文章目录
- 前言
- C语言的字符串
- string
- string类的常用接口
- string类的常见构造
- string (const string& str);
- string (const string& str, size_t pos, size_t len = npos);
- capacity
- size和length
- reserve
- resize
- resize可以删除数据
- modify
- 尾插
- 插入字符
- 插入字符串
- insert
- erase
- replace
- 迭代器
- swap
- c_str
- find
- 反向迭代器
- const迭代器
- auto
前言
无论c++还是c语言,字符串都是最常见的类之一。我们日常当中写的程序必然要存储数据。
我们的内置类型只能表示基础的信息,无法表示一些复杂的信息,比如int, double.但我们要表示身份证、住址那就表示不了了。
C语言的字符串
C语言用字符数组来表示字符串,但是这里有一个巨大的缺陷。
1.不够好用
2.不能够很好的管理
比如:用字符数组来存储地址,但是地址的长度要修改呢?这就很麻烦。
所以c++提供了一个管理字符串的一个类,string,你可以把它想象成存储字符的顺序表。
string
string是一个类模板,它是typedef出来的。
string的底层是一个字符数组,但是你可以把它想象成可以增删查改的数组。
string类的常用接口
string类的常见构造
string (const string& str);
#include <string>
int main()
{string s2("hello world");for (size_t i = 0; i < s2.size(); ++i){s2[i]++;}cout << s2 << endl;for (size_t i = 0; i < s2.size(); ++i){cout << s2[i] << " ";}cout << endl;return 0;
}
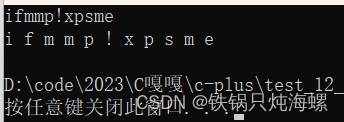
为什么可以这样构造?
string s1="hello world";
本质是类型转换,把const char* 转换成string.
它是先构造再拷贝构造,然后优化成了构造。
string (const string& str, size_t pos, size_t len = npos);
int main()
{string s3 = "hello world";string s4(s3, 6, 3);cout << s4 << endl;string s5(s3, 6, 13);//如果字符不够,有多少取多好cout << s5 << endl;return 0;
}
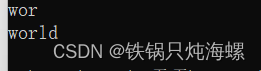
** 如果第三个参数不给呢?**
string s6(s3, 6);
这里给了一个参数,npos,并且npos=-1;
-1代表什么,这里其实是无符号,所以-1表示42亿九千万。
npos很大意味着取到结束
capacity
容量没有把’\0’算进去。
size和length
size和length有什么差异?
int main()
{string s3 = "hello world";cout << s3.size() << endl;cout << s3.length() << endl;return 0;
}
没有什么差异。
** 那为什么同时会有这两个东西呢?**
跟STL的发展历史有关。平时用size就可以了。
reserve
** 观察vs编译器的扩容情况**
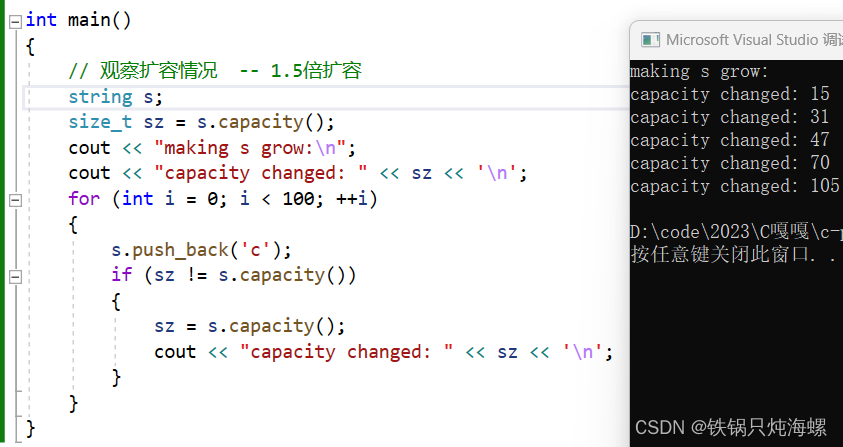
** 那假如我知道要开多少空间呢?**
我们可以调用这样一个接口,reserve
知道需要开多少空间,提前开空间,减少扩容,提高效率。
s.reserve(100)
注意,你要100的空间,它不一定给你100的空间,它可能为了一些对齐等等的原因,可能开的比100大一些。
resize
resize和reserve功能相似,但也有很大区别。
resize除了开空间它还帮助初始化
int main()
{string s1;s1.reserve(100);cout << sizeof(s1) << endl;cout << s1.size() << endl;cout << "--------------" << endl;string s2;s2.resize(100);cout << sizeof(s2) << endl;cout << s2.size() << endl;return 0;
}

那初始化填了什么值呢?
填的是0;
那我想填其他的值怎么办呢?
比size小,删除数据,保留前5个
s2.resize(100, 'x');
但是它不会缩容。
这里提一个点,为什么编译器不会轻易的缩容?
缩容其实是不支持原地缩的,原地缩荣的话,那以为这要delete一部分空间,这增加了内存管理的难度。
真正缩荣都是开好另一块空间,然后将需要保留的数据拷贝过去。这也意味着缩容肯定会带来性能上的消耗。一般来说不要轻易的缩容。
resize可以删除数据
s2.resize(5);
modify
string 最好用的地方就是不用去管空间。
尾插
插入字符
int main()
{string s3 = "hello world";s3.push_back(' ');s3.push_back('!');return 0;
}
插入字符串
s3.append("bit");
但是我们不管是插入字符还是插入字符串都不喜欢这样写,我们喜欢用运算符重载+=;
s3+=' ';
s3+='!';s3+='bit';
不过+=底层还是调用了push_back和append.
insert
如果我们再头部或者中间插入一个数据,我们就可以用insert;
int main()
{string s1("world");s1.insert(0, "hello");cout << s1 << endl;return 0;
}
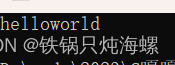
中间插入
int main()
{string s1("world");s1.insert(0, "hello");//s1.insert(5, 1, ' ');//s1.insert(5, " ");s1.insert(s1.begin() + 5, ' ');//迭代器位置cout << s1 << endl;return 0;
}

不推荐经常使用,能不用就不用。因为要挪动数据,影响性能。
erase
删除一个字符
int main()
{string s2("hello world");//s2.erase(5, 1);s2.erase(s2.begin() + 5);//迭代器位置cout << s2 << endl;return 0;
}
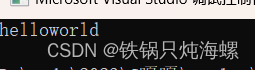
删除多个字符
int main()
{string s2("hello world");//s2.erase(5, 30);//如果要删除的数据大于字符串的剩余长度,那就相当于全部删完s2.erase(5);cout << s2 << endl;return 0;
}
不推荐经常使用,能不用就不用。因为要挪动数据,影响性能。
replace
将hello world 中间空格,替换成%%d
string s1("hello world");
s1.replace(5, 1, "%%d");
replace 能不用就不用,为什么?
1.空间不够就要扩容
2.需要挪动数据
有个题目,把hello world i love you 中的所有空格替换成%20
int main()
{string s1("hello world i love you");size_t pos = s1.find(' ');while (pos != string::npos){s1.replace(pos, 1,"%20");pos = s1.find(' ');}cout << s1 << endl;return 0;
}

那上面的代码能不能优化一下呢?
每次都是从0的位置开始找,其实没必要。
还有一个点就是,replace可能会扩容。
int main()
{string s1("hello world i love you");size_t num = 0;//计算有多少个' ',为开空间做准备for (auto ch : s1){if (ch == ' ')++num;}// 提前开空间,避免repalce时扩容s1.reserve(s1.size() + 2 * num);size_t pos = s1.find(' ');while (pos != string::npos){s1.replace(pos, 1, "%20");pos = s1.find(' ', pos + 3);}cout << s1 << endl;return 0;
}
再给大家看个好玩的东西
int main()
{string s1("hello world i love you");string newStr;size_t num = 0;for (auto ch : s1){if (ch == ' ')++num;}// 提前开空间,避免repalce时扩容newStr.reserve(s1.size() + 2 * num);for (auto ch : s1){if (ch != ' ')newStr += ch;elsenewStr += "%20";}s1 = newStr;cout << newStr << endl;return 0;
}

这个是以空间换时间的方式,不需要挪动数据。
迭代器
如果不用[]加下标怎么访问string对象呢,这里要用到迭代器。
int main()
{string s1("hello world");string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;return 0;
}
这个代码看起来有点懵,可以暂时先把迭代器理解为指针。
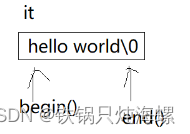
bein()表示第一个字符的地址,end()表示最后一个字符下一个位置的地址。
它是左闭右开。
其实还可以用范围for来访问,不过范围for的底层原理还是迭代器
for (auto ch : s1)
{cout << ch << " ";
}
cout << endl;
swap
看下面的代码有什么区别?
int main()
{string s1("hello world");string s2("xxxxx");s1.swap(s2);cout << s1 << endl;cout << s2 << endl;cout << "------------" << endl;swap(s1, s2);cout << s1 << endl;cout << s2 << endl;return 0;
}
s1.swap()和swap()有什么区别?
我们知道swap()是类模板,所有类型都可以交换,是泛型模板。
s1.swap()和swap()谁的效率高?
很明显s1.swap()的效率更高,s1和s2两段空间,只需要交换两段空间指针的指向就可以了。
而swap()要产生一个临时对象,需要调用拷贝构造,还是深拷贝,然后又需要两次赋值。
c_str
int main()
{string s1("hello world");cout << s1 << endl;cout << s1.c_str() << endl;return 0;
}
两者都可以打印数据,那它们的区别是什么?
s1.c_str()是遇到‘\0’结束,而cout << s1 << endl;则是根据s1.size()来打印的。
c_str的主要作用还是,为c的接口提供兼容
find
find其实前面已经见过了,再看一个例子,怎样取文件名的后缀。
int main()
{string file("string.cpp");size_t pos = file.find('.');if (pos != string::npos)//npos是静态成员变量,所以可以这样写,直接加上类域{string suffix = file.substr(pos, file.size() - pos);//substr表示从某个位置开始,取len字符长度的字符串string suffix = file.substr(pos);cout << suffix << endl;}return 0;
}
如果文件有多个点怎么样找后缀?
倒着找
size_t pos = file.rfind('.');
反向迭代器
除了正着访问string,还可以反着访问,这里要用到反向迭代器。
int main()
{string s1("hello world");string::reverse_iterator rit = s1.rbegin();while (rit != s1.rend()){cout << *rit << " ";++rit;}return 0;
}

const迭代器
写成这样为什么会报错?
void Func(const string& s)
{// 遍历和读容器的数据,不能写string::iterator it = s.begin();//报错这里赋值不过去while (it != s.end()){//*it += 1;cout << *it << " ";++it;}cout << endl;
}
int main()
{ string s1("hello world");Func(s1);return 0;
}
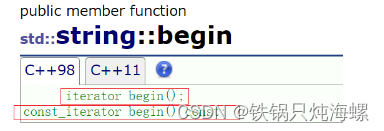
有两个版本,const对象返回const对象,普通对象返回普通对象。
所以很显然,应该改成const迭代器
string::const_iterator it = s.begin();//只能遍历和读取容器的数据,不能写
为什么要有返回const的迭代器呢?
不允许被修改。
普通迭代器和 const迭代器的区别?
能不能写的问题。
auto
正向的普通迭代器和const迭代器一共就有4种,我们可以用auto来优化一下迭代器的写法。
auto it = s.begin();
不过它也有一个弊端,降低了程序的可读性。








)








、int(20) 的区别到底在哪里)

