一、单Mysql节点
假如一主一从
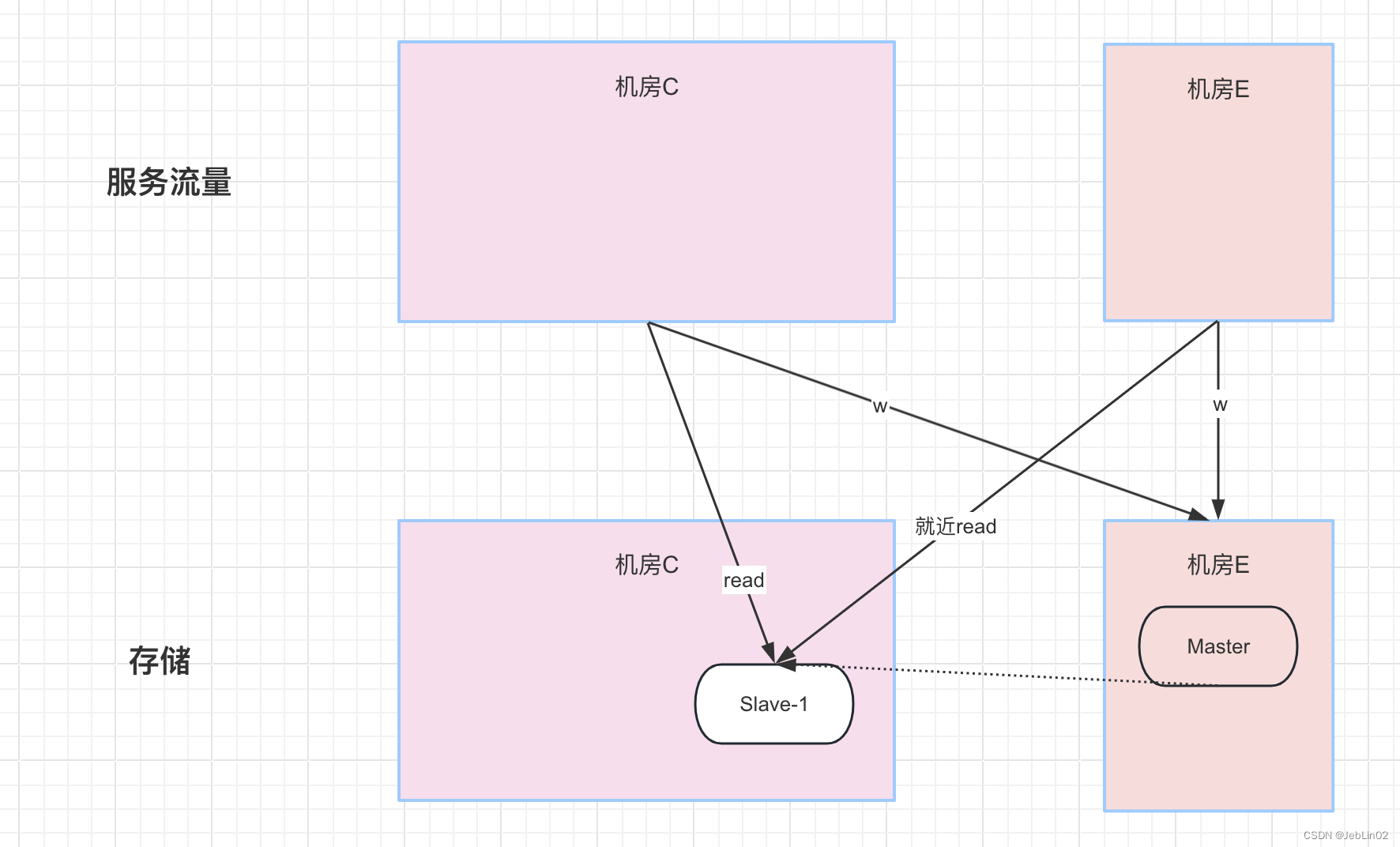
为什么不能无限读?
瓶颈分析:
-
资源限制: 如CPU、内存、磁盘I/O、网络带宽等。随着读请求的增加,服务器的负载将会增加,甚至可能导致系统崩溃。
-
连接数限制: MySQL有最大连接数的限制。超出限制抛异常。
-
锁和并发控制: 大量读请求可能导致锁的争用。
SELECT ... FOR SHARE或者SELECT ... LOCK IN SHARE MODE -
缓存频繁失效: 数据库有查询缓存功能,高并发读请求会导致缓存失效
调用方的直观感觉:
- 响应增加
- 数据库链接失败
为什么不能无限写?
瓶颈分析:
-
主从复制延迟: 大量的写入操作可能会增加复制的延迟,导致从库数据同步滞后。(主从延迟耗时超过1秒告警)
-
磁盘空间问题: 大量写入操作可能导致磁盘空间迅速耗尽(需要有70%红线预警)
-
无限读的那4个瓶颈。
调用方的直观感觉:
- 由于读的是从库,由于主从延迟,会一直读不到最新的数据。
- 响应增加
- 数据库链接失败
最佳实践:单库读超过 1WQPS、写超过5000 就要预警
二、一主多从
目的:
- 为了应付更多的读写请求
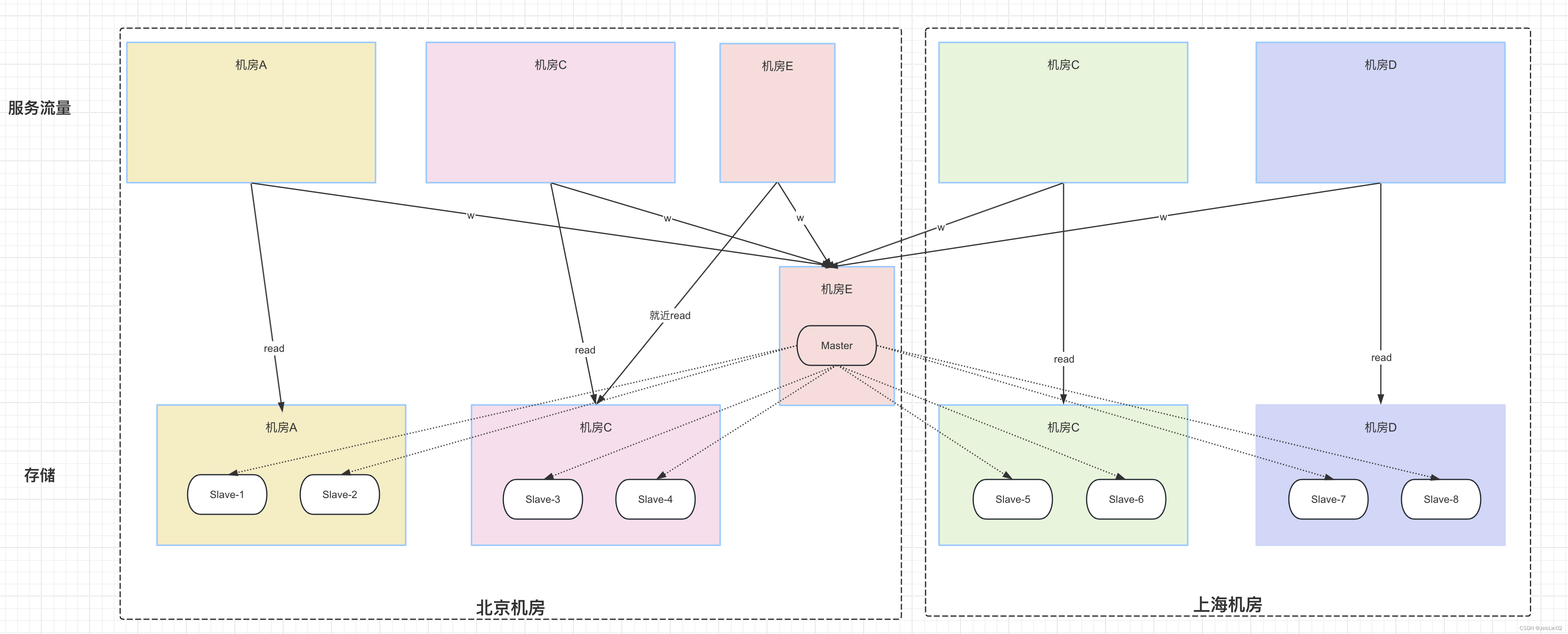
将Mysql设置1主8从,每2个从节点放到一个机房,后续同机房的服务流量能降低延迟。
三、分库分表
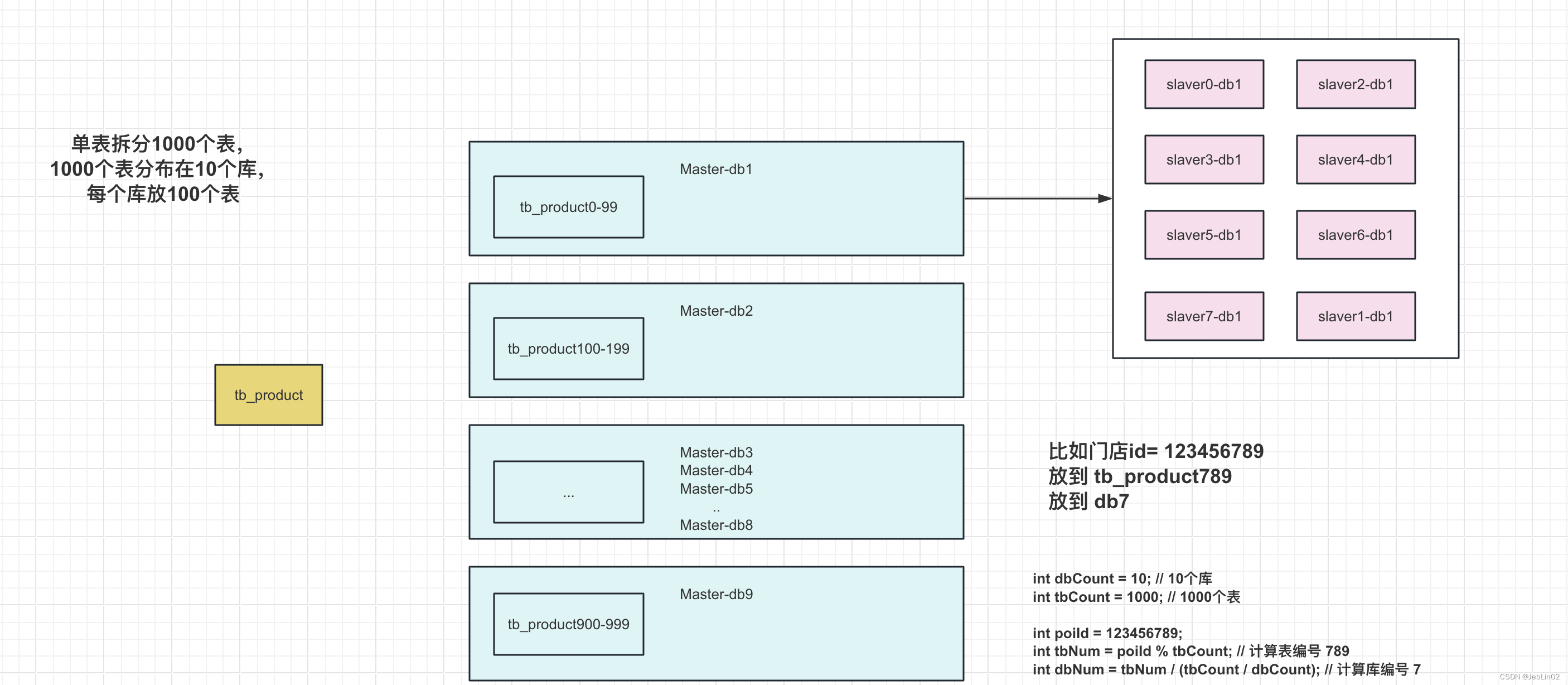
路由规则
- 表 shard 规则:table_num = 分表字段 % 1000
- 库 shard 规则:db_num = table_num / (1000 / 10)。
单表拆分1000个表,
1000个表分布在10个库,每个库放100个表db0 放 tb_[0-99]
db1 放 tb_[100-199]
db2 放 tb_[200-299]
...
db9 放 tb_[900-999]比如商品table根据门店id分段,
假如门店id是 123456789,那么就分到了
table_789 (门店id % 1000)
table_789 是放到 db7 里面 (门店id % 10)---
int dbCount = 10; // 10个库
int tbCount = 1000; // 1000个表int poiId = 123456789;
int tbNum = poiId % tbCount; // 计算表编号 789
int dbNum = tbNum / (tbCount / dbCount); // 计算库编号 7System.out.println("Table: tb_" + tbNum + ", Database: db" + dbNum);四、数据迁移过程
1、双写新老库

思考问题:
- insert老table失败,insert新table成功怎么办?(先写老table,失败直接抛Exception,不走后面的写新table,接口返回失败)
- insert老table成功,insert新table失败 (则捕获异常,记录log并发消息给MQ,或者存到mysql 某个table,后续处理,接口返回成功)
- update同上
2、存量数据复制
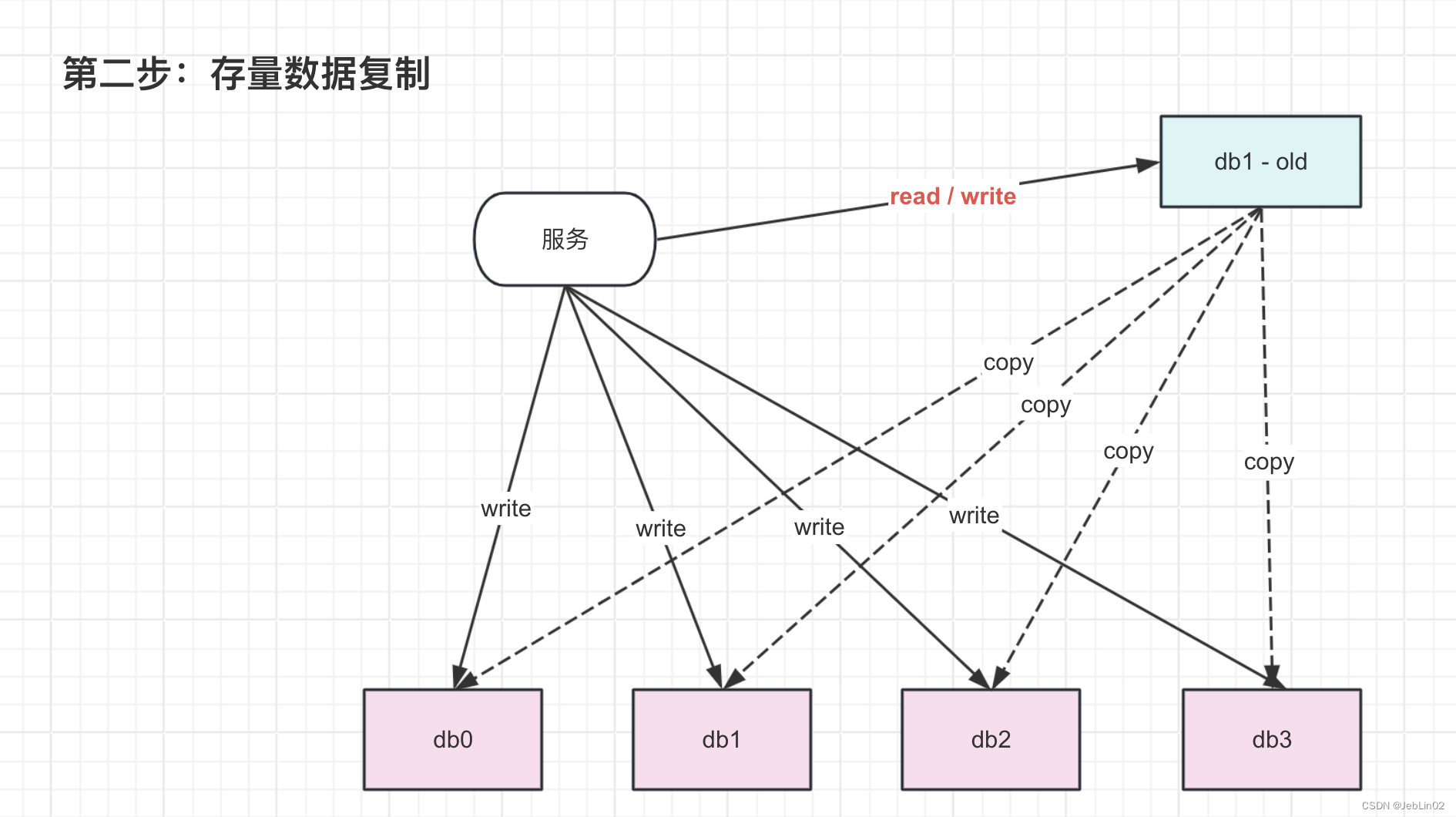
- 新增情况采用insert ... ignore.. (避免因错误或异常数据导致这一批次插入丢失,如果主键id 数字单调递增,基本不会出现这个情况)
- copy过程准备插入数据 row1,row2,row3到新库,但是新库存在row2
- 此时由于 ignore,于是插入了 row1,row3
- 但是row2的数据其实是脏的,那么就出现脏数据
- update过程中发生脏数据
- copy线程复制了数据,还没写入(假如就是延时或者刚好发生了gc导致停顿)
- a线程先update老库,然后update新库的时候,由于数据还没写入,那么会update row = 0,然后copy线程
- copy线程写入数据到新库,此时新库的数据是过时的,属于脏数据。更新操作丢失
- delete过程同上,老库已经删了,新库又给插了一条进去。删除操作丢失
3、数据检查

- 批量读取老库数据,比如每次一千条(注意深分页问题,别一味 limit page,size )
- 与新库数据进行对比(一切以老库数据为准)
- 如果新库缺数据,那么就insert
- 如果新库存在数据,但是数据不一致,那么更新新库数据(ctime、utime看情况可以不比对,可以忽略)
- 如果存在新库存在老库不存在的数据,那么直接删除
4、灰度切读与观察
5% 10% 20% ... 100%
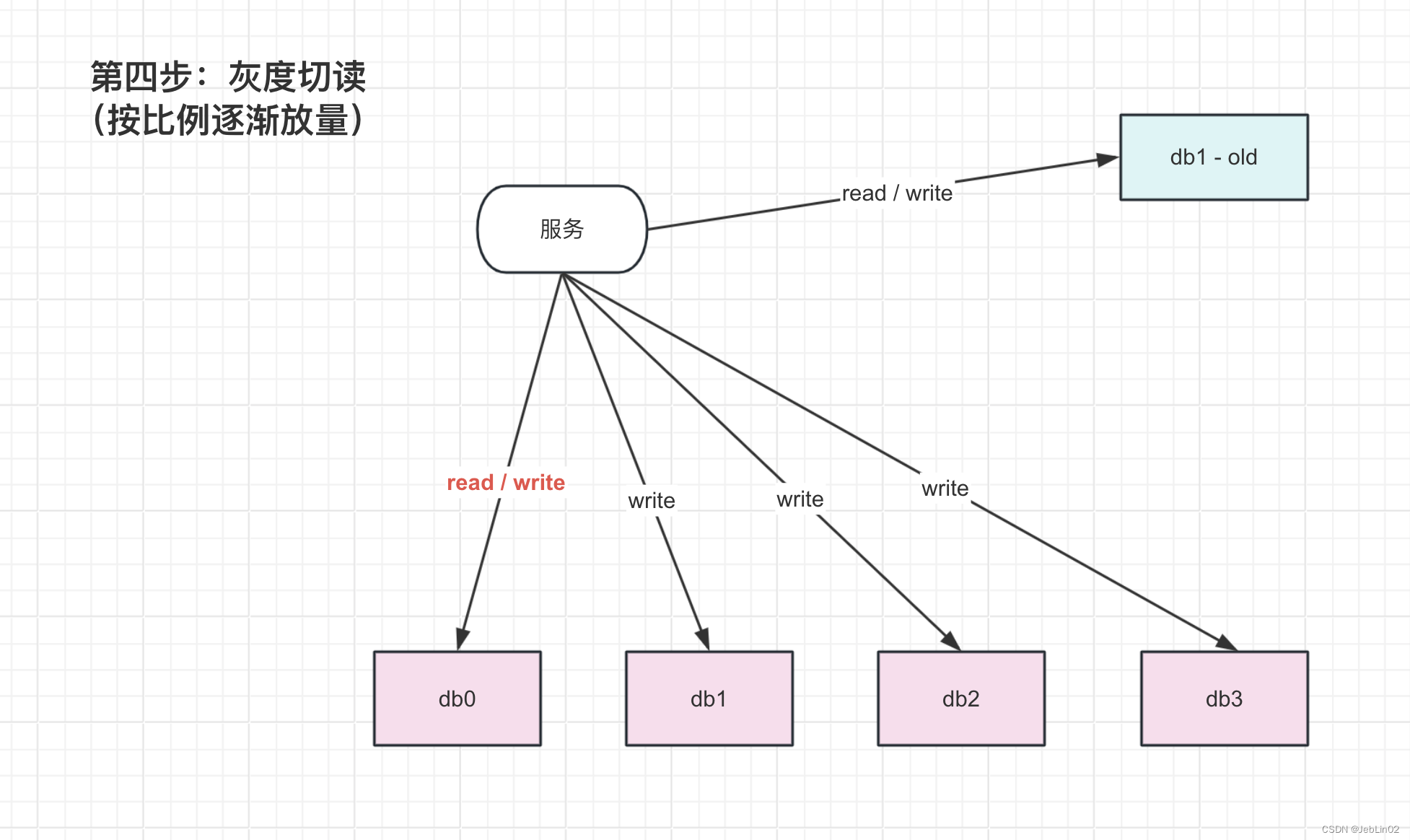
有问题就回滚,切换开关
5、全量切读与观察

建议持续个一两周,最后再下掉~
6、停双写,数据迁移完成
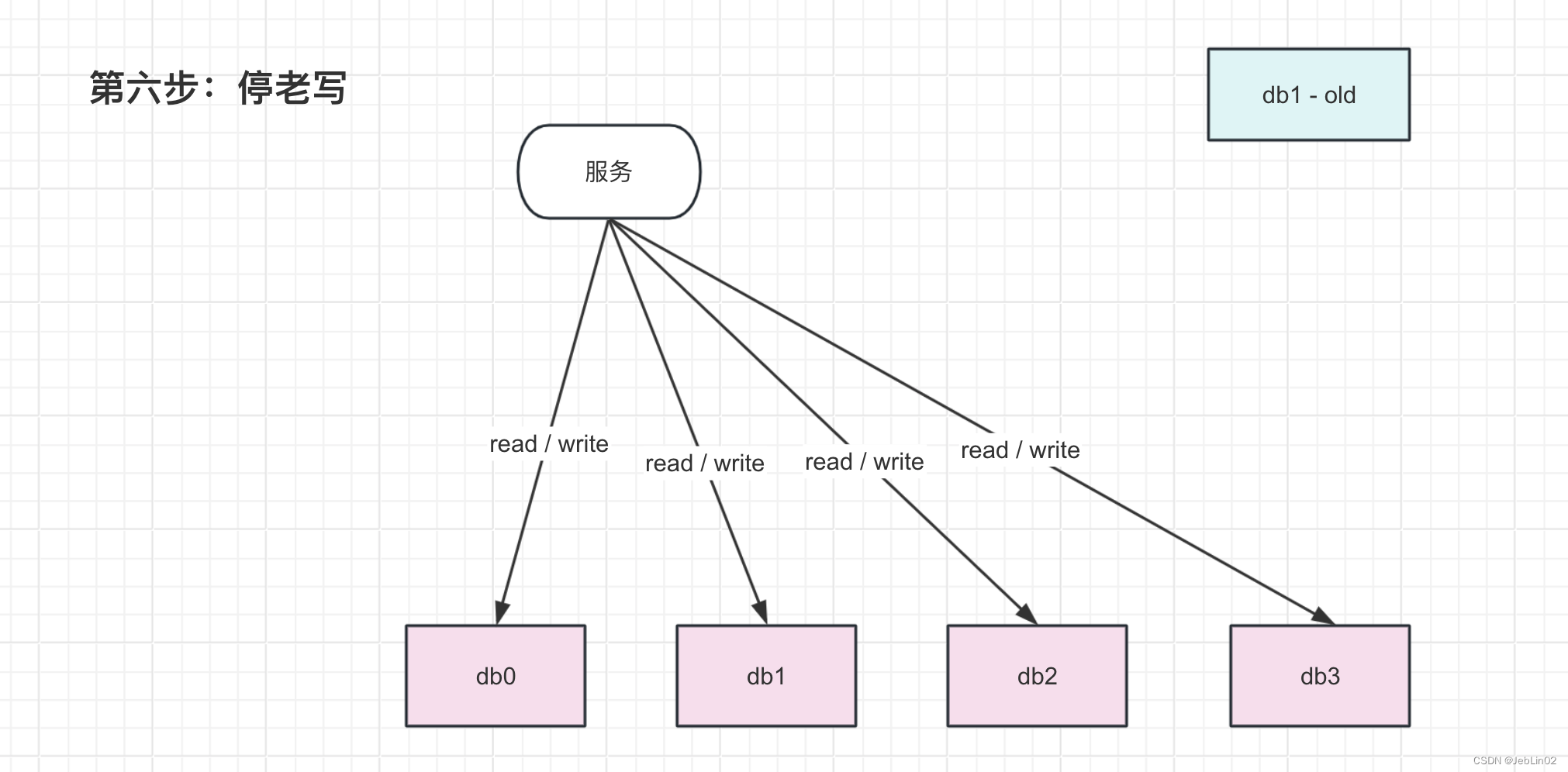






】)


)









