0x13 链表与邻接表
数组是一种支持随机访问,但不支持在任意位置插入和删除元素的数据结构。与之相对应,链表支持在任意位置插入或删除元素,但只能按顺序依次访问其中元素。我们可以使用一个struct来表示链表的节点,其中可以存储任意数据。另外用prev和next两个指针指向前后两个相邻的节点,构成一个常见的双向链表。为了避免在左右两端或者空链表中访问越界,我们通常建立额外的两个节点head和tail代表链表头尾,把实际数据节点存储在head和tail之间,来减少链表边界处的判断,减低编程复杂度。
struct node{int value;node *prev,*next;
};
node *head,*tail;void initialize()
{head=new node();tail=new node();head->next=tail;tail->prev=head;
}
struct node{int val;int pre,next;
}nd[SIZE];
int head,tail,tot;void initialize()
{tot=2;head=1;tail=2;nd[head].next=tail;nd[tail].pre=head;
}
1.邻接表
在与链表相关的数据结构中,邻接表是相当重要的一种。它是图与树一般化存储方式,还能用于实现我们将在下一节中介绍的开散列Hash表。实际上,邻接表可以看成“带有索引数组的多个数据链表”构成的结构集合。在这样的结构中存储的数据被分为若干类,每一类的数据构成一个链表。每一类还有一个代表元素,称为该类对应链表的“表头”。所有的表头构成一个表头数组,作为一个可以随机访问的索引,从而可以通过表头数组定位到某一类数据对应的链表。
一个有n个点m条边的有向图,可以如此存储:
int tot;//边的总数
int ver[SIZE],edge[SIZE],next[SIZE],head[SIZE];
//分别记录每个边的终点,每个边的权值,把此边加入链表后的下一个边的序号,头结点指向的第一个边的序号//加入有向边(x,y),权值为z
void add(int x,int y,int z)
{ver[++tot]=y,edge[tot]=z;next[tot]=head[x],head[x]=tot;
}//访问从x出发的所有边
for(int i=head[x];i;i=next[i])
{int y=ver[i],z=edge[i];
}
例如插入6条边,顺序为(1,2),(2,3),(2,5),(3,5),(5,4),(5,1)。
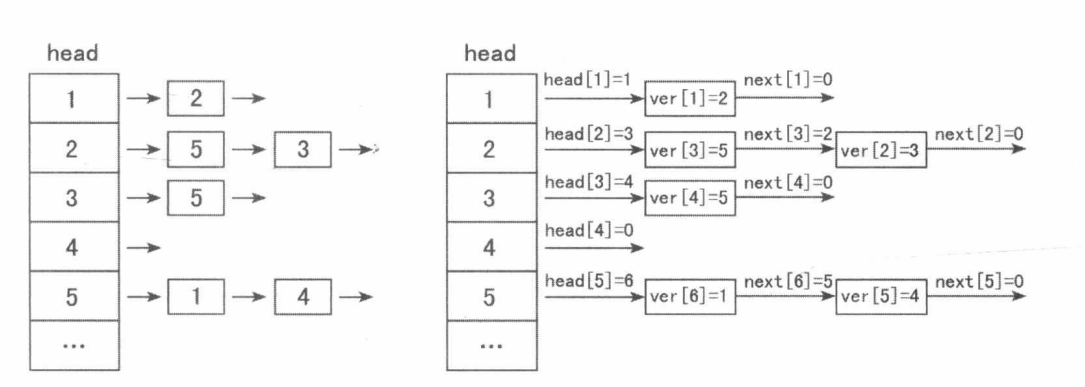
对于无向图,我们可以把每条无向边看做两条有向边即可。我们可以利用第0x01学到的“成对变换”的位运算性质,程序开始时令tot=1,这样无向边便存储在ver和edge数组下标“2和3”,“4和5”…的位置上。通过对下标异或的操作,就可以直接定位到反向边。如果ver[i]是第i条边的终点,那么ver[i xor 1]则是第i条边的起点。



![[LGR-168-Div4]题解](http://pic.xiahunao.cn/[LGR-168-Div4]题解)



)






 神码ai)




+Tomcat实现负载均衡、动静分离)