1.Redis介绍
Redis 是 NoSQL,但是可处理 1 秒 10w 的并发(数据都在内存中) 使用 java 对 redis 进行操作类似 jdbc 接口标准对 mysql,有各类实现他的实现类,我们常用的是 druid 其中对 redis,我们通常用 Jedis(也为我们提供了连接池 JedisPool) 在 redis 中,key 就是 byteredis 的数据结构(value): String,list,set,orderset,hash
2.数据结构
1. 字符串 (String)
Redis中的字符串是二进制安全的,可以存储任何类型的数据,如文本、图片等。
使用场景:
缓存数据:存储经常访问的数据,以提高读取速度。 计数器:适用于统计网站访问量、用户点击次数等。 分布式锁:使用字符串实现简单的分布式锁机制。
2. 列表 (List)
有序、可重复的元素集合。
使用场景:
消息队列:通过LPUSH和RPUSH实现队列的入队和出队操作。 最新列表:保存最新的N条记录,如最新发布的文章列表。 分页数据:存储分页数据,以减轻数据库负担。
3. 集合 (Set)
无序、不重复的元素集合。
使用场景:
标签系统:每个标签是一个集合,用户可以属于多个标签。 共同好友:两个用户的共同好友可以用集合表示。 利用集合运算求交集、并集、差集等。
4. 散列 (Hash)
类似于字典,包含键值对的集合。
使用场景:
存储对象:将对象的字段存储为散列,方便读取和更新。 用户属性:存储用户的各种属性,如用户名、年龄等。 记录存储:适用于存储多个字段的数据。
5.有序集合 (Sorted Set)
数据结构: 有序的元素集合,每个元素都有一个分数。
使用场景:
排行榜:根据分数排序,适用于游戏中的用户排名等场景。 范围查找:根据分数范围查找元素,如查找指定区间内的文章。 唯一性成员:确保集合中的成员唯一。
3.为什么 redis 是单线程的都那么快
3.1 内存存储和异步操作:
Redis主要将数据存储在内存中,这极大地加快了数据的读写速度。此外,Redis采用异步操作模式,将部分耗时的操作如持久化写操作(RDB快照、AOF日志)等交给后台线程处理,主线程则继续处理其他请求。
3.2 非阻塞 I/O:
Redis使用了非阻塞的I/O多路复用机制,主线程通过 epoll 或 select 监听多个套接字,当其中一个套接字准备好数据时,主线程即可快速切换到该套接字进行读写操作,从而充分利用 CPU 资源。
3.3 避免了多线程的竞态条件:
单线程模型避免了多线程的竞态条件和锁的开销。在多线程环境下,为了保证数据一致性,需要使用锁,而锁的使用可能导致性能下降。Redis通过单线程模型避免了这一问题,简化了代码复杂度。
3.4 持久化策略的灵活选择:
Redis允许用户选择不同的持久化方式(如RDB快照、AOF日志),用户可以根据自己的需求选择适合的方式,以达到一定的持久化要求,而不是强制性地进行同步持久化。
3.5 高效的网络模型:
Redis采用基于事件驱动的网络模型,使用了非阻塞的套接字和异步的事件处理机制,能够在处理大量连接时保持较低的延迟。
4.redis数据持久化
4.1 RDB快照
在默认情况下,Redis将内存数据库快照保存在名字为dump.rdb 的二进制文件中。你可以对Redis进行设置,让它在“N秒内数据集至少有M个改动”这一条件被满足时,自动保存一次数据集。 比如,以下设置会让Redis在满足“60秒内有至少有1000个键被改动”这一条件时,自动保存一次
save 60 1000
//关闭RDB只需要将所有的save保存策略注释掉即可
还可以手动执行命令生成RDB快照,进入redis客户端执行命令save或bgsave可以生成dump.rdb文件,每次命令执行都会将所有redis内存快照到一个新的rdb文件里,并覆盖原有rdb快照文件。
bgsave 子进程是由主线程fork 生成的,可以共享主线程的所有内存数据.bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果主线程对这些数据也都是读操作,那么,主线程和 bgsave 子进程相互不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
优点: 是一个紧凑压缩的二进制文件,Redis 加载 RDB 恢复数据远远快于 AOF 的方式。
缺点: 由于每次生成 RDB 开销较大,非实时持久化
4.2 AOF (append-only file)
快照功能并不是非常耐久 (durable) : 如果 Redis 因为某些原因而造成故障停机,那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。从 1.1 版本开始,Redis 增加了一种完全耐久的持久化方式: AOF 持久化,将修改的每条指今记录进文件appendonly.aof中(先写入o cache,每隔一段时间fsync到磁盘)
可以通过修改配置文件来打开AOF功能:
appendonly yes
可以配置Redis多久才将数据同步到到磁盘一次。
appendfsync always; #每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全
appendfsync everysec: #每秒 fsync 一次,足够快,并且在敌障时只会丢失 1 秒钟的数据(默认-推荐)
appendfsync no: #从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
优点: 实时持久化。
缺点: 所以 AOF 文件体积逐渐变大,需要定期执行重写操作来降低文件体积, 加载慢
5.主从模式

概述:
主从复制,是指将一台 Redis 服务器的数据,复制到其他的 Redis 服务器。前者称为主节点(Master),后者称为从节点(Slave);数据的复制是单向的,只能由主节点到从节点。 默认情况下,每台 Redis 服务器都是主节点;且一个主节点可以有多个从节点 (或没有从节点),但一个从节点只能有一个主节点
优点 数据冗余备份,提高数据可靠性。 读写分离,提高系统性能。 缺点 无法自动进行故障转移,主节点发生故障,需要手动切换主节点。 主节点承担所有写操作,性能可能会遇到瓶颈 数据没有分布式存储,节点内存要求过高。
主节点挂了,单纯的主从模式,无法实现故障转移。需要利用下述的哨兵进行故障转移
6.哨兵模式
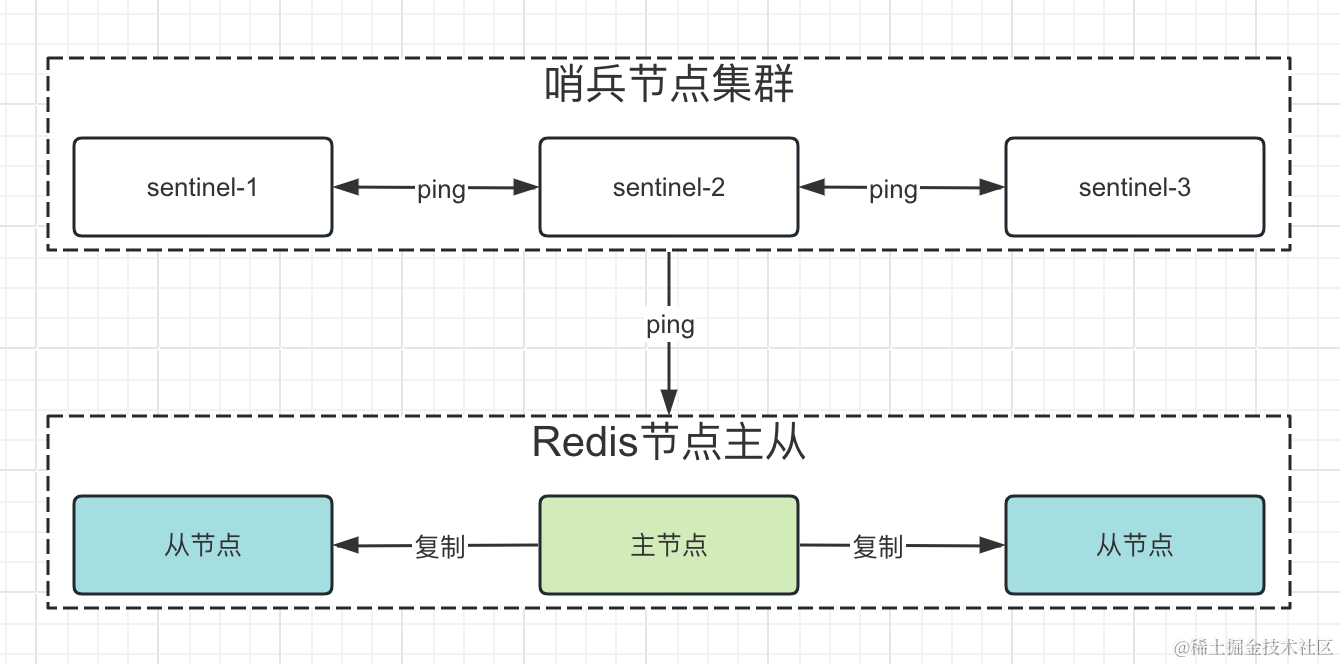
 (2.8 版本或更高才有) sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息) 优点 主从模式的基础之上,增加自动故障转移 缺点 数据没有分布式存储,节点内存要求过高。
(2.8 版本或更高才有) sentinel哨兵是特殊的redis服务,不提供读写服务,主要用来监控redis实例节点。哨兵架构下client端第一次从哨兵找出redis的主节点,后续就直接访问redis的主节点,不会每次都通过sentinel代理访问redis的主节点,当redis的主节点发生变化,哨兵会第一时间感知到,并且将新的redis主节点通知给client端(这里面redis的client端一般都实现了订阅功能,订阅sentinel发布的节点变动消息) 优点 主从模式的基础之上,增加自动故障转移 缺点 数据没有分布式存储,节点内存要求过高。
6.1 定时监控任务
- 每隔 10s,每个 S 节点( 哨兵节点)会主节点和从节点发送 info 命令获取最新的拓扑结构
- 每隔 2s,每个 S 节点会向某频道上发送该 S 节点对于主节点的判断以及当前 SI 节点的信息, 同时每个 Sentinel 节点也会订阅该频道,来了解其他 S 节点以及它们对主节点的判断(做客观下线依据)
- 每隔 1s,每个S 节点会向主节点、从节点、其余 S 节点发送一条 ping 命令做一次心跳检测(心跳检测机制),来确认这些节点当前是否可达
6.2 主客观下线
- 主观下线:根据第三个定时任务对没有有效回复的节点做主观下线处理
- 客观下线: 若主观下线的是主节点,会咨询其他 S 节点对该主节点的判断超过半数,对该主节点做客观下线
6.3 选举出某一哨兵节点作为领导者,来进行故障转移。
选举方式 :raft算法。每个 S 节点有一票同意权,哪个 S 节点做出主观下线的时候,就会询问其他 S 节点是否同意其为领导者。获得半数选票的则成为领导者。基本谁先做出客观下线,谁成为领导者。
6.4 故障转移
S节点的领导者会进行故障转移操作。 当Redis主节点挂了,哨兵集群会重新选举出新的Redis主节点,同时会修改所有sentinel节点的配置文件的集群元数据信息。其中会包括主节点的从节点信息,感知到的其他哨兵节点信息,以及当前主节点信息。
- 执行命令slaveof no one关闭复制,从节点变更为主节点。
- 其余从节点slaveof new master变更成新的master的从节点。
- notice client:故障转移后sentinel结点会将结果通知给客户端(应用方)。
- 原主节点恢复后变成从节点去复制新的主节点信息。
6.5 哨兵环境搭建
环境准备
实例说明,一主两从一哨兵。单机上装3台Redis一个哨兵。也可以分多多机器进行
主:6379
从:6380、6381
哨兵:26379
6379配置文件参考
#修改绑定的ip地址,绑定后,只有此ip才能够访问redis
bind 0.0.0.0
#端口号
port 6379
#保护模式修改为否,允许远程连接
protected-mode no
#后台运行
daemonize yes
#设定访问密码
requirepass 123456
#设定主库密码与当前库密码同步,保证从库能够提升为主库。(与主库的requirepass一致)
masterauth 123456
#打开AOF持久化支持
appendonly yes
#进程守护文件
pidfile "/var/run/redis_6379.pid"
#db等相关文件目录位置(替换成自己的目录)
dir "../redis-sentinel"
#日志目录(替换成自己的目录)
logfile "../redis-sentinel/log6379.log"
6380、6381配置与6379配置雷同,把端口号及一些进程守护文件等做一些区分即可。但是还需要在增加一个配置
#将6379配置为该从节点的主节点
replicaof 127.0.0.1 6379
启动三台Redis并查看Redis进程
liswdeMBP:bin lisw$ ps -ef |grep redis501 48167 1 0 10:17上午 ?? 0:18.96 ./redis-server *:6380 501 48174 1 0 10:17上午 ?? 0:19.52 ./redis-server *:6381 501 49266 1 0 10:37上午 ?? 0:17.01 ./redis-server *:6379
liswdeMBP:bin lisw$
登录6379,查看主从状态
liswdeMBP:bin lisw$ ./redis-cli -a 123456 -h 127.0.0.1 -p 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.50.130,port=6380,state=online,offset=602,lag=1
slave1:ip=192.168.50.130,port=6381,state=online,offset=588,lag=1
master_failover_state:no-failover
master_replid:3c459593935c380cc4647d6214a751f6f79ac1dd
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:602
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:602
127.0.0.1:6379>
哨兵节点环境搭建
修改sentinel.conf文件,关键配置如下:
# redis sentinel配置文件
#配置监听的主节点,masterRedis为服务名称,可以自己定义。192.168.50.130为主节点的ip,6379为主节点的名称,1代表有一个或者一个以上的哨兵认为主节点不可用时,则进行选举操作
sentinel monitor masterRedis 192.168.50.130 6379 1
#设置主节点的访问密码
sentinel auth-pass masterRedis 123456
# 关闭保护模式,只有关闭之后,才能远程连接
protected-mode no
# 哨兵端口
port 26379
# 哨兵数据存放位置
dir "/Users/lisw/work/work-tools/redis-6.2.7/redis-sentinel/sentineldata"
# 日志文件
logfile "../redis-sentinel/sentinellog.log"
# 以守护进程运行
daemonize yes
# 进程ID保存位置
pidfile "/var/run/redis-sentinel-26379.pid"
# 设置sentinel的访问密码
requirepass "123456"
如果哨兵节点与主节点在同一台ip时,配置sentinel monitor时不要使用127.0.0.1,否则可能会有问题。
最后启动哨兵节点即可
liswdeMBP:bin lisw$ ./redis-sentinel ../redis-sentinel/sentinel.conf
7.集群模式
Redis Cluster,是Redis 3.0开始引入的分布式存储方案。集群由多个Redis节点组成,数据也是进行分布式存储在不同的节点上的。节点划分为主节点与从节点,主节点负责读写请求的处理以及集群状态的维护。从节点负责从主节点进行数据的复制。

优点 数据分布式存储,单节点压力过小,可实现大规模数据存储。 负载均衡,提高性能。 高可用故障自动转移。 缺点 配置和管理较复杂 一些复杂的多键操作可能受到限制
7.1 数据分片存储的原理
Redis集群有16384个哈希槽(编号0-16383),集群的每组节点负责一部分哈希槽 每个Key通过CRC16校验后对16384取余来决定放置哪个哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
三个主节点各自有一个从节点,其中一个主节点不可用以后,对应的从节点会成为主节点继续服务。如果对应的从节点也不可用,那么整个集群将不可用。
7.2 集群环境搭建
环境准备
按照单机版的redis进行编译及安装redis。
实例说明,三主三从
192.168.0.10 6380、6381、6382
192.168.0.11 6380、6381、6382
两台机器的redis分别复制redis.conf配置文件各形成3份,分配修改3个配置文件。关键信息如下: 这里是把redis可执行文件安装到了redis目录中。编译redis的时候执行的命令如下:
cd /opt/redis-6.2.7
make
make install PREFIX=/opt/redis-6.2.7
6380配置文件参考
#修改绑定的ip地址,绑定后,只有此ip才能够访问redis
bind 0.0.0.0
#端口号
port 6379
#保护模式修改为否,允许远程连接
protected-mode no
#后台运行
daemonize yes
#设定访问密码,所有节点需要一直
requirepass enginex123
#访问主库时的密码
masterauth enginex123
#打开AOF持久化支持
appendonly yes
#进程守护文件
pidfile "/var/run/redis_6380.pid"
#db等相关文件目录位置(替换成自己的目录)
dir "../redis-cluster"
#日志目录(替换成自己的目录)
logfile "../redis-cluster/log6380.log"
#开启集群
cluster-enabled yes
#集群节点文件,自动生成的。
cluster-config-file nodes-6380.conf
#集群节点之前的连接超时时间
cluster-node-timeout 15000
6381、6382配置与6380配置雷同,把端口号及一些进程守护文件等做一些区分即可。
启动节点并查看服务进程
./redis-server ../redis-cluster/6380/redis-6380.conf &
./redis-server ../redis-cluster/6381/redis-6381.conf &
./redis-server ../redis-cluster/6382/redis-6382.conf &
[root@master ~]# ps -ef |grep redis
root 11162 1 0 09:33 ? 00:00:24 ./redis-server 192.168.0.10:6380 [cluster]
root 11189 1 0 09:33 ? 00:00:24 ./redis-server 192.168.0.10:6381 [cluster]
root 11215 1 0 09:33 ? 00:00:25 ./redis-server 192.168.0.10:6382 [cluster]
另外一台机器,按照同样方式进行启动。
创建集群
./redis-cli -a 123456 --cluster create 192.168.0.10:6380 192.168.0.10:6381 192.168.0.10:6382 192.168.0.11:6380 192.168.0.11:6381 192.168.0.11:6382 --cluster-replicas 1
-a 为Redis的节点密码
–cluster-replicas 1 代表 一个master后有几个slave,1代表为1个slave节点
过程中会提示以下内容,输入 yes 继续。 自此集群环境搭建完毕
验证
连接任意一台redis,输入cluster nodes
[root@iZuf643dnnz46hhj1s4ttbZ bin]# ./redis-cli -c -h 192.168.0.148 -p 6380 -a enginex123
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.0.148:6380> cluster nodes
a5c37c5392a2183d917b97e2e9dc357c537245e1 192.168.0.142:6381@16381 master - 0 1667898025618 2 connected 10923-16383
395205d531c6e4cf5f9feb8c78e2881252f1e5a6 192.168.0.142:6382@16382 slave 1dc115668298557846ad8dfa48aeb4784fb8a8f5 0 1667898026620 4 connected
5687fbf444b734bd98a040dd8686993b7af61109 192.168.0.148:6382@16382 slave f3de8d817b8648d97ed74537b690d394825bfa29 0 1667898027000 1 connected
f3de8d817b8648d97ed74537b690d394825bfa29 192.168.0.142:6380@16380 master - 0 1667898025000 1 connected 0-5460
e67d6f23088f1e9d4c246f3a7293f2012a5eac1c 192.168.0.148:6381@16381 slave a5c37c5392a2183d917b97e2e9dc357c537245e1 0 1667898027622 2 connected
1dc115668298557846ad8dfa48aeb4784fb8a8f5 192.168.0.148:6380@16380 myself,master - 0 1667898025000 4 connected 5461-10922
192.168.0.148:6380>
8.缓存过期策略
过期策略是 Redis 用来处理过期键的一种机制。当 Redis 中的键值对设置了过期时间后,在过期时间到达时,会自动触发过期键删除策略,将过期的键值对删除以释放内存空间。
- 定时删除策略:每个设置了过期时间的 key 都会创建一个定时器(timer),当时间到期时,这个 key 将会被自动删除。
- 惰性删除策略(默认):只有当对 key 进行操作时,才会检查该 key 是否过期,如果过期则删除。
- 定期删除策略(默认):每隔一段时间,程序会对过期键进行扫描,删除过期键。这种策略是惰性删除策略的补充,因为有些过期键可能会在惰性删除策略中被忽略。
- 随机删除策略:Redis 将设置过期时间的 key 放在一个字典中,并设置一个虚拟时间,每次随机删除字典中的一部分过期 key。这种策略可以避免在同一时间点过多的 key 过期而导致 Redis 阻塞。
9.内存淘汰策略
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- volatile-lru(默认):当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
可通过修改配置文件,进行配置内存淘汰策略
#配置淘汰策略为,内存不足,写入数据操作会报错。
maxmemory-policy noeviction
10.缓存穿透,击穿,雪崩
10.1 缓存穿透
查询一个一定不存在的数据,如果从DB查不到数据则不会写入缓存,这将导致这个不存在的数据每次请求都要到 DB 去查询,这个过程我们成为缓存穿透。
解决方案:
1.空数据仍然进行缓存,可缩短缓存时间。 2.利用布隆过滤器,将所有可能存在的数据存在Reids的BigMap中,一定不存在的数据,会被BigMap拦截掉,从而达到无法进入DB查询的目的。
10.2 缓存击穿
对于设置了过期时间的 key,缓存在某个时间点过期的时候,恰好这时间点对这个 Key 有大量的并发请求过来,这些请求发现缓存过期,会从DB 加载数据并存储到缓存,大并发的请求全部到DB,这个情况称为缓存击穿。
解决方案:
1.使用锁,防止大量请求进入DB得到数据在存储到Redis。 2.设置永不过期。可以单独开辟人物去刷新这些永不过期的数据做过期逻辑
10.3 缓存雪崩
设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部到 DB,DB 瞬时压力过重雪崩。与缓存击穿的区别:雪崩是很多 key,击穿是某一个key 缓存。
解决方案:
将缓存失效时间分散开,比如可以在原有的失效时间基础上增加一个随机值, 比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效 的事件。
分号问题)











)
:JSON 序列化和反序列化(json 模块))





)