1、背景
先阐明一下Mysql和Redis的关系:Mysql是数据库,用来持久化数据,一定程度上保证数据的可靠性;Redis是用来当缓存,用来提升数据访问的性能。
关于如何保证Mysql和Redis中的数据一致(即缓存一致性问题),这是一个非常经典的问题。其实网上应该是有很多相关的介绍,但是其实从实际出发,如果数据存在频繁的写操作,是不建议直接放到Redis中的,并且无论是哪种方式,其实都不能说完全可以使得数据一致性,我们只能说尽可能的让数据在绝大部分时间内保持一致,并保证最终是一致的。
2、产生原因
如果数据一直没有变更,那么就不会出现缓存不一致的问题。
通常缓存不一致是发生在数据有变更的时候。 因为每次数据变更你需要同时操作数据库和缓存,而他们又属于不同的系统,无法做到同时操作成功或失败,总会有一个时间差。在并发读写的时候可能就会出现缓存不一致的问题(理论上通过分布式事务可以保证这一点,不过实际上基本上很少有人这么做,也可以通过订阅binlog日志来操作,但是系统的复杂度就会提高,也不建议)。
虽然没办法在数据有变更时,保证缓存和数据库强一致,但对缓存的更新还是有一定设计方法的,遵循这些设计方法,能够让这个不一致的影响时间和影响范围最小化
3、缓存更新的几种设计
- 先删除缓存,再更新数据库(这种方法在并发下最容易出现长时间的脏数据,不可取)
- 先更新数据库,删除缓存
- 只更新缓存,由缓存自己同步更新数据库
- 只更新缓存,由缓存自己异步更新数据库
- 经典延时双删策略
简单介绍:
- 先删除缓存,再更新数据库
这种方法在并发读写的情况下容易出现缓存不一致的问题

如上图所示,其可能的执行流程顺序为:
- 客户端1 触发更新数据A的逻辑
- 客户端2 触发查询数据A的逻辑
- 客户端1 删除缓存中数据A
- 客户端2 查询缓存中数据A,未命中
- 客户端2 从数据库查询数据A,并更新到缓存中
- 客户端1 更新数据库中数据A
可见,最后缓存中的数据A跟数据库中的数据A是不一致的,缓存中的数据A是旧的脏数据。
因此一般不建议使用这种方式。
- 先更新数据库,再让缓存失效
这种方法在并发读写的情况下,也可能会出现短暂缓存不一致的问题
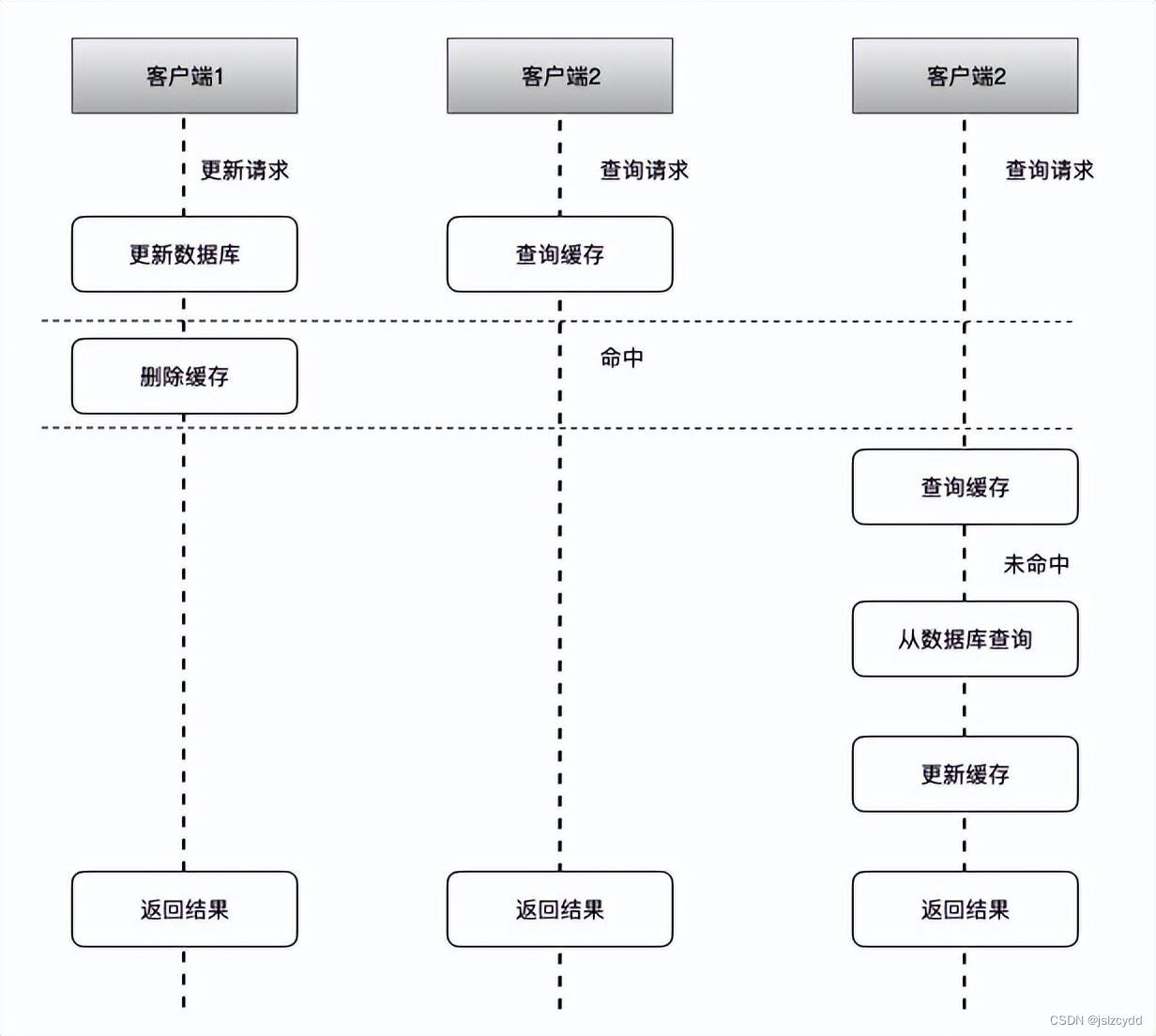
如上图所示,其可能执行的流程顺序为:
- 客户端1 触发更新数据A的逻辑
- 客户端2 触发查询数据A的逻辑
- 客户端3 触发查询数据A的逻辑
- 客户端1 更新数据库中数据A
- 客户端2 查询缓存中数据A,命中返回(旧数据)
- 客户端1 让缓存中数据A失效
- 客户端3 查询缓存中数据A,未命中
- 客户端3 查询数据库中数据A,并更新到缓存中
可见,最后缓存中的数据A和数据库中的数据A是一致的,理论上可能会出现一小段时间数据不一致,不过这种概率也比较低,大部分的业务也不会有太大的问题。这种方式相对第一种的可用性就大大提高。
- 只更新缓存,由缓存自己同步(异步)更新数据库
大致思路:当A请求来的时候,只对缓存做更新操作,然后后续的请求来的时候,获取到的都是最新的缓存中的值。这样子读请求的数据可以到达一致性。当A请求更新完缓存的时候,再又缓存自己去同步(异步)更新数据库。只不过需要对缓存进行专门的改造。同步的方式相对异步较好,因为异步的情况会存在如果在缓存异步将数据更新到数据库中时,缓存服务挂了,此时未更新到数据库中的数据就丢失了。
- 延时双删策略
这个的相关介绍应该就很多了,在做数据更新的操作时候执行,大致简单的思路就是:先删除缓存数据 ->再执行update更新数据库数据 ->最后(延时N秒)执行删除缓存 。
这里有一个问题其实还是会存在,就是关于延时时间的问题,因为如果延时太久可能导致程序卡主时间较长,但是最终结果肯定是更好的准确。但是在高并发情况下,是不允许的。如果时间太短,可能会导致数据库数据更新还未完成就已开始执行删除的操作。一般更新自己系统日常的允许运行时长,可以来自定义时间。这里给一个参考时间500ms。
总结
综上所述,其实没有绝对完美的方式来解决数据一致性的问题,只能说尽最大的可能来对数据库的一致性进行保障。如果系统有机会引入第三方的监测软件(例如canal)也是可以的,但是不建议引入额外第三方,不然部署和日常开发都会增加额外的成本。
Redis的数据如果像上面说的,真的会存在很频繁的更新操作其实也不建议放Redis,直接通过数据库来查询,毕竟数据的准确性重要程度远远大于时效性。
根据上面的分析,个人建议可以采用 第二种:先更新数据库,再删除缓存。第五种:延时双删策略



)

线程的实现)







)

)



