2022年高校大数据挑战赛
B题 图像信息隐藏
原题再现:
互联网的快速发展,给图像、视频的传播方式带来巨大变化。图像作为媒体的重要载体,每天有大量的原创图像公开在互联网上,如何保护图像版权的同时不破坏原始的图像一直是图像处理方向的研究热点。
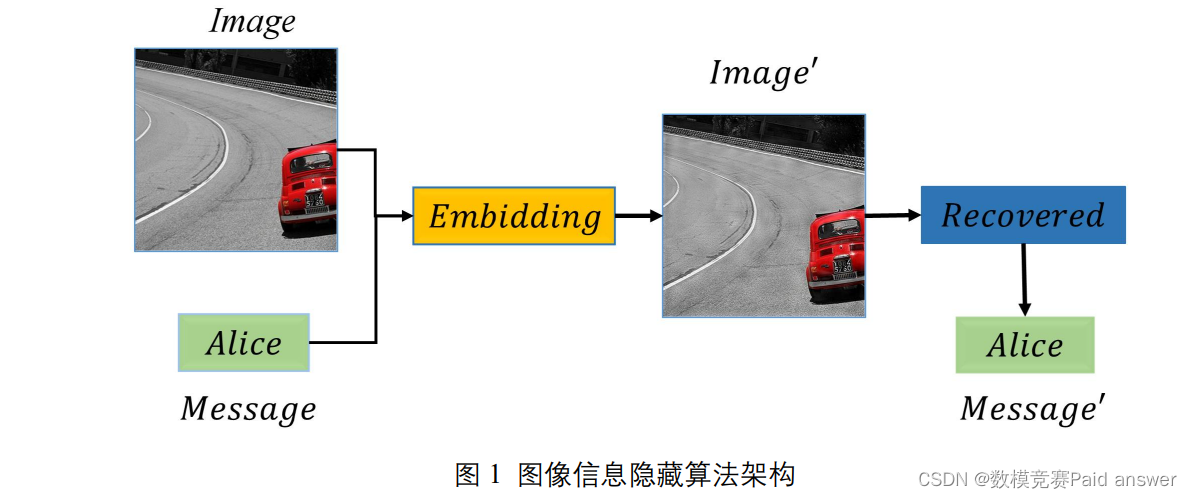
近年来,图像水印算法逐渐成为保护图像版权的重要手段。一般的图像水印算法分为嵌入算法和提取算法。图 1 展示了图像水印算法的基本架构。黄色部分代表嵌入算法,将具有可辨识的信息(Alice)融合到需要保护的图像(Image)中,得到嵌入信息的图像(Image’)。与此同时,嵌入算法不对保护图像造成大的影响。从人类视觉角度无法分辨Image与Image’之间的差别。蓝色部分为水印提取算法,其作用是在发生版权纠纷时能通过算法提取出嵌入的信息(Alice),从而确定图像的版权归属。
附件 1 训练样本中包含 images_original和image_message两个文件夹,还有嵌入的信息列表保存在message.txt中。为了简化问题,每张image_message图片中只嵌入 26 + 26 + 10 = 62 个(az,AZ,0~9)字符中的一个字符。分别提供了9950 张图片和对应的标签信息,请你查阅相关文献,回答以下问题。
问题 1:图像信息隐藏算法的图像质量评价指标很多,其中影响视觉效果的指标具有不可见性,可用来衡量嵌入水印的图像与原始图像之间的差异性。现请你根据附件 1 中的数据,使用多种图像质量评价指标说明原始图像与嵌入水印之后图像之间的差别,并使用合适的统计方法说明差别图像之间至少 3 种共同的特征。参考图 2 的方式展示,论文中仅需要展示“im100067. jpg” 和“im10234. jpg”两张图像的差别图像。

问题 2: 运用提供的 9950 张图片和对应的标签信息,尽量使用问题 1 中的共同特征来设计图像信息隐藏的检测算法,检测任意一张嵌入信息图片中存在的信息,并对你的算法进行校验。检验量化指标为 :9950 张图像中被正确检测信息的图像数量。
问题 3:使用检测算法对“附件 2”文件夹下 test_images 中包含的 50张图片(包含嵌入和没有嵌入信息的图像 ) ,请先判断是否嵌入信息( 信息为a-z,A-Z,0-9 中的某一个字母或数字)。如果嵌入了信息请检测出对应信息,并将检测结果填写到表 1 中。
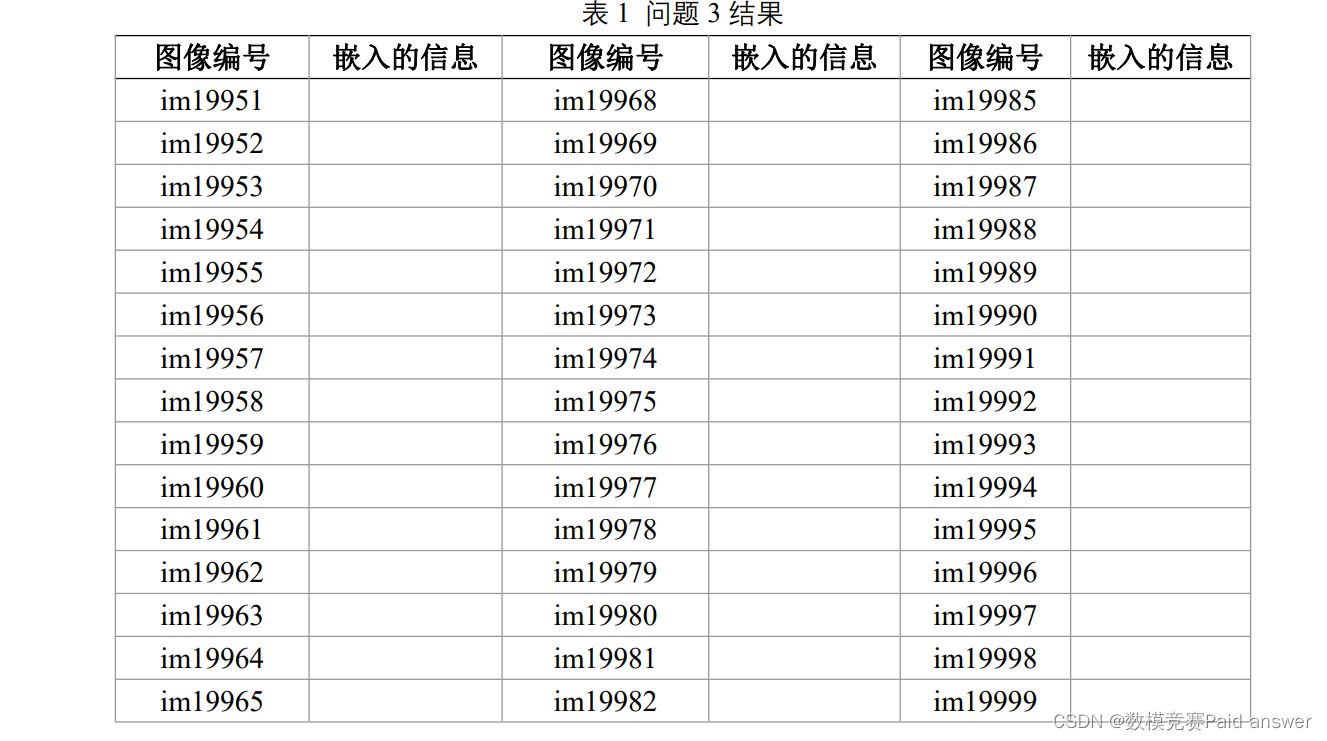

注:表 1 中的“嵌入的信息”列为需要填写的检测结果,其中有信息嵌入的直接填写对应的字符,没有信息嵌入的填写“无”。
说明:
1. 项目程序建议在 python3.6 及以上环境下搭建,其他语言不做统一要求,但是需要在运行说明中写明软件名称及版本。无需提交赛题自带的图像。
2. 除了论文外,还需要提供完整程序代码、运行说明(包括依赖包及其版本)、模型文件(若有)等,以压缩包的形式提交。提交的支撑材料不得超过 20Mb。
3.本研究可以用机器学习方法,包括各种深度学习方法,如CNN、DNN算法、VGG、U-Net等。
整体求解过程概述(摘要)
随着互联网的快速发展,图像作为重要信息载体其传播范围也越来越广。水印算法作为一种图像信息隐藏技术,能够实现在用户视觉无法分辨的情况下添加版权信息,有效保证了图像的版权安全和图像质量。本文在附件一所提供的 9950 组带有包含 60 种类别水印字符标签的原始图像和嵌入水印图像的数据集上,利用差值图像作为主观可视化评价指标,分析得出嵌入水印的图像想比原图增加了部分前景边缘信息。利用 MSE、RMSE、PSNR、SSIM、信息熵等客观非可视化评价指标分析了嵌入水印图像与原始图像之间的区别,即嵌入水印的图像的信噪比和结构一致性有所降低。对于差别图像进行统计分析得出其包含一定量的纹理特征,灰度分布服从正态分布,并且利用 HOG、ORB、LBP 等多种特征描述符表示了差值图像的共同特征,其中 HOG 特征点数量范围为[154,218],ORB 特征点数量范围在[34,96],LBP 特征点数量范围在[206,462]。为了实现水印类别检测算法,本文将问题一中统计的差值图像以及其 HOG、ORB、LBP特征指标相结合作为训练输入。构建了基于支持向量机(SVM)、随机森林(RF)和深度卷积神经网络 CNN(ResNet50)的分类模型并进行对比,结果表明随机森林模型准确率均值较低为 79.2965%,并且 ResNet50 模型存在不稳定问题,因此最终选择 SVM模型作为图像水印隐藏信息检测模型,在 9950 张图像中被正确检测信息的图像数量为9848 张,即准确率达到 98.9749%。
针对附件二中的 50 张不明确是否嵌入水印的图像,传统的基于 DCT、SVD 原理的算法针对性较强,不适应数据集中的隐式水印掩膜映射处理的图像数据。因此本文根据CVAE 变分自动编码器重构模型和 CUT 风格迁移网络原理构建了基于深度学习的水印去除模型。假设 50 张图像全部嵌入了水印信息,将模型输入设定为 50 张待判定图像,输出为模拟水印去除后的结果图。随后利用输入和输出的差值图像指标判定输入的图像是否嵌入了水印信息,并对嵌入水印的图像利用问题二构建的 SVM 分类模型进行类别预测,同时输出对应的置信度。最终分类结论为:对于附件二中的 50 张图像,其中未嵌入信息的图像数量为 7,嵌入信息的图像总数为 43,嵌入 a~z 的图像数量为 21,嵌入A-Z 的图像数量为 17,嵌入 0-9 的图像数量为 5。
最后,本文对所构建的基于 SVM 和差值图像描述符的分类模型和基于 CVAE 的模拟水印去除网络模型进行了评价与推广,提出了模型的改进方向。在模型功能完善的情况下,能够利用本文的方案实现基于水印嵌入和水印提取的图像信息隐藏技术,具有良好的应用前景和实际价值。
模型假设:
根据题目所给的信息以及相关要求,做出如下假设:
1. 假设训练标签与训练集图像数据一一对应;
2. 假设嵌入水印的过程中图像的原始信息保存完好;
3. 假设图像数据集中不包含标签中未出现的字符;
4. 假设水印的添加方式为隐式字符映射 One-Hot 向量编码掩膜模型;
5. 假设机器学习和深度学习方式能够感知和捕获到图像的隐藏信息;
6. 假设重采样的样本均衡方式可以解决分类标签数量差别对分类结果的影响;
问题分析:
问题一分析
通过附件 1 中的数据,绘制出原始图像与嵌入信息图像的差别图像,选取合适的图像评价指标进行差异性分析(每种图像均为 9950 张),同时利用合适的统计方法说明两种图像之间的三个共同特征。
步骤一:使用 OpenCV 库函数获得差别图像,并获取相关的图像质量评价指标。
步骤二:选择合适的图像质量评价指标进行差异性分析,并且记录下来。
步骤三:采取统计学方法获取差别图像间的共同特征,得出结果。
问题二分析
该问题需要根据提供的 9950 张图片获取的图像质量评价指标,也就是其对应的标签信息。然后根据其共同特征来选择合适的模型,获取已经隐藏信息的图像以及将图像进行筛选分类,得到隐藏了信息的图像数量及隐藏信息。根据题意应应选择两类模型进行求解,分别用来分辨图片、统计数量获取隐藏信息。
步骤一:先利用题意求解的共同特征构建合适的模型,将附件一中的 image_message和差别图像根据嵌入信息的种类进行分类,获得分类后的数据集。
步骤二:然后构建适当的检测与分类模型,调整好参数进行训练,获得最佳模型,再利用模型进行嵌入信息的检测与分析,获得隐藏的信息。
步骤三:利用合适的统计方法对隐藏的信息及其数量进行记录。
问题三分析
根据题意可知,需要调用问题二中构建的模型,首先调用识别图像的模型,将测试集输入该模型中,判断否为隐藏信息的图像,判断成功后再将通过测试的数据集调用分类的模型进行分类并获取隐藏信息,并对测试结果进行分析。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
部分程序如下:
import cv2
import pandas as pd
import matplotlib.pyplot as plt
import math
#%matplotlib inline
from skimage.metrics import mean_squared_error as compare_mse
from skimage.metrics import peak_signal_noise_ratio as compare_psnr
from skimage.metrics import structural_similarity as compare_ssim
data = pd.DataFrame(columns=['PSNR','SSIM','RMSE']) # ['PSNR','SSIM','MSE','RMSE']
data.to_csv('A.xlsx', index=False, encoding='utf-8')
#for i in range(1,9951,1):
for i in range(1,9951,1):
input1 = 'data/image_original/im1%04d.jpg'%i
input2 = 'data/image_message/im1%04d.jpg'%i
img1 = cv2.imread(input1)
img2 = cv2.imread(input2)
p_ = compare_psnr(img1, img2)
s_ = compare_ssim(img1, img2, channel_axis=2)
m_ = compare_mse(img1, img2)
rm_ = math.sqrt(m_)
p = pd.Series(p_)
s = pd.Series(s_)
m = pd.Series(m_)
#rm = pd.Series(rm_)
a = [[p_,s_,rm_]]
#a = [[p_,s_,m_,rm_]]
data_temp = pd.DataFrame(a)#横着拼
data_temp.columns = ['PSNR','SSIM','RMSE']
# ['PSNR','SSIM','MSE','RMSE']
data = pd.DataFrame(columns=['PSNR','SSIM','RMSE'])
#清空数据,表头 # ['PSNR','SSIM','MSE','RMSE']
data = pd.concat([data,data_temp],axis=0,ignore_index=0)#竖着拼
#print(data)
data.to_csv('A.xlsx', mode='a', index=False, encoding='utf-8',header=0)
import numpy as np
import cv2
import matplotlib.pyplot as plt
# %matplotlib inline
def grey_scale(img_gray ):
#归一化函数
rows, cols = img_gray.shape
flat_gray = img_gray.reshape((cols * rows,)).tolist()
A = min(flat_gray)
B = max(flat_gray)
print('A = %d,B = %d' % (A, B))
output = np.uint8(255 / (B - A) * (img_gray - A) + 0.5)
return output
origin = cv2.imread('data/image_original/im10067.jpg')
with_message = cv2.imread('data/image_message/im10067.jpg')
origin = cv2.cvtColor(origin, cv2.COLOR_BGR2RGB)
with_message = cv2.cvtColor(with_message, cv2.COLOR_BGR2RGB)
origin_gray = cv2.imread('data/image_original/im10067.jpg',0).astype(np.int32)
with_message_gray = cv2.imread('data/image_message/im10067.jpg',0).astype(np.int32)
difference_gray = with_message_gray - origin_gray
difference_gray = grey_scale(difference_gray)
fig,a = plt.subplots(1,3,figsize=(16,12),dpi=250)
#绘制平方函数
a[0].imshow(origin)
a[0].set_xticks([]) # 去掉 x 轴
a[0].set_yticks([]) # 去掉 y 轴
a[0].set_xlabel('original image',fontsize=18)
#绘制平方根图像
a[1].imshow(with_message)
a[1].set_xticks([]) # 去掉 x 轴
a[1].set_yticks([]) # 去掉 y 轴
a[1].set_xlabel('message image',fontsize=18)
#绘制指数函数
#a[2].imshow(difference_gray)
a[2].imshow(difference_gray,cmap='gray')
a[2].set_xticks([]) # 去掉 x 轴
a[2].set_yticks([]) # 去掉 y 轴
a[2].set_xlabel('residual',fontsize=18)
plt.show()
import numpy as np
from sklearn import svm
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
import scipy.io as sio
import matplotlib.pyplot as plt
import os
import re
import pandas as pd
import joblib
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' import glob
import cv2
import numpy as np
from PIL import Image
# 读取文件夹中图片
Image_dir = './data/image_residual/' # 添加绝对路径
Image_glob = os.path.join(Image_dir, "*.jpg")
Image_name_list = []
# 将符合条件的 png 文件路径读取到 Image_list 中去
Image_name_list.extend(glob.glob(Image_glob))
print(Image_name_list[::])
len_Image_name_list = len(Image_name_list)
image=[]
for i in range(len_Image_name_list):
image_path = Image_name_list[i]
image.append(cv2.imread(image_path,0).reshape(-1, 1))
image = np.array(image)
image = image.squeeze()
print(image)
data = pd.read_table('./data/message.txt', sep = '\t', header = None, names = ['file label'])
label=[]
for i in range(len(data)):
label.append(data.loc[i][0][-3])
train_data, test_data, trian_label, test_label = train_test_split(image, label,test_size=0.3)
#测试数据乱序重构
state1 = np.random.get_state() #获取生成器内部状态元组 保存状态,记录下数组被打乱
的操作(数组如何被打乱的)
np.random.shuffle(train_data) #乱序重构
np.random.set_state(state1) #相同的打乱方式 对标签进行同样操作
np.random.shuffle(trian_label) #乱序重构
#训练数据乱序重构
state2 = np.random.get_state()
np.random.shuffle(test_data)
np.random.set_state(state2)
np.random.shuffle(test_label)
clf = svm.SVC(decision_function_shape='ovo') #构造多分类 SVM
clf.fit(train_data,trian_label) #训练
joblib.dump(clf, "svm_model.m")
predict_res = clf.predict(image) #预测
print(predict_res)
data_cnt=[]
for i in range(predict_res.shape[0]):
data_cnt.append(i)
print('SVM accuracy')
print(accuracy_score(predict_res,label))
clf2 = RandomForestClassifier()
clf2.fit(train_data,trian_label)
joblib.dump(clf2, "rf_model.m")
res2 = clf2.predict(image)
print('Rondom_Forest')
print(accuracy_score(res2,label))
predict_res_pd=pd.DataFrame(data=predict_res)
res2_pd=pd.DataFrame(data=res2)
test_label_pd=pd.DataFrame(data=label)
print(predict_res)
print(type(predict_res))
print(predict_res_pd)
print(type(predict_res_pd))
predict_res_pd.to_csv('predict_res_pd.csv',encoding='gbk')
res2_pd.to_csv('res2_pd.csv',encoding='gbk')
test_label_pd.to_csv('test_label_pd.csv',encoding='gbk')


猫狗识别)


 - 准备键盘和终端屏幕)





 中的组合语义分析)







