记录之前刚学习Redis 的笔记, 主要包括Redis的基本数据结构、Redis 发布订阅机制、Redis 事务、Redis 服务器相关及采用Spring Boot 集成Redis 实现增删改查基本功能
一:常用命令及数据结构
1.Redis 键(key)
# 设置key和value
127.0.0.1:6379> set mykey hello
OK# 获取key对应的内容
127.0.0.1:6379> get mykey
"hello"# 序列化给定 key ,并返回被序列化的值
127.0.0.1:6379> dump mykey
"\x00\x05hello\t\x00\xb3\x80\x8e\xba1\xb2C\xbb"# 判断是否存在某个key是否存在
127.0.0.1:6379> exists mykey
(integer) 1
127.0.0.1:6379> exists mykey1
(integer) 0# 查询所有的key
127.0.0.1:6379> keys *
1) "mykey"
2) "mylist1"
3) "key1"
4) "list"
5) "myList"
6) "mylist"
7) "friend:a"
8) "friend:b"# 设置key的过期时间
127.0.0.1:6379> expire mykey 20
(integer) 1
127.0.0.1:6379> get mykey
"hello"# 以秒为单位,返回给定 key 的剩余生存时间
127.0.0.1:6379> ttl mykey
(integer) -2# 返回 key 所储存的值的类型
127.0.0.1:6379> set mykey hello
OK
127.0.0.1:6379> type mykey
string
127.0.0.1:6379>
2:Redis字符串
# 设置键
127.0.0.1:6379> set mykey hello
OK
127.0.0.1:6379> get key
(nil)
127.0.0.1:6379> get mykey
"hello"# 返回 key 中指定长度的字符串值的子字符
127.0.0.1:6379> getrange mykey 0 4
"hello"
127.0.0.1:6379> getrange mykey 0 2
"hel"# 重新设置key的值,并且返回老的值
127.0.0.1:6379> getset mykey hello&world
"hello"
127.0.0.1:6379># 获取多个key对应的值
127.0.0.1:6379> mget mykey mykey1 mykey2 mykey3 mykey4
1) "hello&world"
2) "java"
3) "spring"
4) "springboot"
5) "mysql"
127.0.0.1:6379># 为指定的 key 设置值及其过期时间,如果存在则修改值,如果不存在则新增并赋值
127.0.0.1:6379> SETEX mykey4 20 spark
OK
127.0.0.1:6379> get mykey4
"spark"
127.0.0.1:6379> SETEX mykey5 20 Hbase
OK
127.0.0.1:6379> get mykey5
"Hbase"# SETNX 命令在指定key不存在时,创建key并设置,当key存在时则不处理-->原生Redis分布式就是采用这个性质
127.0.0.1:6379> exists presto
(integer) 0
127.0.0.1:6379> setnx presto hiveSql
(integer) 1
127.0.0.1:6379> get presto
"hiveSql"
127.0.0.1:6379> setnx presto hiveSql+search
(integer) 0
127.0.0.1:6379> get presto
"hiveSql"
127.0.0.1:6379># 获取指定key值的长度
127.0.0.1:6379> get mykey3
"springboot"
127.0.0.1:6379> strlen mykey3
(integer) 10# 批量设置key和value
127.0.0.1:6379> mset mykey4 kafka mykey5 redis mykey6 nginx mykey7 oracle
OK
# 批量获取key和value
127.0.0.1:6379> mget mykey4 mykey5 mykey6 mykey7
1) "kafka"
2) "redis"
3) "nginx"
4) "oracle"
127.0.0.1:6379># 设置nkey 值为100
127.0.0.1:6379> set nkey 100
OK
127.0.0.1:6379> get nkey
"100"
# 自增1
127.0.0.1:6379> incr nkey
(integer) 101
# 自减1
127.0.0.1:6379> decr nkey
(integer) 100
# 加上一定的数
127.0.0.1:6379> incrby nkey 100
(integer) 200
# 减去一定的数
127.0.0.1:6379> decrby nkey 100
(integer) 100# 给指定的key对应的值后面拼接字符串
127.0.0.1:6379> get mykey7
"oracle"
127.0.0.1:6379> append mykey7 11
(integer) 8
127.0.0.1:6379> get mykey7
"oracle11"
127.0.0.1:6379>
3:Redis 哈希(Hash)
# 设置hash表key为field1,值为mysql
127.0.0.1:6379> hset hkey field1 mysql
(integer) 1
127.0.0.1:6379> hset hkey field2 oracle
(integer) 1# 获取hash表的值
127.0.0.1:6379> hget hkey field1
"mysql"# 获取所有的key
127.0.0.1:6379> hkeys hkey
1) "field1"
2) "field2"# 判断hash表中指定key是否存在
127.0.0.1:6379> hexists hkey field3
(integer) 0127.0.0.1:6379> hset hkey field3 spring
(integer) 1
127.0.0.1:6379> hget hkey field3
"spring"# 获取hash表的长度,及hash表的元素个数
127.0.0.1:6379> hlen hkey
(integer) 3# 获取hash表中所有的key
127.0.0.1:6379> hkeys hkey
1) "field1"
2) "field2"
3) "field3"# hash表元素增加指定量
127.0.0.1:6379> hset hkey field4 100
(integer) 1
127.0.0.1:6379> hget hkey field4
"100"
127.0.0.1:6379> hincrby hkey field4 100
(integer) 200# 获取hash表中所有的值
127.0.0.1:6379> hvals hkey
1) "mysql"
2) "oracle"
3) "spring"
4) "200"# 获取hash表中的多个字段的值
127.0.0.1:6379> hmget hkey field1 field2 field3 field4
1) "mysql"
2) "oracle"
3) "spring"
4) "200"# 只有在字段 field 不存在时,设置哈希表字段的值
127.0.0.1:6379> hsetnx hkey field5 springboot
(integer) 1
127.0.0.1:6379> hsetnx hkey field6 springcloud
(integer) 1
127.0.0.1:6379> hsetnx hkey field7 springCloud
(integer) 1
127.0.0.1:6379> hsetnx hkey field6 springCloud
(integer) 0
127.0.0.1:6379>
4:Redis 列表(List)
# push
127.0.0.1:6379> lpush lkey spring springboot mybatis mysql oracle kafka redis hive presto clickhourse es spark hbase flink vue
(integer) 15# 求长度
127.0.0.1:6379> llen lkey
(integer) 15# 根据索引获取元素
127.0.0.1:6379> lindex lkey 0
"vue"
127.0.0.1:6379> lindex key 1
(nil)
127.0.0.1:6379> lindex lkey 1
"flink"
127.0.0.1:6379> lindex lkey 5
"clickhourse"# 获取指定范围索引的值
127.0.0.1:6379> lrange lkey 0 -11) "vue"2) "flink"3) "hbase"4) "spark"5) "es"6) "clickhourse"7) "presto"8) "hive"9) "redis"
10) "kafka"
11) "oracle"
12) "mysql"
13) "mybatis"
14) "springboot"
15) "spring"
127.0.0.1:6379> lrange lkey 0 1
1) "vue"
2) "flink"
127.0.0.1:6379>
5.Redis 集合(Set)
Set 是 String 类型的无序、不可重复的集合
D:\software\redis>redis-cli.exe -h 127.0.0.1 -p 6379\
# 往Set集合添加元素
127.0.0.1:6379> sadd skey redis
(integer) 1# 查询Set集合中的元素个数
127.0.0.1:6379> scard skey
(integer) 1# 查询Set集合中所有的元素
127.0.0.1:6379> smembers skey
1) "redis"# 往Set集合中批量添加元素
127.0.0.1:6379> sadd skey mysql oracle hive presto spark hadoop kafka spring springboor springCloud mybatis
(integer) 11# 查询Set集合中所有的元素
127.0.0.1:6379> smembers skey1) "redis"2) "spring"3) "hadoop"4) "spark"5) "mybatis"6) "springboor"7) "presto"8) "kafka"9) "springCloud"
10) "hive"
11) "mysql"
12) "oracle"# 往Set集合中添加已经存在的元素,添加失败
127.0.0.1:6379> sadd skey redis
(integer) 0127.0.0.1:6379> smembers skey1) "spring"2) "hadoop"3) "spark"4) "mybatis"5) "springboor"6) "presto"7) "kafka"8) "springCloud"9) "hive"
10) "mysql"
11) "oracle"
12) "redis"# 批量往Set集合添加元素
127.0.0.1:6379> sadd skey1 mysql oracle hive presto spark hadoop kafka spring springboor springCloud mybatis nginx linux
(integer) 13127.0.0.1:6379> smembers skey11) "spring"2) "hadoop"3) "spark"4) "mybatis"5) "springboor"6) "presto"7) "kafka"8) "hive"9) "mysql"
10) "springCloud"
11) "oracle"
12) "linux"
13) "nginx"# 查询差集:在skey集合中存在,但是在skey1集合中不存在的数据
127.0.0.1:6379> sdiff skey skey1
1) "redis"
# 查询差集:在skey1集合中存在,但是在skey集合中不存在的数据
127.0.0.1:6379> sdiff skey1 skey
1) "nginx"
2) "linux"
127.0.0.1:6379> sinter skey skey11) "spring"2) "hadoop"3) "spark"4) "mybatis"5) "springboor"6) "presto"7) "kafka"8) "springCloud"9) "hive"
10) "mysql"
11) "oracle"# 查询集合skey和集合skey1的差集(在skey存在但是在skey1中不存在的数据),并且存在skey3
127.0.0.1:6379> sdiffstore skey3 skey skey1
(integer) 1
127.0.0.1:6379> smembers skey3
1) "redis"# 查询集合skey和集合skey1的交集,并且存在skey4
127.0.0.1:6379> sinterstore skey4 skey skey1
(integer) 11
127.0.0.1:6379> smembers skey41) "hadoop"2) "kafka"3) "presto"4) "spark"5) "springCloud"6) "spring"7) "springboor"8) "mybatis"9) "mysql"
10) "hive"
11) "oracle"# 查询skey4中是否存在元素linux
127.0.0.1:6379> sismember skey4 linux
(integer) 0
127.0.0.1:6379> sismember skey4 kafka
(integer) 1127.0.0.1:6379> smembers skey11) "spring"2) "hadoop"3) "spark"4) "mybatis"5) "springboor"6) "presto"7) "kafka"8) "hive"9) "mysql"
10) "springCloud"
11) "oracle"
12) "linux"
13) "nginx"# 把linux元素从skey1移动到skey4(移动后->返回1,skey1不存在,skey4存在该元素)
127.0.0.1:6379> smove skey1 skey4 linux
(integer) 1127.0.0.1:6379> smembers skey41) "spring"2) "hadoop"3) "spark"4) "springboor"5) "mybatis"6) "presto"7) "kafka"8) "springCloud"9) "mysql"
10) "hive"
11) "oracle"
12) "linux"# srandmember表示从集合中一个或多个随机数
127.0.0.1:6379> srandmember skey4
"linux"
127.0.0.1:6379> srandmember skey4
"springCloud"
127.0.0.1:6379> srandmember skey4
"springboor"
127.0.0.1:6379> srandmember skey4
"mybatis"
127.0.0.1:6379> srandmember skey4
"spark"
127.0.0.1:6379> srandmember skey4
"kafka"
127.0.0.1:6379> srandmember skey4
"springCloud"
127.0.0.1:6379> srandmember skey4
"oracle"127.0.0.1:6379> smembers skey41) "spring"2) "hadoop"3) "spark"4) "springboor"5) "mybatis"6) "presto"7) "kafka"8) "springCloud"9) "mysql"
10) "hive"
11) "oracle"
12) "linux"
127.0.0.1:6379> smembers skey11) "spring"2) "hadoop"3) "spark"4) "mybatis"5) "springboor"6) "presto"7) "kafka"8) "hive"9) "mysql"
10) "springCloud"
11) "oracle"
12) "nginx"# 返回所有给定集合的并集
127.0.0.1:6379> sunion skey1 skey41) "spring"2) "hadoop"3) "spark"4) "springboor"5) "mybatis"6) "presto"7) "kafka"8) "hive"9) "springCloud"
10) "mysql"
11) "oracle"
12) "linux"
13) "nginx"# 移除集合中一个或多个成员
127.0.0.1:6379> srem skey4 springCloud
(integer) 1# 移除并返回集合中的一个随机元素
127.0.0.1:6379> spop skey4
"spark"127.0.0.1:6379> smembers skey41) "spring"2) "hadoop"3) "springboor"4) "mybatis"5) "presto"6) "kafka"7) "mysql"8) "hive"9) "oracle"
10) "linux"
127.0.0.1:6379> spop skey4
"kafka"
127.0.0.1:6379> smembers skey4
1) "spring"
2) "hadoop"
3) "springboor"
4) "mybatis"
5) "presto"
6) "mysql"
7) "hive"
8) "oracle"
9) "linux"
127.0.0.1:6379>
6.Redis 有序集合(sorted set)
sorted set是一个有序、不重复的集合。每个元素都会关联一个double类型的分数,通过分数为集合中的成员进行从小到大进行排序。底层是通过哈希表实现的,添加、删除、查询的时间复杂度都是O(1)
有序集合的元素不可重复,但是分数可以重复
D:\software\redis>redis-cli.exe -h 127.0.0.1 -p 6379# 新建key为C++的sorted set,并往里批量添加元素
127.0.0.1:6379> zadd C++ 99 zhangsan 89 lisi 88 wangwu 79 zhaoliu 60 xiaoqi
(integer) 5# 查询有序集合中的成员数
127.0.0.1:6379> zcard C++
(integer) 5# 查询指定区间分数(min max)的元素个数
127.0.0.1:6379> zcount C++ 90 100
(integer) 1
127.0.0.1:6379> zcount C++ 80 90
(integer) 2
127.0.0.1:6379> zcount C++ 70 80
(integer) 1
127.0.0.1:6379> zcount C++ 60 70
(integer) 1# 给有序集合中某个元素的分数添加上指定的值
127.0.0.1:6379> zincrby C++ 10 xiaoqi
"70"# 查询有序集合中的全部的元素
127.0.0.1:6379> zrange C++ 0 -1
1) "xiaoqi"
2) "zhaoliu"
3) "wangwu"
4) "lisi"
5) "zhangsan"# 查询有序集合中的全部的元素及值
127.0.0.1:6379> zrange C++ 0 -1 WITHSCORES1) "xiaoqi"2) "70"3) "zhaoliu"4) "79"5) "wangwu"6) "88"7) "lisi"8) "89"9) "zhangsan"
10) "99"# 查询有序集合中的指定分数区间对应的元素
127.0.0.1:6379> ZRANGEBYSCORE C++ 90 100
1) "zhangsan"# 查询有序集合中所有的元素,并且按照升序排序
127.0.0.1:6379> ZRANGEBYSCORE C++ -inf +inf
1) "xiaoqi"
2) "zhaoliu"
3) "wangwu"
4) "lisi"
5) "zhangsan"# 查询有序集合中所有的元素及分数,并且按照升序排序
127.0.0.1:6379> ZRANGEBYSCORE C++ -inf +inf WITHSCORES1) "xiaoqi"2) "70"3) "zhaoliu"4) "79"5) "wangwu"6) "88"7) "lisi"8) "89"9) "zhangsan"
10) "99"# 查询有序集合中分数为90以下的元素
127.0.0.1:6379> ZRANGEBYSCORE C++ -inf 90
1) "xiaoqi"
2) "zhaoliu"
3) "wangwu"
4) "lisi"# 查询有序集合中分数为90以下的元素及对应的分数
127.0.0.1:6379> ZRANGEBYSCORE C++ -inf 90 WITHSCORES
1) "xiaoqi"
2) "70"
3) "zhaoliu"
4) "79"
5) "wangwu"
6) "88"
7) "lisi"
8) "89"# 查询有序集合中分数为90以下的元素及对应的分数
127.0.0.1:6379> ZRANGEBYSCORE C++ 70 +inf WITHSCORES1) "xiaoqi"2) "70"3) "zhaoliu"4) "79"5) "wangwu"6) "88"7) "lisi"8) "89"9) "zhangsan"
10) "99"# 查询指定元素在有序集合中的元素排序,不存在会返回nil
127.0.0.1:6379> zrank zkey zhangsan
(nil)
127.0.0.1:6379> zrank C++ zhangsan
(integer) 4
127.0.0.1:6379> zrank C++ xiaoqi
(integer) 0
127.0.0.1:6379> zrank C++ zhaoliu
(integer) 1# 返回有序集中指定分数区间内的元素,分数从高到低排序 ZREVRANGEBYSCORE key max min
127.0.0.1:6379> ZREVRANGEBYSCORE C++ 100 60
1) "zhangsan"
2) "lisi"
3) "wangwu"
4) "zhaoliu"
5) "xiaoqi"# 返回有序集中指定分数区间内的元素及分数,分数从高到低排序 ZREVRANGEBYSCORE key max min
127.0.0.1:6379> ZREVRANGEBYSCORE C++ 100 60 WITHSCORES1) "zhangsan"2) "99"3) "lisi"4) "89"5) "wangwu"6) "88"7) "zhaoliu"8) "79"9) "xiaoqi"
10) "70"# 查询有序集合中所有的元素 按照分数从大到小
127.0.0.1:6379> ZREVRANGEBYSCORE C++ +inf -inf
1) "zhangsan"
2) "lisi"
3) "wangwu"
4) "zhaoliu"
5) "xiaoqi"# 查询有序集合中所有的元素 按照分数从大到小 ZREVRANGEBYSCORE key max min
127.0.0.1:6379> ZREVRANGEBYSCORE C++ 60 80
(empty list or set)127.0.0.1:6379> ZREVRANGEBYSCORE C++ 80 60
1) "zhaoliu"
2) "xiaoqi"# 查询有序集合中所有的元素及对应的分数 按照分数从大到小 ZREVRANGEBYSCORE key max min
127.0.0.1:6379> ZREVRANGEBYSCORE C++ 80 60 WITHSCORES
1) "zhaoliu"
2) "79"
3) "xiaoqi"
4) "70"# 返回有序集合中指定元素在集合中的排名,按照分数降序排序
127.0.0.1:6379> zrevrank C++ zhangsan
(integer) 0
127.0.0.1:6379> zrevrank C++ xiaoqi
(integer) 4# 返回有序集合中指定元素对应的分数
127.0.0.1:6379> zscore C++ zhangsan
"99"# 新建Java 有序集合
127.0.0.1:6379> zadd Java 99 zhangsan 89 lisi 88 wangwu 79 zhaoliu 60 xiaoqi
(integer) 5# 计算两个有序集合的分数值
127.0.0.1:6379> ZINTERSTORE scores 2 C++ Java
(integer) 5
127.0.0.1:6379> zrange scores 0 -1
1) "xiaoqi"
2) "zhaoliu"
3) "wangwu"
4) "lisi"
5) "zhangsan"
# 查询计算分数值后的有序集合
127.0.0.1:6379> zrange scores 0 -1 WITHSCORES1) "xiaoqi"2) "130"3) "zhaoliu"4) "158"5) "wangwu"6) "176"7) "lisi"8) "178"9) "zhangsan"
10) "198"
127.0.0.1:6379>

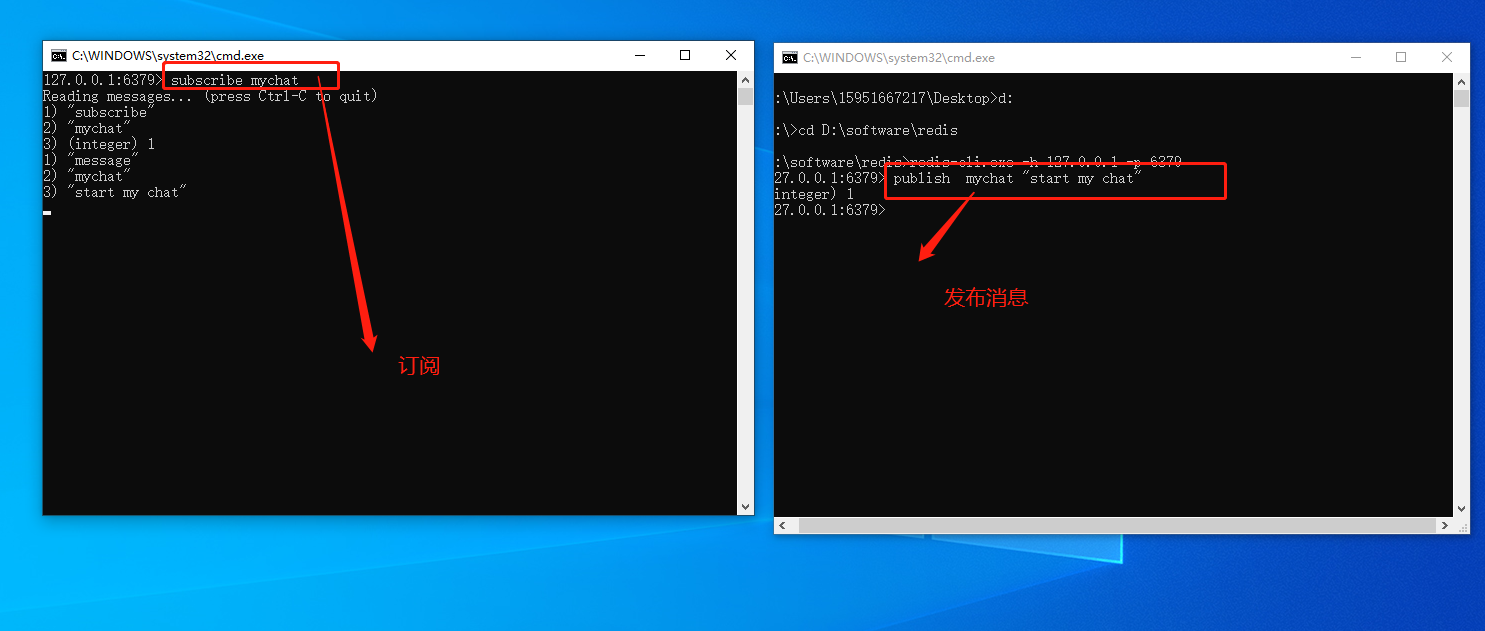
二:Redis发布与订阅
发布端
D:\software\redis>redis-cli.exe -h 127.0.0.1 -p 6379# 发布消息
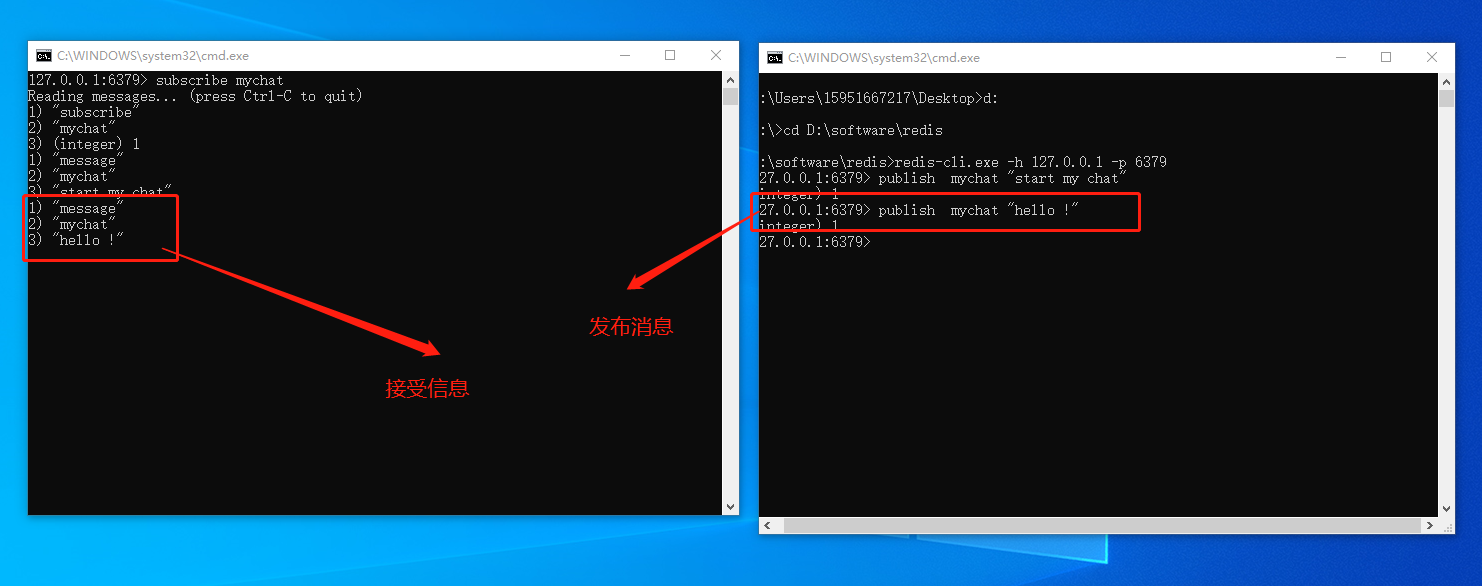
127.0.0.1:6379> publish mychat "start my chat"
(integer) 1127.0.0.1:6379> publish mychat "hello !"
(integer) 1
127.0.0.1:6379> pubsub channels
1) "mychat"
127.0.0.1:6379> punsubscribe mychat
1) "punsubscribe"
2) "mychat"
3) (integer) 0
127.0.0.1:6379> publish mychat "hello !"
(integer) 1
127.0.0.1:6379>
三:Redis 事务
什么是Redis事务?
Redis 事务可以一次执行多个命令,
- 批量操作在发送EXEC命令前被放入到缓存中;【开始事务】
- 收到EXEC命令后进入事务执行,事务中任意命令执行失败,其余的命令依然被执行;【命令入列】
- 在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中;【执行事务】
事务案例
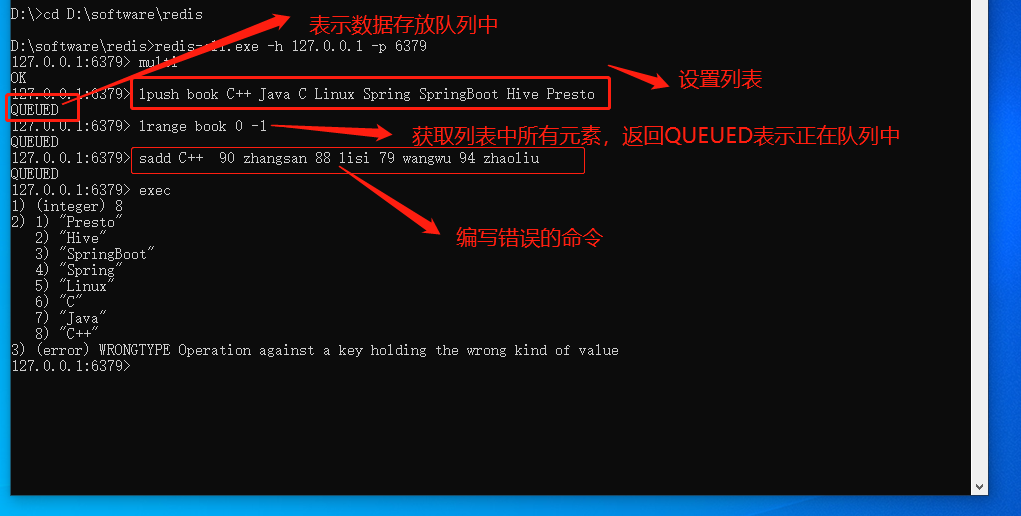
D:\software\redis>redis-cli.exe -h 127.0.0.1 -p 6379
# 开启事务
127.0.0.1:6379> multi
OK
# 往List里面批量添加元素,返回QUEUED表示命令存入队列中
127.0.0.1:6379> lpush book C++ Java C Linux Spring SpringBoot Hive Presto
QUEUED# 查询List中所有元素,返回QUEUED表示命令存入队列中
127.0.0.1:6379> lrange book 0 -1
QUEUED# 错误命令演示
127.0.0.1:6379> sadd C++ 90 zhangsan 88 lisi 79 wangwu 94 zhaoliu
QUEUED# 执行命令
127.0.0.1:6379> exec# 第一个命令执行成功,往List里面添加了8个元素
1) (integer) 8# 第二个命令执行成功,返回List中的所有数据
2) 1) "Presto"2) "Hive"3) "SpringBoot"4) "Spring"5) "Linux"6) "C"7) "Java"8) "C++"# 第三个命令执行错误
3) (error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379># 演示取消事务
# 开启事务
127.0.0.1:6379> multi
OK
127.0.0.1:6379> lpush book1 C++ Java C Linux Spring SpringBoot Hive Presto
QUEUED
127.0.0.1:6379> lrange book1 0 -1
QUEUED
127.0.0.1:6379> discard
OK
127.0.0.1:6379> lrange book1 0 -1
(empty list or set)
127.0.0.1:6379>
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
四:Redis服务器
# 手动触发异步式重写AOF
127.0.0.1:6379> bgrewriteaof
Background append only file rewriting started# 异步保存当前数据库的数据到磁盘
127.0.0.1:6379> BGSAVE
Background saving started# 获取连接到服务器的客户端连接列表
127.0.0.1:6379> client list
id=9 addr=127.0.0.1:56993 fd=11 name= age=6255 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client# 关闭客户端连接
127.0.0.1:6379> client kill 127.0.0.1:56993
OK
# 之前的连接已经被关闭,CLI 客户端又重新建立了连接,之前端口号是56993 现在是59469
127.0.0.1:6379> client list
id=10 addr=127.0.0.1:59469 fd=10 name= age=0 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client# 获取连接的客户端的名称
127.0.0.1:6379> client getname
(nil)
# 设置连接客户端的名称
127.0.0.1:6379> client setname hello-wordld-connection
OK
127.0.0.1:6379> client getname
"hello-wordld-connection"# 获取Redis命令详情
127.0.0.1:6379> command
# 获取Redis命令总数
127.0.0.1:6379> command count
(integer) 200# 获取Reids 中所有的key
127.0.0.1:6379> dbsize
(integer) 30
127.0.0.1:6379> set k v
OK
127.0.0.1:6379> dbsize
(integer) 31# 切换到1号数据库,dbsize查看1号数据库的key为0
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> dbsize
(integer) 0
# 在1号数据库添加数据
127.0.0.1:6379[1]> set key Java
OK
127.0.0.1:6379[1]> set Key1 C++
OK
127.0.0.1:6379[1]> get key
"Java"
127.0.0.1:6379[1]> get Key1
"C++"
127.0.0.1:6379[1]> dbsize
(integer) 2
# 清空整个 Redis 服务器的数据
127.0.0.1:6379[1]> fluahall
(error) ERR unknown command `fluahall`, with args beginning with:
127.0.0.1:6379[1]> flushall
OK
127.0.0.1:6379[1]> dbsize
(integer) 0# 返回最近一次Redis成功把数据保存到磁盘上的时间,以 UNIX 时间戳格式表示
127.0.0.1:6379[1]> lastsave
(integer) 1687104505# 列出连接客户端
127.0.0.1:6379> client list
id=15 addr=127.0.0.1:61301 fd=13 name= age=68 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=26 qbuf-free=32742 obl=0 oll=0 omem=0 events=r cmd=client# Slaveof 命令可以将当前服务器转变为指定服务器的从属服务器(slave server)
# 如果当前服务器已经是某个主服务器(master server)的从属服务器,那么执行 SLAVEOF host port 将使当前服务器停止对旧主服务器的同步,丢弃旧数据集,转而开始对新主服务器进行同步
# 对一个从属服务器执行命令 SLAVEOF NO ONE 将使得这个从属服务器关闭复制功能,并从从属服务器转变回主服务器,原来同步所得的数据集不会被丢弃
# 利用『 SLAVEOF NO ONE 不会丢弃同步所得数据集』这个特性,可以在主服务器失败的时候,将从属服务器用作新的主服务器,从而实现无间断运行。
127.0.0.1:6379> SLAVEOF 127.0.0.1 61301
OK
127.0.0.1:6379>
五:Redis GEO
Redis GEO 主要用于存储地理位置信息,并对存储的信息进行操作,该功能在 Redis 3.2 版本新增。
Redis GEO 操作方法有:
- geoadd:添加地理位置的坐标。
- geopos:获取地理位置的坐标。
- geodist:计算两个位置之间的距离。
- georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。
- georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。
- geohash:返回一个或多个位置对象的 geohash 值。
六:Redis客户端
1.Jedis
优点:
- 以Redis命令作为方法的名称,学习成本低,简单使用,提供了比较全面的Redis命令支持;
缺点:
- Jedis实例是线程不安全的,同步阻塞IO,不支持异步,多线程环境下需要基于连接池来使用;
使用案例
(1)创建项目,引入依赖
<dependencies><!-- Jedis --><dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.7.0</version></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>5.7.1</version><scope>test</scope></dependency></dependencies>
(2)编写测试代码
public class JedisTest {private Jedis jedis;@BeforeEachvoid setUp() {//1.建立连接jedis = new Jedis("127.0.0.1", 6379);//2.设置密码(如果Reis有设置密码的话,必须手动设置密码,否则无须指定密码)// jedis.auth("123456");//3.选择库jedis.select(0);}@Testvoid testString() {//存入String key = "k1";String value = "张三";String result = jedis.set(key, value);System.out.println("result=" + result);//读取String name = jedis.get(key);System.out.println("name=" + name);}@Testvoid testHash() {Map<String, String> map = new HashMap<>();map.put("k", "C++");map.put("k1", "Java");map.put("k2", "C");map.put("k3", "Spring");map.put("k4", "SpringBoot");String key = "tech";Long result = jedis.hset(key, map);if (result != 0) {//获取所有的keySet<String> hkeys = jedis.hkeys(key);System.out.println("获取所有的key=" + hkeys.toString());//获取hash表的值List<String> hvals = jedis.hvals(key);System.out.println("获取hash表的值=" + Arrays.toString(hvals.toArray()));//获取hash表长度Long hlen = jedis.hlen(key);System.out.println("获取hash表长度,len=" + hlen);//获取hash表中多个字段的值List<String> hmget = jedis.hmget(key, "k", "k1", "k2", "k3");System.out.println("获取hash表中多个字段的值=" + Arrays.toString(hmget.toArray()));}}//执行后@AfterEachvoid tearDown() {if (null != jedis) {jedis.close();}}
}
上述代码在多线程场景下会出现线程安全问题,可以采用Jedis的线程池处理
// 定义工具类
public class JedisConnectionFactory {private static final JedisPool jedisPool;static {JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();// 最大连接jedisPoolConfig.setMaxTotal(8);// 最大空闲连接jedisPoolConfig.setMaxIdle(8);//最小空闲连接jedisPoolConfig.setMinIdle(0);// 设置最长等待时间msjedisPoolConfig.setMaxWaitMillis(200);jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1X", 6379, 1000);}public static Jedis getJedis() {return jedisPool.getResource();}
}
对于上述代码改造,只需要把创建连接的方式调整成从连接吃里面获取即可
@BeforeEachvoid setUp() {jedis = JedisConnectionFactory.getJedis();jedis.select(0);}
2.Lettuce
优点:
- Lettuce是基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。
缺点:
- API更抽象,学习成本高
3.Redisson
优点:
- Redisson是一个基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、Lock、 Semaphore、AtomicLong等强大功能。
缺点:
- API更抽象,学习成本高
七:SpringBoot 整合Redis
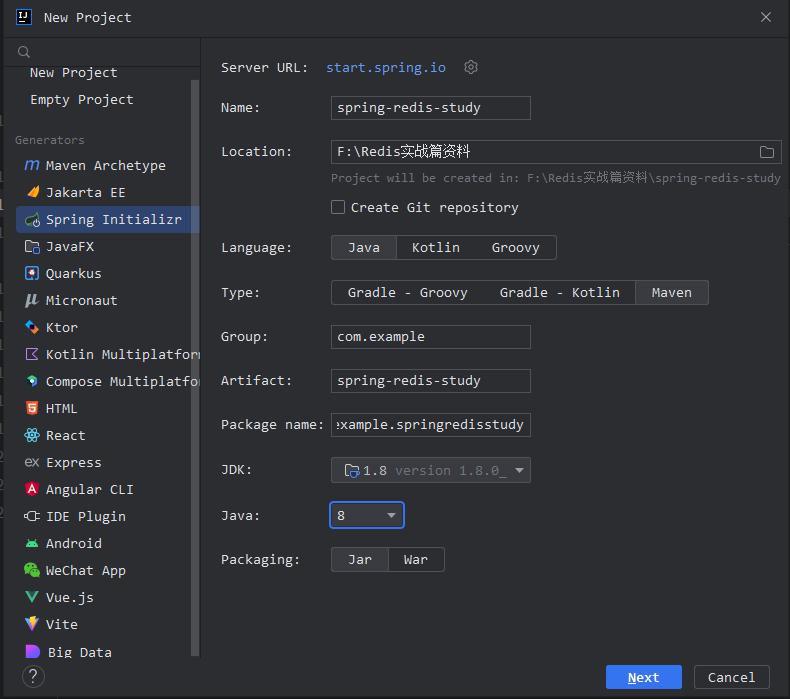
1.创建SpringBoot 项目
2.引入依赖(完整pom文件)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.5.7</version><relativePath/></parent><groupId>com.example</groupId><artifactId>spring-redis</artifactId><version>0.0.1-SNAPSHOT</version><name>spring-redis</name><description>spring-redis</description><properties><java.version>8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><!--common-pool--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency><!--Jackson依赖--><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
3.配置文件
application.yaml
spring:data:redis:host: 127.0.0.1port: 6379lettuce:pool:max-active: 8max-idle: 8min-idle: 0max-wait: 100ms
4.测试:使用RedisTemplate操作Redis
@SpringBootTest
class SpringRedisApplicationTests {@Autowiredprivate RedisTemplate redisTemplate;@Testvoid testString() {redisTemplate.opsForValue().set("zhangsan", "张三");Object zhangsan = redisTemplate.opsForValue().get("zhangsan");System.out.println("name = " + zhangsan);}}
八:Redis 序列化器
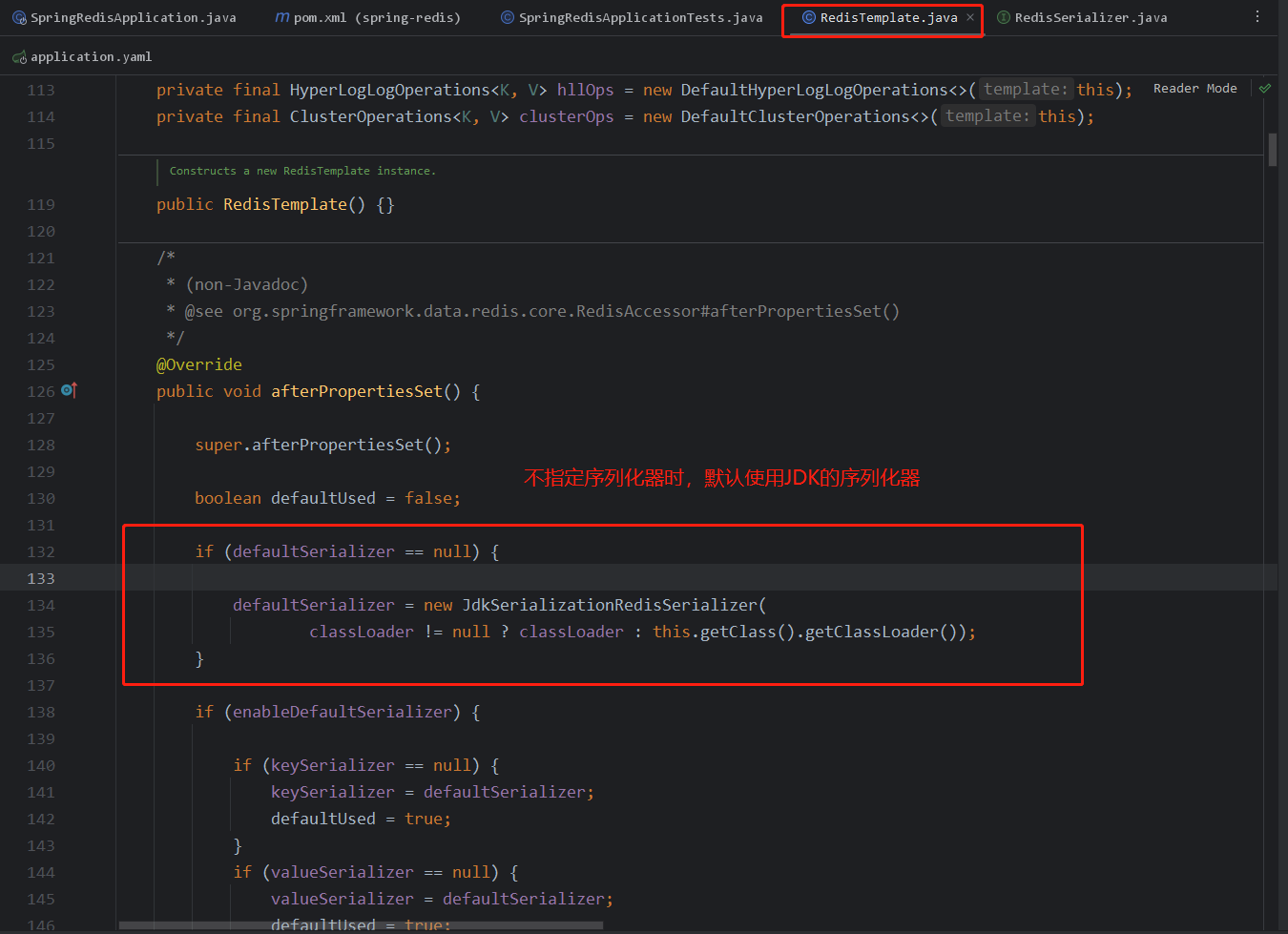
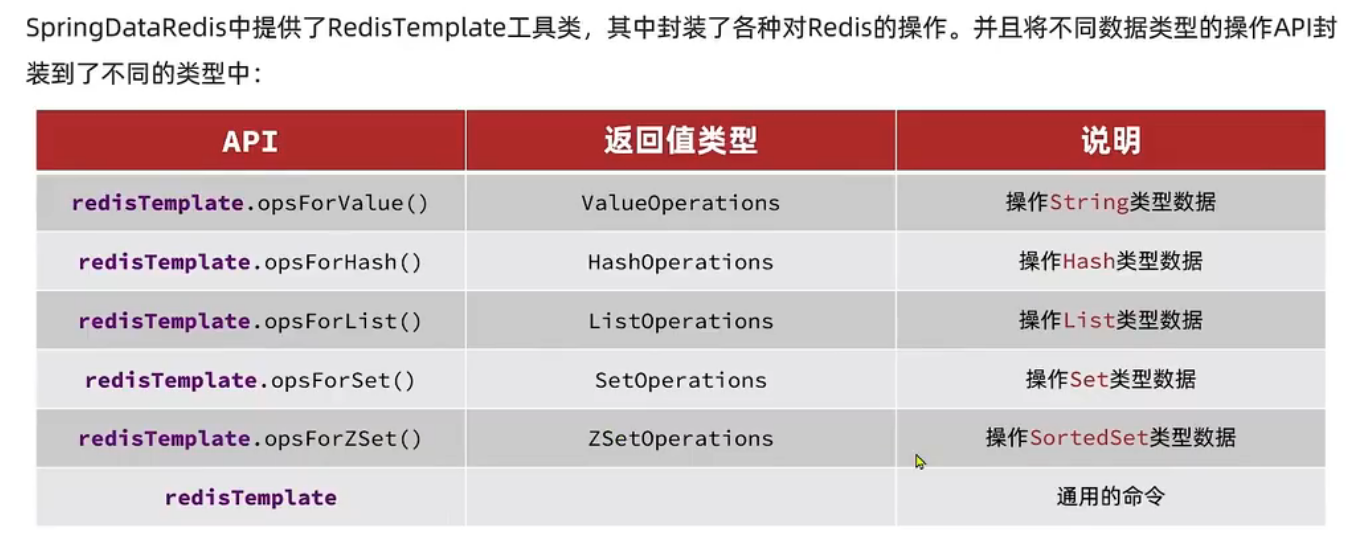
RedisSerializer又包含以下几个序列化器:
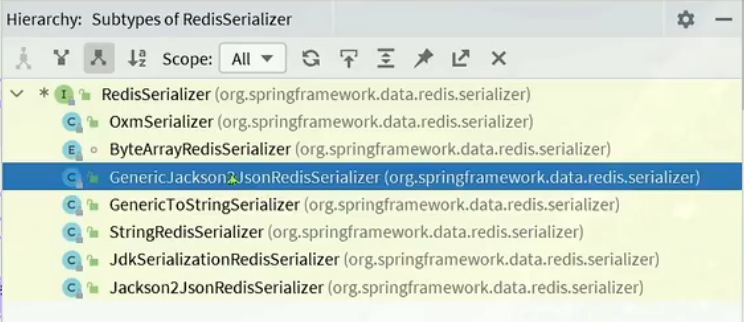
我们可以自定义Redis 序列化器,具体如下:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){// 创建RedisTemplate对象RedisTemplate<String, Object> template = new RedisTemplate<>();// 设置连接工厂template.setConnectionFactory(connectionFactory);// 创建JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 设置Key的序列化template.setKeySerializer(RedisSerializer.string());template.setHashKeySerializer(RedisSerializer.string());// 设置Value的序列化template.setValueSerializer(jsonRedisSerializer);template.setHashValueSerializer(jsonRedisSerializer);// 返回return template;}
}
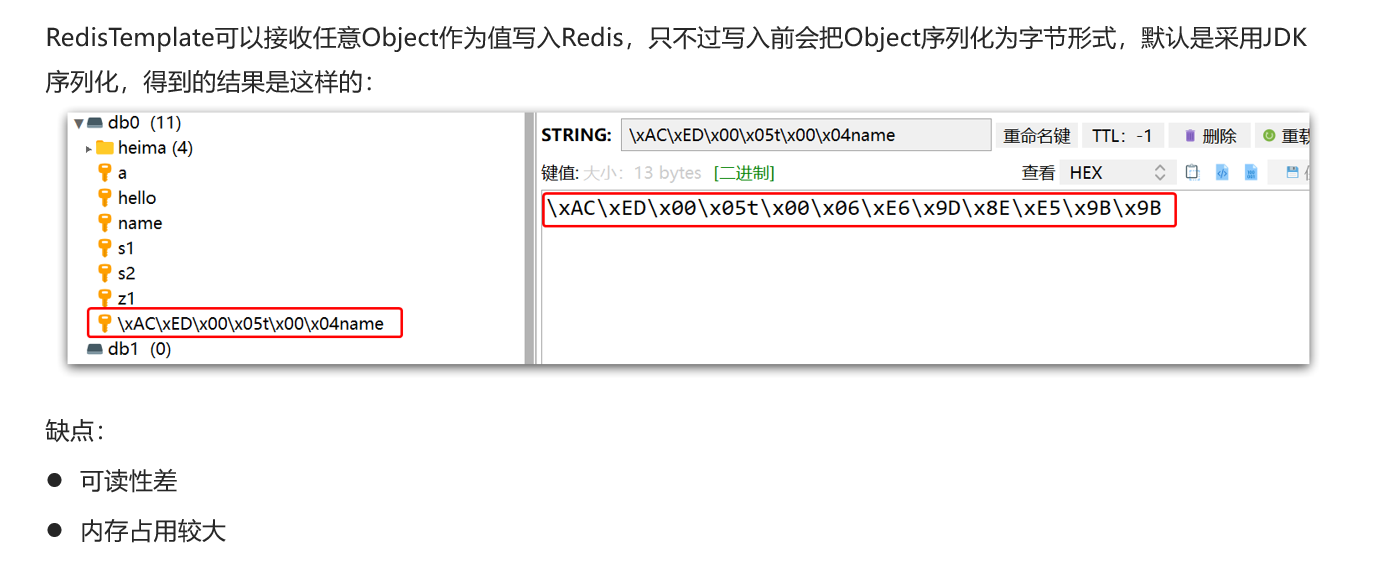
使用自定义序列化器后,就能解决上述不规则的字节形式
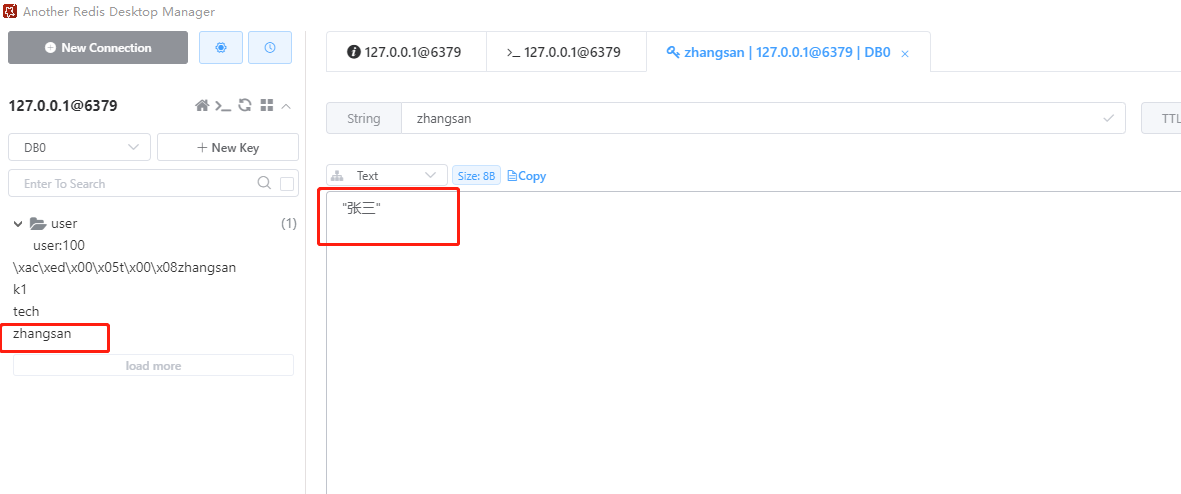
存储对象时,自定义的Redis序列化器也会自动把对象转成JSON后存储,反序列化时可以把JSON转成对象
@Testvoid testSaveUser() {// 写入数据redisTemplate.opsForValue().set("user:100", new User("李四", 18));// 获取数据User o = (User) redisTemplate.opsForValue().get("user:100");System.out.println("o = " + o);}
执行成功可以查看到此时存储的是JSON格式的数据
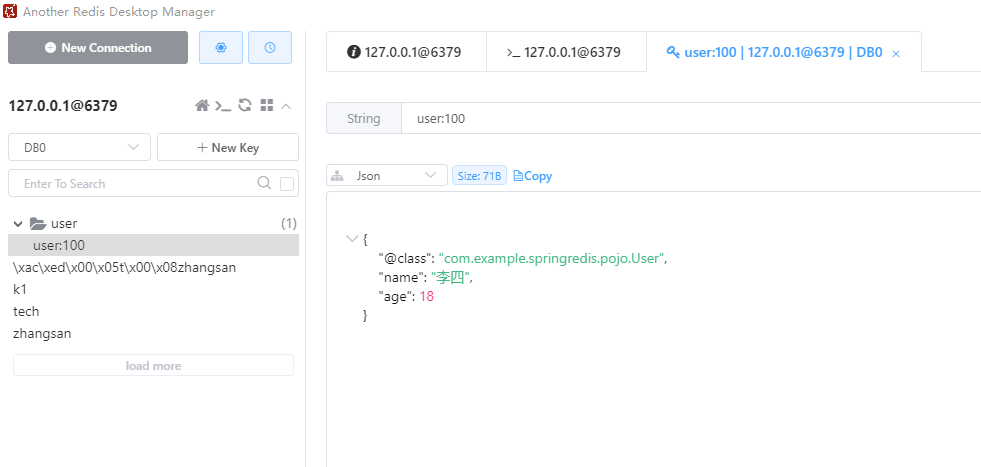
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题,如图
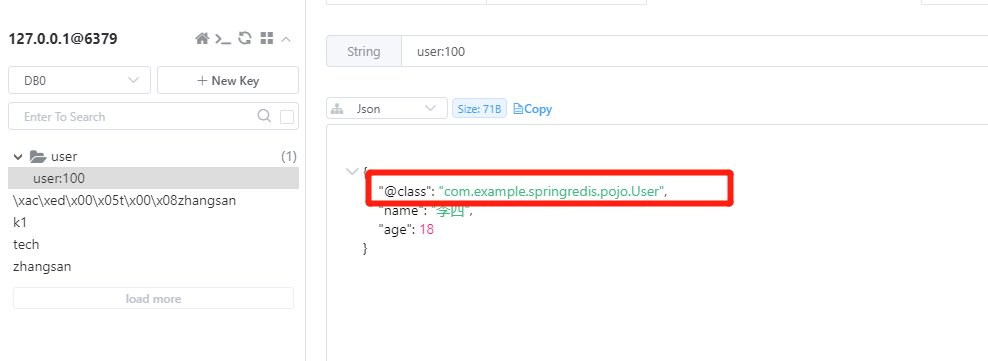
为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
StringRedisTemplate
使用StringRedisTemplate解决上述出现的问题,具体如下:
@SpringBootTest
class RedisStringTests {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Testvoid testString() {// 写入一条String数据stringRedisTemplate.opsForValue().set("k3", "老六");// 获取string数据Object name = stringRedisTemplate.opsForValue().get("k3");System.out.println("k3 = " + name);}private static final ObjectMapper mapper = new ObjectMapper();@Testvoid testSaveUser() throws JsonProcessingException {// 创建对象User user = new User("王五", 19);// 手动序列化String json = mapper.writeValueAsString(user);// 写入数据stringRedisTemplate.opsForValue().set("user:200", json);// 获取数据String jsonUser = stringRedisTemplate.opsForValue().get("user:200");// 手动反序列化User user1 = mapper.readValue(jsonUser, User.class);System.out.println("user1 = " + user1);}@Testvoid testHash() {stringRedisTemplate.opsForHash().put("user:400", "name", "王五");stringRedisTemplate.opsForHash().put("user:400", "age", "19");Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries("user:400");System.out.println("entries = " + entries);}
}
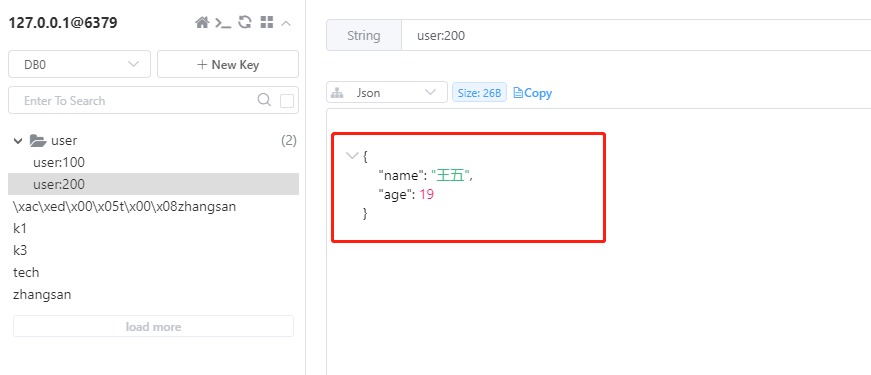
此时只存对象的类型,不会存储对象所在类的类型。










:XPath 基础知识)


— 缓存商品、购物车功能)
)

)


