1 集合排序
1.1 集合排序API
1.1.1 集合排序概述
集合排序是指对一个集合中的元素按照特定规则进行重新排列,以使得集合中的元素按照预定义的顺序呈现。
在集合排序中,通常需要定义一个比较规则,这个比较规则用于决定集合中的元素在排序后的顺序。元素之间的比较可以是数字的大小比较、字符串的字典序比较、对象的属性比较等。
例如,将学生信息集合按照学生的学号排序,按照姓名的字典顺序排序,或者按照生日排序。
在Java中实现集合排序的方式可以分为两大类:
1、使用集合排序API。
2、使用支持自动排序的集合。
- 一些集合底层使用的数据结构支持自动排序,如红黑树结构
1.1.2 Collections.sort() 方法
Collections是集合的工具类,它提供了很多便于我们操作集合的方法,其中就有用于集合排序的sort方法。该方法的定义为:
void sort(List<T> list)该方法的作用是对集合元素进行自然排序(按照元素的由小至大的顺序)。
1.1.3 【案例】Collections.sort方法示例
编写代码,测试集合的排序实现。代码示意如下:
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Random;
public class ListSortDemo1 {public static void main(String[] args) {List<Integer> list = new ArrayList<Integer>();Random r = new Random(1);for (int i = 0; i < 10; i++) {list.add(r.nextInt(100));}// [85, 88, 47, 13, 54, 4, 34, 6, 78, 48]System.out.println(list);Collections.sort(list);// [4, 6, 13, 34, 47, 48, 54, 78, 85, 88]System.out.println(list);}
} 1.1.4 Comparable接口
在Java中,如果想对某个集合的元素进行排序,有一个前提条件:该集合中的元素必须是Comparable接口的实现类。
Comparable是一个接口,用于定义其子类是可以比较的,该接口有一个用于比较大小的抽象方法:

所有 Comparable 接口的实现类都需要重写 compareTo 方法来定义对象间的比较规则:
int compareTo(T t); 此方法使用当前对象与给定对象进行比较,并要求返回一个整数,这个整数不关心具体的值,而是关注取值范围:
- 当返回值>0时,表示当前对象比参数给定的对象大
- 当返回值<0时,表示当前对象比参数给定的对象小
- 当返回值=0时,表示当前对象和参数给定的对象相等
1.1.5 【案例】Comparable接口示例
编写代码,定义类并实现Comparable接口;然后定义包含该对象的集合,测试其排序效果。代码示意如下:
public class Student implements Comparable<Student>{String String name;String int age;String double score;public Student(String name, int age, double score) {this.name = name;this.age = age;this.score = score;}@Overridepublic int compareTo(Student o) {// 按年龄的大小排序return this.age - o.age;}@Overridepublic String toString() {return "Student{" +"name='" + name + '\'' +", age=" + age +", score=" + score +'}';}
}
import java.util.*;
public class ListSortDemo2 {public static void main(String[] args) {Student s1 = new Student("Tom", 18, 88.5);Student s2 = new Student("Jerry", 16, 95);Student s3 = new Student("Lucy", 17, 100);System.out.println("s1 compareTo s2:" + s1.compareTo(s2));System.out.println("s2 compareTo s3:" + s2.compareTo(s3));List<Student> list = Arrays.asList(s1,s2,s3);// 排序Collections.sort(list);// 查看list中的元素for(Student s : list){System.out.println(s); // Jerry, Lucy, Tom}}
}1.1.6 Comparator接口
一旦Java类实现了 Comparable 接口,其比较逻辑就已经确定;如果希望在排序的操作中临时指定比较规则,可以通过声明 Comparator 接口的实现类来实现。
Comparator 接口也用于定义比较逻辑,可用于在集合外部提供元素的比较逻辑。对比如下图所示:

因此,实现了 Comparator 接口的类可以看作是定义了特定比较逻辑的比较器。
Comparator接口的核心方法是compare方法,用于比较两个元素的大小:
int compare(T o1,T o2)
实现compare方法的返回值要求:
- 若o1>o2则返回值应>0
- 若o1<o2则返回值应<0
- 若o1=o2则返回值应为0
1.1.7 【案例】Comparator接口示例
接续上一个案例:使用Comparator接口,为sort() 方法指定其他比较规则并实现排序。代码示意如下:
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class ListSortDemo3 {public static void main(String[] args) {Student s1 = new Student("Tom", 18, 88.5);Student s2 = new Student("Jerry", 16, 95);Student s3 = new Student("Lucy", 17, 100);List<Student> list = Arrays.asList(s1,s2,s3);// 排序 指定新的比较逻辑 按分数排序System.out.println("====> 按分数排序后的结果");Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return (int) Math.ceil(o1.score - o2.score);}});// 查看list中的元素for(Student s : list){System.out.println(s); // Tom, Jerry, Lucy}// 排序 指定新的比较逻辑 按分数降序排序System.out.println("====> 按分数降序排序后的结果");Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return (int) Math.ceil(o2.score - o1.score);}});// 查看list中的元素for(Student s : list){System.out.println(s); // Lucy, Jerry, Tom}// 排序 指定新的比较逻辑 按姓名排列System.out.println("====> 按姓名排序后的结果");Collections.sort(list, new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {// String和包装类都实现了Comparable接口return o1.name.compareTo(o2.name);}});// 查看list中的元素for(Student s : list){System.out.println(s); // Jerry, Lucy, Tom}}
}1.1.8 Comparator接口中的默认方法
在Java 8之前,接口中只能定义抽象方法,也就是只能定义方法的签名,而没有具体的实现。
Java 8引入了默认方法(Default Method)的概念,它是一种可以在接口中定义具体实现的方法。默认方法的引入使得Java的接口可以更好地支持类库的演化和功能的扩展。
Comparator 接口在Java 8及以后的版本中引入了一些默认方法,这些方法提供了更多的灵活性和便利性。
以下是Comparator 接口中常用的默认方法:
1、reversed():该方法返回当前比较器的逆序比较器。它将原来的比较规则进行颠倒,使得升序排序变为降序排序,反之亦然。

2、thenComparing(Comparator<? super T> other):该方法返回一个组合比较器,用于对两个比较规则进行联合排序。如果原始比较器认为两个元素相等,则使用传入的 other 比较器进一步比较。

1.1.9 【案例】Comparator默认方法示例
import java.util.Arrays;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class ListSortDemo4 {public static void main(String[] args) {Student s1 = new Student("Tom", 18, 88.5);Student s2 = new Student("Jerry", 16, 95);Student s3 = new Student("Lucy", 17, 100);Student s4 = new Student("Alice", 17, 96);List<Student> list = Arrays.asList(s1,s2,s3,s4);// 声明年龄升序比较器Comparator<Student> c1 = new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return o1.age - o2.age;}};// 声明年龄降序比较器Comparator<Student> c2 = c1.reversed();// 测试效果System.out.println("====> 按年龄升序排序后的结果");Collections.sort(list, c1);printList(list);System.out.println("====> 按年龄降序排序后的结果");Collections.sort(list, c2);printList(list);// 声明分数升序比较器Comparator<Student> c3 = new Comparator<Student>() {@Overridepublic int compare(Student o1, Student o2) {return (int) Math.ceil(o1.score - o2.score);}};// 组合比较器:先按年龄降序,年龄相同按分数升序Comparator<Student> c4 = c2.thenComparing(c3);// 测试效果System.out.println("====> 按年龄降序,年龄相同按分数升序排序后的结果");Collections.sort(list, c4);printList(list);}public static void printList(List<Student> list) {for(Student s : list){System.out.println(s);}}
}1.2 自动排序的集合
1.2.1 树数据结构
树(Tree)是一种常见的非线性数据结构,它由一组节点(Node)和节点之间的连接关系(边,Edge)组成。树的结构类似于自然界中的树,由根节点、分支节点和叶子节点构成,分支节点连接多个子节点,而叶子节点没有子节点。

1.2.2 二叉搜索树
二叉搜索树(Binary Search Tree, BST)满足以下条件:
1、对于根节点,左子树中所有节点的值 < 根节点的值 < 右子树中所有节点的值
2、任意节点的左、右子树也是二叉搜索树,即同样满足条件 1

这个特性使得在二叉搜索树中进行查找操作非常高效。在理想的情况下,二叉搜索树是“平衡”的,这样就可以在logn轮循环内查找任意节点。
BST的插入和删除操作也相对简单,但它没有强制性的自平衡机制,可能导致树的不平衡性,如果二叉树退化成链表,这时各种操作的时间复杂度也会退化为O(n)。

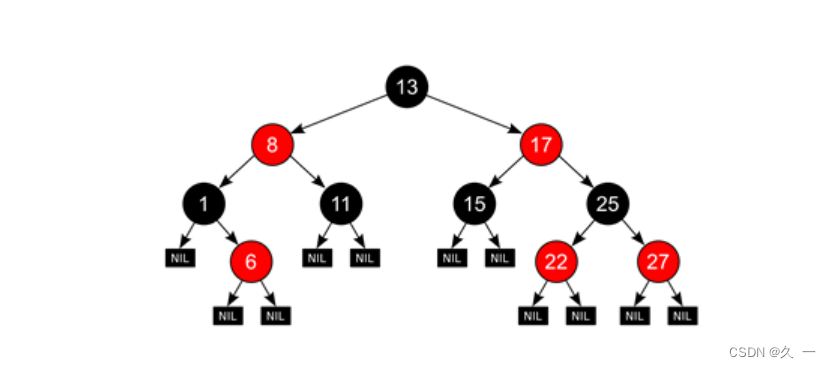
1.2.3 红黑树
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在普通二叉搜索树的基础上添加了额外的规则来保持树的平衡。红黑树的命名源自于每个节点都有一个颜色属性,可以是红色或黑色。
红黑树通过遵守以下五条规则来保持树的平衡性:
- 每个节点要么是红色,要么是黑色
- 根节点是黑色
- 每个叶子节点(NIL节点)都是黑色
- 如果一个节点是红色的,则其两个子节点必须都是黑色的
- 从任意节点到其每个叶子节点的简单路径上,黑色节点的数量相同
示意如下:
1.2.4 TreeMap
在Java中,TreeMap 是一种实现了 SortedMap 接口的有序映射集合。它基于红黑树(Red-Black Tree)数据结构来实现,可以确保其中的元素按照键的自然顺序或者自定义比较器进行排序。TreeMap 提供了一系列方法来操作键值对,具有快速查找、插入和删除的特性。
以下是 TreeMap 的一些特点和用法:
1、键的有序性:TreeMap 中的键是有序的,这是因为它基于红黑树来实现。键的排序可以是键类型的自然顺序,或者通过传入的 Comparator 对象来定义。
2、查找效率:由于红黑树是一种自平衡的二叉搜索树,TreeMap 中的查找、插入和删除操作的时间复杂度都是 O(log n),其中 n 是映射中键值对的数量。
3、允许 null 键:TreeMap 允许 null 键,但要注意在自定义比较器中处理 null 键的情况,否则可能导致异常。
TreeMap充分发挥了二叉搜索树的特点,为用户提供了一些与Key元素大小相关的方法。

1.2.5【案例】TreeMap示例
编写代码,测试TreeMap的使用。代码示意如下:
import java.util.Map;
import java.util.SortedMap;
import java.util.TreeMap;
public class TreeMapDemo {public static void main(String[] args) {TreeMap<Integer, String> treeMap = new TreeMap();treeMap.put(5,"Tom");treeMap.put(3,"Jerry");treeMap.put(9,"Lucy");treeMap.put(2,"Tony");// 遍历TreeMapfor(Map.Entry<Integer, String> entry : treeMap.entrySet()){System.out.println("key: " + entry.getKey()+", value: " + entry.getValue());}System.out.println("------------");// 返回临近的高值键值对Map.Entry<Integer,String> entry1 = treeMap.higherEntry(8);System.out.println("higherEntry(8): "+entry1);// 返回临近的低值键值对Map.Entry<Integer,String> entry2 = treeMap.lowerEntry(8);System.out.println("lowerEntry(8): "+entry2);System.out.println("------------");// 获取子集 key在 from和to之间,默认包前不包后SortedMap<Integer,String> subMap1 = treeMap.subMap(3,5);System.out.println("subMap(3, 5): "+subMap1);// 可设置是否包含边界System.out.println("------------");System.out.println("subMap(3, 5) include: "+treeMap.subMap(3, true, 9, true));// 返回逆序的集合System.out.println("------------");System.out.println("desc: "+treeMap.descendingMap());}
}1.2.6 TreeSet
在Java中,TreeSet 是一种实现了 SortedSet 接口的有序集合。它底层使用一个TreeMap的Key来存储所有的元素。TreeSet 中不允许包含重复的元素。

1.2.7【案例】TreeSet示例
编写代码,测试TreeSet的使用。代码示意如下:
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo {public static void main(String[] args) {Employee e1 = new Employee("Tom",18);Employee e2 = new Employee("Jerry",16);Employee e3 = new Employee("Lucy",13);Employee e4 = new Employee("Tony",20);TreeSet<Employee> set1 = new TreeSet();set1.add(e1);set1.add(e2);set1.add(e3);set1.add(e4);System.out.println("set1: "+set1);Comparator<Employee> cpt = new Comparator<Employee>() {@Overridepublic int compare(Employee o1, Employee o2) {return o1.name.compareTo(o2.name);}};TreeSet<Employee> set2 = new TreeSet(cpt);set2.addAll(set1);System.out.println("set2: "+set2);}
}
class Employee implements Comparable<Employee> {String name;int age;public Employee(String name, int age) {this.name = name;this.age = age;}@Overridepublic int compareTo(Employee o) {System.out.println(this.age + " compareTo" + o.age );return this.age - o.age;}@Overridepublic String toString() {return "Employee{" +"name='" + name + '\'' +", age=" + age +'}';}
}2 Lambda和Stream
2.1 Lambda表达式
2.1.1 什么是Lambda表达式
Java Lambda表达式是Java编程语言中的一个功能,它允许您将代码块作为参数传递给方法或作为返回值从方法中返回。Lambda表达式是一个匿名函数,它没有名称,但它可以像普通方法一样传递参数并执行代码。
Lambda表达式的语法类似于函数式编程语言中的函数定义,使用箭头符号"->"来将参数列表和函数体分开。Lambda表达式通常用于简化代码,特别是在使用函数接口(Functional Interface)时,它允许您使用更少的代码来定义方法。
2.1.2 函数接口(Functional Interface)
函数式接口是Java 8中引入的一个概念,它是指只有一个抽象方法的接口。由于只有一个抽象方法,因此函数式接口可以看作是一个函数类型,可以用Lambda表达式来表示。函数式接口的特点是允许使用Lambda表达式来创建该接口的实例。
由于函数式接口只有一个抽象方法,因此可以用@FunctionalInterface注解来标识它们。这个注解可以帮助开发人员检查接口是否符合函数式接口的要求。这个注解不是必须标注的注解!
例如,以下代码定义了函数式接口,并在其中定义一个抽象方法:
@FunctionalInterface
public interface MyFunction {int apply(int x, int y);
}使用Lambda表达式作为函数式接口的实现:
MyFunction add = (a, b)-> a + b;
int result = add.apply(2,3);
System.out.println(result); // 结果为52.1.3 【案例】Lambda的基本使用
测试Lambda表达式的使用,代码示意如下:
@FunctionalInterface
public interface MyFunction {int apply(int x, int y);
}
public class LamdbaDemo {public static void main(String[] args) {MyFunction add = (a,b)-> a + b;int result = add.apply(2, 3);System.out.println(result);}
}上述代码中,Lambda表达式被赋值给一个函数式接口类型的变量add;然后可以像一个方法一样被调用:将参数2和3传递给Lambda表达式,它将返回这两个数字的和5。
这个Lambda表达式的返回类型是int,与MyFunction接口中定义的apply方法的返回类型相匹配。
2.1.4 Lambda完整语法
Lambda的使用示例如下:
MyFunction add = (x, y) -> x + y;语法形如:
(参数) -> {主体}Lambda表达式有以下组成部分:
1、参数列表:(x, y)
Lambda表达式的参数列表可以为空,或包含一个或多个参数,参数类型可以显式指定,也可以由编译器根据上下文推断得出。如果只有一个参数时候,可以省略括号 ()。
2、箭头:->
箭头符号将参数列表和Lambda表达式的主体分开。箭头左侧表示参数列表,箭头右侧表示Lambda表达式的主体。
3、主体:x + y
Lambda表达式的主体可以是一个表达式,也可以是一段代码块。如果主体是一个表达式,则不需要使用return关键字返回结果。如果主体是一段代码块,则需要使用{}囊括代码块,并且使用return语句返回结果。
4、返回值
Lambda表达式的返回值类型,和函数式接口的apply方法的返回类型一致,否则会出现编译错误。
例如,对于只有一个参数的函数式接口:
public interface MyFunction1 {int apply(int x);
}可以使用Lambda表达式来计算任何整数的平方。由于Lambda表达式只有一个参数,因此我们不需要使用括号将参数括起来,例如:
public class LambdaDemo1 {public static void main(String[] args) {//只有一个参数时候,可以省略参数 ()MyFunction1 square = x -> x*x;int result = square.apply(3);System.out.println(result); // 输出 9}
}下面是一个多行语句实现的Lambda表达式的例子:
public class LambdaDemo2 {public static void main(String[] args) {MyFunction1 factorial = x -> {int result = 1;for (int i = 1; i <= x; i++) {result *= i;}return result;};int result = factorial.apply(5);System.out.println(result); // 输出 120}
}这个Lambda表达式实现了函数式接口MyFunction,其中apply方法接受一个整数参数并返回一个整数。这个Lambda表达式有一个参数x,它的主体包含了多个语句,用于计算参数的阶乘。
在Lambda表达式的主体中,我们首先声明一个变量result,并将其初始化为1。然后,我们使用for循环计算参数x的阶乘,并将结果存储在result变量中。最后,我们使用return语句返回结果。
我们可以使用这个Lambda表达式来计算任何整数的阶乘,例如我们传入整数5给Lambda表达式,它返回5的阶乘值120,并将结果打印到控制台。由于Lambda表达式包含多个语句,因此我们需要使用花括号将语句块括起来,并使用return语句返回结果。
2.1.5 【案例】使用Lambda过滤文件夹内容
本案例需要实现:过滤文件夹中以“M”为开头的文件。
Java中的FileFilter是功能性接口,其接口声明为:
@FunctionalInterface
public interface FileFilter {boolean accept(File pathname);
}方式一:用内部类实现
import java.io.File;
import java.io.FileFilter;
public class FilterFiles1 {public static void main(String[] args) {File folder = new File("./src/jaf_07");// 使用内部类实现文件过滤器FileFilter fileFilter = new FileFilter() {@Overridepublic boolean accept(File file) {return file.isFile() && file.getName().startsWith("M");}};// 获取过滤后的文件列表File[] filteredFiles = folder.listFiles(fileFilter);// 输出过滤后的文件列表for (File file : filteredFiles) {System.out.println(file.getName());}}
}方式二:用 Lambda 表达式实现
import java.io.File;
public class FilterFiles2 {public static void main(String[] args) {File folder = new File("./src/jaf_07");// 使用 Lambda 表达式实现文件过滤器File[] filteredFiles = folder.listFiles(file -> file.isFile() && file.getName().startsWith("M"));// 输出过滤后的文件列表for (File file : filteredFiles) {System.out.println(file.getName());}}
}两种写法的功能都是一样的,都是过滤文件夹中以 "M" 为开头的文件。但是,Lambda 写法相比内部类写法更加简洁和易读。Lambda 表达式可以将代码压缩到一行中,避免了冗长的内部类语法。此外,Lambda 表达式具有更高的可读性,因为它们强调了操作的目的而不是实现。Lambda 表达式还可以使代码更加函数式,这使得它们更容易与其他函数式编程技术和库进行交互。
Java Lambda表达式有以下好处:
- 简化代码:Lambda表达式可以让代码更简洁,减少了样板代码,使代码更易读
- 增加可读性:Lambda表达式可以使代码更易读和易懂,通过Lambda表达式可以将方法的逻辑和关键代码部分更加清晰地表达出来
- 提高可维护性:使用Lambda表达式可以减少代码中的重复性,使代码更易于维护
- 支持函数式编程:Lambda表达式支持函数式编程,可以方便地使用函数式接口进行函数组合,从而更加简洁地表达程序逻辑
- 并行编程支持:Lambda表达式可以支持并行编程,可以使用Java Stream API来处理大规模数据集合
- 提高性能:Lambda表达式的执行效率比传统的匿名内部类更高
总之,Lambda表达式是Java 8中最受欢迎和强大的新特性之一。它们使Java编程语言更具现代化,更加灵活,并提供了更强大的编程工具,以更好地支持现代应用程序开发。
2.1.6 函数引用
Java 8 引入了函数引用(Method references)的概念,使得我们可以更方便地使用已有的方法或构造函数作为 Lambda 表达式。函数引用可以简化代码,使得代码更加简洁易懂。
Java 函数引用的语法形式为:
持有者::方法名其中,“持有者”可以是类或对象,“方法名”则根据具体情况分为4种。
函数引用可以分为以下四种类型:
- 静态方法引用:引用一个已有的静态方法,例如:Math::abs
- 实例方法引用:引用一个已有的实例类型方法,例如:String::length
- 对象方法引用:引用一个已有的实例对象方法,例如:out::println
- 构造函数引用:引用一个已有的构造函数(使用较少),例如:ArrayList::new
2.1.7 函数引用类型
1、Object::instanceMethod
实例方法引用,使用一个对象的实例方法作为函数接口的实现。代码示意如下:
import java.util.function.Function;
public class MethodRefDemo1 {public static void main(String[] args) {//使用字符串对象 str 的 charAt 方法作为 Function 接口的实现,返回第 6 个字符。String str = "Hello World";Function<Integer, Character> function = str::charAt;char c = function.apply(6);}
}上述代码中,使用字符串对象 str 的 charAt 方法作为 Function 接口的实现,返回第 6 个字符。
2、Class::instanceMethod
类方法引用,使用一个类的实例方法作为函数接口的实现。代码示意如下:
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
public class MethodRefDemo3 {public static void main(String[] args) {//使用 String 类的 compareToIgnoreCase 方法作为 //Collections.sort 方法的比较器,实现对列表的忽略大小写排序。List<String> list = Arrays.asList("one", "two", "three");Collections.sort(list, String::compareToIgnoreCase);System.out.println(list);}
}上述代码中,使用 String 类的 compareToIgnoreCase 方法作为 Collections.sort 方法的比较器,实现对列表的忽略大小写排序。
3、Class::staticMethod
静态方法引用,使用一个类的静态方法作为函数接口的实现。代码示意如下:
import java.util.function.Function;
public class MethodRefDemo2 {public static void main(String[] args) {//使用 Integer 类的 parseInt 方法作为 Function 接口的实现,将字符串 "123" 转换为整数。Function<String, Integer> function = Integer::parseInt;int num = function.apply("123");System.out.println(num);}
}上述代码中,使用 Integer 类的 parseInt 方法作为 Function 接口的实现,将字符串 "123" 转换为整数。
4、Class::new
构造器引用,使用一个类的构造器作为函数接口的实现。代码示意如下:
//使用ArrayList的构造器函数引用作为Lambda表达式
Supplier<ArrayList<String>> supplier = ArrayList::new;
ArrayList<String> arrayList = supplier.get();
arrayList.add("Tom");
System.out.println(arrayList);我们定义了一个 Supplier 函数接口的实例,它引用了 ArrayList的默认构造函数。最后我们使用 supplier.get() 方法创建了一个新的 ArrayList对象。
需要注意的是,函数引用只是 Lambda 表达式的一种语法简写形式,本质上还是使用 Lambda 表达式来实现函数接口的实现。在实际使用中,需要根据具体情况选择使用 Lambda 表达式还是函数引用,以实现代码的最佳简洁性和可读性。
函数作为只是 Lambda 表达式的一种语法简写形式,Java 函数引用可以替代 Lambda 表达式的一些场景,特别是当 Lambda 表达式只包含单一方法调用时。
2.1.8 【案例】Lambda示例1
对于一个 List 中的每个元素,打印出它们的值:
import java.util.Arrays;
import java.util.List;
public class MethodRefDemo4 {public static void main(String[] args) {List<String> names = Arrays.asList("Tom", "Jerry", "Andy");//使用Lambda输出集合内容, Lambda 中只有一个方法调用names.forEach(name -> System.out.println(name));//使用函数引用输出集合内容names.forEach(System.out::println);}
}上述代码使用了对象方法引用,将 println 方法引用传递给了 forEach 方法,实现了对每个元素的输出。
2.1.9 【案例】Lambda示例2
将一个字符串转换为大写形式:
import java.util.function.Function;
public class MethodRefDemo5 {public static void main(String[] args) {//使用Lambda表达式将字符串转化为大些Function<String, String> upperCase1 = (str) -> str.toUpperCase();String s = upperCase1.apply("Tom");System.out.println(s);//使用函数引用将字符串转化为大写Function<String, String> upperCase2 = String::toUpperCase;String ss = upperCase2.apply("Tom");System.out.println(ss);}
}上述代码使用了实例方法引用,将 toUpperCase 方法引用传递给了 Function 函数式接口,实现了字符串的大写转换。
2.1.10 【案例】Lambda示例3
import jaf.day03.cases.Student;
import java.util.Arrays;
import java.util.List;
public class MethodRefDemo6 {public static void main(String[] args) {Student s1 = new Student("Tom", 18, 88.5);Student s2 = new Student("Jerry", 16, 95);Student s3 = new Student("Lucy", 17, 100);List<Student> list = Arrays.asList(s1,s2,s3);// 使用Lambda表达式提供Comparator接口实现list.sort((o1,o2)->o1.age-o2.age);list.forEach(System.out::println);}
} 2.2 Stream API
2.2.1 什么是 Stream API
Java 8 Stream是Java 8中引入的一个新的API,用于处理集合和数组等数据结构的元素。它允许您在数据集上进行功能性操作,例如过滤、映射、排序等,而不需要编写循环或迭代器等底层代码。
Java 8 Stream与集合不同,它并不是一个数据结构,而是一种可操作的流。流可以是无限的,也可以是有限的。在使用流进行操作时,不会改变原始数据集合中的数据,而是返回一个新的流。
Stream API包含了丰富的操作方法,例如过滤、映射、排序、归约等,使得对数据集合进行操作变得非常方便。Java 8 Stream的使用可以极大地简化代码,并提高代码的可读性和可维护性。
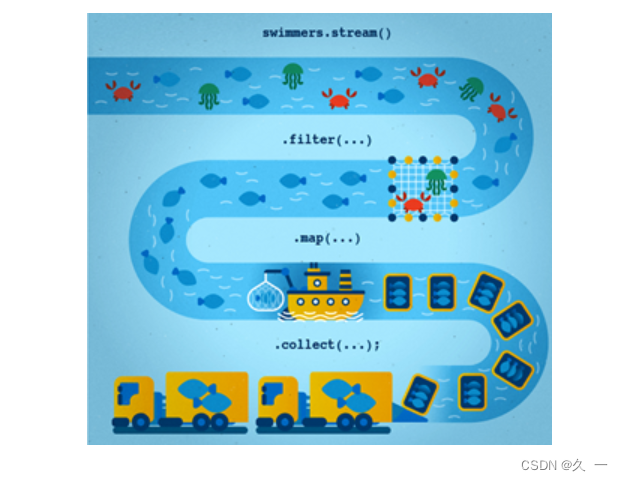
2.2.2 初识Stream API
用一个案例来认识StreamAPI的使用:过滤“J”开头的用户名。
方式一:用传统的循环方式处理
List<String> names = Arrays.asList("John", "Jane", "Bob", "Tom");//传统Java编码实现找出J开头的人名List<String> jNames = new ArrayList<>();for (String name : names){if (name.startsWith("J")){jNames.add(name);}}System.out.println(jNames);// 输出:[John, Jane]方式二:用 Stream API
//使用Stream API实现找出J开头的人名List<String> filteredNames = names.stream().filter(name -> name.startsWith("J")).collect(Collectors.toList());System.out.println(filteredNames); // 输出:[John, Jane]上述代码中采用了两种方式实现了过滤“J”开头的用户名,一种是传统for循环方式,另外一种就是Stream API。可以看到使用Stream方式可以大大简化代码。Stream方式中,先使用stream()方法将集合转换为流,然后使用filter()方法筛选以“J”开头的字符串,最后使用collect()方法将筛选后的结果转换为List集合。
2.2.3 常用Stream API方法
Java 8中常用的Stream API主要包括以下几个:
- filter:过滤流中的元素,只保留符合条件的元素
- map:对流中的元素进行映射,将一个元素映射为另一个元素
- flatMap:对流中的元素进行扁平化映射,将一个元素映射为多个元素
- sorted:对流中的元素进行排序
- distinct:去重,保留流中的不同元素
- limit:限制流中元素的数量
- skip:跳过流中的前N个元素
- forEach:遍历流中的元素
- reduce:对流中的元素进行归约,得到一个结果
- collect:将流中的元素收集到一个集合中
- min和max:找出流中的最小值和最大值
- count:统计流中元素的数量
- anyMatch、allMatch和noneMatch:判断流中的元素是否满足某个条件
- findFirst和findAny:找到流中的第一个元素和任意一个元素
- parallel和sequential:切换流的并行和串行模式
上述API定义在集合类和Collectors类上,可以让我们对流进行过滤、映射、排序、去重、统计、归约等常见的操作,并且提供了并行处理的支持,可以充分利用多核处理器的性能,提高程序的执行效率。
2.2.4 Stream API的使用步骤
Java 8 Stream API的使用方法主要分为以下几个步骤:
1、创建流
通过集合、数组或者Stream类中提供的静态方法创建流。例如,通过集合创建流:
List<String> list = Arrays.asList("apple", "banana", "orange");
Stream<String> stream = list.stream();2、中间操作
对流进行中间操作,可以使用filter、map、flatMap、sorted、distinct、limit、skip等操作。例如,使用filter方法过滤集合中的元素:
stream = stream.filter(s -> s.startsWith("a"));3、终止操作
对流进行终止操作,可以使用forEach、reduce、collect、min、max、count等操作。例如,使用forEach方法遍历流中的元素:
stream.forEach(System.out::println);4、并行处理
对于大数据集,可以使用并行流来提高程序的执行效率,可以使用parallel和sequential方法来切换并行和串行模式。例如,使用parallel方法将流转换为并行流:
stream = stream.parallel();以上是Java 8 Stream API的使用方法,可以通过这些步骤来创建、操作和处理流。需要注意的是,在使用Stream API时,应该避免在操作中修改流中的元素,以免出现意外的结果。
2.2.5 【案例】Stream API的使用示例1:筛选数据
筛选数据:筛选以“J”开头的字符串。代码示意如下:
List<String> names = Arrays.asList("John", "Jane", "Bob", "Tom");
List<String> filteredNames = names.stream().filter(name -> name.startsWith("J")).collect(Collectors.toList());
System.out.println(filteredNames); // 输出:[John, Jane]上述代码中,使用stream()方法将集合转换为流,然后使用filter()方法筛选以“J”开头的字符串,最后使用collect()方法将筛选后的结果转换为List集合。
2.2.6 【案例】Stream API的使用示例2:映射数据
映射字符串的长度,代码示意如下:
List<String> names = Arrays.asList("John", "Jane", "Bob", "Tom");
List<Integer> nameLengths = names.stream().map(String::length).collect(Collectors.toList());
System.out.println(nameLengths); // 输出:[4, 4, 3, 3]上述代码中,使用stream()方法将集合转换为流,然后使用map()方法将字符串映射为字符串长度,最后使用collect()方法将映射后的结果转换为List集合。
2.2.7 【案例】Stream API的使用示例3:统计数据
统计数据,代码示意如下:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
long count = numbers.stream().count();
int max = numbers.stream().max(Integer::compare).orElse(0);
int min = numbers.stream().min(Integer::compare).orElse(0);
int sum = numbers.stream().mapToInt(Integer::intValue).sum();
double average = numbers.stream().mapToInt(Integer::intValue).average().orElse(0.0);
System.out.println("Count: " + count); // 输出:Count: 5
System.out.println("Max: " + max); // 输出:Max: 5
System.out.println("Min: " + min); // 输出:Min: 1
System.out.println("Sum: " + sum); // 输出:Sum: 15
System.out.println("Average: " + average); // 输出:Average: 3.0上述代码中,使用count()方法统计流中元素的个数,使用max()和min()方法求出流中的最大值和最小值,使用sum()方法求出流中元素的总和,使用average()方法求出流中元素的平均值。
2.2.8 【案例】Stream API的使用示例4:排序数据
实现数据排序,代码示意如下:
List<Integer> numbers = Arrays.asList(3, 2, 1, 5, 4);
List<Integer> sortedNumbers = numbers.stream().sorted().collect(Collectors.toList());
System.out.println(sortedNumbers); // 输出:[1, 2, 3, 4, 5]上述代码中,使用sorted()方法对流中的元素进行排序,最后使用collect()方法将排序后的结果转换为List集合。
以上是一些Java 8 Stream API的基本案例,这些案例只是展示了Stream API的基本用法,还有更多丰富的操作可以使用,例如归约、去重、分组、分区等。



】【Python】【和为 K 的子数组】【前缀和】【中等】)
:数据库主从同步的原理)

)












