68、VQVAE预训练模型的论文原理及PyTorch代码逐行讲解_哔哩哔哩_bilibili本期视频主要讲解大规模无监督预训练模型之VQVAE的论文原理以及PyTorch代码逐行讲解,希望对大家理解VQVAE以及图像生成有帮助。, 视频播放量 9920、弹幕量 80、点赞数 485、投硬币枚数 322、收藏人数 413、转发人数 51, 视频作者 deep_thoughts, 作者简介 在有限的生命里怎么样把握住时间专注做点自己喜欢做的同时对别人也有价值的事情,是我们应该时常自查反省的(纯公益分享不接任何广告或合作),相关视频:【授权】李宏毅2023春机器学习课程,语音合成超简洁训练代码框架,[论文简析]VQ-VAE:Neural discrete representation learning[1711.00937],图神经网络系列讲解及代码实现-异质图卷积网络RGCN 2,GPT-4写代码是真的强👍,技术培训-娄晓-手把手教Diffusion_VAE_VQVAE_UNet-附github代码,33、完整讲解PyTorch多GPU分布式训练代码编写,[pytorch] 深入理解 nn.KLDivLoss(kl 散度) 与 nn.CrossEntropyLoss(交叉熵),GPT,GPT-2,GPT-3 论文精读【论文精读】,[论文简析]VAE: Auto-encoding Variational Bayes[1312.6114]![]() https://www.bilibili.com/video/BV14Y4y1X7wb/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
https://www.bilibili.com/video/BV14Y4y1X7wb/?spm_id_from=333.337.search-card.all.click&vd_source=4aed82e35f26bb600bc5b46e65e25c22
VQ-VAE解读 - 知乎VAEVAE (variational autoencoder)是一种强大的生成模型. 我们可以从AE的角度去理解, 即有一个Encoder把数据编码到隐空间 ( z = Ecd(x) ), 然后又用一个Decoder把数据从隐空间中重建回来( x=Dcd(z) ). 而对于VAE, …![]() https://zhuanlan.zhihu.com/p/91434658轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型 - 知乎近两年,有许多图像生成类任务的前沿工作都使用了一种叫做"codebook"的机制。追溯起来,codebook机制最早是在VQ-VAE论文中提出的。相比于普通的VAE,VQ-VAE能利用codebook机制把图像编码成离散向量,为图…
https://zhuanlan.zhihu.com/p/91434658轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型 - 知乎近两年,有许多图像生成类任务的前沿工作都使用了一种叫做"codebook"的机制。追溯起来,codebook机制最早是在VQ-VAE论文中提出的。相比于普通的VAE,VQ-VAE能利用codebook机制把图像编码成离散向量,为图…![]() https://zhuanlan.zhihu.com/p/633744455文本天然是一种离散的符号,图像和音频的特征高维和稀疏,如果想对图片和音频进行多模态预训练,可以对它们进行信息压缩,不在图像像素空间或者语音的信号点空间上建模,而是可以将他们压缩一个隐空间中,它的特征就更加紧凑,然后对隐空间进行建模取生成。
https://zhuanlan.zhihu.com/p/633744455文本天然是一种离散的符号,图像和音频的特征高维和稀疏,如果想对图片和音频进行多模态预训练,可以对它们进行信息压缩,不在图像像素空间或者语音的信号点空间上建模,而是可以将他们压缩一个隐空间中,它的特征就更加紧凑,然后对隐空间进行建模取生成。
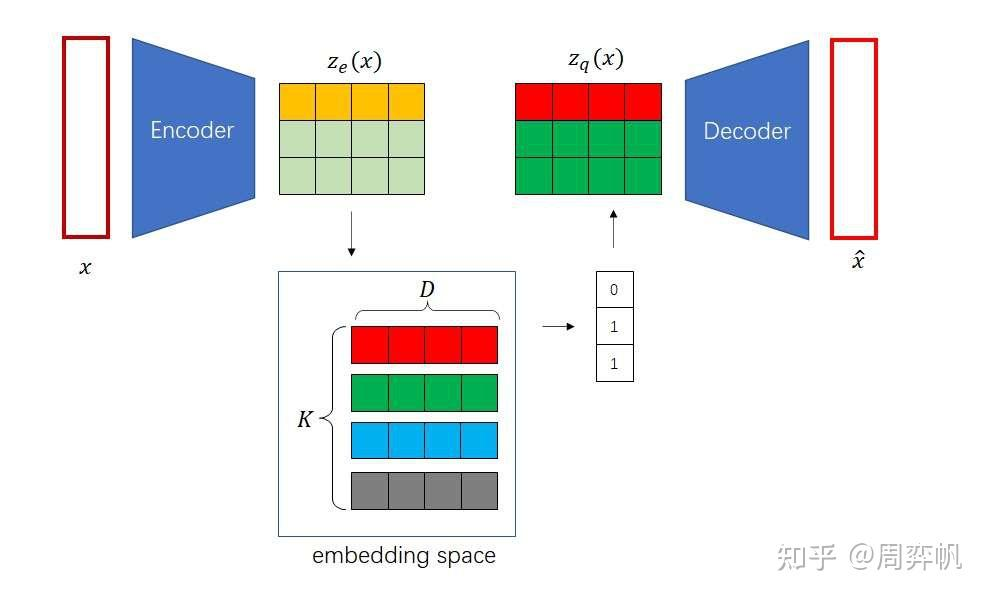
如何在无监督下去学习有用的表征?VQVAE和VAE的区别在于,1.编码器网络产生的是离散的编码,而不是连续的编码,离散就是当你训练一个语言模型,比如word2vec时,把每个单词建立一个单词表,单词表中单词的顺序就作为这个单词的一个离散的表征,2.先验是可学习的而不是静态的,在VAE中通常假设先验是一个标准分布,是一个高斯分布,在VQVAE中先验不再是一个静态的分布,而是模型去学到的某一个分布,是一个离散的类别分布。基于VQ的方法不存在后验崩塌的问题,后验崩塌指的是无论输入的隐变量是什么,解码器的输出都一样的,和GAN的模式崩塌基本一样的。在VQVAE的基础上,可以用一个自回归的先验模型去学习隐变量分布,可以用生成。
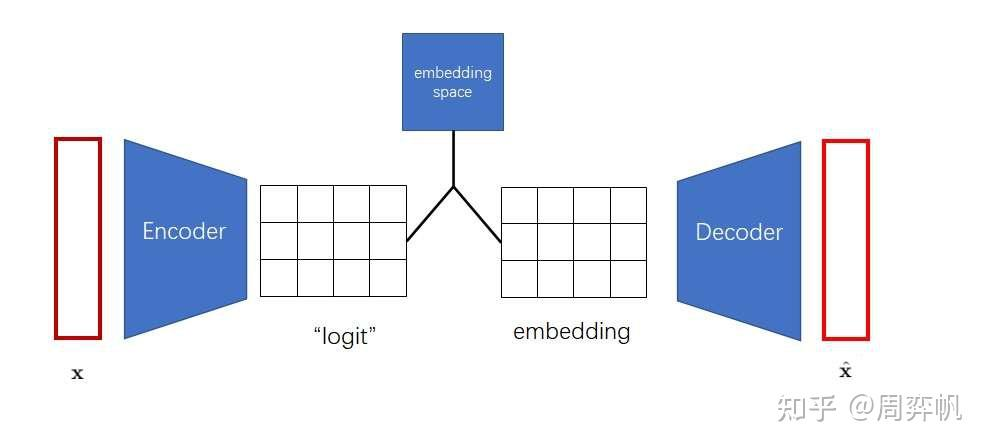
VAE中为了表征一个对象,先对对象进行一个信息压缩,先编码,把高维稀疏的数据压缩到一个空间中,再通过解码器还原。包含三个部分,后验分布,先验分布和解码器。后验分布和先验分布通常假设成一个标准的高斯分布,通过重参数让解码器和编码器的梯度可导。VQVAE中VQ,对隐变量不再让它从一个连续的高斯分布中去生成,而是从一个离散的分布中去生成,此时的后验分布和先验分布都是类别分布,从类别中产生的样本,其实就是索引,基于这个索引从embedding table中找到相应的embedding,然后让这个embedding作为提取的z,送入到解码器中。
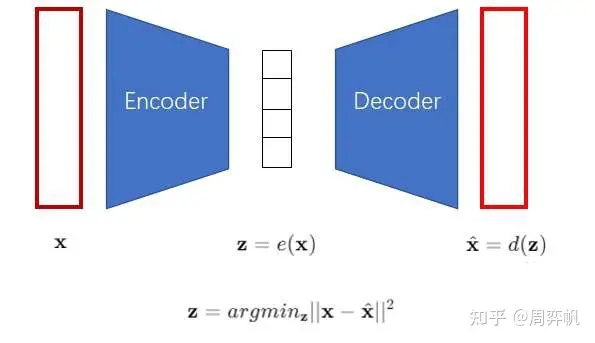
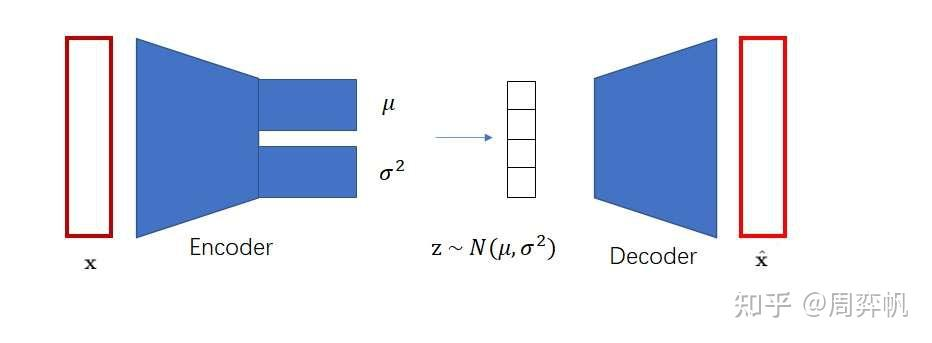
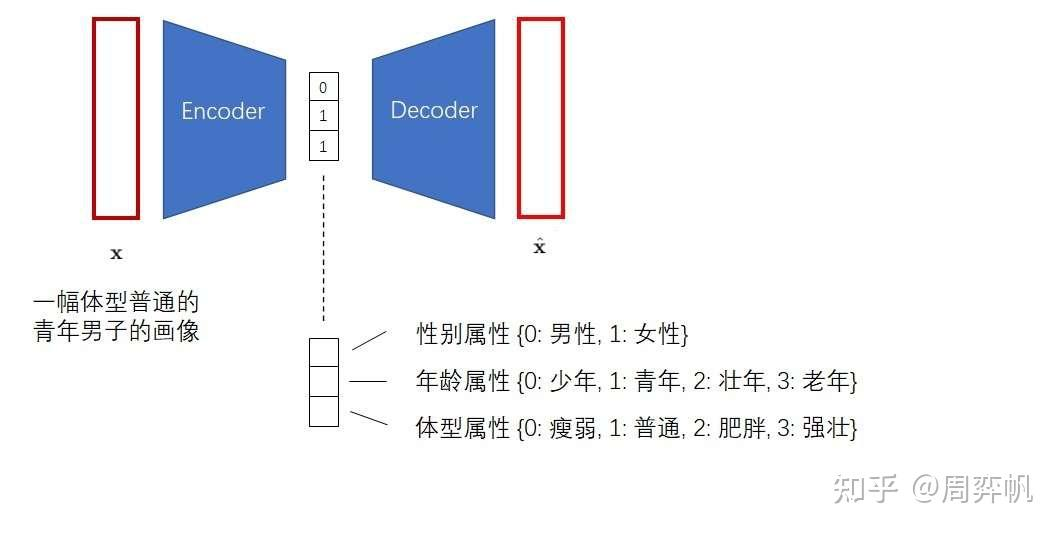
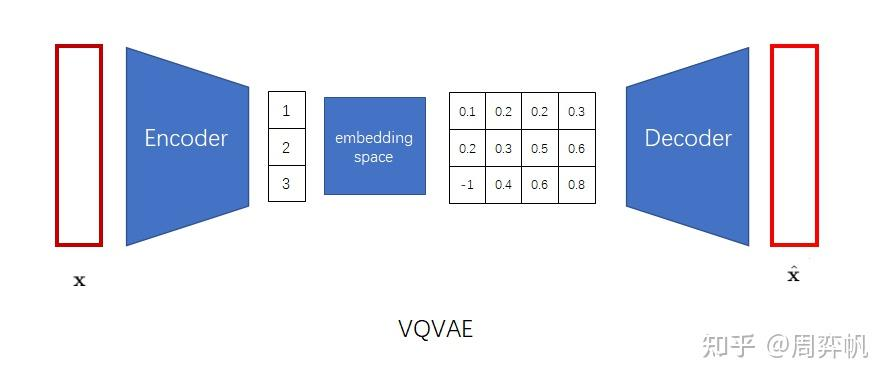
- 训练VQ-VAE的编码器和解码器,使得VQ-VAE能把图像变成「小图像」,也能把「小图像」变回图像。
- 训练PixelCNN,让它学习怎么生成「小图像」。
- 随机采样时,先用PixelCNN采样出「小图像」,再用VQ-VAE把「小图像」翻译成最终的生成图像。

)


















与控制框架/架构)