mybaits提供一级缓存,和二级缓存
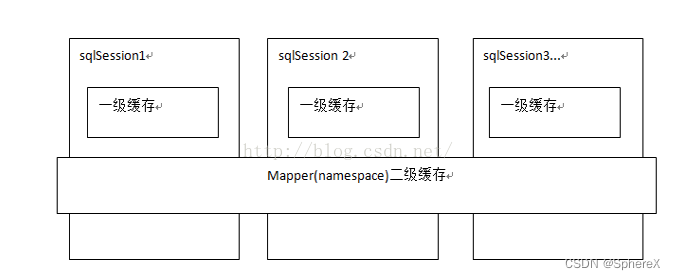
一级缓存(默认开启)

一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存。
一级缓存只是相对于同一个SqlSession而言。所以在参数和SQL完全一样的情况下,我们使用同一个SqlSession对象调用一个Mapper方法,往往只执行一次SQL,因为使用SelSession第一次查询后,MyBatis会将其放在缓存中,以后再查询的时候,如果没有声明需要刷新,并且缓存没有超时的情况下,SqlSession都会取出当前缓存的数据,而不会再次发送SQL到数据库。

一级缓存的生命周期有多长?
a、MyBatis在开启一个数据库会话时,会 创建一个新的SqlSession对象,SqlSession对象中会有一个新的Executor对象。Executor对象中持有一个新的PerpetualCache对象;当会话结束时,SqlSession对象及其内部的Executor对象还有PerpetualCache对象也一并释放掉。b、如果SqlSession调用了close()方法,会释放掉一级缓存PerpetualCache对象,一级缓存将不可用。
c、如果SqlSession调用了clearCache(),会清空PerpetualCache对象中的数据,但是该对象仍可使用。
d、SqlSession中执行了任何一个update操作(update()、delete()、insert()) ,都会清空PerpetualCache对象的数据,但是该对象可以继续使用
怎么判断某两次查询是完全相同的查询?
mybatis认为,对于两次查询,如果以下条件都完全一样,那么就认为它们是完全相同的两次查询。2.1 传入的statementId
2.2 查询时要求的结果集中的结果范围
2.3. 这次查询所产生的最终要传递给JDBC java.sql.Preparedstatement的Sql语句字符串(boundSql.getSql() )
2.4 传递给java.sql.Statement要设置的参数值
@Testpublic void testCache1() throws Exception{SqlSessionsqlSession = sqlSessionFactory.openSession();//创建代理对象UserMapperuserMapper = sqlSession.getMapper(UserMapper.class);//下边查询使用一个SqlSession//第一次发起请求,查询id为1的用户Useruser1 = userMapper.findUserById(1);System.out.println(user1);// 如果sqlSession去执行commit操作(执行插入、更新、删除),清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。//更新user1的信息user1.setUsername("测试用户22");userMapper.updateUser(user1);//执行commit操作去清空缓存sqlSession.commit();//第二次发起请求,查询id为1的用户Useruser2 = userMapper.findUserById(1);System.out.println(user2);sqlSession.close();}mybatis和spring进行整合开发,事务控制在service中。
一个service方法中包括很多mapper方法调用。
如果是执行两次service调用查询相同的用户信息,不走一级缓存,因为Service方法结束,sqlSession就关闭,一级缓存就清空。
service{//开始执行时,开启事务,创建SqlSession对象//第一次调用mapper的方法findUserById(1)//第二次调用mapper的方法findUserById(1),从一级缓存中取数据//aop控制 只要方法结束,sqlSession关闭 sqlsession关闭后就销毁数据结构,清空缓存Service结束sqlsession关闭}二级缓存
MyBatis的二级缓存是Application级别的缓存
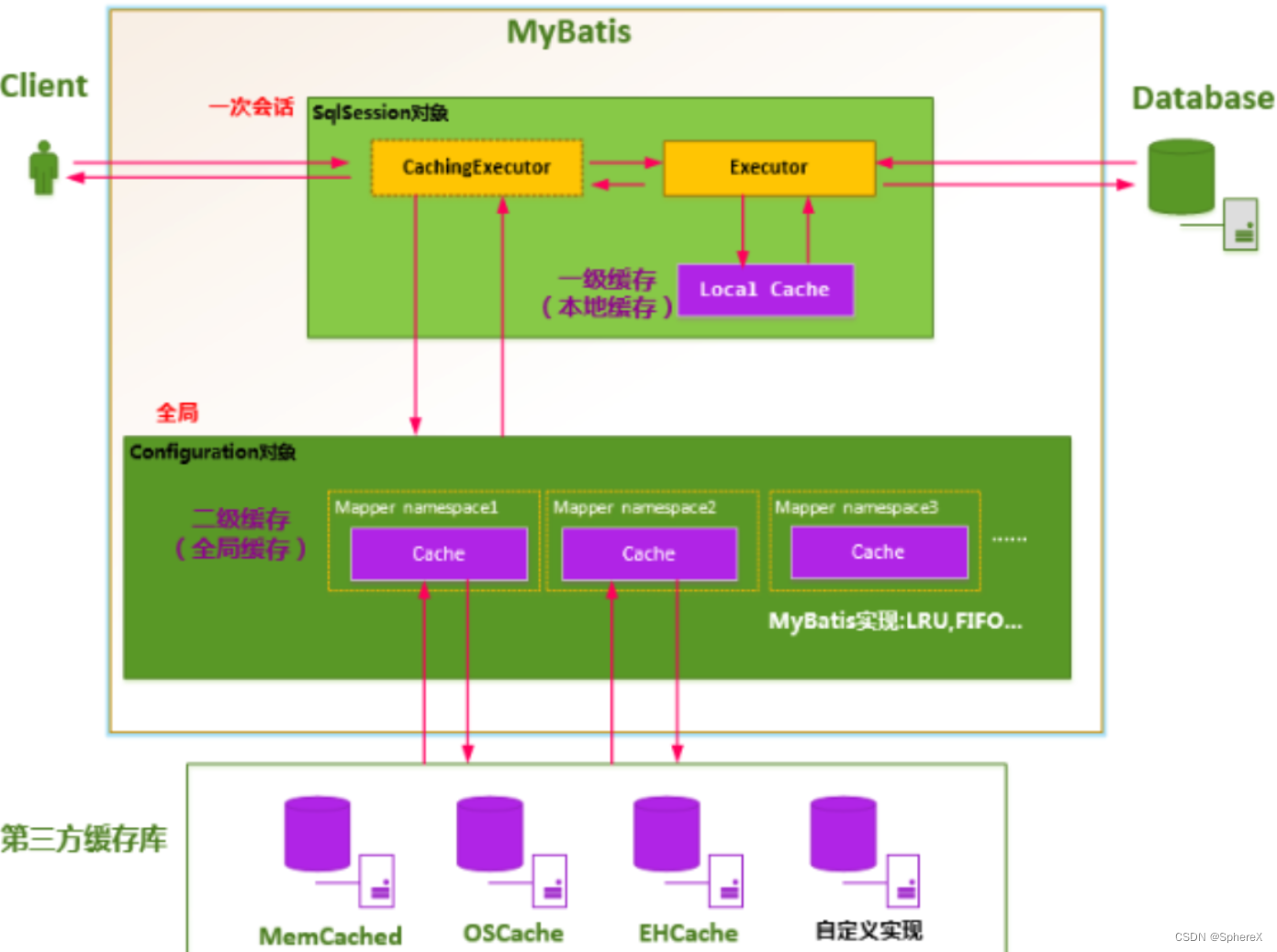
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession去操作数据库得到数据会存在二级缓存区域,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。
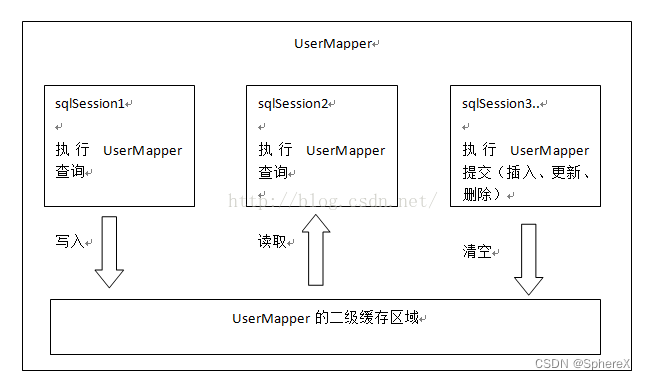
二级缓存与一级缓存区别,二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域。数据类型仍然为HashMap
UserMapper有一个二级缓存区域(按namespace分,如果namespace相同则使用同一个相同的二级缓存区),其它mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中。
sqlSessionFactory层面上的二级缓存默认是不开启的,二级缓存的开启需要进行配置,实现二级缓存的时候,MyBatis要求返回的POJO必须是可序列化的。 也就是要求实现Serializable接口,配置方法很简单,只需要在映射XML文件配置就可以开启缓存了<cache/>,如果我们配置了二级缓存就意味着:
映射语句文件中的所有select语句将会被缓存。
映射语句文件中的所欲insert、update和delete语句会刷新缓存。
缓存会使用默认的Least Recently Used(LRU,最近最少使用的)算法来收回。
根据时间表,比如No Flush Interval,(CNFI没有刷新间隔),缓存不会以任何时间顺序来刷新。
缓存会存储列表集合或对象(无论查询方法返回什么)的1024个引用
缓存会被视为是read/write(可读/可写)的缓存,意味着对象检索不是共享的,而且可以安全的被调用者修改,不干扰其他调用者或线程所做的潜在修改。
开启二级缓存
mybaits的二级缓存是mapper范围级别,除了在SqlMapConfig.xml设置二级缓存的总开关,还要在具体的mapper.xml中开启二级缓存。
在核心配置文件SqlMapConfig.xml中加入
<setting name="cacheEnabled"value="true"/><!-- 全局配置参数,需要时再设置 --><settings><!-- 开启二级缓存 默认值为true --><setting name="cacheEnabled" value="true"/></settings>在UserMapper.xml中开启二缓存,UserMapper.xml下的sql执行完成会存储到它的缓存区域(HashMap)
<mapper namespace="cn.hpu.mybatis.mapper.UserMapper"><!-- 开启本mapper namespace下的二级缓存 --><cache></cache>调用pojo类实现序列化接口
public class Userimplements Serializable {//Serializable实现序列化,为了将来反序列化二级缓存需要查询结果映射的pojo对象实现java.io.Serializable接口实现序列化和反序列化操作,注意如果存在父类、成员pojo都需要实现序列化接口。
pojo类实现序列化接口是为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定在内存有可能是硬盘或者远程服务器。
// 二级缓存测试@Testpublic void testCache2() throws Exception {SqlSessionsqlSession1 = sqlSessionFactory.openSession();SqlSessionsqlSession2 = sqlSessionFactory.openSession();SqlSessionsqlSession3 = sqlSessionFactory.openSession();// 创建代理对象UserMapperuserMapper1 = sqlSession1.getMapper(UserMapper.class);// 第一次发起请求,查询id为1的用户Useruser1 = userMapper1.findUserById(1);System.out.println(user1);//这里执行关闭操作,将sqlsession中的数据写到二级缓存区域sqlSession1.close();//使用sqlSession3执行commit()操作UserMapperuserMapper3 = sqlSession3.getMapper(UserMapper.class);Useruser = userMapper3.findUserById(1);user.setUsername("张明明");userMapper3.updateUser(user);//执行提交,清空UserMapper下边的二级缓存sqlSession3.commit();sqlSession3.close();UserMapperuserMapper2 = sqlSession2.getMapper(UserMapper.class);// 第二次发起请求,查询id为1的用户Useruser2 = userMapper2.findUserById(1);System.out.println(user2);sqlSession2.close();}useCache配置禁用二级缓存
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。<selectid="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
总结:针对每次查询都需要最新的数据sql,要设置成useCache=false,禁用二级缓存。
mybatis刷新缓存(就是清空缓存)
在mapper的同一个namespace中,如果有其它insert、update、delete操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读。设置statement配置中的flushCache="true" 属性,默认情况下为true即刷新缓存,如果改成false则不会刷新。使用缓存时如果手动修改数据库表中的查询数据会出现脏读。
如下:
<insertid="insertUser" parameterType="cn.itcast.mybatis.po.User" flushCache="true">
总结:一般下执行完commit操作都需要刷新缓存,flushCache=true表示刷新缓存默认情况下为true,我们不用去设置它,这样可以避免数据库脏读。
Mybatis Cache参数
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:1. LRU – 最近最少使用的:移除最长时间不被使用的对象。
2. FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
3. SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
4. WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
mybatis整合ehcache
ehcache是一个分布式缓存框架。
EhCache 是一个纯Java的进程内缓存框架,是一种广泛使用的开源Java分布式缓存,具有快速、精干等特点,是Hibernate中默认的CacheProvider。
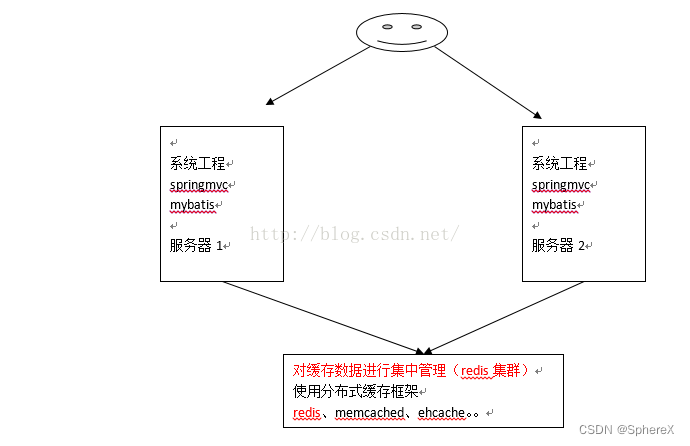
不使用分布缓存,缓存的数据在各各服务单独存储,不方便系统开发。所以要使用分布式缓存对缓存数据进行集中管理。
mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合。
整合方法(掌握无论整合谁,首先想到改type接口)
mybatis提供了一个cache接口,如果要实现自己的缓存逻辑,实现cache接口开发即可。
mybatis和ehcache整合,mybatis和ehcache整合包中提供了一个cache接口的实现类。
加入ehcache包
![]()
整合ehcache
配置mapper中cache中的type为ehcache对cache接口的实现类型。
<mapper namespace="cn.hpu.mybatis.mapper.UserMapper"><!-- 开启本mapper namespace下的二级缓存type:指定cache接口实现类,mybatis默认使用PerpetualCache要和eache整合,需要配置type为ehcahe实现cache接口的类型--><cache type="org.mybatis.caches.ehcache.EhcacheCache"></cache>可以根据需求调整缓存参数:
<cache type="org.mybatis.caches.ehcache.EhcacheCache"><property name="timeToIdleSeconds" value="3600"/><property name="timeToLiveSeconds" value="3600"/><!-- 同ehcache参数maxElementsInMemory--><property name="maxEntriesLocalHeap"value="1000"/><!-- 同ehcache参数maxElementsOnDisk --><property name="maxEntriesLocalDisk" value="10000000"/><property name="memoryStoreEvictionPolicy" value="LRU"/></cache>加入ehcache的配置文件
在classpath下配置ehcache.xml
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="../config/ehcache.xsd"><diskStore path="F:\develop\ehcache"/><defaultCachemaxElementsInMemory="1000"maxElementsOnDisk="10000000"eternal="false"overflowToDisk="false"timeToIdleSeconds="120"timeToLiveSeconds="120"diskExpiryThreadIntervalSeconds="120"memoryStoreEvictionPolicy="LRU"></defaultCache></ehcache>属性说明:
diskStore:指定数据在磁盘中的存储位置。
defaultCache:当借助CacheManager.add("demoCache")创建Cache时,EhCache便会采用<defalutCache/>指定的的管理策略
以下属性是必须的:
maxElementsInMemory - 在内存中缓存的element的最大数目
maxElementsOnDisk - 在磁盘上缓存的element的最大数目,若是0表示无穷大
eternal - 设定缓存的elements是否永远不过期。如果为true,则缓存的数据始终有效,如果为false那么还要根据timeToIdleSeconds,timeToLiveSeconds判断
overflowToDisk- 设定当内存缓存溢出的时候是否将过期的element缓存到磁盘上
以下属性是可选的:
timeToIdleSeconds - 当缓存在EhCache中的数据前后两次访问的时间超过timeToIdleSeconds的属性取值时,这些数据便会删除,默认值是0,也就是可闲置时间无穷大
timeToLiveSeconds - 缓存element的有效生命期,默认是0.,也就是element存活时间无穷大
diskSpoolBufferSizeMB 这个参数设置DiskStore(磁盘缓存)的缓存区大小.默认是30MB.每个Cache都应该有自己的一个缓冲区.
diskPersistent在VM重启的时候是否启用磁盘保存EhCache中的数据,默认是false。
diskExpiryThreadIntervalSeconds - 磁盘缓存的清理线程运行间隔,默认是120秒。每个120s,相应的线程会进行一次EhCache中数据的清理工作
memoryStoreEvictionPolicy - 当内存缓存达到最大,有新的element加入的时候,移除缓存中element的策略。默认是LRU(最近最少使用),可选的有LFU(最不常使用)和FIFO(先进先出)
集成SpringBoot缓存相关问题
1.一级缓存只有在开启了数据库事物【@EnableTransactionManagement】并且处于一个被事物标注的方法下【直接或间接】才会生效。
2.禁用一级缓存:mybatis没有提供一级缓存的启用、禁用开关,但在Mapper文件对应的语句中增加flushCache="true"可以达到实际禁用一级缓存的效果,一般同时还会加上useCache="false",以便关闭二级缓存;下面讨论使用springboot配置的方式控制一级缓存。
MyBatis 一级缓存(MyBaits 称其为 Local Cache)无法关闭,但是有两种级别可选:
A.session
在同一个 sqlSession 内,对同样的查询将不再查询数据库,直接从缓存中获取。
mybatis:configuration:cache-enabled: false #禁用二级缓存local-cache-scope: session #一级缓存指定为session级别
B.statement
每次查询结束都会清掉一级缓存,实际效果就是禁用了一级缓存;
mybatis:configuration:cache-enabled: false #禁用二级缓存local-cache-scope: statement #一级缓存指定为statement级别
@Transactional(propagation = Propagation.REQUIRED) public List<Users> getUsers() {List<Users> usersList = usersMapper.selectByExample(new UsersExample()); #1usersList = usersMapper.selectByExample(new UsersExample()); #2return usersList; }A.一级缓存级别设置为session
在代码中1处,通过日志观察,打印出sql语句,未走缓存【此时缓存数据还不存在】;
在执行2处语句之前,通过数据库工具修改数据库记录并提交,继续执行程序后,通过日志观察,未打印出sql语句,获取的数据未体现出通过工具修改数据的变化,说明使用的是缓存中的数据;
B.一级缓存级别设置为statement
在代码中1处,通过日志观察,打印出sql语句,未走缓存【此时缓存数据还不存在】;
在执行2处语句之前,通过数据库工具修改数据库记录并提交,继续执行程序后,通过日志观察,打印出sql语句,且获取的数据也体现出通过工具修改数据的变化,说明未使用缓存中的数据;
结论:通过将一级缓存级别设置为statement,可以达到禁用一级缓存的效果。
@Transactional(propagation = Propagation.REQUIRED) public List<Users> getUsers() {List<Users> usersList = usersMapper.selectByExample(new UsersExample()); #1usersList = usersServer.getUsersList();return usersList; }#下面的代码属于usersServer
@Transactional(propagation = Propagation.NESTED) #3 public List<Users> getUsersList() {return usersMapper.selectByExample(new UsersExample()); #2 }观察到的结果与上面的一致。
结论:同上,同时证明了嵌套事物NESTED本质上与上层事物处于一个相同的事物中。
将代码3处事物配置调整成REQUIRES_NEW,重做之前的实验;观察到的结果:在一级缓存级别为session与statement时,现象一致,带执行代码2处,均打印SQL语句,并且体现出了手动修改数据库记录的效果;
结论:REQUIRES_NEW确实重新起了一个新的事物,与上层事物没有关系。
结论:
1.将mybatis一级缓存级别设置为statement可以事实上达到禁用一级缓存的效果;
2.启用mybatis一级缓存,将级别设置为session【或不做任何设置,mybaits默认就是这个级别】

)

二十二 使用opencv进行人脸、眼睛、嘴的检测)
字节码文件的组成)
 算法)

)






配置文件详细)




