1. 深度学习基础与MLP
1.1 框架:
线性回归;
Softmax回归(实际上用于分类问题);
感知机与多层感知机;
模型选择;
权重衰退(weight decay);
丢弃法(drop out);
数值稳定性;
神经网络基础
1.2 知识点:
pytorch本身会梯度累加,因此在多次计算梯度时需将梯度归0;
pytorch中结尾带下划线的method的作用通常为覆盖当前值,如normal_(0, 0.01);
batchsize越小,相当于网络输入的噪声越大,模型训练效果越好;
lr和batchsize一般不会影响最终收敛效果,只是可能耗时更久;
当样本大小不是batchsize整数倍时,可以取更小的batchsize,或舍弃多余的样本、或从下个epoch中预取出一些;
判断收敛:两个epoch间loss变化不大(1%),或验证数据集精度不增加。多训练一点也没关系,虽然数值不变,但可能内部在微调;
pytorch网络层定义时会自动带有参数初始值;
回归输出为连续数值(单个),分类输出为每一类别的置信度(多个);
用交叉熵衡量两概率区别;
分类问题只关心正确类的预测值(置信度),见交叉熵公式(但有时会指定多个目标类别);
num_workers为用于读取数据(从硬盘上读取,预读取等)的进程数量;
训练前需要检查数据读取速度,与CPU性能有关,最好比训练快很多;
*args allows a function to accept a variable number of positional arguments, and *args can also be used when calling a function to unpack a sequence and pass its elements as individual arguments;
展平层(flatten)的作用就是把矩阵第0维度保留,展为2D tensor;
Softmax回归的输出层是一个全连接层(Linear,线性层 ),softmax及其对数的计算都是在CrossEntropyLoss()中实现的;
多层感知机即在感知机基础上增加隐藏层,采用激活函数(必须为非线性),得到非线性模型,且可用于多类分类问题;
激活函数主要用于避免层数塌陷,即其本质上为引入非线性,不同函数的选择本质上没有太大区别;
多层感知机=Softmax回归+隐藏层;
隐藏层大小设置:一般来讲,根据数据复杂度,越复杂m1层越大,甚至m1层维度可以比输入多,但后序必须逐渐减小(压缩);多层网络相比单层网络每层的神经元数可以少一些;
输入与参数的乘积一般采用X@W+b的形式;
模型更大,数据拟合性会更好,损失会下降,但测试集精度不一定会上升;
MLP相较于SVM在代码层面好调整,其本身甚至可以理解为一种编程语言,但SVM对超参数不敏感,数学性更好;两者最终性能差不多;
一层神经网络包含:权重(箭头)+激活函数+计算;
理论上,一层隐藏层可以拟合任意函数,但实际做不到,优化方法解不了;
同样的网络复杂度,更深的模型比更宽的模型好训练,因为不需要同时并行过多神经元,且可以每层学习一个简单任务;所以一般会增加网络层数,而不是增加神经元个数;
模型深度/宽度的选择:1)先试无隐藏层的线性模型;2)再试单隐藏层,设置不同的神经元个数;3)再增加隐藏层,根据上一步结果进行设置。如此不断复杂;
训练误差与泛化误差分别为在训练数据和新数据上的误差;
训练数据集:训练模型参数;验证数据集:拿出部分(如50%)训练数据,不训练,只评估模型超参数好坏;测试数据集:只用一次,最终测试模型泛化性能;推荐比例:6:2:2;
K-则交叉验证(k-fold cross-validation):没有足够多数据时,将训练数据分为K(常用5或10)块,For i = 1,..., K,使用第i块作为验证数据集,其余作为训练数据集,训练K次(同一超参数得到K次不一样的模型参数),报告K个验证集误差的平均;K越大效果越好,但计算也更贵;
K-则交叉验证应用方法:1)取K折中表现最好的超参数,再在整个训练+验证数据集上训练一遍,作为最终模型进行测试;2)直接取K折中表现最好的模型为最终模型进行测试,较简单但少看了一部分数据;3)对K折训练出的所有模型进行测试,测试精度做平均,相当于做了voting,增加模型稳定性(每个模型都有偏移,多个模型平均可以降低其方差);
模型容量:拟合各种函数的能力
估计模型容量:对于相同种类算法:1)参数个数;2)参数值的选择范围;
深度学习核心:首先拥有大的模型容量,再对其进行控制使泛化误差下降;
VC维(VC dimension):统计机器学习中,对于一个分类模型,VC等于一个最大的数据集的大小,不管如何给定标号,都存在一个模型来对它进行完美分类;作用:提供为什么一个模型好的依据,可以衡量训练误差和泛化误差之间的间隔,但深度学习中很少使用,因为衡量不很准确且计算困难;
数据复杂度:1)样本个数;2)每个样本的元素个数;3)时间、空间结构;4)多样性;
超参数选择:1)老中医;2)从所有可能的排列组合中随机100次,取验证数据集上效果最好的那个;
类别比例差距很大的问题在验证时,两个类别的数据最好为1:1,防止模型过于注重占比较大的那一类数据,但如果现实世界也差别很大那就无需调整了,关注更重要的部分是合理的;还可以在loss中对小占比部分提高权重;
所有深度学习模型不做泛化和正则化等的话,都有可能是无限VC维的;
神经网络本质上还是MLP,理论上MLP可以解决所有问题,只是训练不出来;CNN和RNN等其实只是告诉模型要怎样处理信息,帮助其更好地进行训练;
权重衰退:为处理过拟合,限制参数值选择范围来控制模型容量,使用均方范数作为硬/柔性限制,硬性即单独subject to,柔性即对loss加一penalty(对w进行L2范数惩罚,通常不限制b),调整超参数λ(一般取e-3);从参数更新法则层面理解:每次参数更新时都会先对当前w乘一小于1的数(1-ηλ)进行放小,再减去学习率乘loss梯度;
数据都有固定噪音,因此总是会学到比数学最优解的值更大的模型参数,所以权重衰退不会起负作用;且使用有随机噪音的数据等价于Tikhobov正则,增强模型对输入数据的扰动鲁棒;
丢弃法:在层之间无偏差(前后期望相等)地加入随机噪音,即将一些输出项随机置0,是一种正则项,只在训练中使用;通常作用于多层感知机的隐藏层输出上;p一般取0.1,0.5或0.9;

正则项作用:控制模型复杂度,防止过拟合;
梯度爆炸:值超出值域,对学习率敏感;
梯度消失:梯度值变成0,不管如何选择学习率训练没有进展,对底部层尤为严重(梯度爆炸与消失都是由于多个矩阵连乘使得梯度更新时次幂过高产生的);
让训练更稳定:使梯度值在合理范围内(如[1e-6,1e3]):1)将乘法变加法;2)归一化;3)合理的权重初始和激活函数;
Xavier初始:可适配权重形状变换;
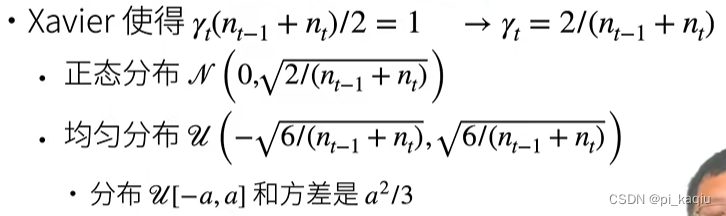
数值稳定性:通过合理地分配权重初始值(Xavier,训练开始时更容易数值不稳定)和选取激活函数(relu,tanh和变换后的sigmoid,有在原点附近时满足f(x) = x)使每一层的输出和梯度均值为0,方差为一固定数
训练出问题解决方式:如准确率奇怪变化,或出现nan(除0)或inf(过大),先尝试一直减小学习率,不然就是模型数值稳定性出了问题;
输出值太大 -> 梯度爆炸;sigmoid激活函数 -> 梯度消失?
定义层和块:通过继承nn.module可以进行非常灵活的模型构造(def __init__(self):)(def forward(self, X):);这里nn.module将python built-in的__call__(self, X)定义为forward(self, X)了;
得到网络所有参数的字典:net.state_dict();
参数绑定:定义并公用shared = nn.Linear(8, 8)层
应用初始化:net.apply()
定义自带参数的层:用nn.Parameter()把数值包起来即可
torch.save和torch.load只能保存和加载网络参数,不能保存网络定义
使用CPU:torch.device("CPU");使用GPU:torch.cuda.device("cuda"), torch.cuda.device("cuda:1");默认使用CPU
将张量存储在GPU上:X = torch.rand(2, 3, device = try_gpu(1));
将网络copy到GPU上:net = net.to(device = try_gpu());
GPU满负荷没问题,主要看温度(不要超过80度太久),90度以上时CPU会自动降频保护,容易烧cuda和GPU关系:GPU为硬件,cuda为SDK;
2. 卷积神经网络
2.1 框架
卷积神经网络
填充(padding)和步幅(stride)
多输入多输出通道
池化层
LeNet
AlexNet
VGG
NiN
GoogLeNet
批量归一化(Batch Normalization)
ResNet
数据增广(强)
微调(Fine-tuning)(Transfer Learning,迁移学习)
目标检测
锚框(Anchor Box)
序列模型
语言模型
RNN(Recurrent Neural Network)
门控循环单元(Gated Recurrent Unit, GRU)
长短期记忆网路(Long short-term memory, LSTM)
深度循环神经网络
双向循环神经网络
机器翻译与数据集
编码器-解码器架构
序列到序列学习(seq2seq)
束搜索(Beam Search)
注意力机制(Attention Mechanism)
使用注意力机制的seq2seq
自注意力(Self-Attention)和位置编码(Position Encoding)
Transformer
BERT预训练
转置卷积(Transposed Convolution)
2.2 知识点
卷积是一个特殊的全连接层;对全连接层使用平移不变性和局部性得到卷积层;
卷积层实际计算使用的是交叉相关;

卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出。因为核大小是固定的,永远看的是核大小范围内的数据,因此无论输入(维度)多大,都不会像MLP那样让参数(维度)变得特别大;
填充:在输入周围添加额外的行/列,来控制输出形状的减少量。当图像较小时,不想让卷积层将图像减小过快,从而可以使用较深的模型;代码中的padding一般指“一边”填充的大小;

步幅:每次滑动核窗口时的行/列步长,可成倍减少输出形状。当图像较大时,使图像以加倍的速度减小,从而减少计算量;一般只要填充取得好,高宽为偶数,步幅为2,可将步幅直接视为将图像缩小一倍;

无论卷积核多大,模型最后一定能看到整张图像的信息;
NAS (neural-network architecture search):训练超参数,自动机器学习;如果是正常情景的话,没必要使用,直接用经典的就好;
Autogulon:可以自动调参深度神经网络,但特别贵;
信息/特征永远是要丢失的,机器学习本质上就是一种极端的压缩算法;
验证集做得比较好的话,过拟合一般可以被避免;
卷积核越小,计算复杂度越低,计算越快;
一个特定的卷积层可以匹配一个特定的纹理;
深度学习相对传统方法:对数据和人的要求更小,更经济;
随着网络深入,特征由局部底层到整体;
输入通道:RGB 3个,为前一卷积层的超参数,卷积层运算时需要融合多输入通道;
输出通道:为当前卷积层的超参数;通道设置太多容易过拟合;
1x1卷积层:只看一个像素,不识别空间模式,只融合通道,相当于权重为的全连接层;处理时将输入拉成多通道的1维向量即1个2维矩阵,原本4维的K省略最后的1x1维转换为2维矩阵,进行矩阵间惩罚,最后对输出维度进行复原;
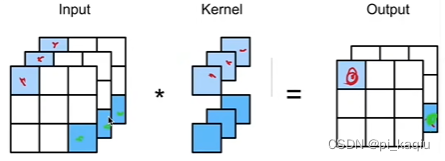

二维卷积层:计算量不小;模型较小,只需存个参数;

输入输出(feature map)高宽都减半时,通常会将输出通道多加一倍;
池化层:返回滑动窗口中的最大(平均)值,可容像素移位,缓解卷积层对位置的敏感性,且可在一定程度上减少计算量,并防止卷积层受;具有窗口大小、填充和步幅,输出通道数=输入通道数;默认stride就是其大小;
池化层应用减少的原因:1)可以用带有stride的卷积层替代池化层;2)数据增强同样可以防止卷积层在图像某些具体位置上过于位置敏感而产生过拟合;
LeNet:卷积层(学习图像空间信息)+ 池化层(降低位置敏感度) + 卷积层 + 池化层 + 2个全连接层 + 输出层(转换类别空间);识别check上的手写数字;
卷积层后面也是要加激活函数的,即卷积+激活+池化;
相较于MLP,CNN模型复杂度小,不容易过拟合;
CNN结束后需要Flatten成向量再输入至MLP中;
CNN本质上是将输入的空间信息不断压缩,并将压缩后的信息存入越来越多的通道中;虽然其通道即pattern数在增大,但总体而言,压缩终归是会有信息损失的;
AlexNet相较于LeNet改进:更深更大;丢弃法;ReLu;MaxPooling;
核方法与深度学习区别:核方法进行人工特征提取,再通过SVM分类;深度学习通过CNN学习特征,再通过Softmax回归转换为分类概率,即端到端地实现;
VGG相较于AlexNet改进:更深更大;提出模块概念,构建重复的VGG块;
NiN相较于之前网络改进:使用1x1卷积层代替全连接层为像素提供非线性性,构成NiN块;使用全局平均池化代替最后分类的全连接层;参数更少,不容易过拟合;
Inception块(v1):4个路径从不同层面抽取信息,然后在输出通道维合并。其中白色1x1卷积是用来变换通道数的,减小模型复杂度;蓝色是在真正提取信息的,1x1提取通道信息,其他提取空间信息;以上所有可使Inception块在增加多样性的同时有更少的参数个数和计算复杂度;
Inception块变革:1)v2:使用batch normalization;2)v3:修改了Inception块,5x5 → 2个3x3,5x5 → 1x7和7x1,3x3 → 1x3和3x1,更深;3)v4:使用残差连接;
GoogLeNet:一次高宽减半就是一个stage;第一个达到上百层的网络(通过并行);其中v3和v4现在还是很常用;
批量归一化起因:靠近损失处梯度较大,靠近数据处梯度较小(较小的数连乘) → 靠近损失处收敛快,靠近数据处收敛慢。但由于靠近数据处学的是底层特征,靠近损失处学的是高层特征,即便靠近损失处训练好了,底层特征一变,又要重新开始训练,因此总体收敛较慢 → 如何在学习底部层的时候避免变化顶部层。
BN实现:固定小批量里面的均值和方差,然后再做额外的调整(可学习的参数),即标准正态分布之外的均值与方差(学习出的是和的偏移和缩放)。
BN作用方式:作用在:1)全连接层和卷积层输出上,激活函数前;2)全连接层和卷积层输入上。区别:1)对全连接层,作用在特征维;2)对卷积层,作用在通道维(所有像素当样本,同一像素的多个通道为特征,通道层是卷积层的一个特征维)(可联想至样本维与特征维组成的二维矩阵更加直观)
BN本质:可能是在每个小批量内加入噪音(非学习的随机偏移和随机缩放,即随机选取的小批量内样本的均值和方差)来控制模型复杂度;若按此思路来讲,则没必要与dropout混合使用;
BN作用:加速收敛速度(各层输入输出均在一个稳定分布的范围内,因此可以选用较大的学习率,底层与顶层共同快速收敛),但一般不改变模型精度;
ResNet: 类似VGG和GoogLeNet的总体框架,但替换成了ResNet块。ResNet152指有152个卷积层;Residual conection。使得很深的网络更加容易训练(模型性能不会更差,且先会优先训练小模型,再逐步过渡到大模型),甚至可以到1000层;
ResNet处理梯度消失:将乘法处理为加法,使得无论网络多深,底层总是可以拿到较大的梯度进行参数更新;
残差块:卷积 + BN + ReLu + 卷积 + BN + ReLu,然后在任意处跳跃连接至任意处。
数据增强:对已有数据集进行操作,使其有更多的多样性,如再语言里面加入各种不同的背景噪音,改变图片的亮度、颜色、截取部分大小和形状等;从原始数据读图片,随机进行在线生成,接着使用增强后数据训练模型,类似于正则项(仅训练时使用)。
数据增强方法:1)翻转:左右翻转、上下翻转(不总是可行);2)切割:从图像中切割一块,然后变形到固定形状。随机高宽比(3/4到4/3)、随机大小(8%到100%)、随机位置;3)颜色:改变色调、饱和度、明亮度(0.5到1.5);4)几十种其他方法(https://github.com/aleju/imgaug).要根据实际场景需求确定采用的方法类型。
一个神经网络可分为两块:1)特征提取:将原始像素变成容易线性分割的特征;2)线性分类器:如Softmax回归;
微调概述:即如何初始化模型权重。是一个正常训练任务,但采用了更强的正则化:更小的学习率,更少的数据迭代。
微调方法:1)重用特征提取权重:利用在源数据集上训练得到的预训练模型特征提取部分的参数对当前模型特征提取部分进行参数初始化,线性分类器部分完全随机初始化,进而在目标数据集上训练;2)重用分类器权重:在源数据集也有目标数据集中部分标号时,可使用预训练模型分类器中对应标号对应的向量来初始化;3)固定一些层: 神经网络通常学习有层次的特征表示,低层次特征更通用,高层次特征更跟数据集相关;可固定底部一些层参数,不参与更新,相当于更强的正则。
目标检测与图片分类:图片分类只关注主体;目标检测需要识别出图像中所有感兴趣的物体,并找到它们的位置。目标检测需要对一张图像中的多个目标分别进行多次人工框选取均值,数据集标注成本较高,因此通常数据集比图片分类小;
边缘框(Bounding Box):由4个数字定义:(左上x,左上y,右下x,右下y)或(左上x,左上y,宽,高)。表示真实值。
锚框(Anchor Box):表示预测值。一类目标检测算法是基于锚框:提出多个被称为锚框的区域 → 预测每个锚框里是否含有关注的物体 → 如果是,预测从这个锚框到真实边缘框的偏移;
数据集:图片分类:1)csv文件:一张图片,对应一个标号;2)文件夹:每个类放在一个文件夹下。常用ImageNet。目标检测:文本文件,每一行表示一个物体,包含图片文件名、物体类别、边缘框(共6个值)。常用COCO(cocodataset.org)
IoU(Intersection over Union,交并比):计算两框之间的相似度,0表示无重叠,1表示重合。
赋予锚框编号:
编码解码:1)CNN:编码器:将输入编码成中间表达形式(特征);解码器:将中间表示解码成输出。2)RNN:编码器:将文本表示成向量;解码器:将向量表示成输出;3)General:任一个模型可被分为两块:编码器处理输入(处理为中间状态state),解码器生成输出;且解码器可额外接收一个输入。

随意线索(Volitional Cue):有意识寻找的线索。不随意线索(Nonvolitional Cue):无意识寻找的线索;
注意力机制概念:通过注意力池化层来由偏向性地选择某些输入:随意线索——查询(query);每个输入——一个值(value)(即Sensory Inputs)和不随意线索(key)的对;
注意力分数(a):Normalize前的注意力权重(α),即softmax的输入,表示query和key的相似度;

注意力池化层:

h是超参数
加性注意力(Additive Attention):等价于将query和key合并起来后放入到一个隐藏大小为h输出大小为1的单隐藏层MLP。允许query、key和value各自具有不同长度,需要学习参数。其中,h为超参数;

点积注意力(Scaled Dot-Product Attention):适用于query和key具有同样的长度d,不需要学习参数。此处为对a的每一行做softmax;
![]()
![]()

n个query,m个key-value对,value的维度为v;a中每行表示一个query,每列表示一个key;f中每行表示一个按照query与对应key相似度加权后的value;
序列数据:有时序结构(可正序,可逆序)。

序列模型:预测的内容和数据样本为同一东西,即使用自身过去数据来预测未来,也称自回归模型(auto-regression)
![]()
马尔科夫假设:假设当前数据只跟个过去数据点相关,则对过去长为
的向量数据训练一个MLP模型(预测一个标量)即可;
潜变量模型(Latent Variable):将函数/模型转换为变量;使用潜变量来概括历史信息;是由
和
得到的,而
是由
和
得到的;
![]()
tokenize:将一段话拆分成各个词元(token)。其中,可以设定token为:1)1个字符(char),只有27个数量较少,但还要学习怎么由字符组成词;2)1个词(word),比较方便学习,但不同词数量很多。tokens是本身是包含行信息的二维列表。
文本词汇表(Vocab):构建一个字典,通常也叫词汇表(vocabulary),用来将字符串类型的token映射到从0开始的数字index中(可双向访问)
<unk>:表示unknown的token;
总体流程:tokenize → 构建Vocab → 将所有功能打包至load_corpus_time_machine函数,得到的corpus为所有token(注意是所有token而非uniq_token)的index组成的向量。最终实现:文本 → 整型的向量
隐变量(hidden variable)与潜变量(latent variable)区别:隐变量通常是现实生活中存在的东西,只是我们没有观察到;潜变量可指代现实生活中不存在(人为创造)的东西。但在神经科学领域,不强调两者区别,可都用隐变量表示;
RNN:其实就是有时间轴的MLP。Phi就是激活函数。没有对x建模,所有的x序列信息都存在h里面,即使用来存时序信息。去掉
项就会变为MLP;
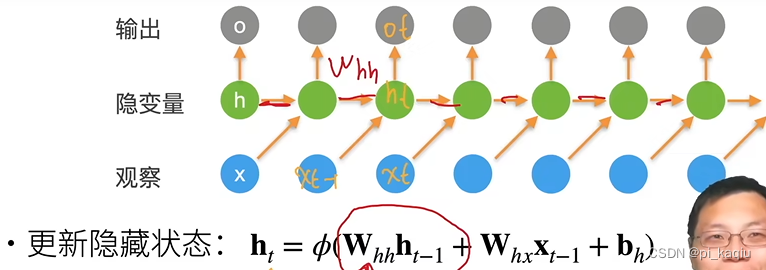
RNN的输出取决于当下输入和前一时间的隐变量(包含历史和时序信息);
语言模型本质上就是一个分类问题,假设字典中有m个词,预测下一个词其实就是做m类分类问题;长度为n的序列就是做n次分类;
衡量语言模型好坏:平均交叉熵就可以,即平均n次分类问题的交叉熵。但历史原因使用困惑度(perplexity)来衡量,即
。其好处是将细微提升的精度值通过指数放大。1表示完美,很确信下一个词就是它,等于k则有k种可能,无穷大是最差情况;

梯度裁剪(Gradient Clip):迭代中计算着T个时间步上的梯度,在反向传播过程中产生长度为O(T)的矩阵乘法链,导致数值不稳定。梯度裁剪能有效预防梯度爆炸。其中,一般取5或10;

RNN应用:第一个其实就是MLP;

GRU:RNN所有信息都放在hidden state内,时间一长会累积过多,不利于抽取较长时间前信息。关注一个序列时,只需要关注一些重要的点。要只记住相关的观察需要:1)更新门(Update Gate):能关注的机制;2)重置门(Reset Gate):能遗忘的机制。两者的都是sigmoid;
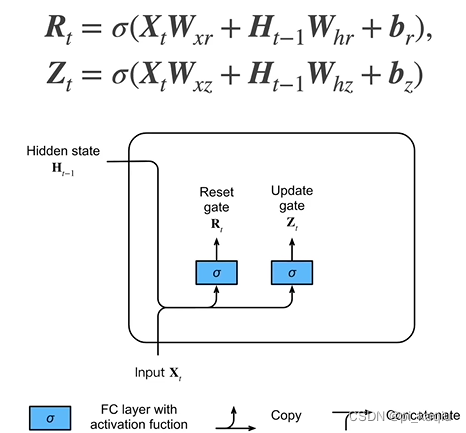
候选隐状态(Candidate hidde state):不是真正的隐藏状态。是一个软的门,因经过了sigmoid,所以取值为0~1,当取0时,即前面信息全不考虑,回到初始状态;当取1时,即把前面所有的隐藏状态都计算进来;简而言之,即要用到多少过去的隐藏状态的信息;
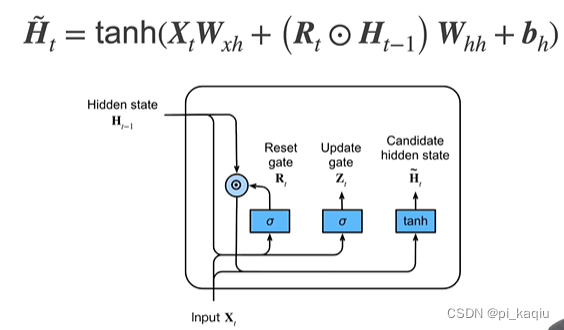
隐状态(Hidden state):同样是一个软的门,表示在计算新的隐状态时要用到多少新的与
相关的信息。当取1时,即不允许与新的
相关的信息通过了;
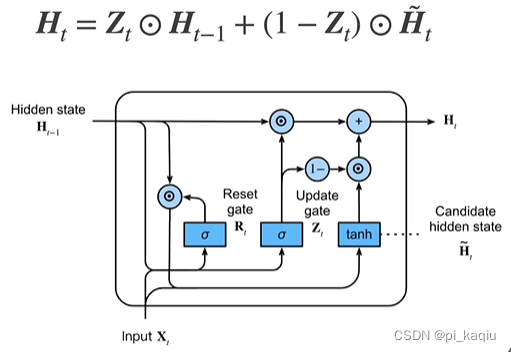
当全0,
全1时,就回到RNN的计算方式。两种极端情况:1)全看
:
与
均为0;2)不看
:
为1,
随意。通常会在两种极端情况间调整;


GRU总结:加了两个门,训练参数为RNN的三倍。
LSTM:1)忘记门:将值朝0减少;2)输入门:决定是否忽略掉输入数据;3)输出门:决定是否使用隐状态;
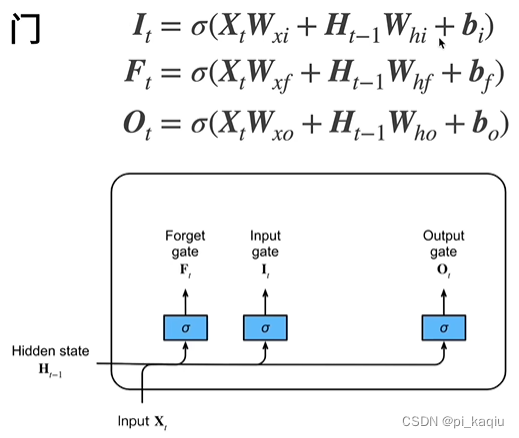
候选记忆单元:取值为-1到+1
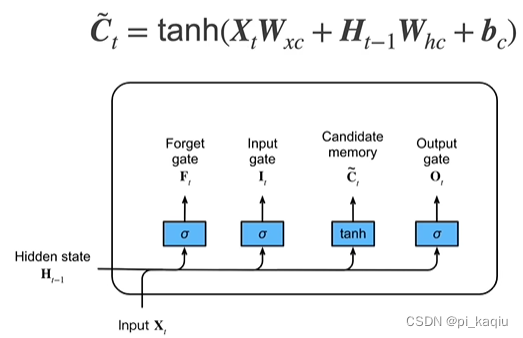
记忆单元:控制是否忘记过去的记忆单元,
控制是否考虑新的记忆单元。与GRU不同,此处两者独立,而不是相加为1。取值为-2到+2
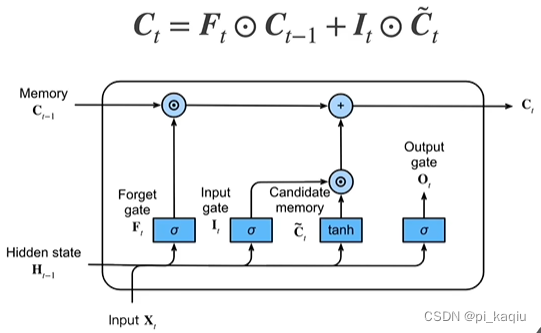
隐状态:再对记忆单元采用tanh,使其值范围恢复到-1到+1之间;表示是否要输出,当为0时即表示过往内容都不要,重置了;

LSTM总结:相较于GRU,多了一个C,可以视作H前未Normalize的辅助的记忆单元

深层循环神经网络:使用多个隐藏层来获得更多的非线性;
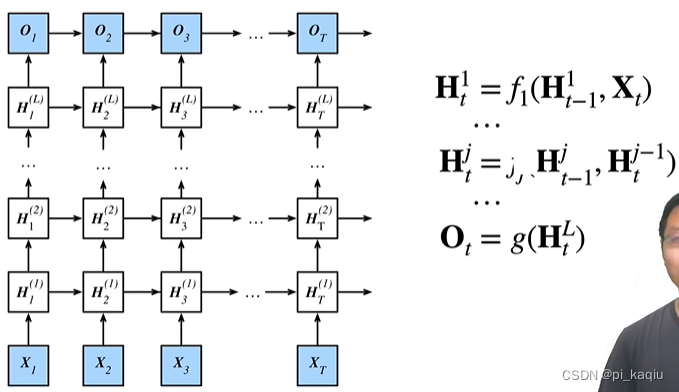
双向RNN:使RNN不止可以看到过去,还可以看到未来。不适合预测下一个词(推理时没有位置信息),适合对一个序列做特征提取(如填空、翻译、改写、语音识别等)。可做encoder,不可做decoder;

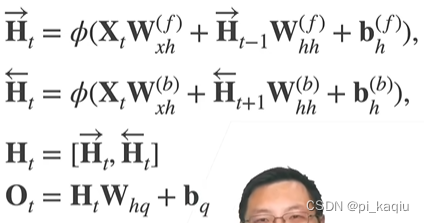
机器翻译:两个句子可以有不同的长度;
Seq2seq:是一种模型的名称。将需要翻译的句子输入给一个RNN的cell(可以是GRU,LSTM等等)作为编码器(可以是双向),将最后一层RNN最后时刻输出的hidden state输入给decoder(另一RNN),再给decoder一个<bos>(begin of sentence)的输入指示翻译开始,每个时刻输出的单词再次作为下一时刻的输入,直到输出<eos>(end of sentence)。从而将不定长的序列生成另一不定长的序列。
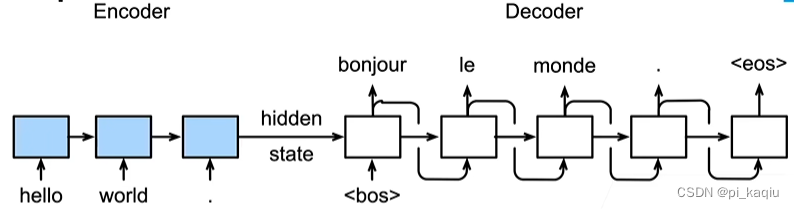
编码器-解码器细节:编码器是没有输出的RNN,编码器最后时间步的隐状态(作为context)用作解码器的初始隐状态。这里Sources指源句子,target指翻译后句子的各个单词。

训练:编码器的训练与推理相同。而对于解码器:训练时使用目标句子作为输入,防止误差累积;但推理时不知道目标句子,只能使用上一时刻的输出作为当前时刻的输入;
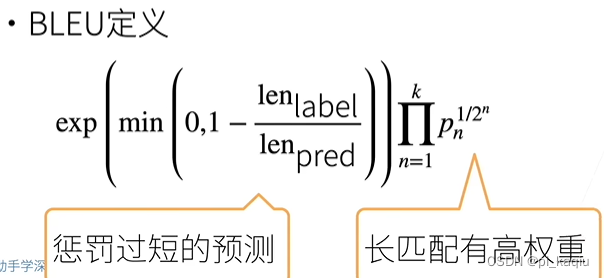
BLEU(bilingual evaluation understudy):衡量生成“序列”好坏。完美是1。第一项在预测长度比实际长度小很多时,会使exp变成非常小的值,造成严厉地惩罚;当计算较大n对应的n-gram时,因其体现较好的生成结果,会在第二项为其赋予较高的权重。

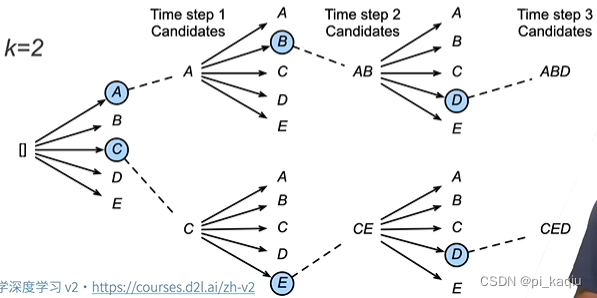
束搜索:seq2seq中使用了贪心搜索来预测序列(将当前时刻预测概率最大的词输出),其效率是最高的,但很可能不是最优的。束搜索是指保存k个候选(贪心只有1个),在每个时刻,对每个候选新加一项(n种可能),在kn个选项种选出最好的k个。在计算分数时(不止计算最终的k个选择,中间选择也会记录下来),短句子概率一般总是较高,为防止总选短句子,分数如下设置(使长句子负的没那么多):

使用注意力机制的seq2seq:动机是机器翻译中,每个生成的词可能相关于源句子中不同的词。
将编码器对每个词的输出作为key和value(它们是等价的)。解码器RNN对上一个词的输出是query。注意力的输出和下一个词的词嵌入合并进入RNN。即注意力机制可以根据编码器RNN的输出来匹配到合适的解码器RNN的输出来更有效地传递信息。

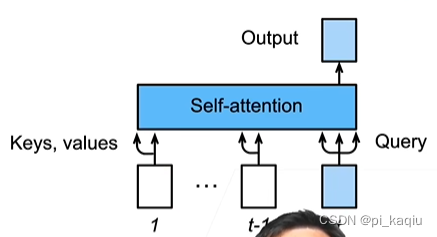
Self-attention:既做query,又做key,又做value。并行度特别好,为O(n)。最长路径为O(1),无视距离,适合处理比较长的文本,也因此计算复杂度较高,为
,模型也较大;


Self-attention与CNN和RNN对比:讨论均应用于序列数据时。(附图)
Position encoding:自注意力机制没有记录位置信息。当变换输入位置时,输出的位置会发生变化,但输出的内容没有变化。不将位置信息加到模型里面,而是直接注入到输入里。P中每一行表示样本(一个token),每一列表示一个特征(token向量表示的一个维度),偶数列为sin,奇数列为cos,且不同奇/偶列周期不同(周期相同的相邻奇偶列有平移)。让模型自己去学会分辨在输入中加入的位置信息,考验模型性能。
![]()


绝对位置信息:1)计算机使用二进制编码:假设表示8个数字,可以用维度为3的特征,不同维度中0和1变化的频率不同,从第一维到最后一维频率逐渐加快。2)位置编码矩阵:使用-1到1间的实数,可以编码的范围较广,如下热度图所示,由前至后频率逐渐减慢。因采用sin与cos函数,所以允许任意长度的d


相对位置信息:位于处的位置编码可以线性投影位于
处的位置编码来表示。只要相对位置不变,无论处于何种绝对位置,线性变换矩阵都不会改变(投影矩阵与
无关);

Transformer:基于编码器-解码器架构来处理序列对(纯基于attention,无RNN)。编码器和解码器都有n个transformer块。
(附图)
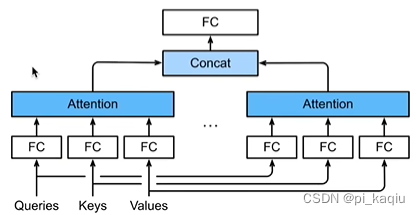
Multi-head attention:不限制具体的attension类型,只要求多头。对同一key、value、query,希望抽取不同的信息,例如短距离关系和长距离关系。先经过FC层,将qkv压缩成低维信息。使用h个独立的attention pooling,concat各个head输出,再通过FC层得到最终输出。
Masked Multi-head attention:解码器对序列中一个元素输出时,不应该考虑该元素之后的元素。通过掩码实现:计算输出时,假装当前序列长度为
,即限制value长度为i,后面部分掩掉,不进入softmax算权重求和,但输入时还是需要一次性都给,只是算value权重求和时不同;
Positionwise FFN(Feed Forward Network,基于位置的前馈网络):本质就是全连接。将输入形状由(b, n, d)变换成(bn, d),其中b为batchsize,n为序列长度,d为每个token的维度。对其作用两个全连接层。再将输出形状由(bn, d)变化回(b, n, d)。等价于两层核窗口为1的1维卷积层。注:因为网络应该可以处理任意长度的序列,因此只能将n与b乘在一起。
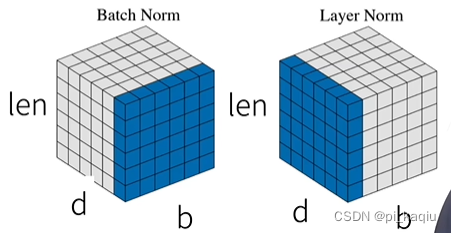
层归一化:批量归一化只能对每个特征(d中的一维)/通道里元素进行归一化,即需要归一化的范围维bn,而n在推理时是不断变化的,会导致BN学的东西很不稳定,因此不适合序列长度会变的NLP应用。层归一化(Layer Norm)对每个样本里的元素进行归一化,虽然n还是会变,但总归是在一个样本里,学到的东西相对稳定。

信息传递:将编码器的输出作为编码中第
个Transformer块中多头注意力的key和value,其query来自目标序列。这意味着编码器和解码器中块的个数和输出维度都是一样的(为了简单、对称);
预测:预测第t+1个输出时,解码器中输入前t个预测值。在自注意力中,前t个预测值作为key和value,第t个预测值还作为query;
Transformer多通道:输出的维度d本身就是多通道,multi-head的每个head提取不同长度的信息,也可以视为多通道;
NLP里的迁移学习:使用预训练好的模型来抽取词、句子的特征,例如word2vec(由一个词推测周围的或者填空)或语言模型。一般不会更新预训练好的模型,只把它当作一个编码器用,后面还是得重新设计。且当需要构建新的网络来抓取新任务需要的信息时,word2vec忽略了时序信息,语言模型只看了一个方向。
BERT动机:设计基于微调的NLP模型。使预训练的模型已经抽取了足够多的信息,新的任务只需要增加一个简单的输出层;
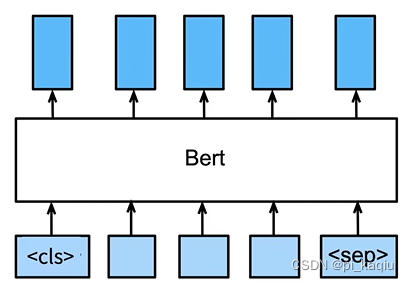
BERT架构:只有编码器的Transformer。很深很大的网络,大规模的数据集;

BERT对输入的修改:每个样本(Token Embedding)是一个句子对(source + target),从<cls>(即class)开始,用<sep>分开;加入额外的片段嵌入(Segment Embedding)表示样本中两个句子分别位于哪部分;不人为设置,而是采用科学系的位置编码(Position Encoding);

BERT预训练任务1:带掩码的语言模型(完形填空)。而非预测模型,所以允许查看双侧信息。需要mask的原因为Transformer的编码器是双向,但标准语言模型要求单向。操作方式为带掩码的语言模型每次随机(15%概率)将一些词元换成<mask>。因为微调任务重不出现<mask>,所以为了不让模型一见到<mask>就预测,在80%概率下,将选中的词元变成<mask>,10%概率下换成一个随机词元,10%概率下保持原有词元;
BERT预训练任务2:下一个句子预测。即预测一个句子对中两个句子是不是相邻。训练样本如下图所示设置。将<cls>对应的输出放到一个全连接层来预测;

两个任务没有太多现实意义,主要是训练一个比较泛化的任务,以供微调使用;
微调BERT:BERT对每一个词元返回抽取了上下文信息的特征向量,不同的任务使用不同的特征;
句子分类:将<cls>对应的向量输入到全连接层分类(预训练判断两个句子是不是pair的时候用的就是这个输出,可训练出句子级别的分类向量,比较适合这一任务);
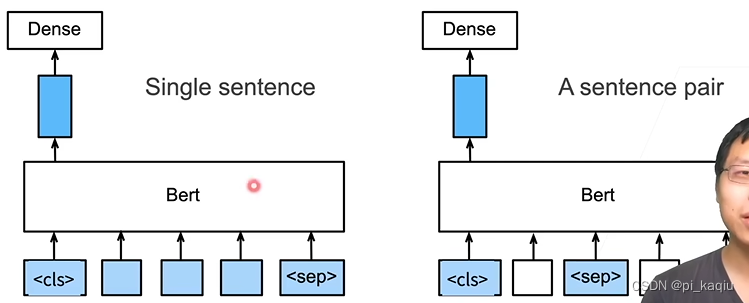
命名实体识别:识别一个词元是不是命名实体,例如人名、机构、位置,将非特殊词元放进全连接层分类;

问题回答: 给定一个问题,和描述文字,找出一个片段作为回答。对片段(值描述文字,问题放在第一个<sep>之前)中的每个词元预测它是回答的开头/是回答的结束/都不是(三分类问题);
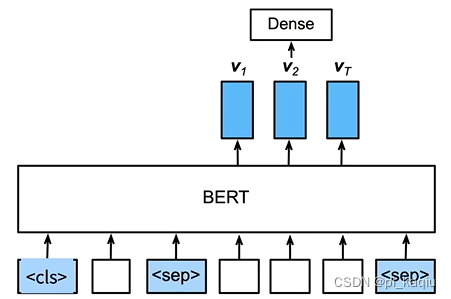
不论何种下游任务,使用BERT微调时均只需增加输出层;但根据任务的不同,输入的表示和使用的BERT特征也会不一样;
转置卷积:用来增大输入高宽,即上采样,本质上仍为卷积操作(卷积与对应转置卷积共享超参数);严格来讲,反卷积(Deconvolution)不同于转置卷积,转置卷积只要求形状可逆,而反卷积要求形状及卷积核内数值均可逆。但深度学习中有时会混用。

总结
简写:i —— 预测的类别;o —— 置信度;σ —— 激活函数;H —— 隐藏层输出
超参数:学习率η,batchsize,epoch,num_workers,隐藏层数,每层隐藏层大小,正则项λ(控制模型容量),丢弃概率,核矩阵大小,填充,步幅,输出通道数;
常用损失函数:1)回归:L2损失,L1损失,Huber's Robust Loss(前两者的结合);2)分类:交叉熵
常用激活函数:sigmoid函数;Tanh函数;ReLU函数(rectified linear unit)(与前两者性能差别不大,主要是简单,算得快)
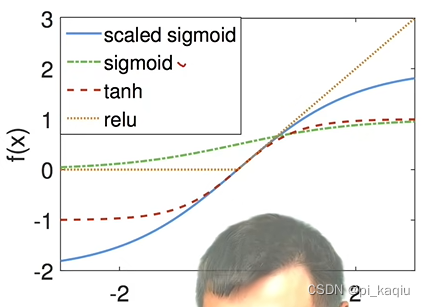
常用正则项:权重衰退;Dropout(仅MLP);
关注robustness研究(新兴领域,适用医疗)!
粒子群算法初始权值阈值
孪生网络,一个文字,输出很大;一个图片,输出很小
疑问
1. RNN部分公式下标怎么一直在变,到底哪个x哪个h;
2. 注意力机制矩阵运算V部分的原理是什么;





)





)







)