论文地址:1409.1556.pdf。 (arxiv.org);1409.1556.pdf (arxiv.org)
项目地址:Kaggle Code
一、背景
ImageNet Large Scale Visual Recognition Challenge 是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展。比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。
VGG Net由牛津大学的视觉几何组(Visual Geometry Group)参加2014年ILSVRC提出的网络模型,它主要的贡献是展示了卷积神经网络的深度(depth)是算法优良性能的关键部分。
VGGNet的产生主要源于2012年AlexNet将深度学习的方法应用到ImageNet的图像分类比赛中并取得了惊人的效果后,大家都竞相效仿并在此基础上做了大量尝试和改进,例如,在卷积层使用更小的卷积核以及更小的步长(Zeiler&Fergus,2013; Sermanet,2014),又或者在整个图像和多个尺度上密集地训练和测试网(Sermanet,2014:Howard,2014)。但这些优化中作者觉得都没有谈到网络深度的工作,因此受到启发,不仅将上面的两种方法应用到自己的网络设计和训练测试阶段,同时想再试试深度对结果的影响。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
二、论文解读

1、网络结构
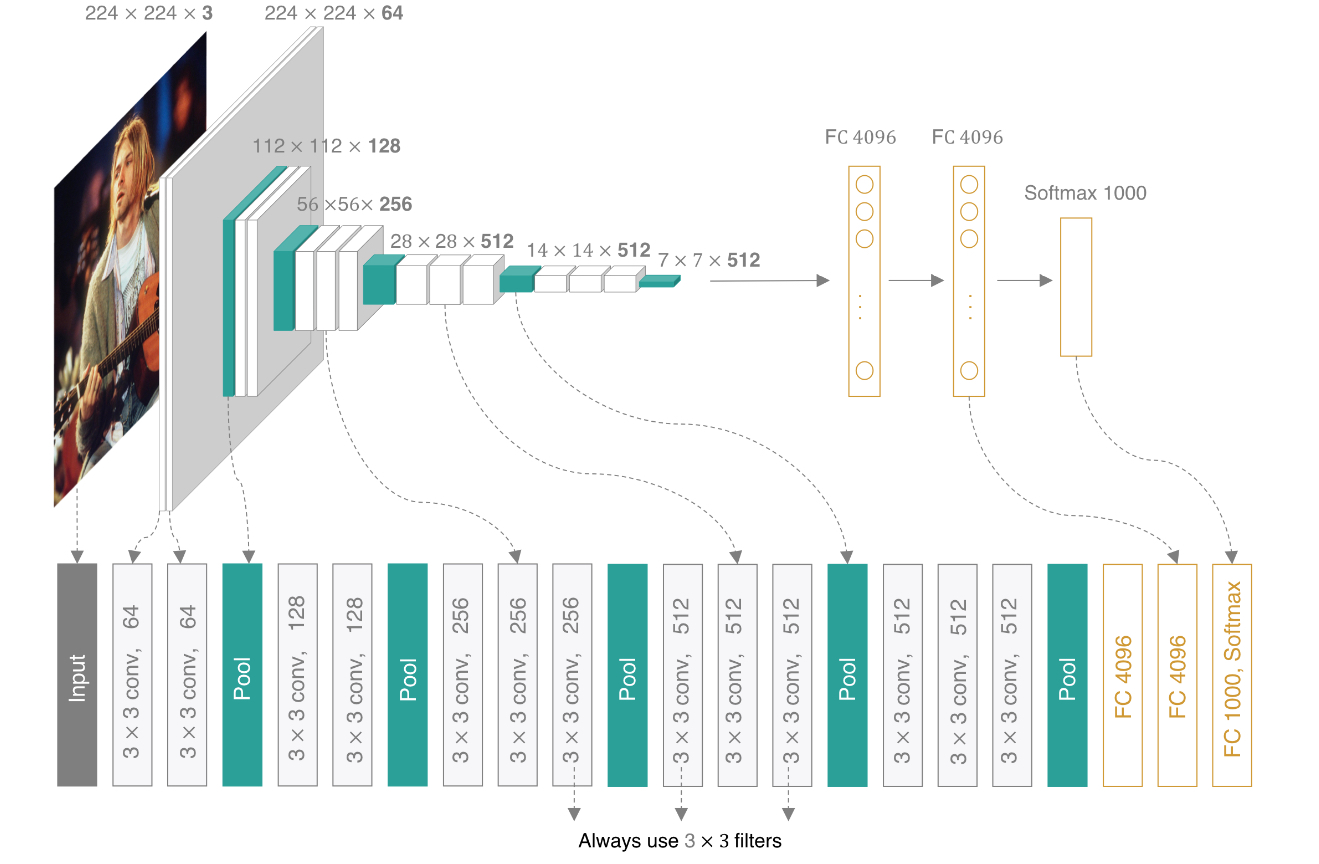
VGGNet可以看成是加深版的AlexNet,把网络分成了5段,每段都把多个尺寸为3×3的卷积核串联在一起,每段卷积接一个尺寸2×2的最大池化层,最后面接3个全连接层和一个softmax层,所有隐层的激活单元都采用ReLU函数。
VGGNet包含很多级别的网络,深度从11层到19层不等。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,先训练浅层的的简单网络VGG11,再复用VGG11的权重初始化VGG13,如此反复训练并初始化VGG19,能够使训练时收敛的速度更快。比较常用的是VGGNet-16和VGGNet-19。VGGNet-16的网络结构如下图所示:
2、论文思路
用小的卷积核(3*3)不断来加深网络,评估在不同深度下对大规模图像识别中准确率。
注:两个3*3的卷积核的感受野是相当于一个5*5的卷积核的感受野。
3、模型特点
- 使用多个小卷积核构成的卷积层代替较大的卷积层,两个3x3卷积核的堆叠相当于5x5卷积核的视野,三个3x3卷积核的堆叠相当于7x7卷积核的视野。一方面减少参数,另一方面拥有更多的非线性变换,增加了CNN对特征的学习能力;
- 引入1*1的卷积核,在不影响输入输出维度的情况下,引入更多非线性变换,降低计算量,同时,还可以用它来整合各通道的信息,并输出指定通道数;
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度;
- 训练时,先训练级别简单(层数较浅)的VGGNet的A级网络,然后使用A网络的权重来初始化后面的复杂模型,加快训练的收敛速度;
- 采用Multi-Scale方法来做数据增强,增加训练的数据量,防止模型过拟合;
- VGGNet不使用局部响应归一化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。

4、为什么两个3*3的卷积核的感受野是相当于一个5*5的卷积核的感受野?
首先从单个3*3的卷积核的谁敢首页来进行靠拢,当我们使用一个3*3的卷积核时,此时它的感受野是3*3;当我们在上述3*3的卷积核的基础上再增加一个3*3卷积核时,此时两个连续3*3的卷积核的感受野变成了5*5,这是因为第二个3*3的卷积核考虑了第一个卷积核输出的3*3的区域,而此时这个区域在原始输入上对应5*5的区域。
5、用两个3*3的卷积核代替一个5*5的卷积核有什么作用?
(1)减少参数的数量:
使用两个3*3的卷积核的参数数量明显少于一个5*5的卷积核的参数数量。具体来说,两个3*3的卷积核总共有2*3*3=18个参数;而一个5*5的卷积核有5*5=25个参数,这就意味着使用两个较小的卷积核来代替一个较大的卷积核可以减少参数,从而减少计算的复杂度和模型过拟合的情况。
下图展示了为什么“两个3x3卷积层”与“单个5x5卷积层”具有等效的5x5的感受野。

(2)增加非线性:
使用 2个3x3卷积层拥有比1个5x5卷积层更多的非线性变换(前者可以使用两次ReLU激活函数,而后者只有一次),使得卷积神经网络对特征的学习能力更强。意味着,我们将在这两个卷积层之间增加一个额外的非线性激活函数,这样不仅仅增加了模型的非线性表达能力。更能够使模型捕获更复杂的特征。
(3)减少网络层参数
- ①对于两个3x3卷积核,所用的参数总量为2×32×channels2\times3^2\times{channels}2×32×channels(假设通过padding填充保证卷积层输入输出通道数不变)
- ②对于单个5x5卷积核,参数量为52×channels5^2\times{channels}52×channels
- ③参数量减少了(1−2×32×channels52×channels)×100%=28%(1-\frac{2\times3^2\times{channels}}{5^2\times{channels}})\times100\%=28\%(1−52×channels2×32×channels)×100%=28%
6、1x1卷积核的作用(优势)
- 作用1:不影响输入输出的维度情况下(即图片尺寸不变),降低了大量运算,同时改变了维度(通道数);
- 作用2:卷积之后再紧跟ReLU进行非线性处理,提高决策函数的非线性
7、感受野的通用计算公式是什么?
对于连续的卷积操作,其累积感受野的计算可以使用下述公式:
RF=k+(k-1)(n-1)
其中:
- RF:是累积感受野的大小;
- k:是每个卷积核的大小;
- n:是连续卷积操作的数量。
8、为什么多层小的卷积核获得的感受野与单层较大的卷积核一致?
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
- input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
- input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果
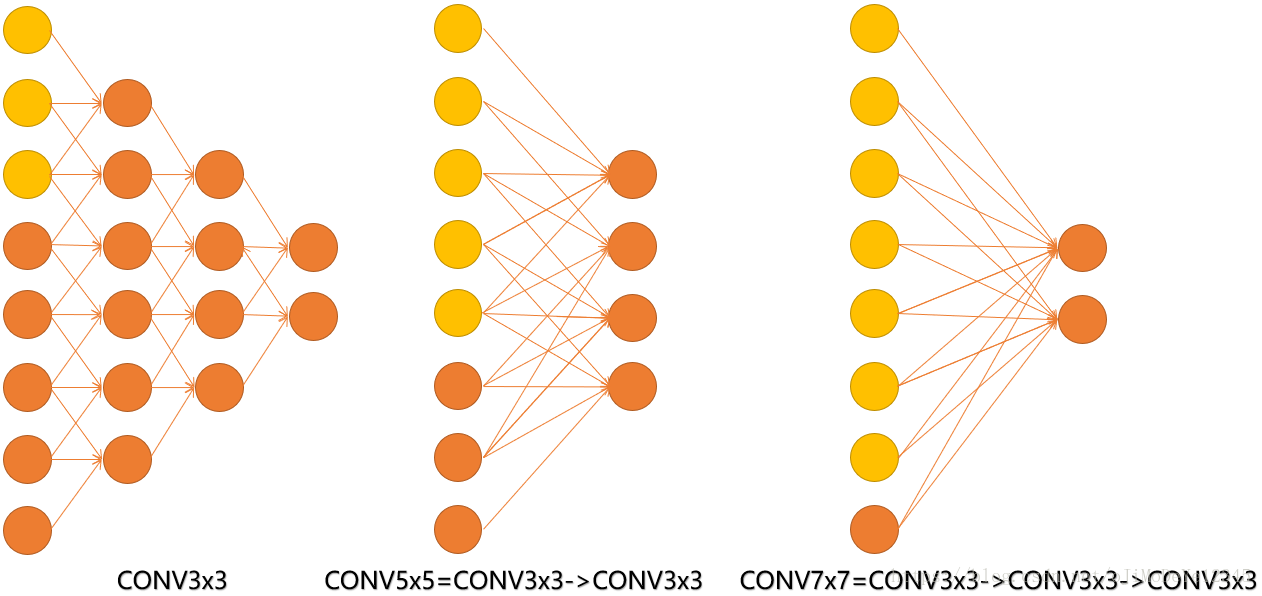
或者说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
同时,倒着看网络,也就是反向传播过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
三.结论
本文评估了深度卷积网络(到19层)在大规模图片分类中的应用。
结果表明:深度有益于提高分类的正确率。
How:通过在传统的卷积网络框架中使用更深的层能够在ImageNet数据集上取得优异的结果。
附录中,展示了我们的模型可以很好的泛化到更多数据集种,性能达到甚至超过了围绕较浅深度的图像表达建立的更复杂的识别流程。
我们的实验结果再次确认了深度在视觉表达中的重要性。
四、VGGNet使用PyTorch框架实现
项目地址:VGGNet | Kaggle
import torch
from torch import nn
import sys
sys.path.append("../input/d2ld2l")
import d2l
from d2l.torch import load_data_fashion_mnist
from d2l.torch import train_ch6
from d2l.torch import try_gpudef vgg_block(num_convs,in_channels,out_channels):layers = []for _ in range(num_convs):layers.append(nn.Conv2d(in_channels,out_channels,kernel_size=3,padding=1))layers.append(nn.ReLU())in_channels = out_channelslayers.append(nn.MaxPool2d(kernel_size=2,stride=2))return nn.Sequential(*layers)conv_arch = ((1,64),(1,128),(2,256),(2,512),(2,512))def vgg(conv_arch, class_num):conv_layers = []in_channels = 1for (num_convs, out_channels) in conv_arch:conv_layer = vgg_block(num_convs, in_channels, out_channels)conv_layers.append(conv_layer)in_channels = out_channelsreturn nn.Sequential(*conv_layers,nn.Flatten(),nn.Linear(out_channels * 7 * 7, 4096),nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 4096),nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(4096, 10))ratio = 4
small_conv_arch = [(v[0],v[1]//4) for v in conv_arch]
net = vgg(small_conv_arch,10)lr,num_epochs,batch_size = 0.05,10,128
train_iter,test_iter = load_data_fashion_mnist(batch_size,resize = 244)
train_ch6(net,train_iter,test_iter,num_epochs,lr,try_gpu())五、VGGNet使用keras框架实现
from keras.models import Sequential
from keras.layers import Conv2D, AveragePooling2D, Flatten, Dense, Activation, MaxPool2D, BatchNormalization, Dropout, ZeroPadding2D1、VGG-16 (configuration D)
model = Sequential()# first block
model.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same',input_shape=(224,224, 3)))
model.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))# second block
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))# third block
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))# forth block
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))# fifth block
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
model.add(MaxPool2D(pool_size=(2,2), strides=(2,2)))# sixth block (classifier)
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))model.summary()2、VGG-19 (configuration E)
vgg_19 = Sequential()# first block
vgg_19.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same',input_shape=(224,224, 3)))
vgg_19.add(Conv2D(filters=64, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(MaxPool2D((2,2), strides=(2,2)))# second block
vgg_19.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=128, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(MaxPool2D((2,2), strides=(2,2)))# third block
vgg_19.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=256, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(MaxPool2D((2,2), strides=(2,2)))# forth block
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(MaxPool2D((2,2), strides=(2,2)))# fifth block
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(Conv2D(filters=512, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same'))
vgg_19.add(MaxPool2D((2,2), strides=(2,2)))# seventh block (classifier)
vgg_19.add(Flatten())
vgg_19.add(Dense(4096, activation='relu'))
vgg_19.add(Dropout(0.5))
vgg_19.add(Dense(4096, activation='relu'))
vgg_19.add(Dropout(0.5))
vgg_19.add(Dense(1000, activation='softmax'))vgg_19.summary()参考:
CNN经典网络模型(三):VGGNet简介及代码实现(PyTorch超详细注释版)_vggnet是哪年发明的_华科附小第一名的博客-CSDN博客
卷积神经网络VGG Net论文细读 - 幕布 (mubu.com)
【论文精读3】VGGNet——《Very Deep Convolutional Networks for Large-Scale Image Recognition》 - 知乎 (zhihu.com)
【论文阅读】《very deep convolutional networks for large-scale image recognition》 - 知乎 (zhihu.com)
)












)



(神坑官网也不说明一下))
、readline()、readlines() 函数 读取文件)
