文章目录 一、改写文本分类 1.导入相关包 2.加载数据集 3.划分数据集 4.数据集预处理 5.创建模型 6.创建评估函数 7.创建 TrainingArguments 8.创建 Trainer 9.模型训练 10.模型评估 11.模型预测 二、交互/单塔模式 1.导入相关包 2.加载数据集 3.划分数据集 4.数据集预处理 5.创建模型(区别) 6.创建评估函数(区别) 7.创建 TrainingArguments 8.创建 Trainer 9.模型训练 10.模型评估 11.模型预测(区别)
!pip install transformers datasets evaluate accelerate
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
dataset = load_dataset("json", data_files="./train_pair_1w.json", split="train")
dataset
'''
Dataset({features: ['sentence1', 'sentence2', 'label'],num_rows: 10000
})
'''
dataset[ : 3 ]
'''
{'sentence1': ['找一部小时候的动画片','我不可能是一个有鉴赏能力的行家,小姐我把我的时间都花在书写上;象这样豪华的舞会,我还是头一次见到。','胡子长得太快怎么办?'],'sentence2': ['求一部小时候的动画片。谢了', '蜡烛没熄就好了,夜黑得瘆人,情绪压抑。', '胡子长得快怎么办?'],'label': ['1', '0', '1']}
'''
datasets = dataset. train_test_split( test_size= 0.2 , seed= 3407 )
datasets[ 'train' ] [ 'sentence1' ] [ 0 ]
'''
王琦瑶说:你家阿大二十岁已经有儿有女了嘛
'''
import torchtokenizer = AutoTokenizer. from_pretrained( "hfl/chinese-macbert-base" ) def process_function ( examples) : tokenized_examples = tokenizer( examples[ "sentence1" ] , examples[ "sentence2" ] , max_length= 128 , truncation= True ) tokenized_examples[ "labels" ] = [ int ( label) for label in examples[ "label" ] ] return tokenized_examplestokenized_datasets = datasets. map ( process_function, batched= True , remove_columns= datasets[ "train" ] . column_names)
tokenized_datasets
'''
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 8000})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 2000})
})
'''
from transformers import BertForSequenceClassification
model = AutoModelForSequenceClassification. from_pretrained( "hfl/chinese-macbert-base" , num_labels= 2 )
import evaluateacc_metric = evaluate. load( "accuracy" )
f1_metirc = evaluate. load( "f1" )
def eval_metric ( eval_predict) : predictions, labels = eval_predictlabels = [ int ( l) for l in labels] predictions = predictions. argmax( axis= - 1 ) acc = acc_metric. compute( predictions= predictions, references= labels) f1 = f1_metirc. compute( predictions= predictions, references= labels) acc. update( f1) return acc
train_args = TrainingArguments( output_dir= "./cross_model" , per_device_train_batch_size= 32 , per_device_eval_batch_size= 32 , logging_steps= 10 , evaluation_strategy= "epoch" , save_strategy= "epoch" , save_total_limit= 3 , learning_rate= 2e-5 , weight_decay= 0.01 , metric_for_best_model= "f1" , load_best_model_at_end= True )
train_args
'''
TrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./cross_model/runs/Nov27_07-11-23_66feef283143,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=./cross_model,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=32,
per_device_train_batch_size=32,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./cross_model,
save_on_each_node=False,
save_safetensors=True,
save_steps=500,
save_strategy=epoch,
save_total_limit=3,
seed=42,
skip_memory_metrics=True,
split_batches=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.01,
)
'''
from transformers import DataCollatorWithPadding
trainer = Trainer( model= model, args= train_args, train_dataset= tokenized_datasets[ "train" ] , eval_dataset= tokenized_datasets[ "test" ] , data_collator= DataCollatorWithPadding( tokenizer= tokenizer) , compute_metrics= eval_metric)
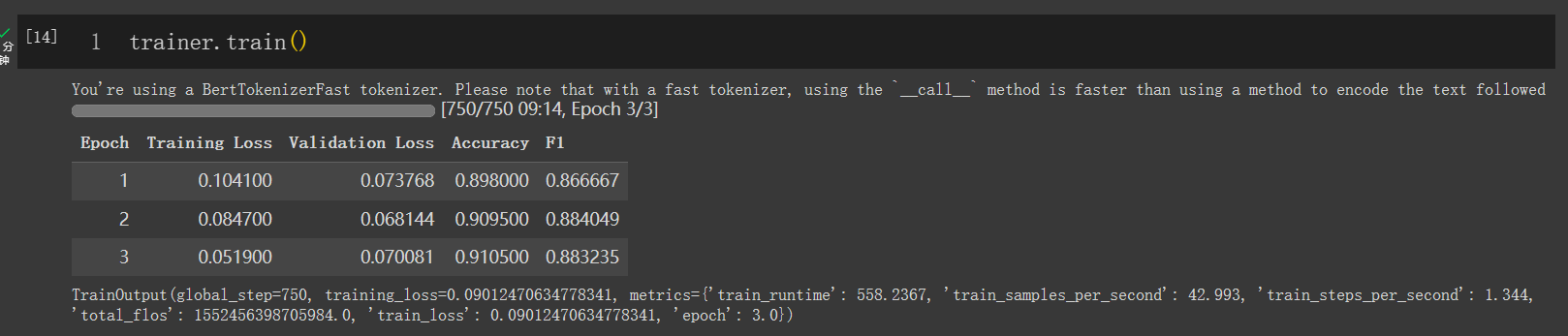
trainer. train( )
trainer. evaluate( tokenized_datasets[ "test" ] )
from transformers import pipeline, TextClassificationPipelinemodel. config. id2label = { 0 : "不相似" , 1 : "相似" }
pipe = pipeline( "text-classification" , model= model, tokenizer= tokenizer, device= 0 ) result = pipe( { "text" : "我喜欢北京" , "text_pair" : "天气" } )
result[ "label" ] = "相似" if result[ "score" ] > 0.5 else "不相似"
result
'''
{'label': '不相似', 'score': 0.8792306780815125}
'''
result = pipe( { "text" : "我喜欢北京" , "text_pair" : "我喜欢北京" } )
result
'''
{'label': '相似', 'score': 0.9374899864196777}
'''
label 设为 1,代表两个句子的相似度分数,通过设置阈值来判断类别 对于同一个句子 A,存在若干候选句子,要找到与句子 A 最相似的某个候选句子(上述文本分类处理方式无法解决),此处将分类任务作为回归任务+阈值的方式进行处理,从而能够得到预测的得分,该得分可以用来判断 哪个候选句子与给定句子最相似 from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
dataset = load_dataset( "json" , data_files= "./train_pair_1w.json" , split= "train" )
dataset
'''
Dataset({features: ['sentence1', 'sentence2', 'label'],num_rows: 10000
})
'''
dataset[ : 3 ]
'''
{'sentence1': ['找一部小时候的动画片','我不可能是一个有鉴赏能力的行家,小姐我把我的时间都花在书写上;象这样豪华的舞会,我还是头一次见到。','胡子长得太快怎么办?'],'sentence2': ['求一部小时候的动画片。谢了', '蜡烛没熄就好了,夜黑得瘆人,情绪压抑。', '胡子长得快怎么办?'],'label': ['1', '0', '1']}
'''
datasets = dataset. train_test_split( test_size= 0.2 , seed= 3407 )
datasets[ 'train' ] [ 'sentence1' ] [ 0 ]
'''
王琦瑶说:你家阿大二十岁已经有儿有女了嘛
'''
import torchtokenizer = AutoTokenizer. from_pretrained( "hfl/chinese-macbert-base" ) def process_function ( examples) : tokenized_examples = tokenizer( examples[ "sentence1" ] , examples[ "sentence2" ] , max_length= 128 , truncation= True ) tokenized_examples[ "labels" ] = [ float ( label) for label in examples[ "label" ] ] return tokenized_examplestokenized_datasets = datasets. map ( process_function, batched= True , remove_columns= datasets[ "train" ] . column_names) tokenized_datasets
'''
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 8000})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 2000})
}
'''
print ( tokenized_datasets[ "train" ] [ 0 ] )
'''
{'input_ids': [101, 4374, 4425, 4457, 6432, 131, 872, 2157, 7350, 1920, 753, 1282, 2259, 2347, 5307, 3300, 1036, 3300, 1957, 749, 1658, 102, 7350, 1920, 1372, 3300, 1036, 2094, 3766, 3300, 1957, 1036, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'labels': 0.0}
'''
from transformers import BertForSequenceClassification model = AutoModelForSequenceClassification. from_pretrained( "hfl/chinese-macbert-base" , num_labels= 1 )
import evaluateacc_metric = evaluate. load( "accuracy" )
f1_metirc = evaluate. load( "f1" )
def eval_metric ( eval_predict) : predictions, labels = eval_predictpredictions = [ int ( p > 0.5 ) for p in predictions] labels = [ int ( l) for l in labels] acc = acc_metric. compute( predictions= predictions, references= labels) f1 = f1_metirc. compute( predictions= predictions, references= labels) acc. update( f1) return acc
train_args = TrainingArguments( output_dir= "./cross_model" , per_device_train_batch_size= 32 , per_device_eval_batch_size= 32 , logging_steps= 10 , evaluation_strategy= "epoch" , save_strategy= "epoch" , save_total_limit= 3 , learning_rate= 2e-5 , weight_decay= 0.01 , metric_for_best_model= "f1" , load_best_model_at_end= True ) train_args
'''
TrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./cross_model/runs/Nov27_06-35-36_66feef283143,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=./cross_model,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=32,
per_device_train_batch_size=32,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./cross_model,
save_on_each_node=False,
save_safetensors=True,
save_steps=500,
save_strategy=epoch,
save_total_limit=3,
seed=42,
skip_memory_metrics=True,
split_batches=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.01,
)
'''
from transformers import DataCollatorWithPadding
trainer = Trainer( model= model, args= train_args, train_dataset= tokenized_datasets[ "train" ] , eval_dataset= tokenized_datasets[ "test" ] , data_collator= DataCollatorWithPadding( tokenizer= tokenizer) , compute_metrics= eval_metric)
trainer. train( )
'''
TrainOutput(global_step=750, training_loss=0.09012470634778341, metrics={'train_runtime': 558.2367, 'train_samples_per_second': 42.993, 'train_steps_per_second': 1.344, 'total_flos': 1552456398705984.0, 'train_loss': 0.09012470634778341, 'epoch': 3.0})
'''
trainer. evaluate( tokenized_datasets[ "test" ] )
'''
{'eval_loss': 0.06814368069171906,'eval_accuracy': 0.9095,'eval_f1': 0.8840486867392696,'eval_runtime': 14.6336,'eval_samples_per_second': 136.672,'eval_steps_per_second': 4.305,'epoch': 3.0}
'''
from transformers import pipeline, TextClassificationPipelinemodel. config. id2label = { 0 : "不相似" , 1 : "相似" } pipe = pipeline( "text-classification" , model= model, tokenizer= tokenizer, device= 0 )
result = pipe( { "text" : "我喜欢北京" , "text_pair" : "天气怎样" } , function_to_apply= "none" )
result[ "label" ] = "相似" if result[ "score" ] > 0.5 else "不相似" result
'''
{'label': '不相似', 'score': -0.025799434632062912}
'''

介绍)
)


![[Oracle]编写程序,键盘输入n,计算1+前n项之和。测试案例:输入:10 输出:22.47](http://pic.xiahunao.cn/[Oracle]编写程序,键盘输入n,计算1+前n项之和。测试案例:输入:10 输出:22.47)

——请求映射)












![[ Vue3 ] 组合式API + Setup语法糖 如何获取组件实例?](http://pic.xiahunao.cn/[ Vue3 ] 组合式API + Setup语法糖 如何获取组件实例?)