声明:
注意!!!
本博客仅用于本人学习笔记作用,所有资料来源都来自于李沐大神,博客中图片为沐神书上的图片。如有侵权,请联系本人删除,谢谢。
资料来源:https://zh-v2.d2l.ai/chapter_introduction/index.html
笔记
本章主要涉及一些简单的数据操作,此笔记也没有按照书上的顺利来写,只是将自己看书时的疑问记录下来。
张量和向量
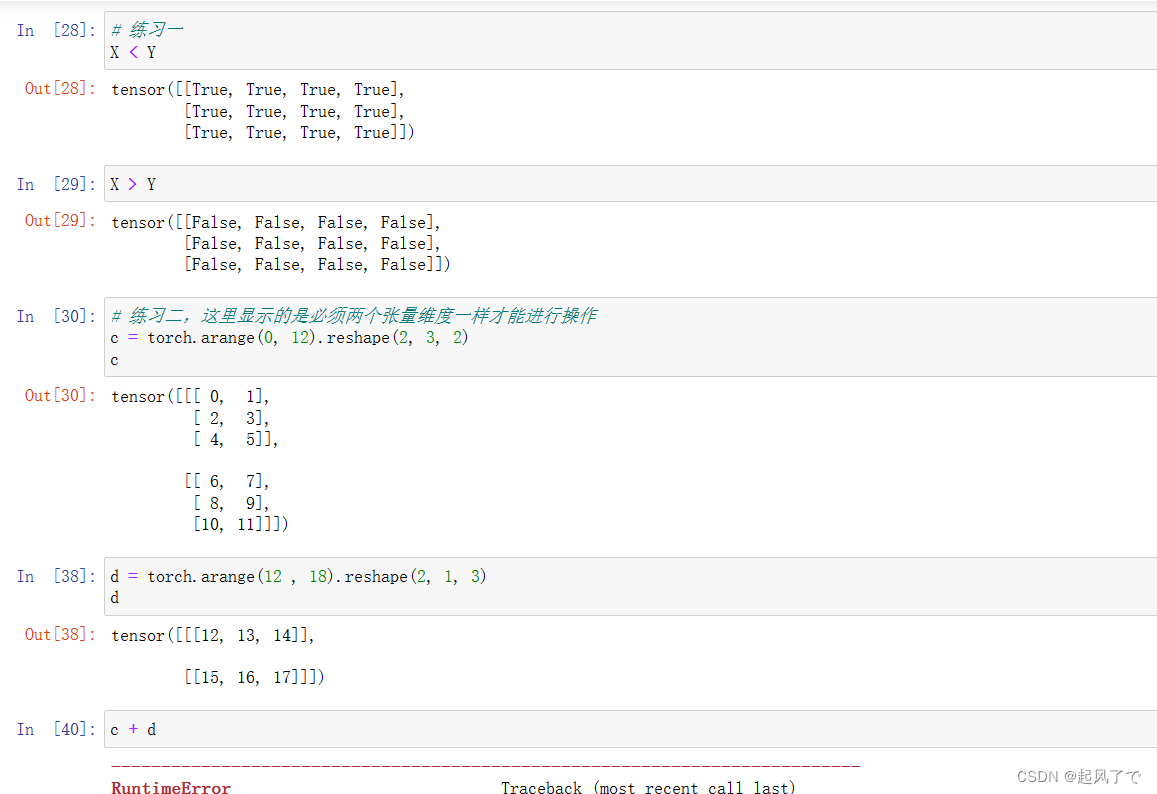
n维数组也称为张量;一个轴的张量对应数学上的向量;两个轴的张量对应数学上的矩阵;两个轴以上的张量没有特殊的数学名称。
可以通过张量的shape属性来访问张量(沿每个轴的长度)的形状 。
shape参数的个数对应维数,每一参数代表该维度上的长度。
# reshape函数,改变张量的形状而不改变原数数量和元素值
X = x.reshape(3, 4)
X tensor([[ 0, 1, 2, 3],[ 4, 5, 6, 7],[ 8, 9, 10, 11]])"""
此处选用了一个reshape,可以更加直观的看到,该张量第一个维度为2,第二个维度为4。
"""
如果我们的目标形状是(高度,宽度), 那么在知道宽度后,高度会被自动计算得出,不必我们自己做除法。 在上面的例子中,为了获得一个3行的矩阵,我们手动指定了它有3行和4列。 幸运的是,我们可以通过-1来调用此自动计算出维度的功能。 即我们可以用x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)。
torch.randn() 函数
torch.randn 函数生成的随机数遵循标准正态分布,也就是均值为0,标准差为1的分布。这意味着生成的随机数在接近0的区域出现的概率较高,而在离0较远的区域出现的概率较低,整体呈钟形曲线分布。这种标准正态分布在统计和深度学习中经常被使用,因为它具有许多有用的性质。
运算符
dim参数:
dim = 0:在垂直方向进行拼接;dim = 1:在水平方向上进行拼接。
# 把多个张量连接(concatenate)起来,行拼接为 0, 列拼接为 1
X = torch.arange(12, dtype=torch.float32).reshape((3, 4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)(tensor([[ 0., 1., 2., 3.],[ 4., 5., 6., 7.],[ 8., 9., 10., 11.],[ 2., 1., 4., 3.],[ 1., 2., 3., 4.],[ 4., 3., 2., 1.]]),tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],[ 4., 5., 6., 7., 1., 2., 3., 4.],[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
广播机制
广播机制是一种在不同形状的张量之间执行操作的方式,使得它们可以进行元素级操作而无需显式扩展其形状。
-
a = torch.arange(3).reshape((3, 1)):这行代码创建了一个大小为 (3, 1) 的张量 a,它包含了从 0 到 2 的连续整数,并且将这些整数重新塑造为一个 3x1 的矩阵。
-
b = torch.arange(2).reshape((1, 2)):这行代码创建了一个大小为 (1, 2) 的张量 b,它包含了从 0 到 1 的连续整数,并且将这些整数重新塑造为一个 1x2 的矩阵。
# 广播机制
a = torch.arange(3).reshape(3, 1)
b = torch.arange(2).reshape(1, 2)
a , b(tensor([[0],[1],[2]]),tensor([[0, 1]]))
a + b
在这个操作中,a 和 b 的形状不同,a 的形状是 (3, 1),而 b 的形状是 (1, 2)。根据广播机制的规则,PyTorch将自动扩展它们的形状,使它们具有相同的形状。这是如何扩展的:
张量 a 扩展为 (3, 2) 的形状,通过在第二个维度(列)上复制。
张量 b 扩展为 (3, 2) 的形状,通过在第一个维度(行)上复制。
最终,a 和 b 都被扩展为 (3, 2) 的形状,然后可以进行元素级的加法操作。最后的结果将是一个大小为 (3, 2) 的张量,包含了对应位置的元素相加的结果。
所以,这段代码的输出将会是:
a:
tensor([[0],[1],[2]])b:
tensor([[0, 1]])result:
tensor([[0, 1],[1, 2],[2, 3]])张量 a 和 b 扩展后的结果如下:
张量 a 扩展为 (3, 2) 的形状,通过在第二个维度(列)上复制,结果如下:
tensor([[0, 0],[1, 1],[2, 2]])
张量 b 扩展为 (3, 2) 的形状,通过在第一个维度(行)上复制,结果如下:
tensor([[0, 1],[0, 1],[0, 1]])
这两个张量扩展后的形状都是 (3, 2),它们分别在行和列上被复制以匹配最终的形状,以便进行元素级的操作。在元素级操作中,它们将相应位置的元素相加,最终得到以下结果:
result:
tensor([[0, 1],[1, 2],[2, 3]])
内存
在内存这一块采用如下方法可保证后续的内存相同:
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
在pycharm测试时发现 X += Y 后X指向的内存与之前的并不一样。
# -*- coding: utf-8 -*-
# Author: xxx
"""
内存
"""x = 12
print(id(x))y = 13
print(id(y))x += y
print('此时x的内存地址为: %s' % id(x))"""
2229481532048
2229481532080
此时x的内存地址为: {2229481532464}
"""
练习


)



)
】【Python】【接雨水】【单调栈】【困难】)





)
)




