Master详细架构
- 位置:namenode
- 实现类:HMaster
- 组成
- 负载均衡器:通过meta了解region的分配,通过zk了解rs的启动情况,5分钟调控一次分配平衡
- 元数据表管理器:管理自己的预写日志,如果宕机,让备用节点读取日志
- 预写日志管理器WAL:32M或1小时滚动一次
RegionServer架构
- 位置:datanode
- 实现类:HRegionServer
- 读写过程
- 写过程:先把操作记录到WAL,然后记录到HDFS中的WAL预写日志中
- 读过程:一般从Block cache或Mem store中读取高频数据,否则再读取磁盘文件
- 必要服务
-
- Region拆分,合并
- mem store刷写
- wal预写日志滚动
-
HBase写流程
- 客户端向zk发送请求创建连接
- 读取zk存储meta表由哪个region server管理
- 访问103读取meta表
- 将读取的meta表作为属性保存在连接中
- 如果meta发生变化需要重新读取缓存
- 客户端发送put写操作请求
- 内存中将请求写入wal并落盘
- 内存将put请求写入mem store,此时已经返回操作成功的ack, 根据rk排序
- 等待触发刷写条件,写入对应的HDFS中的store,每次刷写会生成一个文件。
HBase读流程
- 客户端向zk发送请求创建连接
- 读取zk存储meta表由哪个region server管理
- 访问103读取meta表
- 将读取的meta表作为属性保存在连接中
- 如果meta发生变化需要重新读取缓存
- 客户端发送put读操作请求
- 读取Block cache
- 读取mem store
- 从磁盘中读取数据
- 合并这三个地方的数据,进行数据版本的合并
- HFile带有索引文件,读取rk挺快
- block cache会缓存之前读取的内容和元数据信息,如果HFile没有发生变化,则不需要再次读取
- 布隆过滤器:通过hash的方式排除掉一些肯定没有需要读取文件的位置
刷写Flush流程
- 如果一个store,即一个列族的大小超过128M,就会触发刷写
- 所有memstore的大小根据高低水位线触发,region会按照memstore的大小顺序依次刷写,知道总大小减小到一定范围
- 固定一个小时刷写一次
- 根据wal文件的数量进行刷写
文件结构
- hbase hfile查看命令参数
hbase hfile -m -p 路径/文件名:查看文件信息
storeFile合并
- 小合并:合并部分文件,减少文件的个数,加快读取效率;小合并频率高,每次刷写都会判断执行
- 文件个数3~10
- 文件大小128M之间,追求小合并快速进行
- 大合并:合并所有文件,定期清理掉过期和删除的数据;默认7天执行一次大合并
- 后期可以禁用
- 手动使用major_compact命令来控制合并时间点来进行大合并
Region拆分
- 原因:为了避免单个regioin的数据量太大
- 方式:
- 预分区(自定义分区)
- 系统分区拆分
系统拆分
实际操作:创建文件引用,不会挪动数据,两个region都由原先的regionServer管理。实际的挪动会到下次合并操作时处理。
- 拆分策略
- 按照常量大小拆分,首次拆分太晚,导致分布式效果很差
- 根据某个store的总大小,然后根据换算公式计算,大小根据分区个数的指数性增长
- 首次256M拆分,后续10G拆分
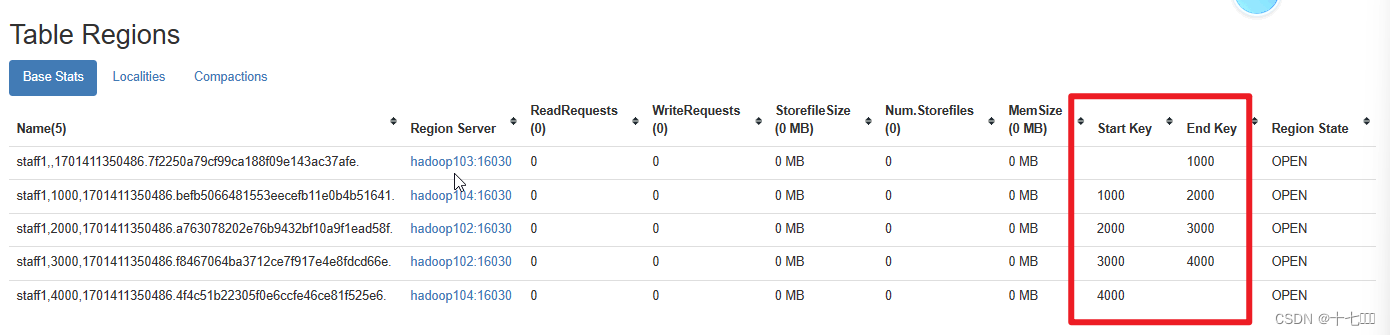
预分区(自定义分区)
根据实际数量、集群的规模等确定分区数。
建表时就创建好分区,防止表中数据被划分到不同分区。如果不指定,默认一个分区,随着表的变大,系统会自动拆分。
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']
HBase优化
RowKey设计
由于rowkey是单调递增的,如果不做设计的话,后续分区时,虽然有多个分区,数据仍然只会往最后一个分区插入,这个就是热点分区问题。
设计原则
- 唯一性:每条数据的rowkey必须是唯一的
- 散列性:将需求的不变量放到rowkey的前面,变量放到后面。
- 长度:rowkey是冗余存储的,rowkey越长,冗余数据越多
HBase经验
- Block cahce负责读
- mem store负责写
HBase API
删除
public static void testDeleteData(String namespaceName, String tableName,String rk,String cf, String cl) throws IOException {//获取Table对象TableName tn = TableName.valueOf(namespaceName, tableName);Table table = connection.getTable(tn);Delete delete = new Delete(Bytes.toBytes(rk));
// delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cl));
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));//删除某个列族DeleteFamilydelete.addFamily(Bytes.toBytes(cf));//删除某个列DeleteColumns
// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cl));table.delete(delete);System.out.println("删除成功");table.close();}
查询
- get
Result result = table.get(get);
List<Cell> cells = result.listCells();
for(Cell cell : cells){//处理每个Kv的数据//获取rowkeyBytes.toString(CellUtil.cloneRow(cell));//获取列族名Bytes.toString(CellUtil.cloneFamily(cell));//获取列名Bytes.toString(CellUtil.cloneQualifier(cell));//获取数据值Bytes.toString(CellUtil.cloneRValue(cell));
}
- scan: 注意要添加起始rowkey和结束rowkey, 传入字符串类型参数即可,使用时使用Bytes.toBytes()转换为byte类型。
Scan scan = new Scan();
scan.withStartRow(Bytes.toBytes(startRow))
.withStopRow(Bytes.toBytes(endRow));
table.getScanner(scan);
)
)
】函数插值与曲线拟合(二):Newton插值【理论到程序】)

 - 胜利与失败)




)
简介)


 世界)
数据分析(一)——创建Glue)
面试题 16:数值的整数次方)
)

)
