文章目录
- 一. Trino架构
- 1. 架构概览
- 2. 协调器
- 3. 发现服务
- 4. 工作节点
- 二. 基于连接器的架构
- 三. 查询执行模型
- 1. 解析—>查询计划
- 2. 查询计划 —> 分布式查询计划
- 3. 运行阶段
- 3.1. 基础概念
- 切片:并行单元
- page 与 exchange算子
- pipeline
- 切片的driver
- Operator
- 3.2. running 概述
本文主要讨论了
- Trino的架构,它使用一个协调器来接收用户请求,之后调用工作节点来组装来自数据源的全部数据。
- trino架构组件:协调者、worker、发现服务
- trino连接器架构的细节:连接器功能内容、通过catalog来配置连接数据源的不同行为,协调者、worker使用不同的连接器接口
- trino的查询执行模型
每个查询都被翻译成分布式查询计划,该查询计划由多个stage中的任务构成。- 数据以切片形式由连接器返回,并在多个stage中处理,直到最终结果可用并由协调器提供给用户。
一. Trino架构
1. 架构概览
Trino是一个分布式SQL查询引擎,大规模并行处理(Massively Parallel Processing,MPP)的数据库和查询引擎。Trino通过在整个集群的服务器上分配处理任务来实现横向扩展,而非通过提高单台服务器的性能来进行垂直扩展。
基于这种架构,Trino查询引擎在集群内的计算节点上可以并行处理海量数据上的SQL查询。在每个计算节点上,Trino都以单个服务器进程的形式运行。一个Trino集群由多个被配置为相互协作的Trino节点组成。
集群架构
A Trino cluster consists of a coordinator and many workers. Users connect to the coordinator with their SQL query tool. The coordinator collaborates with the workers. The coordinator and the workers access
the connected data sources. This access is configured in catalogs.
Processing each query is a stateful operation. The workload is orchestrated by the coordinator and spread parallel across all workers in the cluster. Each node runs Trino in one JVM instance, and
processing is parallelized further using threads.
trino架构由(至少)一个协调者和多个worker组成,用户通过SQL工具与coordinator连接。coordinator管理workers。通过配置catalogs,coordinator 和 the workers访问已连接的数据源。
每个查询的执行都是状态操作,coordinator编排工作负载,它会将任务调度到workers中并行执行。每个trino都运行在JVM实例中,并通过使用线程 进一步将任务并行化。
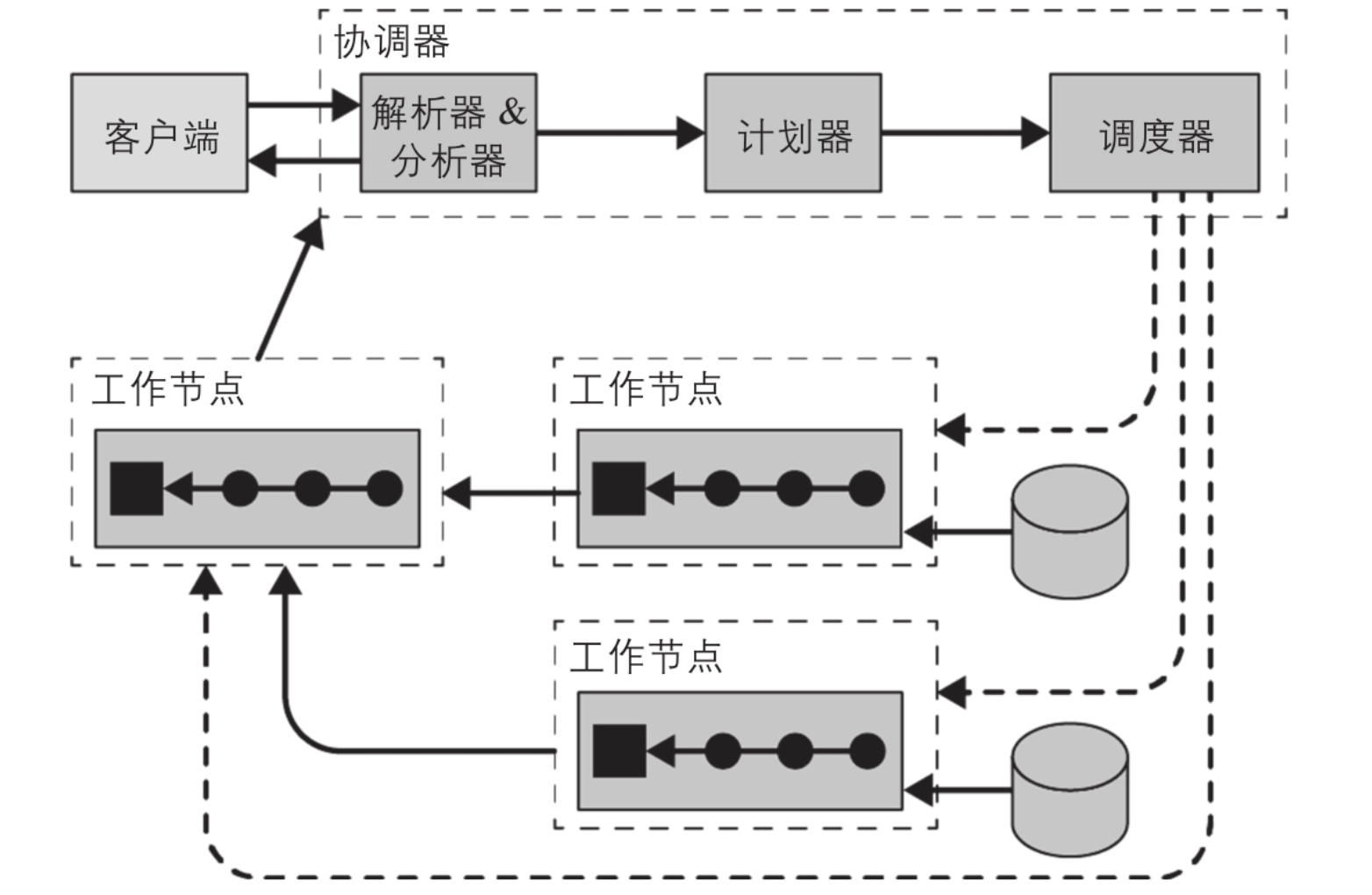
用户使用客户端工具(如JDBC驱动或Trino CLI)连接到集群中的协调器。之后,协调器就可以协调工作节点访问数据源。
协调器是一类处理用户查询请求并管理工作节点执行查询工作的服务器。工作节点是一类负责执行任务和处理数据的服务器。
协调器通常会运行一个节点发现服务,工作节点通过注册到该服务来加入集群。客户端、协调器和工作节点之间所有的通信和数据传输,都通过基于HTTP/HTTPS的REST服务交互(为什么不是rpc服务)。
通讯逻辑
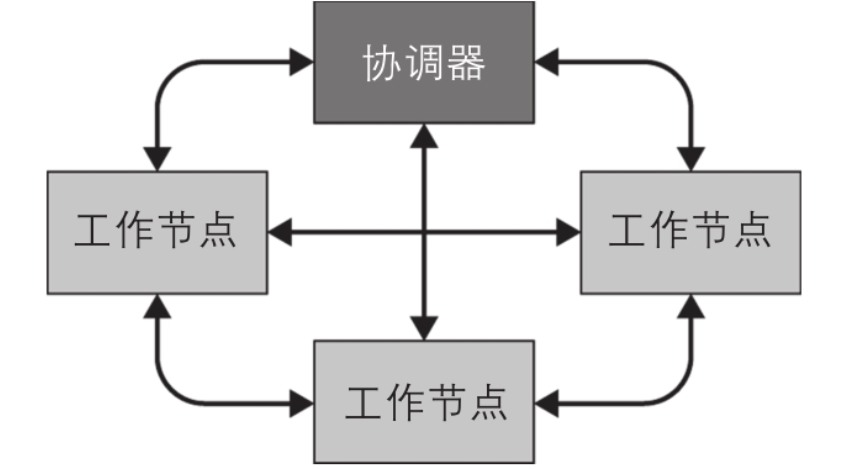
协调器与工作节点通信来分配任务、更新状态,并从工作节点获取顶层(?)的结果集来返回给用户。工作节点从运行在其他工作节点上的上游任务中获取数据,并从数据源获取结果集。
2. 协调器
Trino协调器负责接收用户SQL查询、解析查询语句、规划查询执行 并 管理工作节点。
接收用户查询
协调器是Trino集群的大脑,客户端程序都会连接它。
用户可以通过Trino CLI来与协调器交互,而应用程序可以使用JDBC或ODBC驱动、Python客户端或其他语言下可用的客户端库来交互。
管理工作节点
协调器跟踪每个工作节点的活动并协调查询的执行。协调器创建一个包含一系列Stage的逻辑模型。
sql执行的底层逻辑
- 在协调器接收到一条SQL语句后,它负责对该SQL解析、分析、创建执行计划,并在工作节点上调度执行查询任务。
- 查询语句被翻译成一系列互相连接的任务,这些任务被分发到集群的工作节点上运行。
- 在工作节点处理数据的同时,协调节点会获取执行结果并放入输出缓冲区,并对客户端暴露该缓冲区中的数据。在客户端读完输出缓冲区的数据后,协调节点会代表客户端从工作节点获取更多的数据(结果集是一部分一部分读)。而工作节点轮流与 数据源(?) 交互并从中读取数据。通过以上流程,在查询执行结束以前,客户端不断地请求数据,工作节点则不断地从数据源读取数据并提供给客户端。
协调器、工作节点和客户端基于HTTP协议进行通信。如图展示了客户端、协调器和工作节点之间的通信情况。
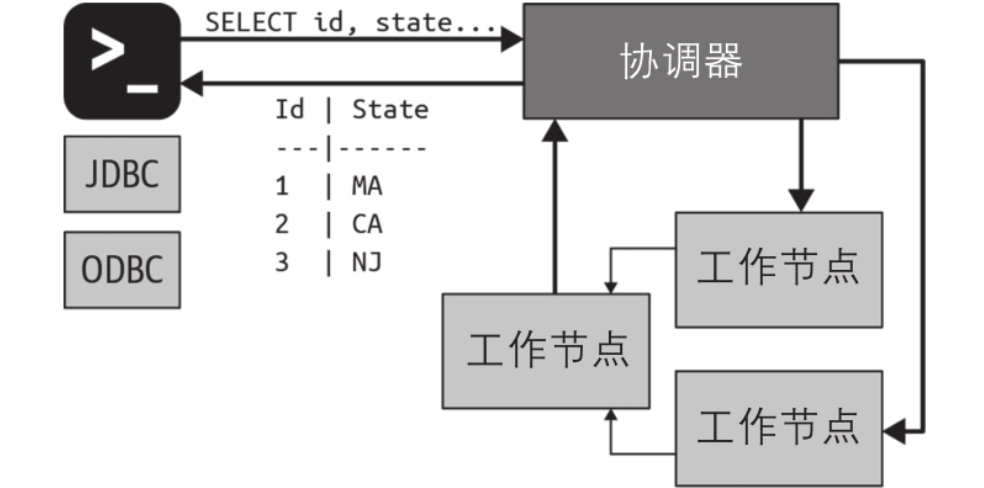
在开发和测试的场景下,单个Trino实例可以作为协调器和工作节点两种角色进行工作。
3. 发现服务
节点发现基本逻辑
Trino使用发现服务来发现集群中的所有节点。每个Trino实例在启动时都会注册到发现服务,并定期向该服务发送心跳信号。通过这种方式,协调器能够维护一个可用工作节点的最新列表,并用它来调度查询的执行。
如果工作节点向发现服务发送心跳消息失败,发现服务就会启动错误探测器(failure
detector),此后该工作节点不会再参与执行新的任务。
通过HTTP进行发现
发现服务运行在Trino协调器中,它与Trino协调器共享一个HTTP服务端,使用同一个端口。因此,工作节点配置的发现服务指向协调器的主机名和端口。
4. 工作节点
工作节点负责执行协调器分配的任务,包括从数据源获取数据并处理数据。
具体工作
工作节点使用连接器从数据源获取数据,工作节点之间也会交换中间数据,然后它发送最终结果数据给协调器。由协调器负责收集来自各个工作节点的结果并发送给客户端。
向协调器注册自己
在安装集群时,工作节点需要知道集群的发现服务所在的主机名或IP地址。工作节点启动时,会将自己注册到发现服务上,以便协调器可以向其分配任务来执行。
与其他节点通讯
工作节点使用HTTP协议与其他工作节点和协调器通信。
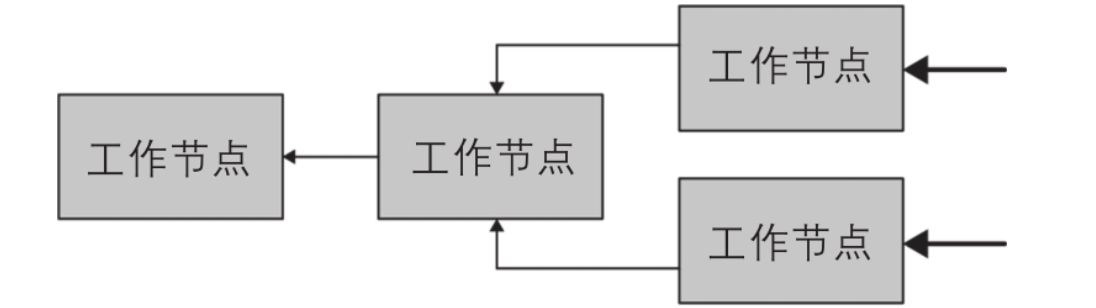
如图展示了多个工作节点如何从数据源检索并协作处理数据,直到其中 (只有一个?)一个工作节点 可以向协调器提供结果。
二. 基于连接器的架构
Trino存储与计算分离的核心是基于连接器的架构。连接器为Trino提供了连接任意数据源的接口。
trino连接器基础
每个连接器在底层数据源上提供了一个基于表的抽象。只要数据能用Trino支持的数据类型表示成表、列和行,Trino就可以创建连接器并让查询引擎使用这些数据进行查询处理。
通过在连接器中实现SPI,Trino就可以在内部使用标准操作来连接到任意数据源,并在该数据源上执行操作。连接器负责处理与特定数据源相关的细节。
每个连接器实现API的三个部分:
- 获取表、视图、schema的元数据的操作。
- 产生 数据分区(mysql也能并行读写?) 的逻辑单元的操作,用于Trino的并行读写。
- 数据源和接收器模块,需要与查询引擎使用的内存数据格式进行转换。
连接器让trino引擎忽略与数据源交互细节
在Trino中,支持从底层数据源读数据的连接器都需要实现listTables的SPI。因此,Trino可以使用相同的方法来让任何连接器检查schema中可用表的列表。
Trino不需要知道连接器实现的细节,一些连接器从information schema中获取数据,其他连接器需要查询元存储(metastore),还有一些通过请求数据源的API来获取信息。Trino引擎的核心会忽略这些细节,而由连接器来处理实现。
这种方式把查询引擎核心关心的内容与底层具体数据源提供的细节清晰地分开。这种方式看似简单,但很有意义,因为它在可读性、可扩展性和代码维护性上能提供很大的好处。
自定义连接器
Trino的SPI还让你能够创建自定义连接器,这在你需要连接到一个尚未支持连接器的数据源时非常有用。如果你最终要创建新连接器,强烈建议你了解下Trino的开源社区,寻求我们的帮助并将你的连接器贡献出来。如果组织内有独特的或专有的数据源,可能也需要自定义连接器。这就是Trino允许用户使用SQL查询任何数据源的原因——真正的SQL-on-Anything。
协调器与worker使用不同的spi接口
Trino SPI包含的不同接口,其中协调器使用的是元数据、数据统计和数据位置接口,工作节点使用的是数据流接口。
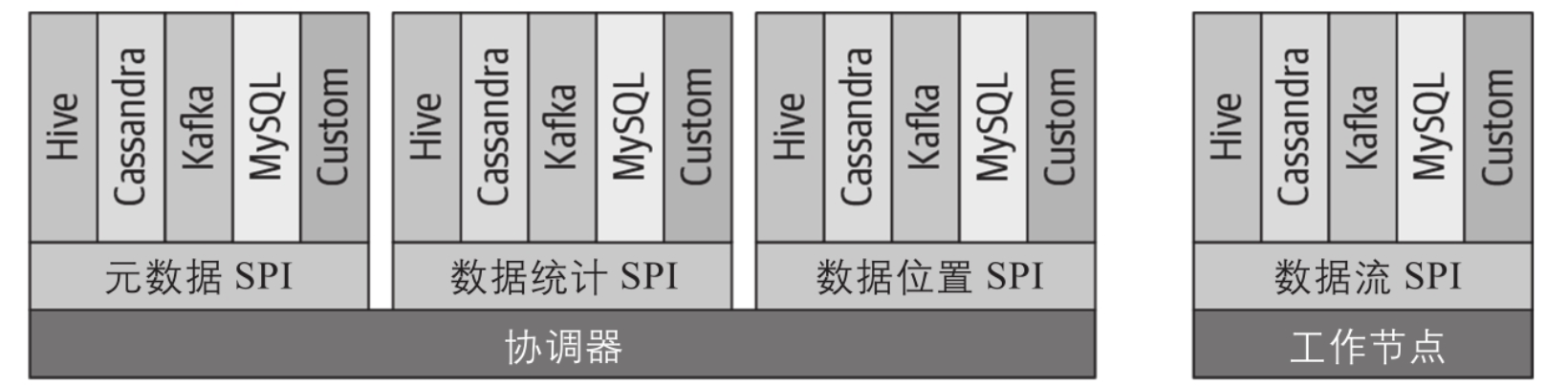
连接器配置与加载
连接器通过配置catalog文件来指定不同数据源特定的参数。Trino在启动时,扫描catalog目录以插件的形式加载连接器。
每个catalog都会配置一个连接器来访问特定的数据源。数据源在catalog中暴露出一个或多个schema(可以理解为数据库)。每个schema包含表,表提供数据行,每个数据行由一些具有不同数据类型的列组成。
插件思想
Trino的很多功能使用了基于插件的架构。除了连接器,插件也可以实现事件监听器、访问控制、函数和数据类型。
三. 查询执行模型
接下来将探讨Trino如何实际处理SQL查询语句。
理解执行模型是在Trino中进行查询性能调优必备的基础知识。
sql在trino架构的执行过程
终端用户通过CLI,使用ODBC或JDBC客户端,或使用其他客户端库来发送SQL语句到协调器。协调器之后调用工作节点从数据源获得数据、创建结果数据集并将结果返回给客户端。
1. 解析—>查询计划
首先,SQL语句以文本形式提交到协调器,协调器解析和分析SQL语句。之后,Trino创建一个由内部数据结构表示的执行计划,叫作查询计划,如下图。
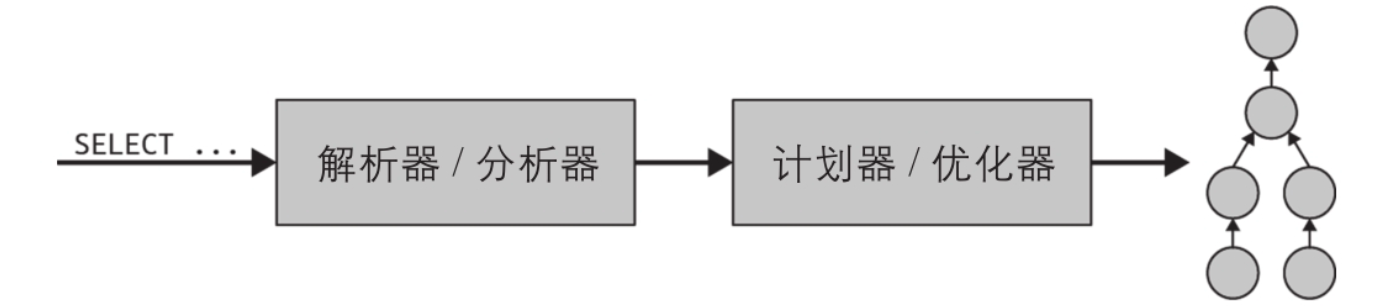
查询计划全面地表示了对每条SQL语句处理数据和返回结果所需进行的步骤。
使用SPI连接到数据源
查询计划生成过程使用元数据SPI和数据统计SPI来创建查询计划。也就是说,协调器会 使用SPI直接连接到数据源来收集有关表和其他元数据的信息。 这些信息用于对查询进行语义校验、表达式类型检查和安全检查。
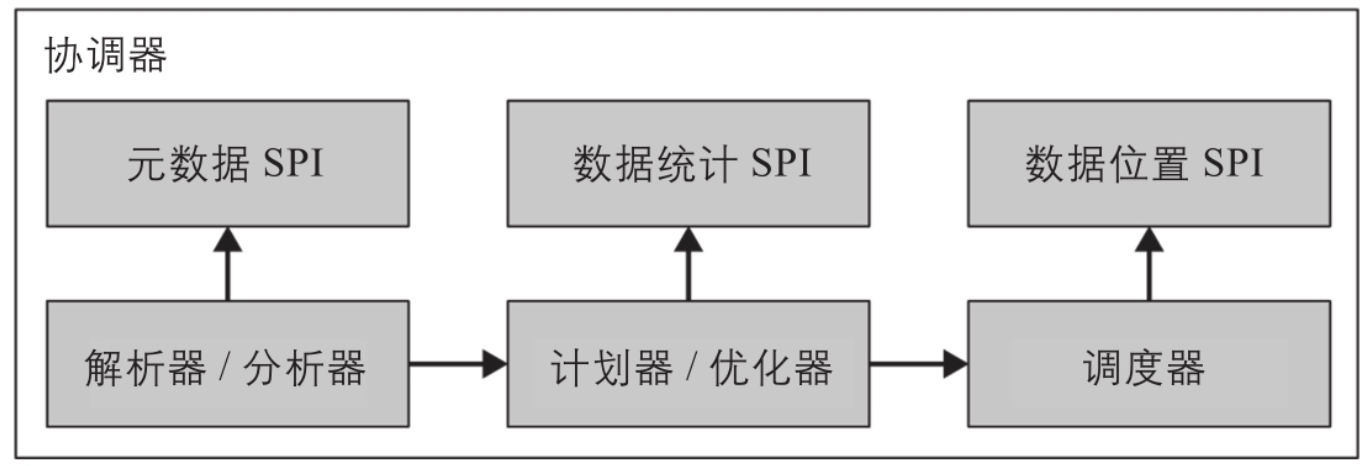
统计SPI\数据位置SPI
- 统计SPI用于获取行数和表大小的信息,从而在计划期间进行基于代价的查询优化。
- 数据位置SPI在创建分布式查询计划时会被用来生成表内容的逻辑切片。切片(具体切片的逻辑)是任务分配和并行的最小单位。
2. 查询计划 —> 分布式查询计划
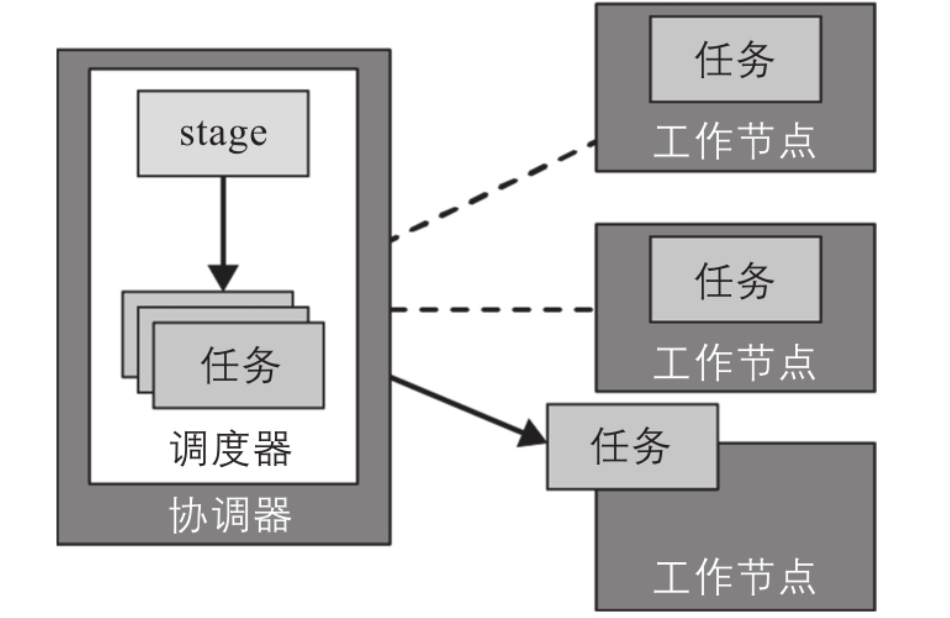
分布式查询计划是查询计划的一个扩展,它包含一个或多个阶段(stage)。查询计划被切分成多个计划片段(plan fragment)。stage是运行时的plan fragment,包含计划片段所描述的所有任务。?
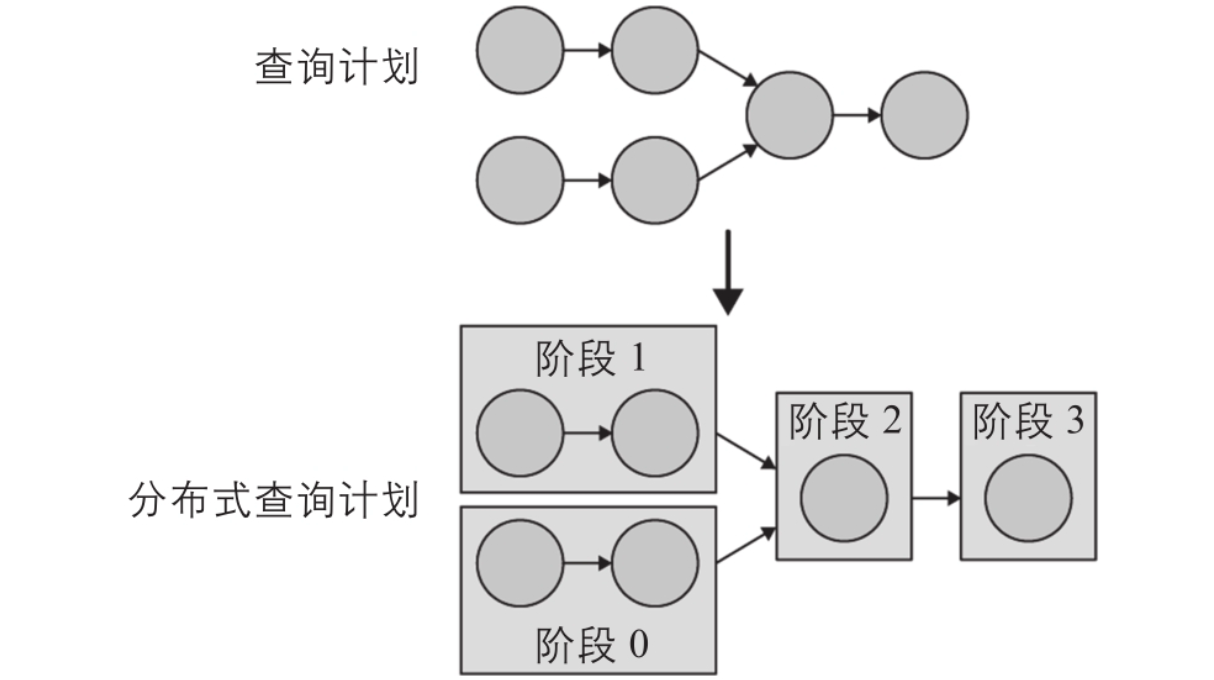
协调器将查询计划切分成stage,分配给集群中的多个工作节点并行处理,从而加快整体查询的执行速度。(一个job中所有的)stage会被创建为成一棵stage依赖树。
stage的数量依赖于查询的复杂度。例如,查询的表、返回的列、JOIN语句、WHERE条件、GROUP BY操作和其他SQL语句都会影响stage的数量。
分布式执行
通过分布式执行计划,协调器在工作节点上进一步计划和调度任务。一个stage通常包含一个或多个任务,每个任务则负责处理一小部分数据。 如下图:协调器将一个stage的任务分配给集群中的工作节点。
3. 运行阶段
3.1. 基础概念
切片:并行单元
一个任务处理数据的单位是切片。切片代表一个工作节点可以提取并处理的一段底层数据,它是并行和任务分配的基本单元。
并发信息:形成切片列表的元数据
连接器执行的特定数据操作依赖于底层的数据源。例如,Hive连接器用带有文件路径、读取偏移量和读取长度的文件信息来描述切片信息,这些信息标明了该文件需要处理的区域。
page 与 exchange算子
page
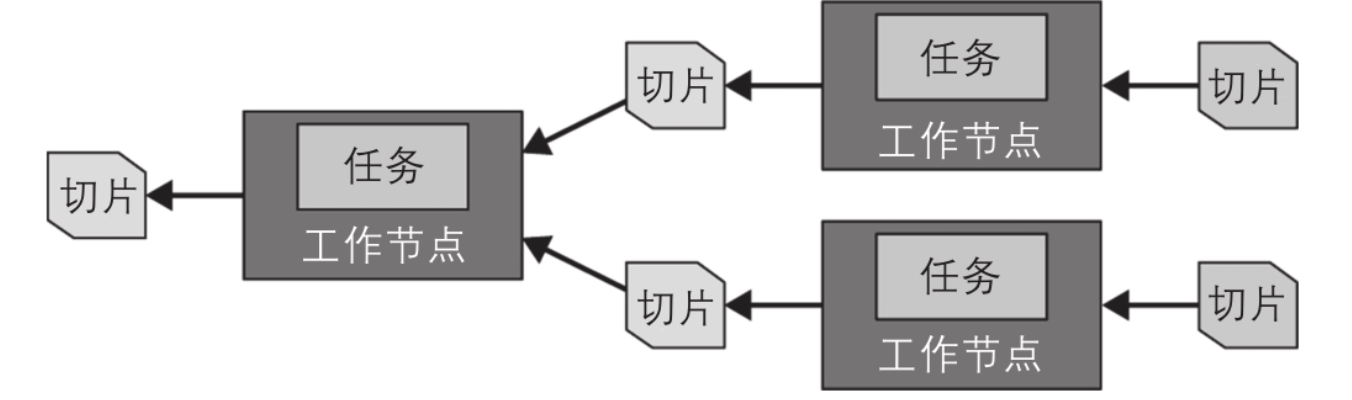
源stage的任务以页(page)的形式生产数据。其中,page是以列格式存储的一系列行,它们被传输到其他中间下游stage。exchange算子从上游stage的任务中读取数据,从而在不同(节点)stage之间传输page。
page的传递
在连接器的帮助下,源任务使用数据源SPI从底层数据源获取数据。Trino以page的形式表示这些数据,并在查询引擎中传送数据。算子根据自身的语义处理(接收到的page)和 产生新的page。
例如,filter算子会丢弃过滤掉的行,projection算子生成(起源于原始列的)新列的page等。
pipeline
包含在一个任务里的一连串算子(operator)叫作流水线(pipeline)。一条流水线中的最后一个算子通常会将它输出的page 放置在任务的输出缓冲区中。下游任务的exchange算子会从上游任务的输出缓冲区中消费page。
如下图,所有这些操作都在不同的工作节点上并行执行。
切片的driver
在任务被创建之后,它会为每个切片初始化一个driver。每个driver都是包含多个算子的流水线的一个实例,并且负责处理切片中的数据。
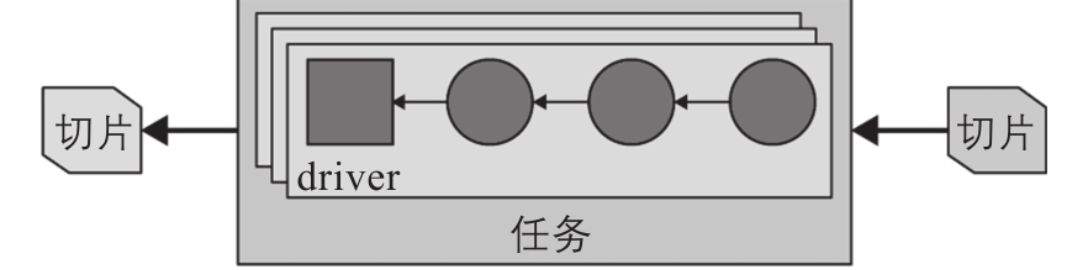
如上图,根据Trino的配置和环境,一个任务可以使用一个或多个driver。一旦所有driver都执行完并且数据被传送到下一个切片,driver和任务的工作就结束了,之后(任务还没结束?)会被销毁。
Operator
常见的算子包括table scan(表扫描)、filter(过滤)、join(连接)和aggregate(聚合)。一系列算子组成一条pipline。例如,你可以拥有这样一条pipline,它先扫描并读入数据,再过滤数据,最后在数据上执行局部聚合。
3.2. running 概述
要处理一条查询,协调器首先根据来自连接器的元数据创建切片列表(ing源码逻辑)。使用该切片列表,协调器开始在工作节点上调度任务,以获取切片中的数据。在查询执行期间,协调器跟踪所有可被处理的切片,以及在工作节点上运行并处理切片的任务的位置。
随着任务结束处理,它会产生更多供下游处理的切片。协调器会不断地调度任务来处理这些新的切片,直到没有需要处理的切片为止。一旦工作节点处理完所有切片,全部数据就都可用,协调器用这些数据产生结果,客户端可以获取该结果。


)
)












】【Python】【四数之和】【哈希表】【中等】)

)
