本文介绍Agent Attention注意力机制,Transformer中的Attention模块可以提取全局语义信息,但是计算量太大,Agent Attention是一种计算非常有效的Attention模块。
论文:Agent Attention: On the Integration of Softmax and Linear Attention
代码:https://github.comA/leaplabthu/agent-attention
一、模块结构
Softmax Attention,Linear Attention, Agent Attention结构如下图:

Softmax Attention先进行Q和K的矩阵乘法,然后经过softmax并与V相乘,计算量大。
Linear Attention先进行K和V的矩阵乘法,然后再与Q相乘,降低了计算量。
Agent Attention引入了agent token A,A的维度为(n,d),n远小于N,通过与A的矩阵乘法降低了Q,K的维度,进而降低计算量。
二、推理公式
传统Attention的计算如下(x是输入,W是权重):

Softmax Attention就是将上式中的Sim(Q,K)变成了下式:
![]()
而Linear Attention的Sim(Q,K)如下:
![]()
为了简单起见,可以将Softmax Attention和Linear Attention写成下式:

那么Agent Attention可以写成:

等价于下式(A是引入的Agent token):

下图是Agent Attention的示意图(可以看到与最上面的图和上式很相似):
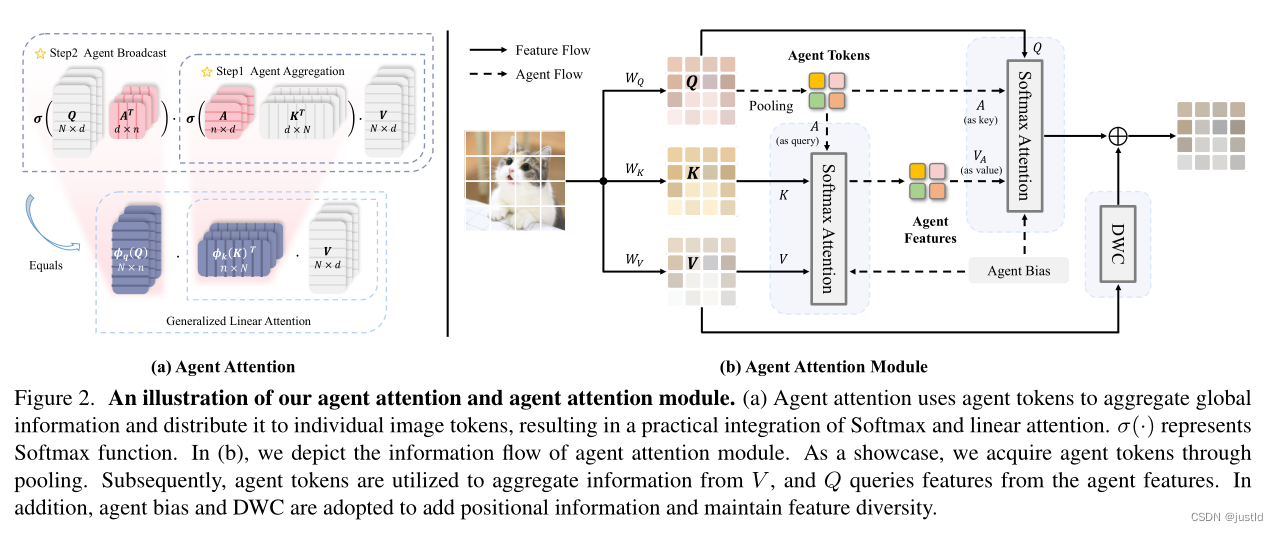
三、代码
Agent Attention可以放入各种Transformer模块中,这里展示PVT中使用Agent Attention的代码(就是将PVT原有的Attention模块替换成Agent Attention):
# -----------------------------------------------------------------------
# Agent Attention: On the Integration of Softmax and Linear Attention
# Modified by Dongchen Han
# -----------------------------------------------------------------------import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partialfrom timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg__all__ = ['agent_pvt_tiny', 'agent_pvt_small', 'agent_pvt_medium', 'agent_pvt_large'
]class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):super().__init__()assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."self.dim = dimself.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.q = nn.Linear(dim, dim, bias=qkv_bias)self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.sr_ratio = sr_ratioif sr_ratio > 1:self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)self.norm = nn.LayerNorm(dim)def forward(self, x, H, W):B, N, C = x.shapeq = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)if self.sr_ratio > 1:x_ = x.permute(0, 2, 1).reshape(B, C, H, W)x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)x_ = self.norm(x_)kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)else:kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)k, v = kv[0], kv[1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass AgentAttention(nn.Module):def __init__(self, dim, num_patches, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,sr_ratio=1, agent_num=49, **kwargs):super().__init__()assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."self.dim = dimself.num_patches = num_patcheswindow_size = (int(num_patches ** 0.5), int(num_patches ** 0.5))self.window_size = window_sizeself.num_heads = num_headshead_dim = dim // num_headsself.scale = head_dim ** -0.5self.q = nn.Linear(dim, dim, bias=qkv_bias)self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)self.sr_ratio = sr_ratioif sr_ratio > 1:self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)self.norm = nn.LayerNorm(dim)self.agent_num = agent_numself.dwc = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=(3, 3), padding=1, groups=dim)self.an_bias = nn.Parameter(torch.zeros(num_heads, agent_num, 7, 7))self.na_bias = nn.Parameter(torch.zeros(num_heads, agent_num, 7, 7))self.ah_bias = nn.Parameter(torch.zeros(1, num_heads, agent_num, window_size[0] // sr_ratio, 1))self.aw_bias = nn.Parameter(torch.zeros(1, num_heads, agent_num, 1, window_size[1] // sr_ratio))self.ha_bias = nn.Parameter(torch.zeros(1, num_heads, window_size[0], 1, agent_num))self.wa_bias = nn.Parameter(torch.zeros(1, num_heads, 1, window_size[1], agent_num))trunc_normal_(self.an_bias, std=.02)trunc_normal_(self.na_bias, std=.02)trunc_normal_(self.ah_bias, std=.02)trunc_normal_(self.aw_bias, std=.02)trunc_normal_(self.ha_bias, std=.02)trunc_normal_(self.wa_bias, std=.02)pool_size = int(agent_num ** 0.5)self.pool = nn.AdaptiveAvgPool2d(output_size=(pool_size, pool_size))self.softmax = nn.Softmax(dim=-1)def forward(self, x, H, W):b, n, c = x.shapenum_heads = self.num_headshead_dim = c // num_headsq = self.q(x)if self.sr_ratio > 1:x_ = x.permute(0, 2, 1).reshape(b, c, H, W)x_ = self.sr(x_).reshape(b, c, -1).permute(0, 2, 1)x_ = self.norm(x_)kv = self.kv(x_).reshape(b, -1, 2, c).permute(2, 0, 1, 3)else:kv = self.kv(x).reshape(b, -1, 2, c).permute(2, 0, 1, 3)k, v = kv[0], kv[1]agent_tokens = self.pool(q.reshape(b, H, W, c).permute(0, 3, 1, 2)).reshape(b, c, -1).permute(0, 2, 1)q = q.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)k = k.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)v = v.reshape(b, n, num_heads, head_dim).permute(0, 2, 1, 3)agent_tokens = agent_tokens.reshape(b, self.agent_num, num_heads, head_dim).permute(0, 2, 1, 3)kv_size = (self.window_size[0] // self.sr_ratio, self.window_size[1] // self.sr_ratio)position_bias1 = nn.functional.interpolate(self.an_bias, size=kv_size, mode='bilinear')position_bias1 = position_bias1.reshape(1, num_heads, self.agent_num, -1).repeat(b, 1, 1, 1)position_bias2 = (self.ah_bias + self.aw_bias).reshape(1, num_heads, self.agent_num, -1).repeat(b, 1, 1, 1)position_bias = position_bias1 + position_bias2agent_attn = self.softmax((agent_tokens * self.scale) @ k.transpose(-2, -1) + position_bias)agent_attn = self.attn_drop(agent_attn)agent_v = agent_attn @ vagent_bias1 = nn.functional.interpolate(self.na_bias, size=self.window_size, mode='bilinear')agent_bias1 = agent_bias1.reshape(1, num_heads, self.agent_num, -1).permute(0, 1, 3, 2).repeat(b, 1, 1, 1)agent_bias2 = (self.ha_bias + self.wa_bias).reshape(1, num_heads, -1, self.agent_num).repeat(b, 1, 1, 1)agent_bias = agent_bias1 + agent_bias2q_attn = self.softmax((q * self.scale) @ agent_tokens.transpose(-2, -1) + agent_bias)q_attn = self.attn_drop(q_attn)x = q_attn @ agent_vx = x.transpose(1, 2).reshape(b, n, c)v = v.transpose(1, 2).reshape(b, H, W, c).permute(0, 3, 1, 2)x = x + self.dwc(v).permute(0, 2, 3, 1).reshape(b, n, c)x = self.proj(x)x = self.proj_drop(x)return xclass Block(nn.Module):def __init__(self, dim, num_patches, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1,agent_num=49, attn_type='A'):super().__init__()self.norm1 = norm_layer(dim)assert attn_type in ['A', 'B']if attn_type == 'A':self.attn = AgentAttention(dim, num_patches,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio,agent_num=agent_num)else:self.attn = Attention(dim,num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)def forward(self, x, H, W):x = x + self.drop_path(self.attn(self.norm1(x), H, W))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass PatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)self.img_size = img_sizeself.patch_size = patch_size# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \# f"img_size {img_size} should be divided by patch_size {patch_size}."self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]self.num_patches = self.H * self.Wself.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = nn.LayerNorm(embed_dim)def forward(self, x):B, C, H, W = x.shapex = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)H, W = H // self.patch_size[0], W // self.patch_size[1]return x, (H, W)class PyramidVisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], agent_sr_ratios='1111', num_stages=4,agent_num=[9, 16, 49, 49], attn_type='AAAA', **kwargs):super().__init__()self.num_classes = num_classesself.depths = depthsself.num_stages = num_stagesdpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rulecur = 0attn_type = 'AAAA' if attn_type is None else attn_typefor i in range(num_stages):patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i - 1) * patch_size),patch_size=patch_size if i == 0 else 2,in_chans=in_chans if i == 0 else embed_dims[i - 1],embed_dim=embed_dims[i])num_patches = patch_embed.num_patchespos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))pos_drop = nn.Dropout(p=drop_rate)block = nn.ModuleList([Block(dim=embed_dims[i], num_patches=num_patches, num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j],norm_layer=norm_layer, sr_ratio=sr_ratios[i] if attn_type[i] == 'B' else int(agent_sr_ratios[i]),agent_num=int(agent_num[i]), attn_type=attn_type[i])for j in range(depths[i])])cur += depths[i]setattr(self, f"patch_embed{i + 1}", patch_embed)setattr(self, f"pos_embed{i + 1}", pos_embed)setattr(self, f"pos_drop{i + 1}", pos_drop)setattr(self, f"block{i + 1}", block)# classification headself.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()# init weightsfor i in range(num_stages):pos_embed = getattr(self, f"pos_embed{i + 1}")trunc_normal_(pos_embed, std=.02)# trunc_normal_(self.cls_token, std=.02)self.apply(self._init_weights)def _init_weights(self, m):if isinstance(m, nn.Linear):trunc_normal_(m.weight, std=.02)if isinstance(m, nn.Linear) and m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.LayerNorm):nn.init.constant_(m.bias, 0)nn.init.constant_(m.weight, 1.0)@torch.jit.ignoredef no_weight_decay(self):# return {'pos_embed', 'cls_token'} # has pos_embed may be betterreturn {'cls_token'}def get_classifier(self):return self.headdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()def _get_pos_embed(self, pos_embed, patch_embed, H, W):if H * W == self.patch_embed1.num_patches:return pos_embedelse:return F.interpolate(pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)def forward_features(self, x):B = x.shape[0]for i in range(self.num_stages):patch_embed = getattr(self, f"patch_embed{i + 1}")pos_embed = getattr(self, f"pos_embed{i + 1}")pos_drop = getattr(self, f"pos_drop{i + 1}")block = getattr(self, f"block{i + 1}")x, (H, W) = patch_embed(x)pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)x = pos_drop(x + pos_embed)for blk in block:x = blk(x, H, W)if i != self.num_stages - 1:x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()return x.mean(dim=1)def forward(self, x):x = self.forward_features(x)x = self.head(x)return xdef _conv_filter(state_dict, patch_size=16):""" convert patch embedding weight from manual patchify + linear proj to conv"""out_dict = {}for k, v in state_dict.items():if 'patch_embed.proj.weight' in k:v = v.reshape((v.shape[0], 3, patch_size, patch_size))out_dict[k] = vreturn out_dictdef agent_pvt_tiny(pretrained=False, **kwargs):model = PyramidVisionTransformer(patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],**kwargs)model.default_cfg = _cfg()return modeldef agent_pvt_small(pretrained=False, **kwargs):model = PyramidVisionTransformer(patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs)model.default_cfg = _cfg()return modeldef agent_pvt_medium(pretrained=False, **kwargs):model = PyramidVisionTransformer(patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],**kwargs)model.default_cfg = _cfg()return modeldef agent_pvt_large(pretrained=False, **kwargs):model = PyramidVisionTransformer(patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],**kwargs)model.default_cfg = _cfg()return model


)






:爬虫框架Scrapy)




)
)


