概述
自 ChatGPT 大模型横空出世以来,文心一言、通义千问等诸多大模型接踵而来,感觉这个世界每天都在发生着翻天覆地的变化。
今年很有幸,参与了云栖的盛宴,当时被震惊到瞠目结舌,12 月 20 日百度云智能云智算大会,又给我一记重拳,这让我不由得开始重新评估 AI 与我们的距离,AIGC 的时代或许已经开始吹响冲锋的号角,而我们也应该做好充足的准备,迎接新的挑战。
在此次百度智能云智算大会上,我细致的听了全程,受益匪浅,学习到很多先进的概念,例如云智一体、智算、数据"智"理、模型即服务等。这都不由得让我感叹 AI 发展的迅速,新的信息风暴已经在爆发的前夕,不日,必将石破天惊。
百度智能云此次地主题是"重构云计算,打造 AI 原生时代地云计算产品与技术体系"。重构这个词通常与解构并行出现,解构最早来源于海德格尔的《存在与时间》,为分解、消解、拆解、揭示等;重构是对解构的扩展和延伸,在程序设计中所用甚广,通常意指调整代码结构,使其设计模式和架构更趋合理。
毫无疑问,在计算机的领域,这是一个非常大的词,更何况后续还附带了体系两字,这不由得让我欣喜,也让我好奇,本次大会又会有何等惊涛骇浪的创新。
重构——云原生时代
在长驱直入本次智算大会之前,我想先聊一下 AI 重构的意义。
不知道大家有没有切身实地的训练过 AI 模型,尝试过 AI 模型的部署,如果你是一个初学者,你会发现这整个过程每个步骤都会让你头痛。
作为浪漫主义和完美主义熏陶的国人,精益求精是我们的核心驱动力,AI 模型也是这样,我们无时无刻不试图突破 AI 模型的精度极限,做到最优、最好。在这个过程中模型参数量也在同步快速的膨胀,越来越大,大模型就这么出现了。
大模型带来了更大的计算复杂度,训练对算力以及基础设施的要求越来越高,训练所需的资源成本也随之飙升。我们不可能停下前进的脚步,那么我们就必须解决两个核心问题:如果稳定的训练模型,如何持续的降本增效。
在一次百度智能云的线上公开课中,针对于当下的 AI 的痛点问题,主要总结了亮点:
- 资源效能: 资源利用率、异构芯片调度等
- 工程效能:大模型落地、训练/推理任务的效率等
AI 工程效率低下,是当下亟待解决的核心问题。那我们又该如何优化那?
云原生,没错,云原生。
云原生 CNCF 定义:云原生是构建应用程序一类技术的统称,通过云原生技术可以构建出可弹性扩展的应用程序,这些应用程序可以被运行在不同环境当中,比如公有云、私有云、混合云等新型动态环境中。
定义非常晦涩,难以理解,但我们可以从中捕获到两个关键词:可弹性扩展和动态环境。借助云原生,应用的开发者不再需要考虑底层的环境,可以实现快速部署、按需弹性扩伸缩的应用程序。云原生 AI 则是更贴近 AI 场景的重构设计,以容器服务为核心,以云原生技术为基础架构的 AI 工程解决方案,整合云计算、存储等服务,贯穿 AI 任务的全周期。
听起来是不是有些困难,在互联网界,越是基础、越是核心的基础设施,解决方案,越是卷,百度智能云又会如何展开自己的重构之路,搭建云原生AI基础设施那?
智算时代
百舸 3.0
云原生 AI 可以帮助 AI 任务实现资源的高效利用和无缝迁移等问题,在此次百度智能云智算大会中,百度进一步重构了智算基础设施,针对大模型场景进行了专项优化。全新发布百度百舸· AI 异构计算平台 3.0,百舸 3.0 承载了百度智能云的云原生 AI,是一套专注于 AI 工程化建设,提供软硬一体的异构计算平台。
百舸 3.0 对原生 AI 应用和大模型的训练、推理等环节进行了全面、专向优化升级,可以看一组官方的参数,你就可以估量此次更新的厚重。其一最高可提升模型训、推吞吐 30% 和 60%;其二,在资源利用方面,能够实现 98% 的超高集群有效训练时间占比,95% 的网络带宽有效利用率,充分释放集群有效算力,大幅降低客户的资源与时间成本;其三,提供了一套完备的体系,包含丰富的运维和可观测工具、自动化容错保障能力等。

我们可以清晰的发现,百舸 3.0 正是针对于当下 AI 的痛点问题,做出的有效应对,百舸 3.0 构建的体系真的很庞大健全,能满足工程的所需。遇到问题,分析问题,解决问题,我相信也是整个百度智能云发展的核心思路,致敬。
极致性价比的基础云服务
AI 应用不止需要模型、服务等软件层面的繁荣,更需要强大硬件的支撑。作为 AI 应用的硬件基础设施,我认为要具备以下几点:性能高、成本低、高可靠。
百度智能云在基础设施方面做了很多努力,致力于打造极致性价比的基础云服务,也就是百度太行系列。
太行这个名字我非常喜爱,太行山脉,就彷佛有一种厚重、扎实、可靠的感觉。没错,百度太行系列也是如此。
- 百度太行 DPU(Data Processing Unit),打造了统一的高性能云原生基础设施架构,可以有效提高资源利用率,能够将 CPU、GPU 的算力资源应用满格 100%。
- 百度太行·计算作为高性能、高弹性、高可靠的云服务算力底座,此次推出三款全新计算实例
- 提供更高效的算力服务的通用计算型云服务器实例 G7,搭载英特尔最新的第五代至强可扩展处理器,综合性能较上一代产品提升 10%。
- 大模型推理场景综合性能较业界主流加速卡可提升达 50% 的 NKL5 实例,搭载了百度自研的昆仑芯 R300 加速处理器,加强了显存规格与 AI 加速处理器互联通信性能,在;
- 综合性能较业界主流加速卡提升可达 40% ,使能大模型开发提速的弹性性能计算实例 NH6T,支持 3.2Tbps RDMA 高速互联带宽。
- 百度太行计算新一代高性能网关平台,提高网络性能,支持百度网盘、百度地图等百度生图的内网便捷访问,降低数据泄露、时延抖动的危险,大幅度降低数据传输成本和数据处理效率。
分布式云基础设施
云边互联是前段时间我非常关注的话题,在边缘节点上实现智能化,能有效提高数据实时性,降低数据传递泄露的风险。特别是在一些 IOT 领域,云边互联能有效推动其发展,在这个 AIGC 迅速发展的时期,我有时就在想,如果 AIGC 碰撞 IOT,会出现那些让人眼前一亮的改变那?
此次百度智能云智算大会,我特别喜欢官方提出一个理念:让智算无处不在,智能无所不及(改成触手可及是否更大气一些)。这完美响应了我的智能理念,无所不在,触手可及。那么这就需要无数的端、边缘节点,共同搭建起繁荣的云边架构。
百度智能云对此也做出了诸多升级
- 边缘计算节点(类似理解成端就行)覆盖范围扩大,智算能力升级,构建愈加完善的云边一体
- ABC Stack 支持本地部署百度智能云千帆大模型平台,为企业构建专属大模型按下加速键
- 本地计算机成 LCC 新能力发布
数据"智"理
这个词真的有点说到我的心坎上了,数据治理,但更要智理,这不仅是字面意思的改变,更是思维层面的跨越,智慧化可以漫步我们的日常,这是一个非常振奋的进步。
对于都模型和 AI 应用,数据的存储也是至关重要的,如何高效的存、高效的取是我们需要关注的关键之一。
百度智能云敏锐的捕捉到了这一点,在云存储、云数据库等基础领域进行了一系列重磅更新,还有我最害怕的一集。
- 百度沧海·存储,又是一个很雅致的名字,海洋辽阔无疆,有容乃大,沧海是百度智能云的存储的同意技术底座,支持各类存储产品,存储高性能、低成本。
- 云原生数据库 GaiaDB 4.0 版本性能大幅度提升,增强并行查询能力,突破单机计算瓶颈,实现跨机多核并行查询,在混合负载和实时分析业务场景中性能提升超过 10 倍。此外,通过共识协议优化、链路优化、自适应动态回放存储多版本等一些列数据流深度优化,大幅提升 GaiaDB 整体性能 60% 以上
还有最害怕的一集,百度智能云发布了一款数据库智能驾驶舱,通过引入大模型能力,能够实现对数据库进行自动的智能化的洞察、评估和优化。蛤?自动智能化洞察,我没听错吧。此款智能仓可以媲美专业的 DBA 水平,复杂问题回复的准确率超过 80%,我有点开始担心未来了,如果此类产品的价位比较适合,很可能可以替换部分基础的工作,再不卷,岗位都要被替代了。
模型即服务——千帆大模型平台
大模型将作为新的通用服务能力,我不由一惊,大模型都已经开始作为服务了吗,AI 距离我们真的是越来越近了。
百度智能云千帆大模型平台目前已经可以提供包括百度文心大模型在内的、国内最多的 54 个主流基础大模型和行业大模型,还为大模型的持续预训练、精调、评估、压缩和部署等环节提供最完善易用的工具链,据官方统计,相较于自建系统训练大模型,使用千帆平台训练的成本最高可以下降 90%。
千帆平台提供一个完整、庞大的模型工具链,初次听到这消息我有些吃惊,大会结束后,我连忙去官网体验了一番,没错,千帆提供了免费的体验,这点真的大大的好评。
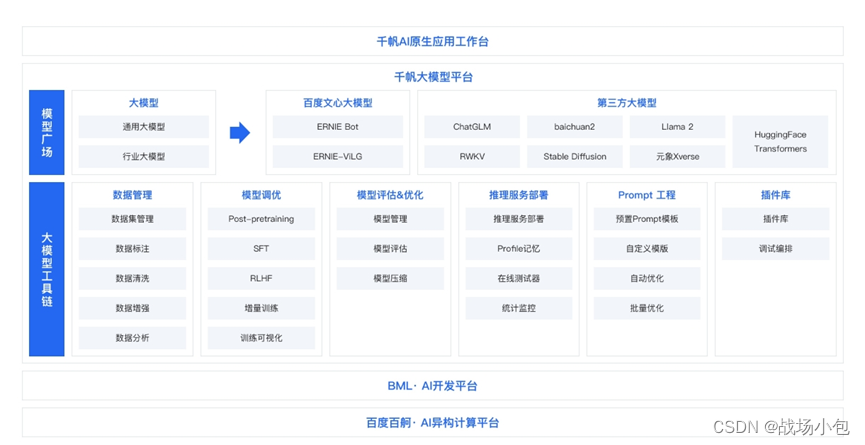
如果日常中实践过 AI 应用,你会发现千帆把你想到的都想到了,没想到的也都实现了,它提供了一组标准化的流程,按照它的思路走,可以省无数的功夫,这都是血淋淋的经验,盲人摸象真的会晕,会乱。
下面是千帆平台的模型广场和体验中心。
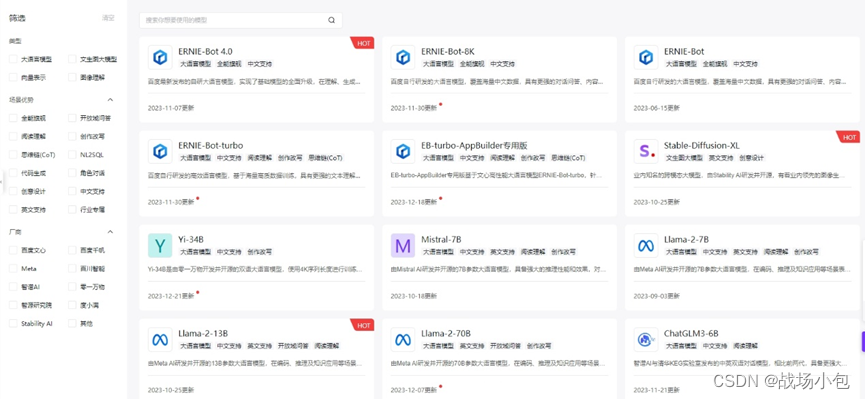
上面看到 54 个模型只是个单调的数字,当我真正看到模型的列表时,才深深的感慨百度智能云的发展,54 个大模型啊,这得多久才能调试、测试出来,它蕴涵了百度人的辛勤劳动。

体验中心可以体验对话类(Gpt)和绘画类,绘画类挺让我惊喜的,虽然它只提供了 Stable diffusion XL 模型,也不支持一些微调模型,但是它给提供了 500 次免费在线的体验过程。我有好多小伙伴,都想体验 AI 绘画,但是迫于环境难搭,性能不足,只能望洋兴叹。千帆平台不只为企业提供了完备的功能,还为个人开发者提供了学习和尝试的平台,更多人参与 AI 不是梦想。此外,还提供了丰富的 prompt 模板,真是不能再赞了。
千帆 AppBuilder
按照以往以我对百度的了解,百度喜欢把产品由繁化简,提高使用者的开发效率,降低开发者的使用门槛,以此来推动行业的进步。
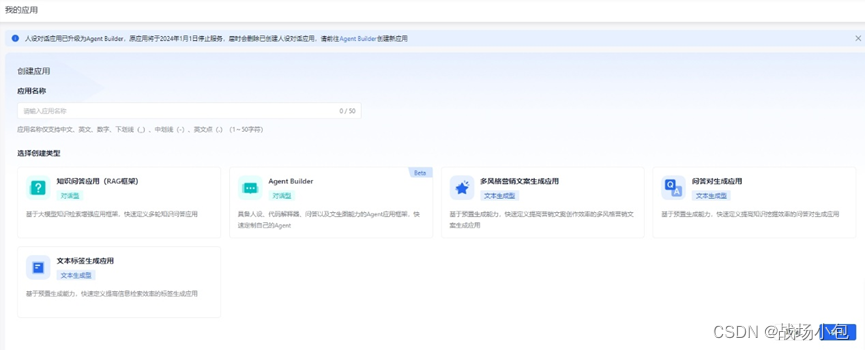
AI 应用开发目前来看门槛还是甚高,社会的舆论以及人们的错判都是阻挡当下 AI 发展的因素,AI 普适化还需要很长的路。百度智能云千帆 AppBuilder 就是一个很好的尝试,它迈出了关键的异步,该平台提供了一套基于 Web 的 AI 应用开发工具,将基于大模型开发 AI 原生应用的常见模式、工具、流程,沉淀成一个工作台,帮助开发者聚焦业务本身,而无需为开发过程牵扯多余精力,让开发者可以快速的进行 AI 应用的开发。
AppBuilder 由组件和框架构成,其中组件主要包含一些能力服务,例如文字识别、文生图、长文总结等;框架则是将组件按照应用所需串联起来,构建一个特定场景。目前 AppBuilder 官方提供了几个在线体验的应用,配置起来特别简单,我甚至都感觉我并不是在开发 AI 应用,只不过在做简单的网站,AppBuilder 用起来实现太简单轻便了,我不由得有点憧憬 AI 的未来。
最后附赠一句侯震宇老师的预测,2024 年将成为 AI 原生应用的元年,迎来AI原生应用的爆发式增长。我也隐隐的感觉到,AI距离我们越来越近了,那就让我们一起跟随着百度智能云的脚步,好风凭借力,送我上青云,一起见证AI的辉煌时代。
)
深入理解Mysql底层数据结构和算法)
:HTTP和HTTPS协议的区别)


)









)



