编译器和解释器
命令式编程使用诸如print、“+”和if之类的语句来更改程序的状态。 考虑下面这段简单的命令式程序:
def add(a, b):return a + bdef fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return gprint(fancy_func(1, 2, 3, 4))10
Python是一种解释型语言(interpreted language)。因此,当对上面的fancy_func函数求值时,它按顺序执行函数体的操作。也就是说,它将通过对e = add(a, b)求值,并将结果存储为变量e,从而更改程序的状态。接下来的两个语句f = add(c, d)和g = add(e, f)也将执行类似地操作,即执行加法计算并将结果存储为变量。
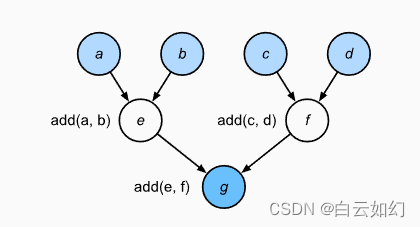
尽管命令式编程很方便,但可能效率不高。一方面原因,Python会单独执行这三个函数的调用,而没有考虑add函数在fancy_func中被重复调用。如果在一个GPU(甚至多个GPU)上执行这些命令,那么Python解释器产生的开销可能会非常大。此外,它需要保存e和f的变量值,直到fancy_func中的所有语句都执行完毕。这是因为程序不知道在执行语句e = add(a, b)和f = add(c, d)之后,其他部分是否会使用变量e和f。
符号式编程
考虑另一种选择符号式编程(symbolic programming),即代码通常只在完全定义了过程之后才执行计算。这个策略被多个深度学习框架使用,包括Theano和TensorFlow(后者已经获得了命令式编程的扩展)。一般包括以下步骤:
-
定义计算流程;
-
将流程编译成可执行的程序;
-
给定输入,调用编译好的程序执行。
这将允许进行大量的优化。首先,在大多数情况下,我们可以跳过Python解释器。从而消除因为多个更快的GPU与单个CPU上的单个Python线程搭配使用时产生的性能瓶颈。其次,编译器可以将上述代码优化和重写为print((1 + 2) + (3 + 4))甚至print(10)。因为编译器在将其转换为机器指令之前可以看到完整的代码,所以这种优化是可以实现的。例如,只要某个变量不再需要,编译器就可以释放内存(或者从不分配内存),或者将代码转换为一个完全等价的片段。下面,我们将通过模拟命令式编程来进一步了解符号式编程的概念。
def add_():return '''
def add(a, b):return a + b
'''def fancy_func_():return '''
def fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return g
'''def evoke_():return add_() + fancy_func_() + 'print(fancy_func(1, 2, 3, 4))'prog = evoke_()
print(prog)
y = compile(prog, '', 'exec')
exec(y)def add(a, b):return a + bdef fancy_func(a, b, c, d):e = add(a, b)f = add(c, d)g = add(e, f)return g print(fancy_func(1, 2, 3, 4)) 10
命令式(解释型)编程和符号式编程的区别如下:
-
命令式编程更容易使用。在Python中,命令式编程的大部分代码都是简单易懂的。命令式编程也更容易调试,这是因为无论是获取和打印所有的中间变量值,或者使用Python的内置调试工具都更加简单;
-
符号式编程运行效率更高,更易于移植。符号式编程更容易在编译期间优化代码,同时还能够将程序移植到与Python无关的格式中,从而允许程序在非Python环境中运行,避免了任何潜在的与Python解释器相关的性能问题。
)

----阅读《测斜仪旋转姿态测量信号处理方法》论文)





)




)





