前言
本文并不局限于ptmalloc的原理,而是从linux的内存虚拟化和系统调用原理出发,结合各种语言实现,讲明内存分配方面的trade off,力图事无巨细,追根究底。本文内容包括但不限于:NIO原理、0拷贝原理、内存虚拟化、GC和内存分配、PCB结构、mmap原理和场景、JVM内存分配细节、缺页异常中断、PTE、物理页分配、驻留内存、malloc分配原理、ptmalloc的设计和缺陷、mimalloc设计。
什么是glibc和ptmalloc
glibc提供了一组在所有Linux发行版上都可用的标准化函数。包括ISO C standard library、POSIX实现、内存管理等。其中的内存分配函数ptmalloc2被包括C++、JVM(Native Heap)、Python在内广泛使用。
ptmalloc2遵循malloc函数的惯例:小内存使用brk分配,大内存使用mmap分配。
同时,ptmalloc2也因为它的内存碎片、内存泄漏和线程间锁争用问题而广受诟病,因此谷歌推出了tcmalloc,facebook推出jemalloc,微软推出mimalloc来取代它。一般在生产环境也建议根据不同的情况选用不同的内存分配库替换掉glibc的实现。
思考题1:ptmalloc2的问题会对哪些语言造成影响?为什么?
答案:
对C++、JVM(Native Heap)、Python都有影响。但是对JVM影响较小。
要理解这个问题首先要理解JVM的内存分配。
首先我们看JVM的内存划分:
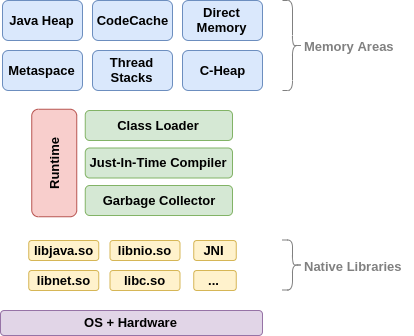
主流GC的中,GC要么是Partial GC要么是Full GC:
- Partial GC:并不收集整个GC堆的模式
- Young GC:只收集young gen的GC
- Old GC:只收集old gen的GC。只有CMS的concurrent collection是这个模式
- Mixed GC:收集整个young gen以及部分old gen的GC。只有G1有这个模式
- Full GC:收集整个堆,包括young gen、old gen、perm gen(如果存在的话)等所有部分的模式。
所以内存回收的粒度是比较大的,对于mimalloc并非像C++和Python那么敏感。这个影响跟G1的-XX:MaxGCPAuseMillS参数也有关系。如果这个jvm参数设置的太低的话,就会导致每次G1 回收的内存很少,受到的底层回收算法影响更大。
更多的关于GC的细节,可以参考下面的简单聊聊GC场景下的内存释放。
那么什么时候知道glibc对JVM产生了影响呢?通过RSS(进程驻留内存)来看:

内存增长模型
虚拟地址空间由地址总线宽度决定:

64位linux进程虚拟地址空间的内存增长模型如下所示:

思考题2: NIO bytebuffer分配的内存属于堆内内存还是堆外内存?属于user space还是kernal space?
答案:既可能是堆内内存也可能是堆外内存,既可能属于user space也可能属于kernal space。

虚拟地址空间、brk和mmap
分配小于128k内存时虚拟地址空间的情况

分配内存大于128k时的情况:

brk分配的内存需要等到高地址内存释放以后才能释放(例如,在B释放之前,A是不可能释放的,这就是内存碎片产生的原因),而mmap分配的内存可以单独释放。
mmap函数的作用就是分配/映射一段虚拟地址空间:

这两种方式分配的都是虚拟内存,没有分配物理内存。在第一次访问已分配的虚拟地址空间的时候,发生缺页中断,操作系统负责分配物理内存,然后建立虚拟内存和物理内存之间的映射关系(写时复制)。
mmap能解决那些性能问题?
- 用户态到内核态的过程中,内存拷贝问题
- 内核态把脏数据写回到块设备的过程中,内存拷贝的问题
- 4K对齐问题
- 零拷贝(实际上是通过映射)问题
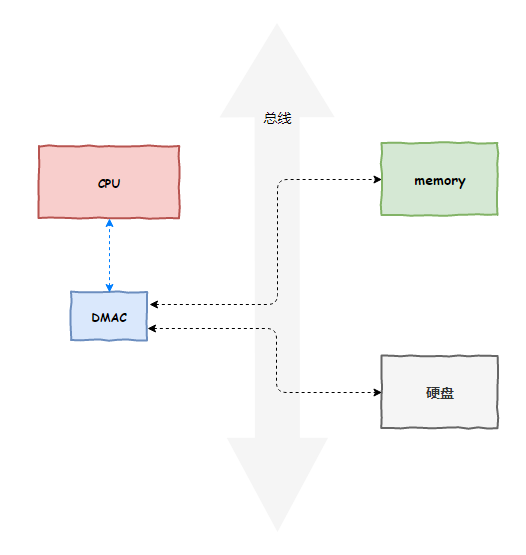
通过下面的流程图可以很直观的明白mmap的作用:
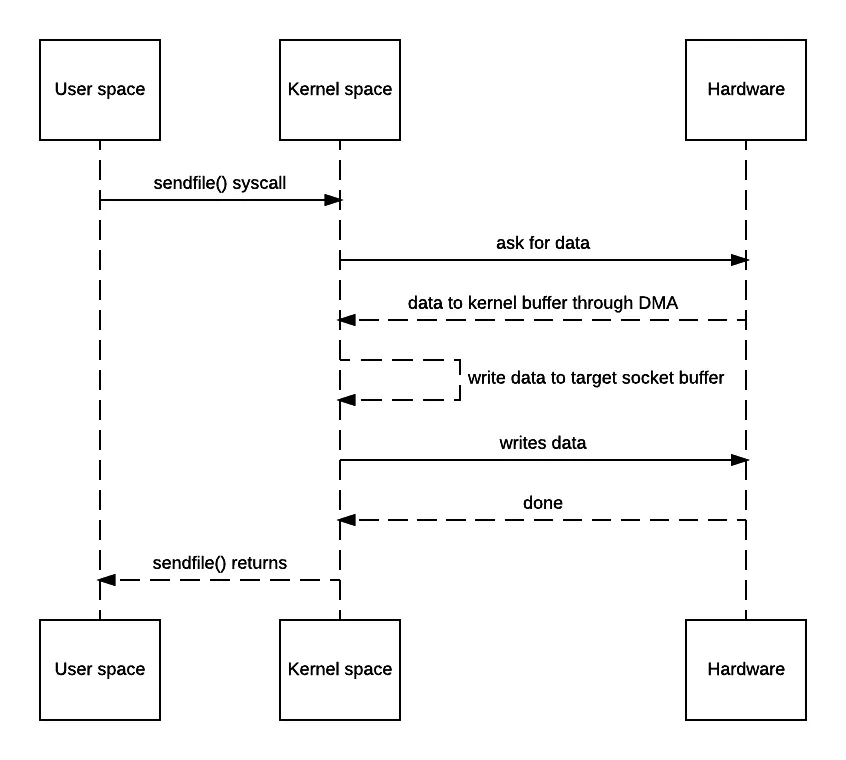

思考题:
- swap space大小影响虚拟空间地址大小吗?
- malloc调用的mmap会设置flags为MAP_ANONYMOUS吗?也就是说malloc会映射到文件吗?
- mmap什么时候回写到文件?
- mmap在文件映射时导致的脏页在回写之后怎么再次标记为脏页触发回写?为什么跟write不一样?
- mmap在文件映射时物理内存+swap spcae不够怎么办?
- mmap怎么保证文件页缓存一致性?
答案:
- 不会
- 不会

dirty pages的物理页可以通过address_space 中的Radix树快速找到并且被pdflush回写。

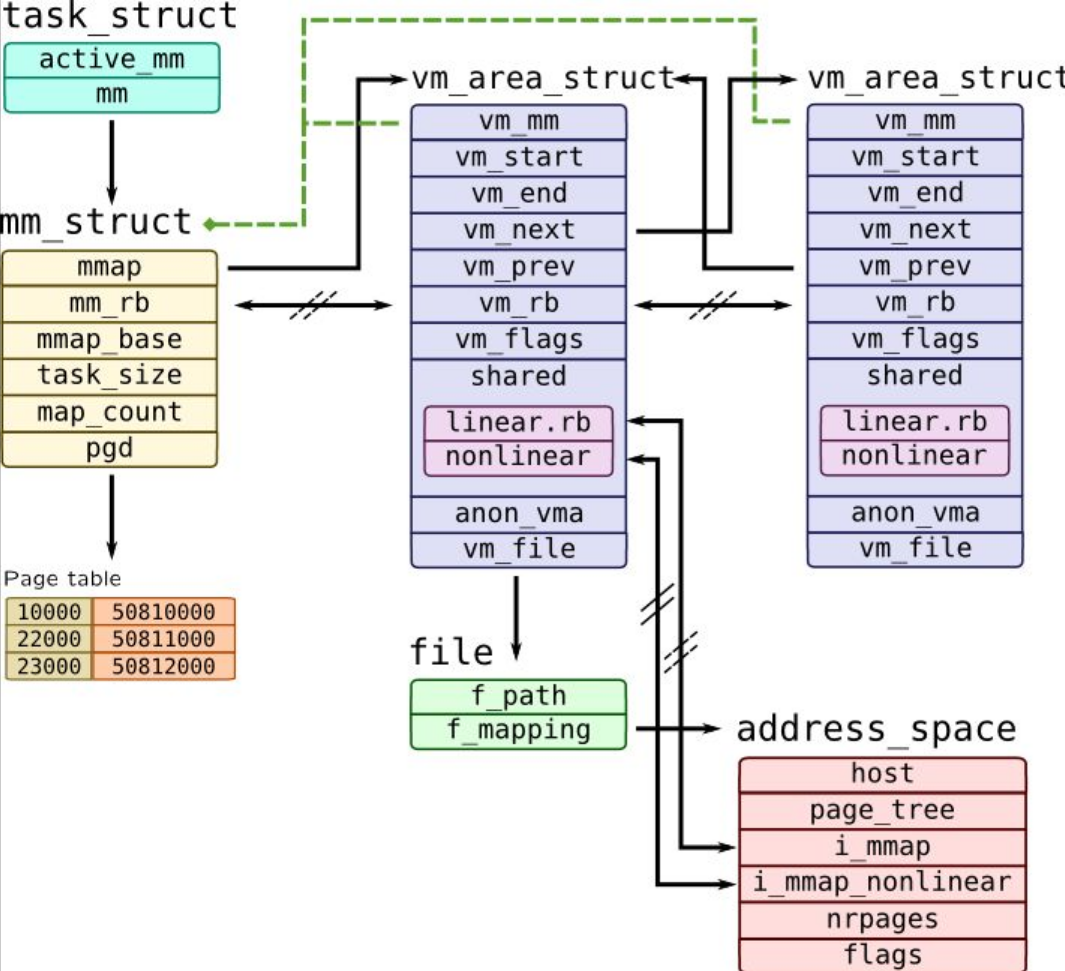
struct mm_struct¶
struct mm_struct 包含所有与进程相关的内存区域。 The mm field of struct task_struct is a pointer to the struct mm_struct of the current process.
struct vm_area_struct¶
A struct vm_area_struct is created at each mmap() call issued from user space. A driver that supports the mmap() operation must complete and initialize the associated struct vm_area_struct. The most important fields of this structure are:
- vm_start, vm_end - the beginning and the end of the memory area, respectively (these fields also appear in /proc//maps);
- vm_file - the pointer to the associated file structure (if any);
- vm_pgoff - the offset of the area within the file;
- vm_flags - a set of flags;
- vm_ops - a set of working functions for this area
- vm_next, vm_prev - the areas of the same process are chained by a list structure
TCB结构图
- 回写的页会变成写保护,写会再次触发缺页
PTE中R/W位标志是否写保护

为什么跟write不一样?我们先看看write的过程:

根本原因当然是再次写不能切换到内核态无法修改PTE,只能通过写保护再次触发写时复制缺页异常,标记为脏页。
- mmap触发的缺页异常并不会一次将所有文件内容读到内存中。
linux将缺页异常分为几种情况分别分配内存,包括PTE是否为空,是匿名映射还是文件映射、是读文件还是写文件、页面是否换出、是否满足COW等等情况。
如果是文件映射导致的缺页异常,最终的调用是这样的:
//如果map_pages函数不为空并且fault_around_bytes有效,//map_pages就是之前讲过的预读的操作函数,fault_around_bytes控制预读长度,一般64kif (vma->vm_ops->map_pages && fault_around_bytes >> PAGE_SHIFT > 1) {//调用do_fault_around预读几个页的文件内容读取到vmf->page,为了减少页错误异常的次数ret = do_fault_around(vmf);if (ret)return ret;}可以通过MADV_SEQUENTIAL来更激进地申请mmap内存,也可以通过MAP_POPULATE直接将文件全部加载到内存中,这也意味着内存会被更快的释放。
- 内核态申请的PTE是共享的 PTE中的G位表示是否共享
ptmalloc

memory
应用地址空间,由RAM或swap提供
chunk
可以在应用中分配、在glibc中释放或与相邻chunk组合成较大范围的小范围内存。请注意,chunk是给定给应用的memory的包装器。每个chunk存在于一个heap中,属于一个arena。
heap
memory中的一个连续区域,它被细分为要分配的chunk。每个heap恰好属于一个arena。
arena
一种在一个或多个线程之间共享的结构,其中包含对一个或更多heap的引用,以及这些heap中“空闲”的chunk的链表。分配给每个arena的线程将从该arena的空闲列表(bins)中分配内存。
chunk
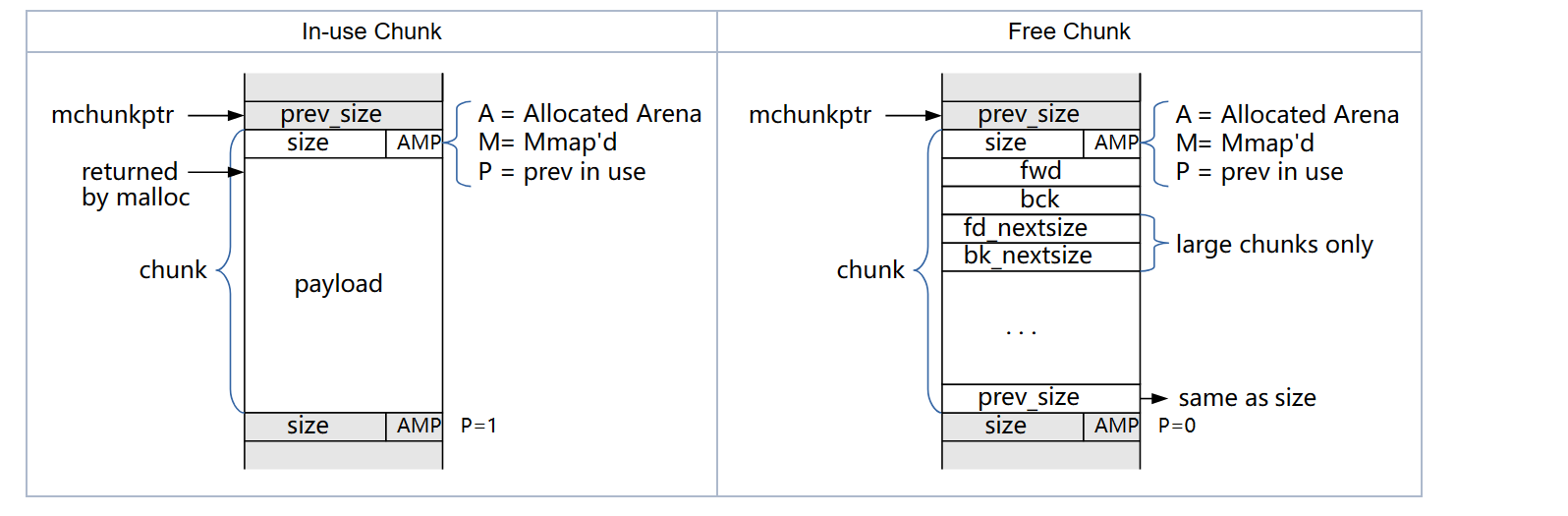
使用中的chunk
1、heap中有chunk指针和mem指针 chunk指针指向chunk开始的地址;mem指针指向用户内存块开始的地址。
2、 p=0时,表示前一个chunk为空闲,prev_size才有效
3、p=1时,表示前一个chunk正在使用,prev_size无效 p主要用于内存块的合并操作;ptmalloc 分配的第一个块总是将p设为1, 以防止程序引用到不存在的区域
4、M=1 为mmap映射区域分配;M=0为heap区域分配
5、 A=0 为主分配区分配;A=1 为非主分配区分配。
空闲的chunk
1、当chunk空闲时,其M状态是不存在的,只有AP状态,
2、原本是用户数据区的地方存储了四个指针,
指针fd指向后一个空闲的chunk,而bk指向前一个空闲的chunk,malloc通过这两个指针将大小相近的chunk连成一个双向链表。
在large bin中的空闲chunk,还有两个指针,fd_nextsize和bk_nextsize,用于加快在large bin中查找最近匹配的空闲chunk。不同的chunk链表又是通过bins或者fastbins来组织的。
arenas和heaps

为了有效地处理多线程应用程序,glibc的malloc允许一次活动多个内存区域。因此,不同的线程可以访问存储器的不同区域,而不会相互干扰。这些记忆区域统称为“arena”。有一个主mrena,即“main arena”,对应于应用程序的初始heap。malloc代码中有一个静态变量指向这个arena,每个arena都有一个下一个指针来链接其他arena。
随着线程碰撞的压力增加,glibc通过mmap创建了额外的arena来缓解压力。arena的数量上限为系统中CPU数量的八倍,这意味着重线程应用程序仍会出现一些争用,但代价是碎片会减少。
每个arena中都有一个mutex,用于控制对该arena的访问。一些操作,例如访问fastbins,可以使用原子操作来完成,并且不需要锁定arena。所有其他操作都要求线程锁定arena。对这个mutex的争用是创建多个arena的原因——分配给不同arena的线程不需要相互等待。如果有争用,线程将自动切换到未使用(未锁定)的arenas。
每个arenas都从一个或多个堆中获得内存。main arenas使用程序的初始堆(从.bss之后开始),可以使用mmap和brk分配内存。其它的arenas只能通过mmap为它们的堆分配内存,每个竞技场都会跟踪一个特殊的“顶部”chunk,这通常是最大的可用chunk,同时指向最近分配的heap。
总结:
1. 主分配区和非主分配区形成一个环形链表进行管理。
2. 每一个分配区利用互斥锁使线程对于该分配区的访问互斥。
3. 每个进程只有一个主分配区,也可以允许有多个非主分配区。
4. ptmalloc根据系统对分配区的争用动态增加分配区的大小
5. 主分配区可以使用brk和mmap来分配,而非主分配区只能使用mmap来映射内存块
6. 申请小内存时会产生很多内存碎片,ptmalloc在整理时也需要对分配区做加锁操作
bins
为了避免频繁的系统调用,应用free的内存块,ptmalloc会根据size和历史存储在不同的bins中。
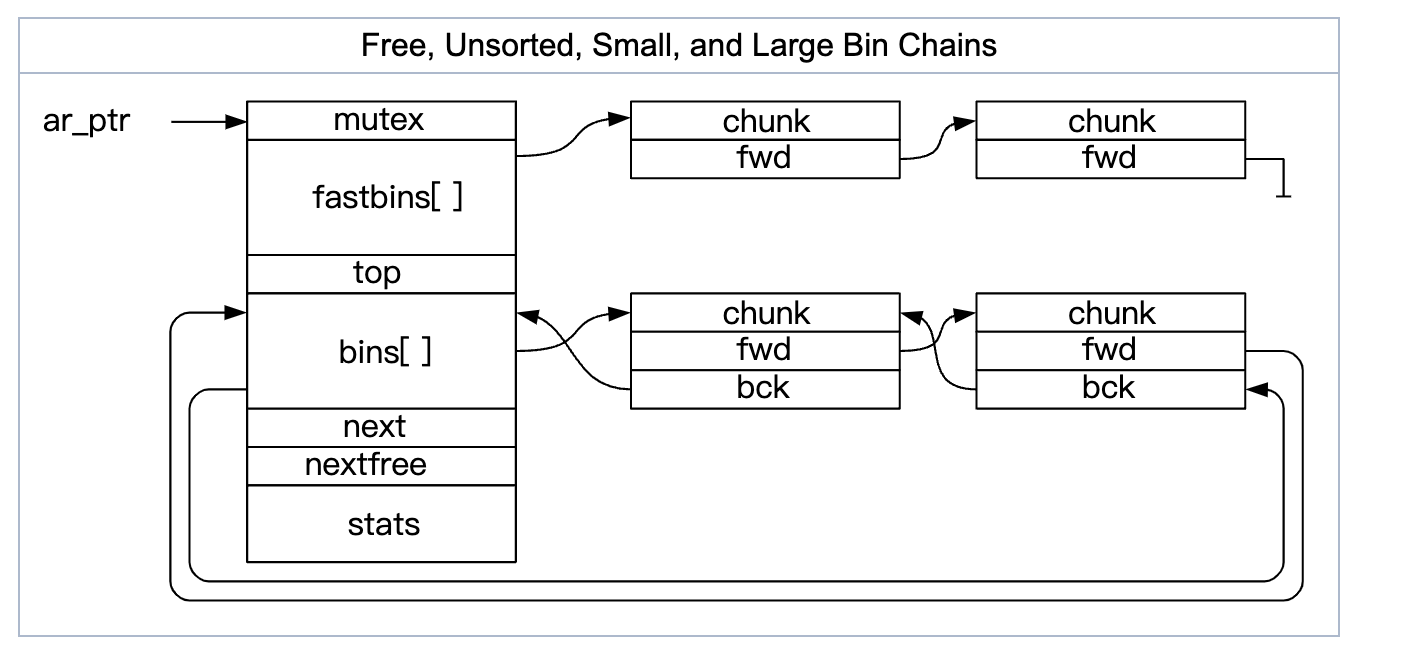
fast bins
fast bins是bins的高速缓冲区,大约有10个定长队列。每个fast bin都记录着一条free chunk的单链表(称为binlist ,采用单链表是出于fast bin中链表中部的chunk不会被摘除的特点),增删chunk都发生在链表的前端。
fastbin中的chunks可以根据需要移动到其他bins中。fast bins 记录着大小以8字节递增的bin链表。当用户释放一块不大于max_fast(默认值64B)的chunk的时候,会默认会被放到fast bins上。当需要给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会到fast bins上寻找是否有合适的chunk,除非特定情况,两个毗连的空闲chunk并不会被合并成一个空闲chunk。不合并可能会导致碎片化问题,但是却可以大大加速释放的过程。

unsorted bins
unsorted bin 的队列使用 bins 数组的第一个,是bins的一个缓冲区,加快分配的速度。当用户释放的内存大于max_fast或者fast bins合并后的chunk都会首先进入unsorted bin上。unsorted bins无尺寸限制,任何大小chunk都可以添加进这里。unsorted bins的设计主要是为了一个最近释放的复用。
用户malloc时,如果在 fast bins 中没有找到合适的 chunk,则malloc 会先在 unsorted bin 中查找合适的空闲 chunk,如果没有合适的bin,ptmalloc会将unsorted bin上的chunk放入bins上,然后到bins上查找合适的空闲chunk。
small bins
大小小于512字节的chunk被称为small chunk,而保存small chunks的bin被称为small bin。数组从2开始编号,前64个bin为small bins,small bin每个bin之间相差8个字节,同一个small bin中的chunk具有相同大小。每个small bin都包括一个空闲区块的双向循环链表(也称binlist)。
free掉的chunk添加在链表的前端,而所需chunk则从链表后端摘除。两个毗连的空闲chunk会被合并成一个空闲chunk。合并消除了碎片化的影响但是减慢了free的速度。分配时,当samll bin非空后,相应的bin会摘除binlist中最后一个chunk并返回给用户。在free一个chunk的时候,检查其前或其后的chunk是否空闲,若是则合并,也即把它们从所属的链表中摘除并合并成一个新的chunk,新chunk会添加在unsorted bin链表的前端。
large bins
大小大于等于512字节的chunk被称为large chunk,而保存large chunks的bin被称为large bin,位于small bins后面。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小递减排序,大小相同则按照最近使用时间排列。
两个毗连的空闲chunk会被合并成一个空闲chunk。
分配时,遵循原则“smallest-first , best-fit”,从顶部遍历到底部以找到一个大小最接近用户需求的chunk。一旦找到,相应chunk就会分成两块User chunk(用户请求大小)返回给用户。Remainder chunk(剩余大小添加到unsorted bin。free时和small bin 类似。
三种特殊chunks
有三种特殊chunks不会存储到bins中:
- Top chunk
top chunk相当于分配区的顶部空闲内存,当bins上都不能满足内存分配要求的时候,就会来top chunk上分配。
当top chunk大小比用户所请求大小还大的时候,top chunk会分为两个部分:User chunk(用户请求大小)和Remainder chunk(剩余大小)。其中Remainder chunk成为新的top chunk。
当top chunk大小小于用户所请求的大小时,top chunk就通过sbrk(main arena)或mmap(thread arena)系统调用来扩容。 - mmaped chunk
当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。
3、Last remainder chunk
当在small bins中找不到合适的chunk,如果last remainder chunk的大小大于所需要的small chunk大小,last remainder chunk就会被分裂成两个chunk,其中一个chunk返回给用户,另一个chunk变成新的last remainder chunk。
tccache
线程会在thread local中记住用过的main arenas,如果这个arenas被占用,那么就会阻塞等待其释放。
线程也有自己的cache,被称为_tcache,这个块大小受到限制,_分配时不需要使用arenas,而回退时需要使用arenas。

内存分配算法

- 如果在tcache中有一个合适的(精确匹配)块,它就会返回给调用者。没有则尝试使用来自较大大小的bins的可用块。
- 如果请求足够大,则使用mmap()直接从操作系统请求内存。请注意,mmap的阈值是动态的,可以通过M_mmap_threshold参数修改,并且同时可以有多少mmap是有限制的。
- 如果合适的fastbin中有一个chunk,请使用它。如果有其他chunk可用,也可以预填充tcache。
- 如果适当的smallbin中有一个chunk,请使用它,可能还会在此处预填充tcache。
- 如果请求“很大”,花点时间把fast bins里的所有东西都拿走,然后把它们移到unsorted bins里,边走边合并。
- 开始从unsorted bins中取出块,并将它们移到小/大的bins中,边走边合并(注意,这是代码中唯一将块放入小/大bins的地方)。如果看到一个合适大小的chunk,则使用它。
- 如果请求是“大”的,则搜索相应的大bin,然后依次搜索更大的bin,直到找到足够大的chunk。
- 如果我们在fastbin中仍然有块(这可能发生在“小”请求中),请合并这些块并重复前两个步骤。
内存释放算法
free()调用并不会真正将内存返还到操作系统,而仅标记为可被应用程序重用。如果top chunk内存足够大,那么可能会取消映射。
- 如果tcache中有空间,则将块存储在那里并返回。
- 如果区块足够小,请将其放入适当的fast bins中。
- 如果这个区块是mmap的,就对它进行munmap。
- 查看此bins是否与另一个可用bins相邻,如果相邻则合并。
- 将区块放在unsorted bins中,除非它现在是top trunk。
- 如果thunk足够大,合并所有fastbin,然后如果顶部的thunk是否足够大,将会在os中取消映射。出于性能原因,这一步骤可能会被推迟,并在malloc或其他调用期间发生。
简单聊聊GC场景下的内存释放
结合上面文章,主要是考虑GC一次回收的粒度问题。
以目前jdk默认的G1为例。
按照分代收集理论,新生代会比老年代有更频繁的gc调用。
参考资料
https://ionutbalosin.com/2020/01/hotspot-jvm-performance-tuning-guidelines/
https://man7.org/linux/man-pages/man2/mmap.2.html
https://zhuanlan.zhihu.com/p/166576293
https://www.microsoft.com/en-us/research/uploads/prod/2019/06/mimalloc-tr-v1.pdf
https://zhuanlan.zhihu.com/p/658307892
https://openjdk.org/groups/hotspot/docs/RuntimeOverview.html#Thread%20Management|outline
https://www.oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf
https://tldp.org/LDP/lki/lki-4.html
https://keys961.github.io/2019/04/10/Linux%E5%86%85%E6%A0%B8-%E9%A1%B5%E9%AB%98%E9%80%9F%E7%BC%93%E5%AD%98%E4%B8%8E%E9%A1%B5%E5%9B%9E%E5%86%99/
https://www.kernel.org/doc/gorman/html/understand/understand005.html
https://www.infradead.org/~mchehab/rst_conversion/filesystems/vfs.html

)








)



)




