)如果ES挂掉,则批量处理线程消费buffer中的数据时会失败,buffer会被生产者填满,由于CircularFifoBuffer在被填满时使用了信号量阻塞生产者线程,消息又会被堆积在Rabbit中,等待ES重新上线之后,消息重新开始处理,数据也不会丢失。
(4)如果Rabbit队列被写满,emmm,设置好在内存被占满时将消息写入硬盘然后搞一个大一点的硬盘吧,Rabbit默认应该就是这么做的。然后做好预警,当消息达到一定量时抓紧处理,一般来说可能性不是很大。
(5)版本冲突,如果商品表中某一条数据如商品A在同一秒内变化了两次,消息队列中有连续两条消息,又由于这两条消息可能在两个线程中被消费,由于网络,计算机性能等原因,先变的数据后被写入ES中,导致ES中数据和MySql数据不一致。因此我们在更新索引时使用ES的外部版本号。使用从MySQL中取数据时的时间戳作为版本号,只有当时间戳比当前版本号大或相等时才能变更文档,否则ES会报版本冲突错误。
private IndexRequest convertToUpdateQuery(Long timestamp, OutStoreProduct outStoreProduct) throws JsonProcessingException {IndexRequest indexRequest = new IndexRequest(indexName, "doc", outStoreProduct.getId());if(StringUtils.isEmpty(outStoreProduct.getTooEbaoProductId())) {log.error("商品 {} 的ebaoProductId为空,无法同步", outStoreProduct.getId());return null;}indexRequest.source(om.writeValueAsString(outStoreProduct), XContentType.JSON).versionType(VersionType.EXTERNAL_GTE).version(timestamp).routing(outStoreProduct.getTooEbaoProductId());return indexRequest;}关于全量同步
以上只是实现了增量同步,在索引初始化时,我们需要做全量同步操作,将数据从数据库初始化到ES索引中。我们可以在Worker中写一个接口,该接口实现逻辑分批将数据同步任务发到消息队列中,其它worker收到消息后完成对应任务。比如我们可以发布每一个门店的数据同步任务,worker每收到一个消息,同步一个门店的数据。
总结
综上,本系统是一个近实时的能够保证ES和MySQL数据一致性的高效索引同步系统。



)



)





)



)

)