什么是流 stream
流是用于在 Node.js 中处理流数据的抽象接口。 node:stream 模块提供了用于实现流接口的 API。
什么是流数据
流数据是指一组顺序、大量、快速、连续到达的数据序列,一般情况下数据流可被视为一个随时间延续而无限增长的动态数据集合。流数据应用于网络监控、传感器网络、航空航天、气象测控和金融服务等领域。与静态数据不同,流数据是实时生成的,需要实时处理和分析。
Nodejs 中的流(Stream)是用来比喻数据传输的一种形式,数据传输的起点就是流的源头,数据传输的终点就是流的终点。
例子
例如在网页发起一个 HTTP 请求,浏览器就是流的源头,服务器就是流的终点。等服务器处理完请求,返回响应时,服务器就变成了流的源头,浏览器变成了流的终点。
计算机中的流传输的是数据(字节)
流的本质
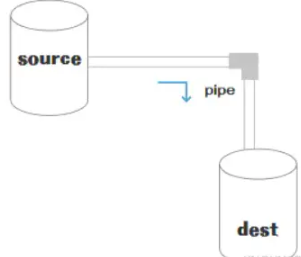
它能够发送/接受数据,本质就是让数据流动起来,如下图:
流可以分成三部分:
sourcedestpipe
在source和dest之间有一个连接的管道pipe,它的基本语法是source.pipe(dest),source和dest就是通过pipe连接,让数据从source流向了dest,如下图所示:
为什么用stream
根据输出结果 说明stream是分块读入内存的
const fs = require('fs');const readStream = fs.createReadStream('testA.file');
const writeStream = fs.createWriteStream('output.file');readStream.on('data', (chunk) => {console.log(`Received ${chunk.length} bytes of data.`);/*Received 65536 bytes of data.Received 65536 bytes of data.Received 65536 bytes of data.Received 65536 bytes of data.Received 65536 bytes of data.Received 22320 bytes of data.65536*5+22320=350,000说明流是分块读文件的*/writeStream.write(chunk);
});readStream.on('end', () => {// console.log('File reading is finished.');writeStream.end();
});
如果读取小文件,我们可以使用fs读取,fs读取文件的时候,是将文件一次性读取到本地内存
const fs = require('fs');
// const path = require('path');
const options = {encoding: 'utf-8',flag: 'r'
}fs.readFile('./testA.file', options, (err, data) => { //fs模块中的readFile方法可以接收3个参数,分别为:文件路径、配置对象、回调函数。if (err) {console.log(err); //readFile一次性读取//只打印一次Received 350000 bytes of data.}console.log(`Received ${data.length} bytes of data.`);
})
上文的readFile和writeFile实际上是对整个文件进行读取和写入,对硬件资源消耗较大。在webserver中这种情况是不被允许的。
stream作为一种“源源不断”的数据传递方式,有效节省了硬件开销
流的类型
Node.js 中有四种基本的流类型:
可写流:可写入数据的流。例如 fs.createWriteStream() 可以使用流将数据写入文件
可读流: 可读取数据的流。例如fs.createReadStream() 可以从文件读取内容
双工流: 既可读又可写的流。例如 net.Socket
转换流: 可以在数据写入和读取时修改或转换数据的流。例如,在文件压缩操作中,可以向文件写入压缩数据,并从文件中读取解压数据
怎么用?
fs.createReadStream(filePathA);//创建读取流
fs.createWriteStream(filePathB)//创建写入流
readStream.pipe(writeStream) // 通过pipe链接读取流和写入流
结果:
读取流与写入流之间通过pipe(管道)进行连接,数据源源不断地从读取流传递到写入流。
textA.txt
1234
textB.txt 由空到有值
1234
const fs = require('fs')
const path = require('path')// 分别获取两个文件的路径
const filePathA ='./testA.txt';
const filePathB = './testB.txt';// 创建读取流和写入流
const readStream = fs.createReadStream(filePathA);//创建读取流
const writeStream = fs.createWriteStream(filePathB)//创建写入流// 通过pipe链接读取流和写入流
readStream.pipe(writeStream) //效果是读取filePathA信息,写入到filePathB// 读取流监听'end'事件,输出完成信息
readStream.on('end', () => {console.log('copy done!');
})
//读取流与写入流之间通过pipe(管道)进行连接,数据源源不断地从读取流传递到写入流。
好处
当我们使用Node.js的流进行文件读取时,数据会被分成一块块的读入内存,而不是一次性将整个文件读入内存。这样可以避免因为文件过大而导致内存溢出的问题。同样,在使用流进行网络传输时,也可以将数据分成一块块进行传输,从而提高传输效率。



![[linux运维] 利用zabbix监控linux高危命令并发送告警(基于Zabbix 6)](http://pic.xiahunao.cn/[linux运维] 利用zabbix监控linux高危命令并发送告警(基于Zabbix 6))


)









)

线程的实现)
