测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中
分组聚合导致的数据倾斜
优化说明
前文提到过,Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
如果group by分组字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由分组聚合导致的数据倾斜问题,有以下两种解决思路:
(1)Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。
相关参数如下:
–启用map-side聚合
set hive.map.aggr=true;
–用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
–用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
–map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;
(2)Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
相关参数如下:
–启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;
优化案例
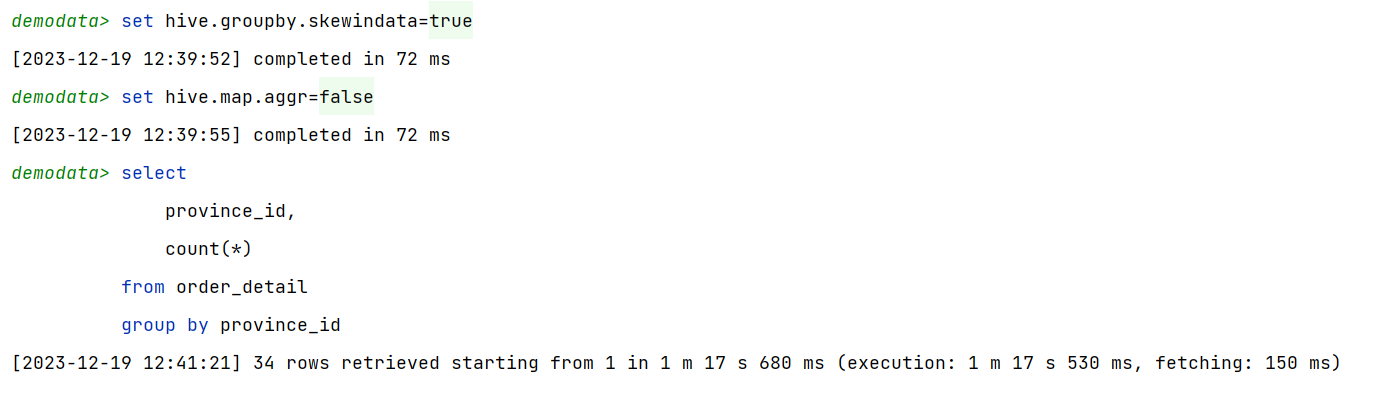
(1)示例SQL语句
selectprovince_id,count(*)
from order_detail
group by province_id;
(2)优化前
该表数据中的province_id字段是存在倾斜的,若不经过优化,通过观察任务的执行过程,是能够看出数据倾斜现象的。
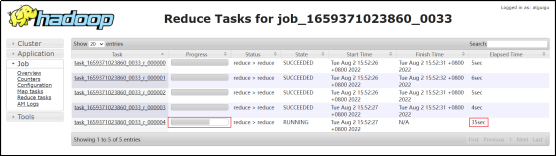
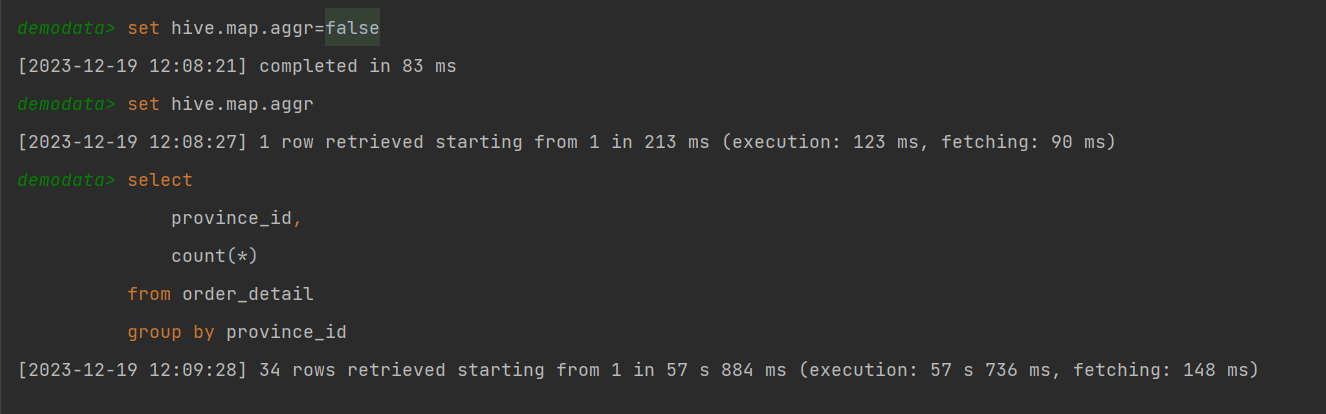
需要注意的是,hive中的map-side聚合是默认开启的,若想看到数据倾斜的现象,需要先将hive.map.aggr参数设置为false。
(3)优化思路
通过上述两种思路均可解决数据倾斜的问题。下面分别进行说明:
(1)Map-Side聚合
设置如下参数
–启用map-side聚合
set hive.map.aggr=true;
–关闭skew-groupby
set hive.groupby.skewindata=false;
开启map-side聚合后的执行计划如下图所示:

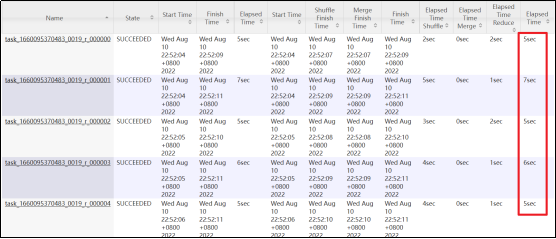
很明显可以看到开启map-side聚合后,reduce数据不再倾斜。
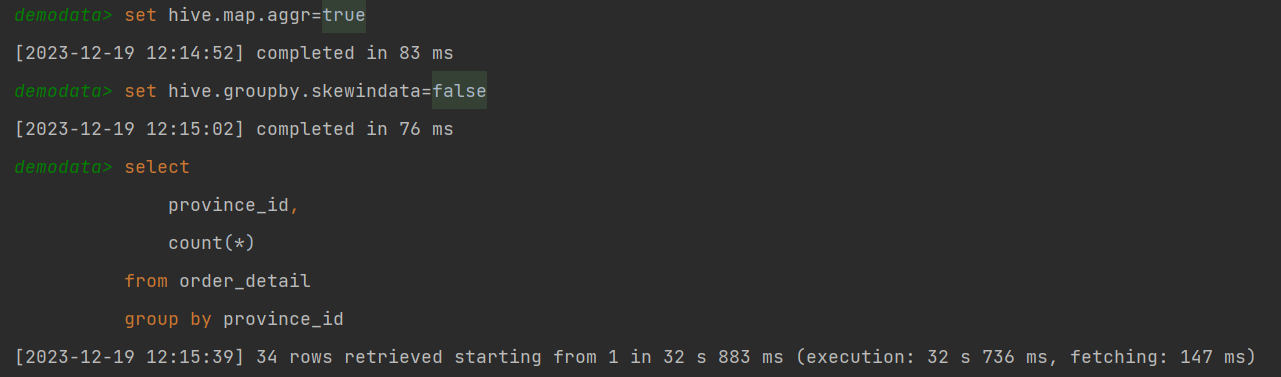
(2)Skew-GroupBy优化
设置如下参数
–启用skew-groupby
set hive.groupby.skewindata=true;
–关闭map-side聚合
set hive.map.aggr=false;
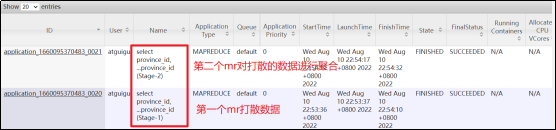
开启Skew-GroupBy优化后,可以很明显看到该sql执行在yarn上启动了两个mr任务,第一个mr打散数据,第二个mr按照打散后的数据进行分组聚合。
Join导致的数据倾斜
优化说明
前文提到过,未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由join导致的数据倾斜问题,有如下三种解决方案:
(1)map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。该方案适用于大表join小表时发生数据倾斜的场景。
相关参数如下:
–启动Map Join自动转换
set hive.auto.convert.join=true;
–一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
–开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
–无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;
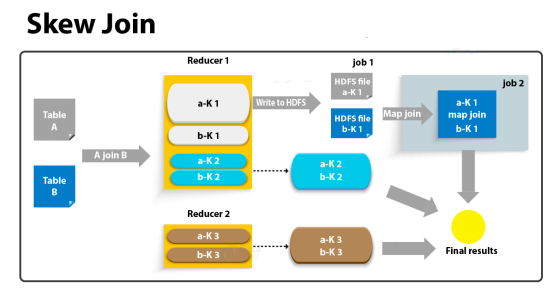
(2)skew join
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。原理图如下:
相关参数如下:
–启用skew join优化
set hive.optimize.skewjoin=true;
–触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;
这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
(3)调整SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
假设原始SQL语句如下:A,B两表均为大表,且其中一张表的数据是倾斜的。
select*
from A
join B
on A.id=B.id;
其join过程如下:
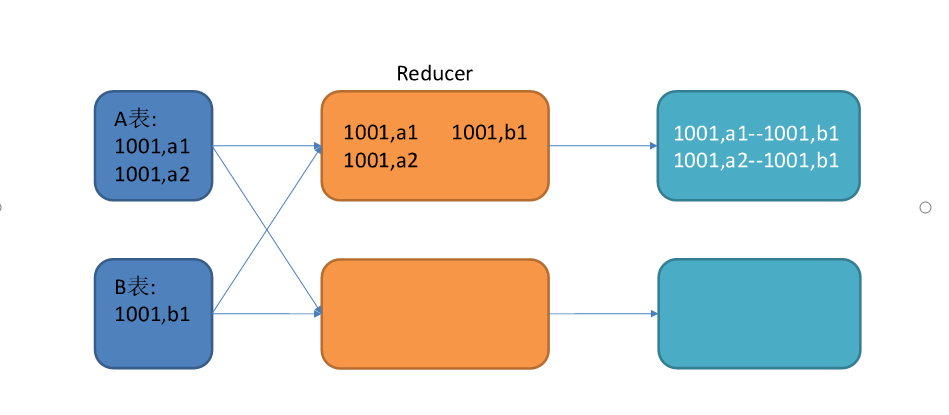
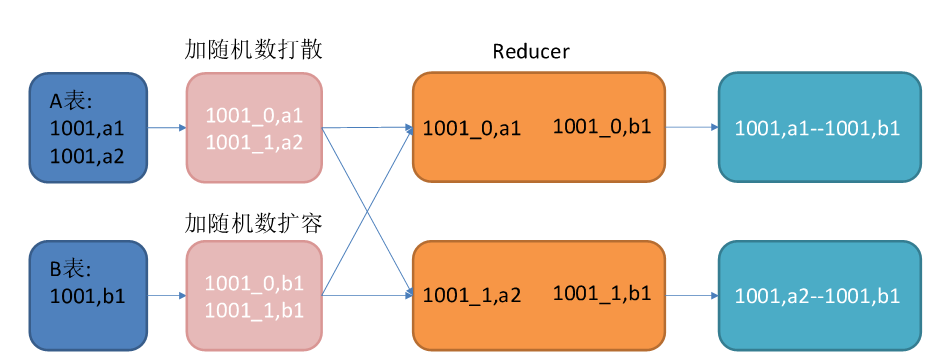
图中1001为倾斜的大key,可以看到,其被发往了同一个Reduce进行处理。
调整SQL语句如下:
select*
from(select --打散操作concat(id,'_',cast(rand()*2 as int)) id,valuefrom A
)ta
join(select --扩容操作concat(id,'_',0) id,valuefrom Bunion allselectconcat(id,'_',1) id,valuefrom B
)tb
on ta.id=tb.id;
调整之后的SQL语句执行计划如下图所示:
优化案例
(1)示例SQL语句
select*
from order_detail od
join province_info pi
on od.province_id=pi.id;
(2)优化前
order_detail表中的province_id字段是存在倾斜的,若不经过优化,通过观察任务的执行过程,是能够看出数据倾斜现象的。
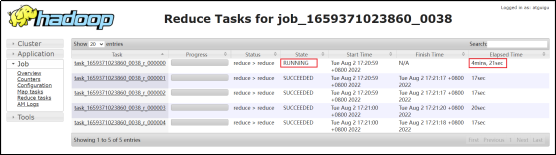
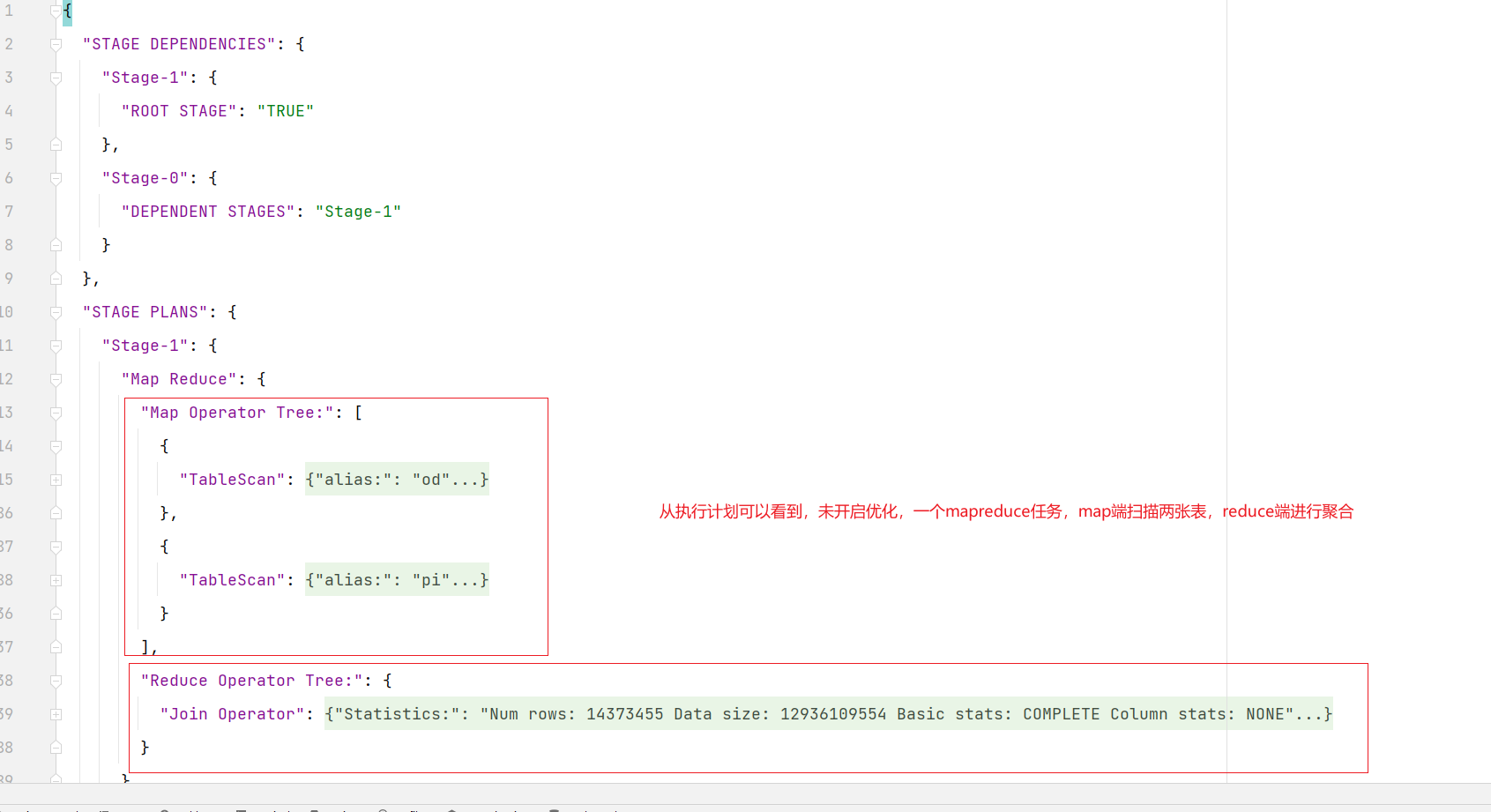

需要注意的是,hive中的map join自动转换是默认开启的,若想看到数据倾斜的现象,需要先将hive.auto.convert.join参数设置为false。
3)优化思路
上述两种优化思路均可解决该数据倾斜问题,下面分别进行说明:
(1)map join
设置如下参数
–启用map join
set hive.auto.convert.join=true;
–关闭skew join
set hive.optimize.skewjoin=false;
可以很明显看到开启map join以后,mr任务只有map阶段,没有reduce阶段,自然也就不会有数据倾斜发生。执行计划里面有MapJoin
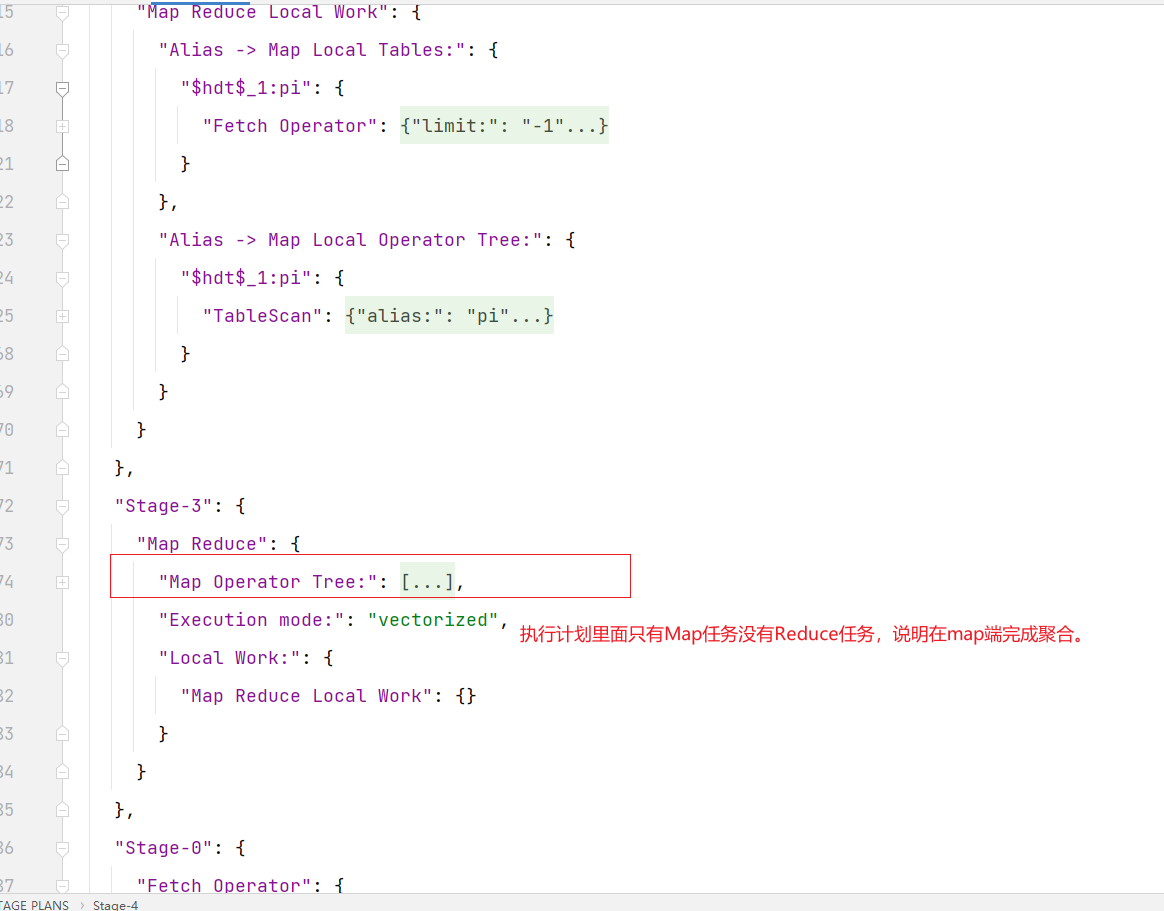
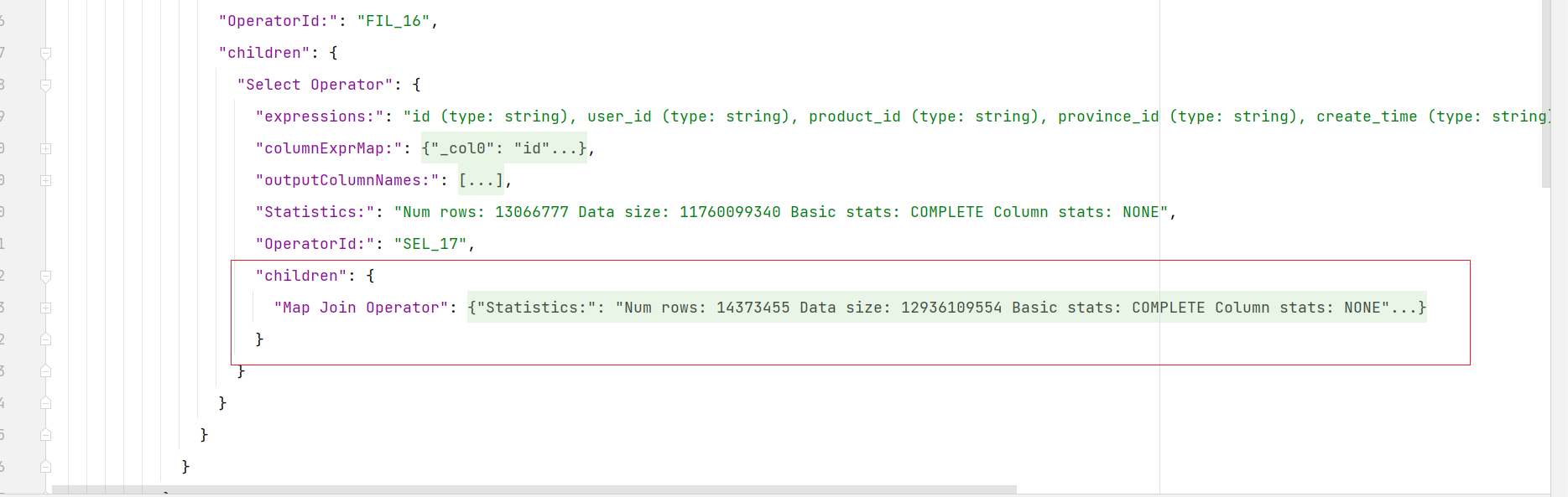


(2)skew join
设置如下参数
–启动skew join
set hive.optimize.skewjoin=true;
–关闭map join
set hive.auto.convert.join=false;
–增加map端容器内存
set mapreduce.map.memory.mb=2048;
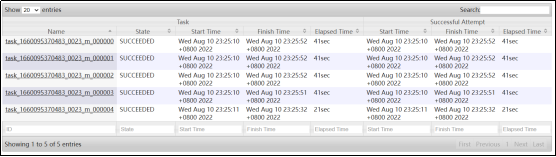
开启skew join后,使用explain可以很明显看到执行计划如下图所示,说明skew join生效,任务既有common join,又有部分key走了map join。

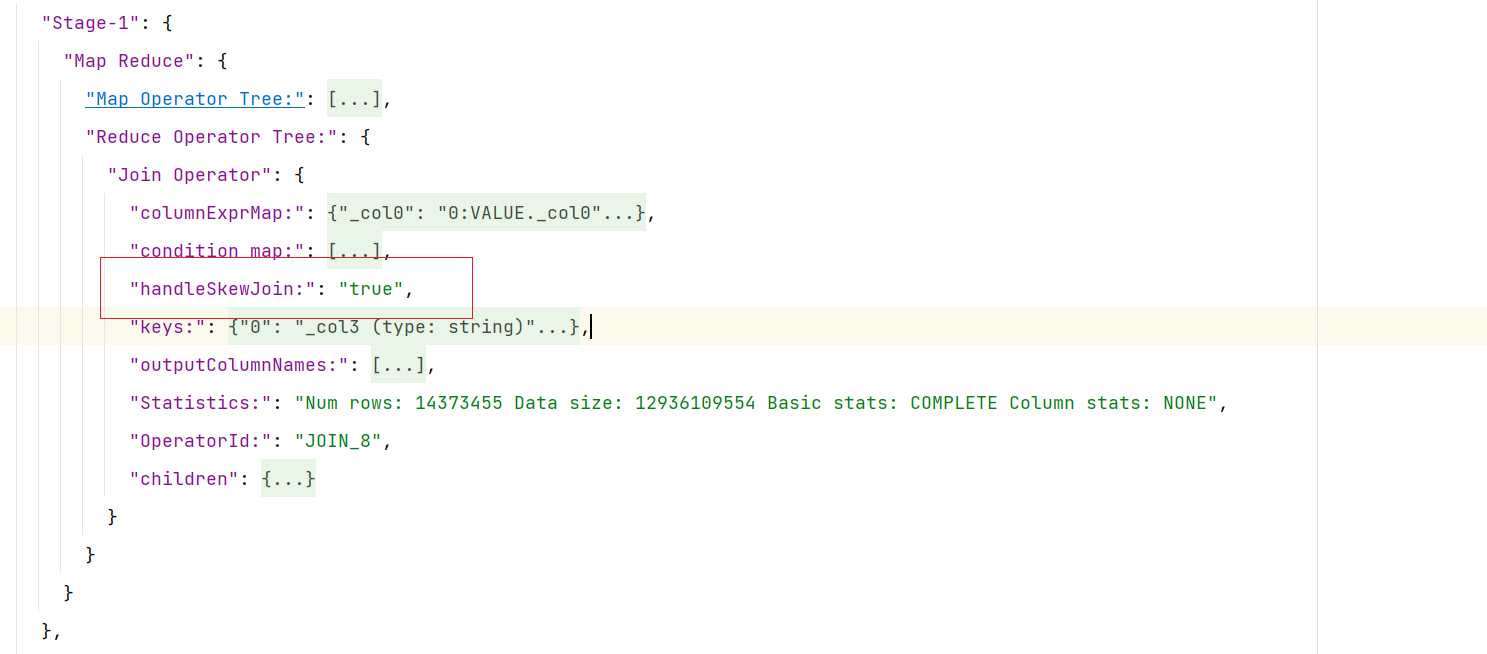

并且该sql在yarn上最终启动了两个mr任务,而且第二个任务只有map没有reduce阶段,说明第二个任务是对倾斜的key进行了map join。

















,仅需三步)

