目录
Part.01 Kubernets与docker
Part.02 Docker版本
Part.03 Kubernetes原理
Part.04 资源规划
Part.05 基础环境准备
Part.06 Docker安装
Part.07 Harbor搭建
Part.08 K8s环境安装
Part.09 K8s集群构建
Part.10 容器回退
第九章 K8s集群构建
9.1.集群初始化
集群初始化是首先形成一个master的集群,因此相关操作仅在master01上完成即可,当集群初始化完成后,将其他master和worker节点相继加入集群。
9.1.1.APIServer高可用配置
9.1.1.1.安装
在master02、master03上安装keepalived和HAProxy服务
yum install -y keepalived haproxy
9.1.1.2.配置HAProxy
备份配置文件
cp /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak20230508
修改配置文件
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend tcp_8443bind *:8443mode tcpstats uri /haproxy?statsdefault_backend tcp_8443#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend tcp_8443mode tcpbalance roundrobinserver server1 master01.k8s.local:6443 checkserver server2 master02.k8s.local:6443 checkserver server3 master03.k8s.local:6443 check
将修改的配置文件分发至master节点上并启动HAProxy服务
systemctl enable --now haproxy
systemctl status haproxy
9.1.1.3.配置KeepAlived
备份配置文件
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak20230508
master02上修改配置文件
! Configuration File for keepalivedglobal_defs {notification_email {root@localhost}notification_email_from root@localhostsmtp_server localhostsmtp_connect_timeout 30router_id master02.k8s.localscript_user rootenable_script_security
}vrrp_script chk_ha_port {script "/etc/keepalived/chk_ha.sh"interval 2weight -5fall 2rise 1
}vrrp_instance VI_1 {state MASTERinterface ens192virtual_router_id 128priority 100advert_int 1authentication {auth_type PASSauth_pass 12345678}virtual_ipaddress {192.168.111.50}track_script {chk_ha_port}
}
master03上修改配置文件
! Configuration File for keepalivedglobal_defs {notification_email {root@localhost}notification_email_from root@localhostsmtp_server localhostsmtp_connect_timeout 30router_id master03.k8s.localscript_user rootenable_script_security
}vrrp_script chk_ha_port {script "/etc/keepalived/chk_ha.sh"interval 2weight -5fall 2rise 1
}vrrp_instance VI_1 {state BACKUPinterface ens192virtual_router_id 128priority 99advert_int 1authentication {auth_type PASSauth_pass 12345678}virtual_ipaddress {192.168.111.50}track_script {chk_ha_port}
}
在master02和mater03上创建监测脚本,/etc/keepalived/chk_ha.sh
#!/bin/bash
counter=$(ps -C haproxy --no-heading | wc -l)
if [ "${counter}" = "0" ]; thensystemctl start haproxysleep 1counter=$(ps -C haproxy --no-heading | wc -l)if [ "${counter}" = "0" ]; thensystemctl stop keepalivedfi
fi
启动keepalived服务
systemctl enable --now keepalived
systemctl status keepalived
在master02和master03上分别查看ens192端口上的IP是否增加192.168.111.50
[root@master02 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:10:9a:be brd ff:ff:ff:ff:ff:ffinet 192.168.111.2/24 brd 192.168.111.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet 192.168.111.50/32 scope global ens192valid_lft forever preferred_lft foreverinet6 fe80::c9dc:d704:71fd:c8bf/64 scope link noprefixroutevalid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group defaultlink/ether 02:42:dc:e5:f5:cd brd ff:ff:ff:ff:ff:ffinet 1.1.1.1/24 brd 1.1.1.255 scope global docker0valid_lft forever preferred_lft forever[root@master03 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:3b:9e:f4 brd ff:ff:ff:ff:ff:ffinet 192.168.111.3/24 brd 192.168.111.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::605:23f1:e01c:b74/64 scope link noprefixroutevalid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group defaultlink/ether 02:42:0d:24:ee:3c brd ff:ff:ff:ff:ff:ffinet 1.1.1.1/24 brd 1.1.1.255 scope global docker0valid_lft forever preferred_lft forever
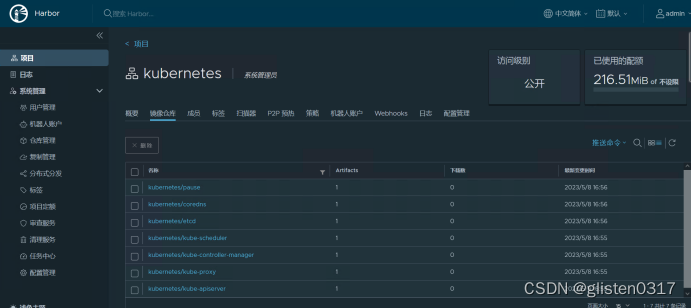
9.1.2.harbor上安装k8s组件镜像
在harbor01上,查看k8s所需镜像
[root@master01 ~]# kubeadm config images list
W0508 16:50:52.428239 4391 common.go:167] WARNING: could not obtain a bind address for the API Server: no default routes found in "/proc/net/route" or "/proc/net/ipv6_route"; using: 0.0.0.0
W0508 16:50:52.440732 4391 version.go:103] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://dl.k8s.io/release/stable-1.txt": dial tcp: lookup dl.k8s.io on [::1]:53: read udp [::1]:49538->[::1]:53: read: connection refused
W0508 16:50:52.440763 4391 version.go:104] falling back to the local client version: v1.23.5
k8s.gcr.io/kube-apiserver:v1.23.5
k8s.gcr.io/kube-controller-manager:v1.23.5
k8s.gcr.io/kube-scheduler:v1.23.5
k8s.gcr.io/kube-proxy:v1.23.5
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
在外网服务器上,拉群对应的组件镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
将拉取的镜像保存到外网服务器本地磁盘上
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5 > /opt/images/kube-apiserver:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5 > /opt/images/kube-proxy:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5 > /opt/images/kube-controller-manager:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5 > /opt/images/kube-scheduler:v1.23.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0 > /opt/images/etcd:3.5.1-0.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6 > /opt/images/coredns:v1.8.6.tar
docker save registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6 > /opt/images/pause:3.6.tar
在harbor01上,创建存储组件镜像的目录
mkdir /opt/kube-images
上传并解压k8s的镜像文件,并将镜像加载到本地
cd /opt/kube-images
docker load -i coredns_v1.8.6.tar
docker load -i etcd_3.5.1-0.tar
docker load -i kube-apiserver_v1.23.5.tar
docker load -i kube-controller-manager_v1.23.5.tar
docker load -i kube-proxy_v1.23.5.tar
docker load -i kube-scheduler_v1.23.5.tar
docker load -i pause_3.6.tar
重新tag
[root@harbor01 ~]# docker images | grep "registry.cn-hangzhou.aliyuncs.com"
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver v1.23.5 3fc1d62d6587 13 months ago 135MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy v1.23.5 3c53fa8541f9 13 months ago 112MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler v1.23.5 884d49d6d8c9 13 months ago 53.5MB
registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager v1.23.5 b0c9e5e4dbb1 13 months ago 125MB
registry.cn-hangzhou.aliyuncs.com/google_containers/etcd 3.5.1-0 25f8c7f3da61 18 months ago 293MB
registry.cn-hangzhou.aliyuncs.com/google_containers/coredns v1.8.6 a4ca41631cc7 19 months ago 46.8MB
registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.6 6270bb605e12 20 months ago 683kB
[root@harbor01 ~]# docker tag 3fc1d62d6587 harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
[root@harbor01 ~]# docker tag 3c53fa8541f9 harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
[root@harbor01 ~]# docker tag 884d49d6d8c9 harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
[root@harbor01 ~]# docker tag b0c9e5e4dbb1 harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
[root@harbor01 ~]# docker tag 25f8c7f3da61 harbor01.k8s.local/kubernetes/etcd:3.5.1-0
[root@harbor01 ~]# docker tag a4ca41631cc7 harbor01.k8s.local/kubernetes/coredns:v1.8.6
[root@harbor01 ~]# docker tag 6270bb605e12 harbor01.k8s.local/kubernetes/pause:3.6
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.23.5
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.1-0
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.6
[root@harbor01 ~]# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
Untagged: registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6
登录到harbor后,并推送镜像到harbor的kubernetes项目中
docker login https://harbor01.k8s.local -uadmin
生成推送指令
[root@harbor01 ~]# docker images | awk '{print "docker push "$1":"$2}' | grep "harbor01.k8s.local"
docker push harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
docker push harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
docker push harbor01.k8s.local/kubernetes/etcd:3.5.1-0
docker push harbor01.k8s.local/kubernetes/coredns:v1.8.6
docker push harbor01.k8s.local/kubernetes/pause:3.6
执行推送指令
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-apiserver:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-apiserver]
50098fdfecae: Pushed
83e216f0eb98: Pushed
5b1fa8e3e100: Pushed
v1.23.5: digest: sha256:d4fdffee6b4e70a6e3d5e0eeb42fce4e0f922a5cedf7e9a85da8d00bc02581c4 size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-proxy:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-proxy]
618b3e11ccba: Pushed
2b8347a02bc5: Pushed
194a408e97d8: Pushed
v1.23.5: digest: sha256:a1dc61984a02ec82b43dac2141688ac67c74526948702b0bc3fcdf1ca0adfcf6 size: 950
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-controller-manager:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-controller-manager]
a70573edad24: Pushed
83e216f0eb98: Mounted from kubernetes/kube-apiserver
5b1fa8e3e100: Mounted from kubernetes/kube-apiserver
v1.23.5: digest: sha256:0dfc4f1512064e909fa8474ac08c49a5699546b03a7c3e87166d7b77eed640b0 size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/kube-scheduler:v1.23.5
The push refers to repository [harbor01.k8s.local/kubernetes/kube-scheduler]
46576c5a6a97: Pushed
83e216f0eb98: Mounted from kubernetes/kube-controller-manager
5b1fa8e3e100: Mounted from kubernetes/kube-controller-manager
v1.23.5: digest: sha256:d9fc2cccd6a4b56637f01b7e967a965fa01acdf50327923addc4c801c51d3e5a size: 949
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/etcd:3.5.1-0
The push refers to repository [harbor01.k8s.local/kubernetes/etcd]
62ae031121b1: Pushed
664dd6f2834b: Pushed
d80003ff5706: Pushed
b6e8c573c18d: Pushed
6d75f23be3dd: Pushed
3.5.1-0: digest: sha256:05c1a3be66823dcaca55ebe17c3c9a60de7ceb948047da3e95308348325ddd5a size: 1372
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/coredns:v1.8.6
The push refers to repository [harbor01.k8s.local/kubernetes/coredns]
80e4a2390030: Pushed
256bc5c338a6: Pushed
v1.8.6: digest: sha256:8916c89e1538ea3941b58847e448a2c6d940c01b8e716b20423d2d8b189d3972 size: 739
[root@harbor01 ~]# docker push harbor01.k8s.local/kubernetes/pause:3.6
The push refers to repository [harbor01.k8s.local/kubernetes/pause]
1021ef88c797: Pushed
3.6: digest: sha256:74bf6fc6be13c4ec53a86a5acf9fdbc6787b176db0693659ad6ac89f115e182c size: 526
登录harbor查看镜像推送结果
9.1.3.kubeadm初始化
在master01上生成配置文件,并根据实际情况进行修改
kubeadm config print init-defaults > /root/init-defaults.conf
对于生成的配置文件,需要修改以下内容:
A.token:连接master使用的token,这里不用修改,后面会生成永久的token;
B.advertiseAddress:连接apiserver的地址,即master的local api地址,只能写IP;
C.name:node节点的名称,如果使用主机名,需要确保master节点可以解析该主机名;
D.controlPlaneEndpoint:master集群对外暴露的IP及端口,10.97.237.239:6443;
E.imageRepository:修改为harbor的kubernetes项目,harbor01.k8s.local/kubernetes;
F.kubernetesVersion:修改为与docker images中镜像的版本一致
G.podSubnet:新增pod地址段,172.16.0.0/24;
H.serviceSubnet:修改service地址段,172.16.1.0/24
文件完整内容如下:
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:- system:bootstrappers:kubeadm:default-node-tokentoken: abcdef.0123456789abcdefttl: 24h0m0susages:- signing- authentication
kind: InitConfiguration
localAPIEndpoint:advertiseAddress: 192.168.111.1bindPort: 6443
nodeRegistration:criSocket: /var/run/dockershim.sockimagePullPolicy: IfNotPresentname: master01.k8s.localtaints: null
---
apiServer:timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.111.50:8443"
controllerManager: {}
dns: {}
etcd:local:dataDir: /var/lib/etcd
imageRepository: harbor01.k8s.local/kubernetes
kind: ClusterConfiguration
kubernetesVersion: 1.23.5
networking:dnsDomain: cluster.localpodSubnet: 172.16.0.0/24serviceSubnet: 172.16.1.0/24
scheduler: {}
使用修改后的配置文件进行初始化
[root@master01 ~]# kubeadm init --config /root/init-defaults.conf
[init] Using Kubernetes version: v1.23.5
[preflight] Running pre-flight checks[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master01.k8s.local] and IPs [172.16.1.1 192.168.111.1 192.168.111.50]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master01.k8s.local] and IPs [192.168.111.1 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master01.k8s.local] and IPs [192.168.111.1 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "admin.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 7.021934 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster
NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently.
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master01.k8s.local as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master01.k8s.local as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: abcdef.0123456789abcdef
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
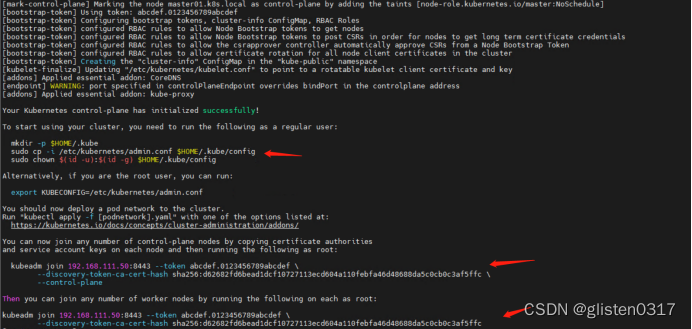
[addons] Applied essential addon: kube-proxyYour Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:kubeadm join 192.168.111.50:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \--control-planeThen you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.111.50:8443 --token abcdef.0123456789abcdef \--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
创建相关文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
9.1.4.安装网络插件
此时查看coredns的状态异常,需要安装网络插件calico
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-767c6f8554-kk8hq 0/1 Pending 0 111s
kube-system coredns-767c6f8554-vbzxg 0/1 Pending 0 111s
kube-system etcd-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 0 2m4s
kube-system kube-proxy-kp4sg 1/1 Running 0 112s
kube-system kube-scheduler-master01.k8s.local 1/1 Running 0 2m4s
查看/var/log/message,存在关于网络的报错,说明需要安装网络插件
May 7 14:23:39 master01 kubelet: E0507 14:23:39.472622 26251 kubelet.go:2347] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized"
在外网服务器上,通过https://docs.tigera.io/下载calico.yaml文件,查找对应的镜像地址
wget https://docs.projectcalico.org/v3.23/manifests/calico.yaml
下载对应calico对应的3个镜像,并保存到本地(docker.io下载太慢,使用dockerproxy镜像加速)
docker pull dockerproxy.com/calico/cni:v3.23.5
docker pull dockerproxy.com/calico/kube-controllers:v3.23.5
docker pull dockerproxy.com/calico/node:v3.23.5
docker save dockerproxy.com/calico/cni:v3.23.5 > /opt/calico/cni:v3.23.5.tar
docker save dockerproxy.com/calico/kube-controllers:v3.23.5 > /opt/calico/kube-controllers:v3.23.5.tar
docker save dockerproxy.com/calico/node:v3.23.5 > /opt/calico/node:v3.23.5.tar
在harbor01上,将calico镜像上传至/opt/calico/
mkdir /opt/calico
docker load -i /opt/calico/cni_v3.23.5.tar
docker load -i /opt/calico/kube-controllers_v3.23.5.tar
docker load -i /opt/calico/node_v3.23.5.tar
新建calico项目
重新tag并推送到私有harbor中
[root@harbor01 ~]# docker images | grep calico
dockerproxy.com/calico/kube-controllers v3.23.5 ea5536b1fa4a 6 months ago 127MB
dockerproxy.com/calico/cni v3.23.5 1c979d623de9 6 months ago 254MB
dockerproxy.com/calico/node v3.23.5 b6e6ee0788f2 6 months ago 207MB
[root@harbor01 ~]# docker tag ea5536b1fa4a harbor01.k8s.local/calico/kube-controllers:v3.23.5
[root@harbor01 ~]# docker tag 1c979d623de9 harbor01.k8s.local/calico/cni:v3.23.5
[root@harbor01 ~]# docker tag b6e6ee0788f2 harbor01.k8s.local/calico/node:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/kube-controllers:v3.23.5
Untagged: dockerproxy.com/calico/kube-controllers:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/cni:v3.23.5
Untagged: dockerproxy.com/calico/cni:v3.23.5
[root@harbor01 ~]# docker rmi dockerproxy.com/calico/node:v3.23.5
Untagged: dockerproxy.com/calico/node:v3.23.5
[root@harbor01 ~]# docker images | grep calico
harbor01.k8s.local/calico/kube-controllers v3.23.5 ea5536b1fa4a 6 months ago 127MB
harbor01.k8s.local/calico/cni v3.23.5 1c979d623de9 6 months ago 254MB
harbor01.k8s.local/calico/node v3.23.5 b6e6ee0788f2 6 months ago 207MB
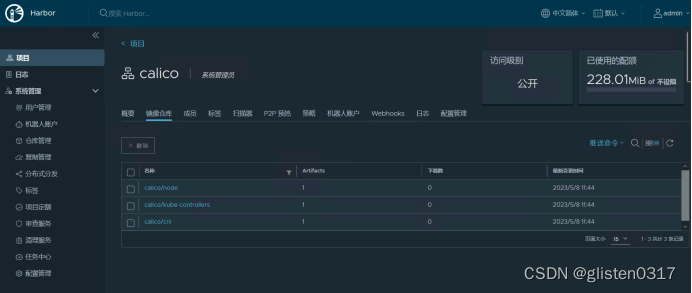
将calico镜像推送至harbor中
docker login https://harbor01.k8s.local -uadmin
docker push harbor01.k8s.local/calico/cni:v3.23.5
docker push harbor01.k8s.local/calico/kube-controllers:v3.23.5
docker push harbor01.k8s.local/calico/node:v3.23.5
将calico.yml文件上传至master01的/root/下,并做如下修改:
修改拉取镜像地址改为私有仓库harbor
[root@master01 ~]# cat calico.yaml | grep imageimage: docker.io/calico/cni:v3.23.5image: docker.io/calico/cni:v3.23.5image: docker.io/calico/node:v3.23.5image: docker.io/calico/node:v3.23.5image: docker.io/calico/kube-controllers:v3.23.5
[root@master01 ~]# sed -i 's/docker.io\/calico/harbor01.k8s.local\/calico/g' /root/calico.yaml
[root@master01 ~]# cat calico.yaml | grep imageimage: harbor01.k8s.local/calico/cni:v3.23.5image: harbor01.k8s.local/calico/cni:v3.23.5image: harbor01.k8s.local/calico/node:v3.23.5image: harbor01.k8s.local/calico/node:v3.23.5image: harbor01.k8s.local/calico/kube-controllers:v3.23.5
calico中用环境变量CALICO_IPV4POOL_IPIP来标识是否开启IPinIP Mode. 如果该变量的值为Always那么就是开启IPIP,如果关闭需要设置为Never。
IPIP的calico-node启动后会拉起一个linux系统的tunnel虚拟网卡tunl0,并由二进制文件allocateip给它分配一个calico IPPool中的地址,log记录在本机的/var/log/calico/allocate-tunnel-addrs/目录下。tunl0是linux支持的隧道设备接口,当有这个接口时,出这个主机的IP包就会本封装成IPIP报文。
# Enable IPIP- name: CALICO_IPV4POOL_IPIPvalue: "Always"# Enable or Disable VXLAN on the default IP pool.- name: CALICO_IPV4POOL_VXLANvalue: "Never"# Enable or Disable VXLAN on the default IPv6 IP pool.- name: CALICO_IPV6POOL_VXLANvalue: "Never"
去掉CALICO_IPV4POOL_CIDR部分的注释,并将修改pod地址段
- name: CALICO_IPV4POOL_CIDRvalue: "172.16.0.0/24"
安装calico插件前,首先检查master01的本机IP
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:d4:d0:64 brd ff:ff:ff:ff:ff:ffinet 192.168.111.1/24 brd 192.168.111.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::e5b5:69ee:10cc:8f0d/64 scope link noprefixroutevalid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group defaultlink/ether 02:42:bd:49:a1:7f brd ff:ff:ff:ff:ff:ffinet 1.1.1.1/24 brd 1.1.1.255 scope global docker0valid_lft forever preferred_lft forever
安装插件
kubectl apply -f /root/calico.yaml
kubectl get node -n kube-system
再次检查coredns的状态,变为正常
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 118m
kube-system calico-node-pr6x6 1/1 Running 0 10m
kube-system coredns-767c6f8554-kk8hq 1/1 Running 0 3h35m
kube-system coredns-767c6f8554-vbzxg 1/1 Running 0 3h35m
kube-system etcd-master01.k8s.local 1/1 Running 0 3h36m
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 3h36m
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 1 (83m ago) 3h36m
kube-system kube-proxy-kp4sg 1/1 Running 0 3h35m
kube-system kube-scheduler-master01.k8s.local 1/1 Running 1 (83m ago) 3h36m
再次检查master01的本机IP,增加了tunnel等网卡
[root@master01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether 00:0c:29:d4:d0:64 brd ff:ff:ff:ff:ff:ffinet 192.168.111.1/24 brd 192.168.111.255 scope global noprefixroute ens192valid_lft forever preferred_lft foreverinet6 fe80::e5b5:69ee:10cc:8f0d/64 scope link noprefixroutevalid_lft forever preferred_lft forever
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group defaultlink/ether 02:42:bd:49:a1:7f brd ff:ff:ff:ff:ff:ffinet 1.1.1.1/24 brd 1.1.1.255 scope global docker0valid_lft forever preferred_lft forever
4: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN group default qlen 1000link/ipip 0.0.0.0 brd 0.0.0.0inet 172.16.0.64/32 scope global tunl0valid_lft forever preferred_lft forever
5: cali9ff1213e5d4@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group defaultlink/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0inet6 fe80::ecee:eeff:feee:eeee/64 scope linkvalid_lft forever preferred_lft forever
6: cali51f93af7f47@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group defaultlink/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 1inet6 fe80::ecee:eeff:feee:eeee/64 scope linkvalid_lft forever preferred_lft forever
7: calid894eb53108@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1480 qdisc noqueue state UP group defaultlink/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2inet6 fe80::ecee:eeff:feee:eeee/64 scope linkvalid_lft forever preferred_lft forever
9.1.5.生成永久token
kubeadm init生成的token为临时,有效期默认为900秒,便于后续扩容node节点,需要生成永久不失效的token
[root@master01 ~]# kubeadm token create --ttl 0
vmz0fo.e1bqw0mj5bszm9bd
[root@master01 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
abcdef.0123456789abcdef 22h 2023-05-09T22:44:56Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
vmz0fo.e1bqw0mj5bszm9bd <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
获取ca证书sha256编码hash值
[root@master01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
生成加入集群指令
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \ --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
9.2.Master节点加入集群
9.2.1.将master01证书文件复制到master02、master03
在master01上,给master02和master03上创建相关目录
ansible 192.168.111.2,192.168.111.3 -m file -a 'path=/etc/kubernetes/pki/etcd/ state=directory'
将相关证书文件等复制到master02和master03上
scp /etc/kubernetes/pki/ca.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master02:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@master02:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@master02:/etc/kubernetes/scp /etc/kubernetes/pki/ca.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/sa.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/front-proxy-ca.* root@master03:/etc/kubernetes/pki/
scp /etc/kubernetes/pki/etcd/ca.* root@master03:/etc/kubernetes/pki/etcd/
scp /etc/kubernetes/admin.conf root@master03:/etc/kubernetes/
9.2.2.master02、master03加入集群
其他master节点加入集群时,一定要添加–experimental-control-plane参数,否则会被认为是普通node节点。
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \--control-plane
执行结果如下:
[root@master02 ~]# kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
> --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc \
> --control-plane
[preflight] Running pre-flight checks[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[preflight] Running pre-flight checks before initializing the new control plane instance
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master02] and IPs [172.16.1.1 192.168.111.2 192.168.111.50]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master02] and IPs [192.168.111.2 127.0.0.1 ::1]
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master02] and IPs [192.168.111.2 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Valid certificates and keys now exist in "/etc/kubernetes/pki"
[certs] Using the existing "sa" key
[kubeconfig] Generating kubeconfig files
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[endpoint] WARNING: port specified in controlPlaneEndpoint overrides bindPort in the controlplane address
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[etcd] Announced new etcd member joining to the existing etcd cluster
[etcd] Creating static Pod manifest for "etcd"
[etcd] Waiting for the new etcd member to join the cluster. This can take up to 40s
The 'update-status' phase is deprecated and will be removed in a future release. Currently it performs no operation
[mark-control-plane] Marking the node master02 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master02 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]This node has joined the cluster and a new control plane instance was created:* Certificate signing request was sent to apiserver and approval was received.
* The Kubelet was informed of the new secure connection details.
* Control plane (master) label and taint were applied to the new node.
* The Kubernetes control plane instances scaled up.
* A new etcd member was added to the local/stacked etcd cluster.To start administering your cluster from this node, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configRun 'kubectl get nodes' to see this node join the cluster.
创建相关文件夹
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看加入集群的状态
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01.k8s.local Ready control-plane,master 138m v1.23.5
master02 Ready control-plane,master 6m13s v1.23.5
master03 Ready control-plane,master 77s v1.23.5
9.3.Node节点加入集群
node在完成基础配置后,使用kubeadm join加入集群
kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \--discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
执行结果如下:
[root@worker01 ~]# kubeadm join 192.168.111.50:8443 --token vmz0fo.e1bqw0mj5bszm9bd \
> --discovery-token-ca-cert-hash sha256:d62682fd6bead1dcf10727113ecd604a110febfa46d48688da5c0cb0c3af5ffc
[preflight] Running pre-flight checks[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 23.0.5. Latest validated version: 20.10[WARNING Service-Kubelet]: kubelet service is not enabled, please run 'systemctl enable kubelet.service'
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
查看加入集群的状态
[root@master01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
master01.k8s.local Ready control-plane,master 3h40m v1.23.5
master02 Ready control-plane,master 88m v1.23.5
master03 Ready control-plane,master 83m v1.23.5
worker01 Ready <none> 79m v1.23.5
worker02 Ready <none> 105s v1.23.5
9.4.常见报错
9.4.1.报错:初始化报错container runtime is not running
在进行kubeadm时报错
[root@master01 ~]# kubeadm init --config /root/init-defaults.conf
[init] Using Kubernetes version: v1.27.0
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR CRI]: container runtime is not running: output: time="2023-05-04T21:06:19+08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决:执行如下指令后重新初始化
[root@master01 ~]# rm -f /etc/containerd/config.toml
[root@master01 ~]# systemctl restart containerd
9.4.2.报错:calico-node状态为Init:CrashLoopBackOff
在启动calico后,查看pod状态,calico-pod为Init:CrashLoopBackOff,并不断尝试重启
[root@master01 ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6b86d5b6c7-27n5d 0/1 Pending 0 14s
kube-system calico-node-wtcjv 0/1 Init:CrashLoopBackOff 1 (4s ago) 14s
kube-system coredns-767c6f8554-kk8hq 0/1 Pending 0 81m
kube-system coredns-767c6f8554-vbzxg 0/1 Pending 0 81m
kube-system etcd-master01.k8s.local 1/1 Running 0 81m
kube-system kube-apiserver-master01.k8s.local 1/1 Running 0 81m
kube-system kube-controller-manager-master01.k8s.local 1/1 Running 0 81m
kube-system kube-proxy-kp4sg 1/1 Running 0 81m
kube-system kube-scheduler-master01.k8s.local 1/1 Running 0 81m
因为pod未完成初始化,因此无法查看pod日志
[root@master01 ~]# kubectl logs calico-node-wtcjv -n kube-system
Error from server (BadRequest): container "calico-node" in pod "calico-node-wtcjv" is waiting to start: PodInitializing
需要使用kubectl describe查看pod的信息包括哪些容器,然后逐个容器查看
kubectl describe pod calico-node-wtcjv -n kube-system
从关于容器的信息中可以看出,calico-node-wtcjv中共需要创建3个容器,分别为upgrade-ipam、install-cni和mount-bpffs
Init Containers:upgrade-ipam:Container ID: docker://c3d8bcce819aa695433def817c05aeb3f1adb0262531292677621fcb66414aaaImage: harbor01.k8s.local/calico/cni:v3.23.5Image ID: docker-pullable://harbor01.k8s.local/calico/cni@sha256:9c5055a2b5bc0237ab160aee058135ca9f2a8f3c3eee313747a02edcec482f29Port: <none>Host Port: <none>Command:/opt/cni/bin/calico-ipam-upgradeState: TerminatedReason: CompletedExit Code: 0Started: Tue, 09 May 2023 08:09:35 +0800Finished: Tue, 09 May 2023 08:09:35 +0800Ready: TrueRestart Count: 0Environment Variables from:kubernetes-services-endpoint ConfigMap Optional: trueEnvironment:KUBERNETES_NODE_NAME: (v1:spec.nodeName)CALICO_NETWORKING_BACKEND: <set to the key 'calico_backend' of config map 'calico-config'> Optional: falseMounts:/host/opt/cni/bin from cni-bin-dir (rw)/var/lib/cni/networks from host-local-net-dir (rw)/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)install-cni:Container ID: docker://39679af86542703bf1824d7a9e94e6347a26a62c9b11893ec75713bdce3a2317Image: harbor01.k8s.local/calico/cni:v3.23.5Image ID: docker-pullable://harbor01.k8s.local/calico/cni@sha256:9c5055a2b5bc0237ab160aee058135ca9f2a8f3c3eee313747a02edcec482f29Port: <none>Host Port: <none>Command:/opt/cni/bin/installState: WaitingReason: CrashLoopBackOffLast State: TerminatedReason: ErrorExit Code: 1Started: Tue, 09 May 2023 08:15:09 +0800Finished: Tue, 09 May 2023 08:15:10 +0800Ready: FalseRestart Count: 6Environment Variables from:kubernetes-services-endpoint ConfigMap Optional: trueEnvironment:CNI_CONF_NAME: 10-calico.conflistCNI_NETWORK_CONFIG: <set to the key 'cni_network_config' of config map 'calico-config'> Optional: falseKUBERNETES_NODE_NAME: (v1:spec.nodeName)CNI_MTU: <set to the key 'veth_mtu' of config map 'calico-config'> Optional: falseSLEEP: falseMounts:/host/etc/cni/net.d from cni-net-dir (rw)/host/opt/cni/bin from cni-bin-dir (rw)/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)mount-bpffs:Container ID:Image: harbor01.k8s.local/calico/node:v3.23.5Image ID:Port: <none>Host Port: <none>Command:calico-node-init-best-effortState: WaitingReason: PodInitializingReady: FalseRestart Count: 0Environment: <none>Mounts:/nodeproc from nodeproc (ro)/sys/fs from sys-fs (rw)/var/run/calico from var-run-calico (rw)/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-dgr48 (ro)
分别查看这3个容器的日志发现install-cni有报错
[root@master01 ~]# kubectl logs calico-node-wn2mc -n kube-system -c install-cni
time="2023-05-09T00:15:09Z" level=info msg="Running as a Kubernetes pod" source="install.go:140"
2023-05-09 00:15:09.958 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/bandwidth"
2023-05-09 00:15:09.958 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/bandwidth
2023-05-09 00:15:10.037 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico"
2023-05-09 00:15:10.037 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico
2023-05-09 00:15:10.104 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/calico-ipam"
2023-05-09 00:15:10.104 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/calico-ipam
2023-05-09 00:15:10.107 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/flannel"
2023-05-09 00:15:10.107 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/flannel
2023-05-09 00:15:10.110 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/host-local"
2023-05-09 00:15:10.110 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/host-local
2023-05-09 00:15:10.194 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/install"
2023-05-09 00:15:10.194 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/install
2023-05-09 00:15:10.200 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/loopback"
2023-05-09 00:15:10.200 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/loopback
2023-05-09 00:15:10.204 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/portmap"
2023-05-09 00:15:10.205 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/portmap
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: File is already up to date, skipping file="/host/opt/cni/bin/tuning"
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: Installed /host/opt/cni/bin/tuning
2023-05-09 00:15:10.209 [INFO][1] cni-installer/<nil> <nil>: Wrote Calico CNI binaries to /host/opt/cni/bin2023-05-09 00:15:10.238 [INFO][1] cni-installer/<nil> <nil>: CNI plugin version: v3.23.52023-05-09 00:15:10.238 [INFO][1] cni-installer/<nil> <nil>: /host/secondary-bin-dir is not writeable, skipping
W0509 00:15:10.238184 1 client_config.go:617] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
2023-05-09 00:15:10.239 [ERROR][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://172.16.1.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 172.16.1.1:443: connect: network is unreachable
2023-05-09 00:15:10.239 [FATAL][1] cni-installer/<nil> <nil>: Unable to create token for CNI kubeconfig error=Post "https://172.16.1.1:443/api/v1/namespaces/kube-system/serviceaccounts/calico-node/token": dial tcp 172.16.1.1:443: connect: network is unreachable
从日志报错中可以看出是网络不可达导致,网上查找资料确认为本地主机侧没有配置默认路由导致calico容器侧的ARP表异常显示incomplete。
[root@master01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
1.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.111.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
[root@master01 ~]# route add -net 0.0.0.0/0 gw 192.168.111.1
[root@master01 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.111.1 0.0.0.0 UG 0 0 0 ens192
1.1.1.0 0.0.0.0 255.255.255.0 U 0 0 0 docker0
192.168.111.0 0.0.0.0 255.255.255.0 U 100 0 0 ens192
重新拉起calico-node后,状态正常
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 66s
calico-node-qqpfj 0/1 Running 0 66s
coredns-767c6f8554-kk8hq 1/1 Running 0 98m
coredns-767c6f8554-vbzxg 1/1 Running 0 98m
etcd-master01.k8s.local 1/1 Running 0 98m
kube-apiserver-master01.k8s.local 1/1 Running 0 98m
kube-controller-manager-master01.k8s.local 1/1 Running 0 98m
kube-proxy-kp4sg 1/1 Running 0 98m
kube-scheduler-master01.k8s.local 1/1 Running 0 98m
9.4.3.报错:calico-node状态为CrashLoopBackOff
在启动calico后,查看pod状态,calico-pod为CrashLoopBackOff
[root@master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-6b86d5b6c7-65f4x 1/1 Running 0 108m
calico-node-qqpfj 0/1 CrashLoopBackOff 33 (65s ago) 108m
coredns-767c6f8554-kk8hq 1/1 Running 0 3h25m
coredns-767c6f8554-vbzxg 1/1 Running 0 3h25m
etcd-master01.k8s.local 1/1 Running 0 3h25m
kube-apiserver-master01.k8s.local 1/1 Running 0 3h25m
kube-controller-manager-master01.k8s.local 1/1 Running 1 (73m ago) 3h25m
kube-proxy-kp4sg 1/1 Running 0 3h25m
kube-scheduler-master01.k8s.local 1/1 Running 1 (73m ago) 3h25m
查看日志
kubectl logs calico-node-pr6x6 -n kube-system
发现报错如下:
2023-05-09 02:09:17.561 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:35661->[::1]:53: read: connection refused
bird: KRT: Received route 0.0.0.0/0 with strange next-hop 192.168.111.1
2023-05-09 02:09:18.563 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:57748->[::1]:53: read: connection refused
2023-05-09 02:09:19.564 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:43132->[::1]:53: read: connection refused
bird: KRT: Received route 0.0.0.0/0 with strange next-hop 192.168.111.1
2023-05-09 02:09:20.565 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:53369->[::1]:53: read: connection refused
2023-05-09 02:09:21.567 [ERROR][84] felix/health.go 296: Health endpoint failed, trying to restart it... error=listen tcp: lookup localhost on [::1]:53: read udp [::1]:36117->[::1]:53: read: connection refused
确认原因为localhost未设置映射,需要在/etc/hosts中增加映射
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6

)

的方法)
)
![LeetCode [中等]二叉树的右视图(层序](http://pic.xiahunao.cn/LeetCode [中等]二叉树的右视图(层序)









)


:函数模板的匹配原则,类模板的实例化)
