目录
一、sed简介(行编辑器)
二、基本用法
三、sed脚本格式(匹配地址 脚本命令)
1、不给地址,那么就是针对全文处理
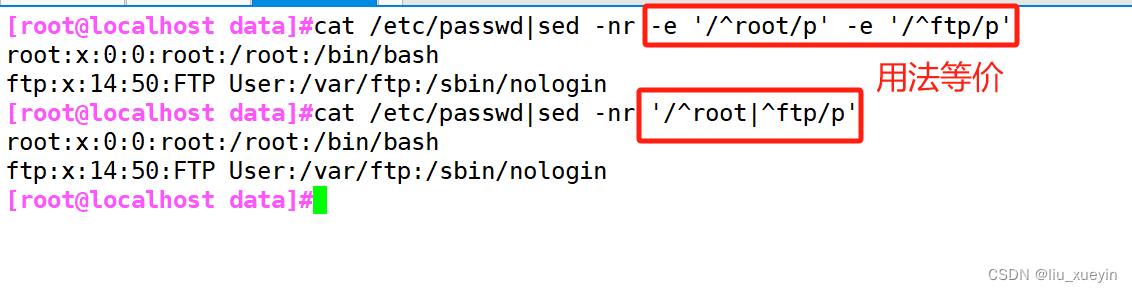
2、单地址,表示#,指定的行,$表示最后一行,/pattter/:表示该模式能匹配到的每一行,正则表达式
3、地址范围:
#,# 从第几行到第几行
#,+#从第几行开始,往后加4行
/patter1/,/patter2/ 表示从第一个开始找,到第二个结束
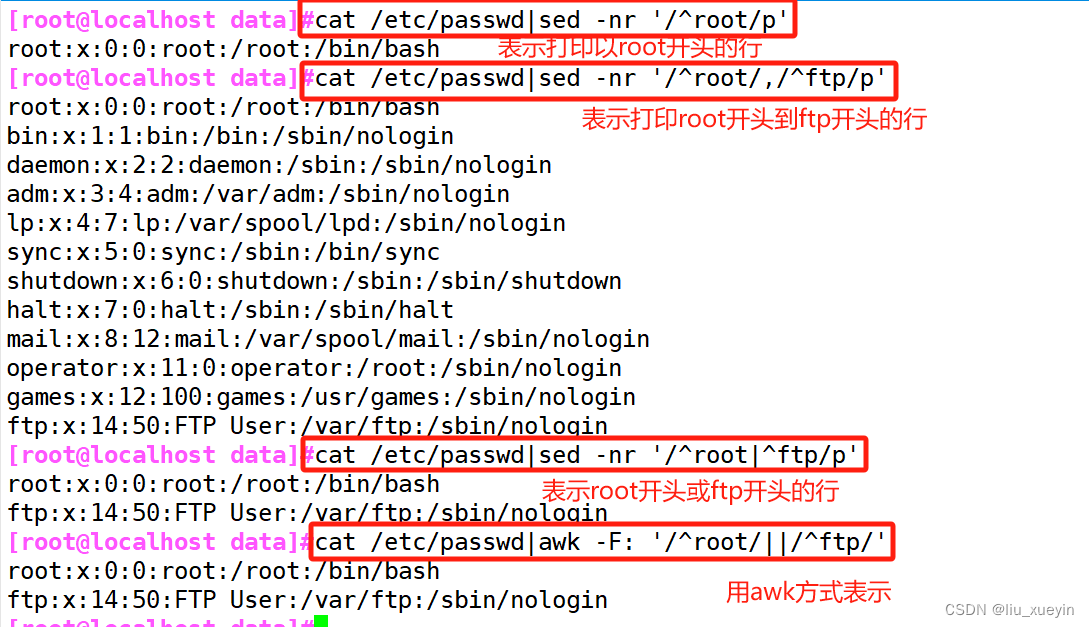
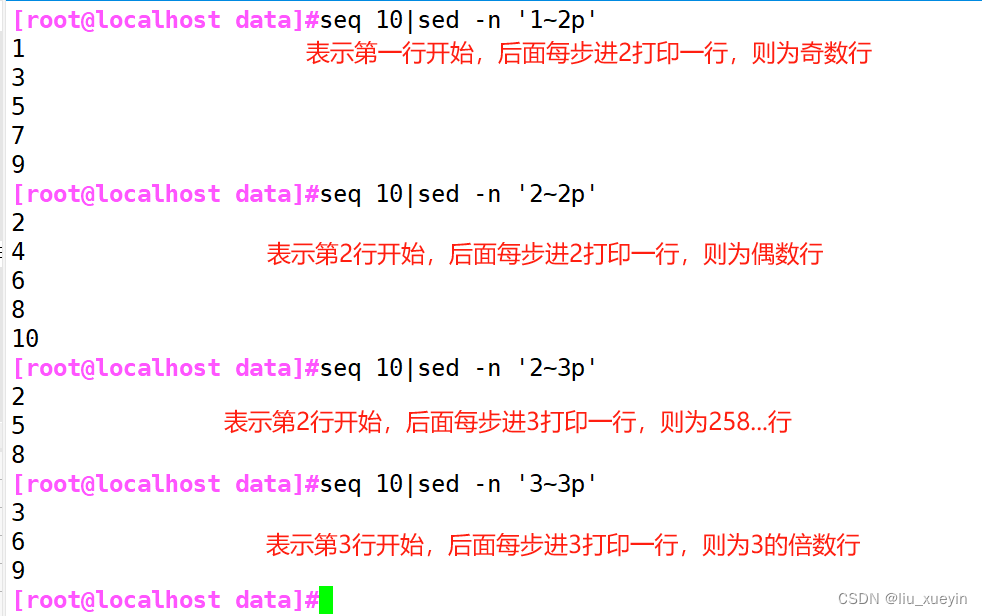
4、步进:~
1~2:表示奇数行
2~2:表示偶数行
3~3:表示可以3的倍数行
5、高级空间用法
sed -n 'n;p' 表示打印偶数行,表示从第一行开始,先放入高级空间,下一行打印,反复以往,表示打印偶数行
sed -n '2,${n;p}' 表示奇数行,表示从第二行开始,先放入高级空间,下一行打印,反复以往,表示打印奇数行
四、搜索替代
五、分组后项引用
面试题一:可以自定义输出匹配内容的顺序
面试题二:使用sed的分组后项引用来提取ip地址
面试题三:提取版本号
面试题四:提取文件的权限
面试题五:提取访问日志中的状态码
面试题六、提取日志的状态码
一、sed简介(行编辑器)
Sed是从文件或管道中读取一行,处理一行,输出一行;再读取一行,再处理一行,再输出一行,直到最后一行。每当处理一行时,把当前处理的行存储在临时缓冲区中,称为模式空间(PatternSpace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。一次处理一行的设计模式使得sed性能很高,sed在读取大文件时不会出现卡顿的现象。如果使用vi命令打开几十M上百M的文件,明显会出现有卡顿的现象,这是因为vi命令打开文件是一次性将文件加载到内存,然后再打开。Sed就避免了这种情况,一行一行的处理,打开速度非常快,执行速度也很快。
sed支持 标准输入、标准输出、文件名

二、基本用法
语法:sed [命令选项] '匹配地址 脚本命令' 文件名或标准输出或标准输入
常用的命令选项:
| 选项 | 功能 |
| -n | 不输出模式空间的内容到屏幕,即不自动打印 |
| -e | 多点编辑器,相当于/匹配1|匹配2/ |
| -f filename | 从指定文件中读取编辑脚本 |
| -r,-E | 使用扩展正则表达式 |
| -i.bak | 备份文件并原处编辑 |
| #说明: -ir 不支持 -i -r 支持 -ri 支持 -ni 会清空文件 | |

sed -i 作为行编辑器,一旦生效,无法撤回,所以强烈建议修改的时候加上-i.bak,可以进行备份
[root@localhost data]#sed -i.bak '1,4d' html.txt
[root@localhost data]#cat html.txt
http://www.google.com/index.html
http://www.yahoo.com.cn/put.html
[root@localhost data]#ls
123.txt html.txt html.txt.bak md5.txt sort.sh uniq.sh
[root@localhost data]#cat html.txt.bak ##bak也可以是别的字母,只是因为bak是backup的缩写,所以常使用bak
三、sed脚本格式(匹配地址 脚本命令)
1、不给地址,那么就是针对全文处理

2、单地址,表示#,指定的行,$表示最后一行,/pattter/:表示该模式能匹配到的每一行,正则表达式
3、地址范围:
#,# 从第几行到第几行
#,+#从第几行开始,往后加4行
/patter1/,/patter2/ 表示从第一个开始找,到第二个结束


4、步进:~
1~2:表示奇数行
2~2:表示偶数行
3~3:表示可以3的倍数行
5、高级空间用法
sed -n 'n;p' 表示打印偶数行,表示从第一行开始,先放入高级空间,下一行打印,反复以往,表示打印偶数行
sed -n '2,${n;p}' 表示奇数行,表示从第二行开始,先放入高级空间,下一行打印,反复以往,表示打印奇数行
这些脚本命令一般与命令选项-i一起搭配使用
脚本命令,操作
p:打印,如果是同时指定行,表示打印指定行;如果不指定行,则表示打印所有内容;如果有非打印字符,则以ASCII码输出。其通常与“-n”选项一起使用。
q:表示到第几行就退出,必须从第一行开始,3q就是1-3行
s:替换,替换指定字符
d:删除,删除选定的行
a:增加,在当前行下面增加一行指定内容
i:插入,在指定行上面插入一行指定内容
c:替换,将指定的行替换为指定内容(整行替换)
y:字符替换,转换前后的字符长度要一致
=:打印行号,这个是在前一行打印
r:表示读取文件内容,放入指定行后面
w:w file 保存模式匹配的行至指定文件
! :表示模式空间中匹配行取反处理
##没有-n,单独就是3q使用,可以表示打印前几行
[root@localhost data]#cat /etc/passwd|sed '3q'
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin

[root@localhost data]#seq 5|sed '3ahhhh'[root@localhost data]#seq 5|sed '3ahhhh\n hhhh'[root@localhost data]#seq 5|sed '3a hhhh'[root@localhost data]#seq 5|sed '3a\ hhhh'





[root@localhost data]#seq 3|sed '2r /etc/issue'
1
2
\S
Kernel \r on an \m3
[root@localhost data]#seq 3|sed '2w /data/2.txt'
1
2
3
[root@localhost data]#cat 2.txt
2
四、搜索替代
s/pattern/string/修饰符 查找替换,支持使用其它分隔符,可以是其它形式:s@@@,s###
替换修饰符:
g 行内全局替换
2 表示行内的第2个匹配内容
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写sed 's/root/&er/g' /etc/passwd
#&指代之前找到的内容
替换的内容应该是一个指定的存在的内容,不可以用正则表达式,这里可以用&这个符号指代前面匹配到的内容

五、分组后项引用
虽然sed是用来一行一行处理的,但是还是可以利用分组后项引用的办法来提取有相同标志的列
两种方式:①先匹配关键字的前后部分有什么特点,②找到关键字的特点,将整行用正则表达式采用分组表示
面试题一:可以自定义输出匹配内容的顺序
面试题二:使用sed的分组后项引用来提取ip地址
[root@localhost data]#ifconfig ens33|sed -rn '2s/.*inet ([0-9.]+) .*/\1/p'
192.168.20.8
[root@localhost data]#ifconfig ens33|sed -n '2p'inet 192.168.20.8 netmask 255.255.255.0 broadcast 192.168.20.255
[root@localhost data]#
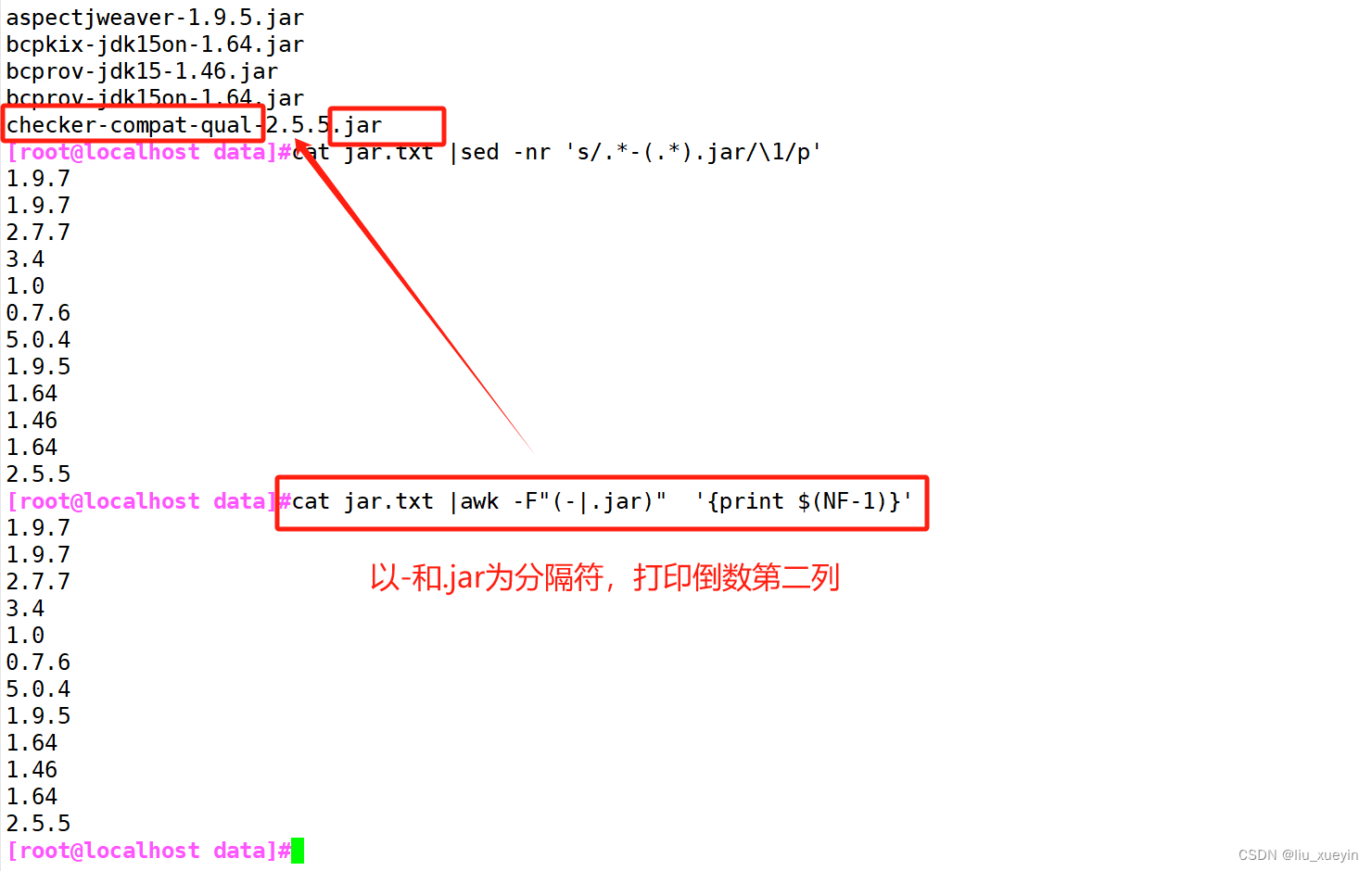
面试题三:提取版本号
[root@localhost data]#cat jar.txt |sed -nr 's/.*-(.*).jar/\1/p'
[root@localhost data]#cat jar.txt |awk -F"(-|.jar)" '{print $(NF-1)}'
面试题四:提取文件的权限
[root@localhost data]#stat 2.txt 文件:"2.txt"大小:2 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:20205496 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
最近访问:2023-11-28 18:27:04.306430260 +0800
最近更改:2023-11-28 18:26:57.672457605 +0800
最近改动:2023-11-28 18:26:57.672457605 +0800
创建时间:-
[root@localhost data]#stat 2.txt |sed -nr '4s/.*([0-9]{4}).*/\1/p'
0644[root@localhost data]#stat 2.txt |sed -n '4p'|egrep -o "[0-9]{4}"
0644[root@localhost data]#stat 2.txt |awk -F"[(/]" 'NR==4{print $2}'
0644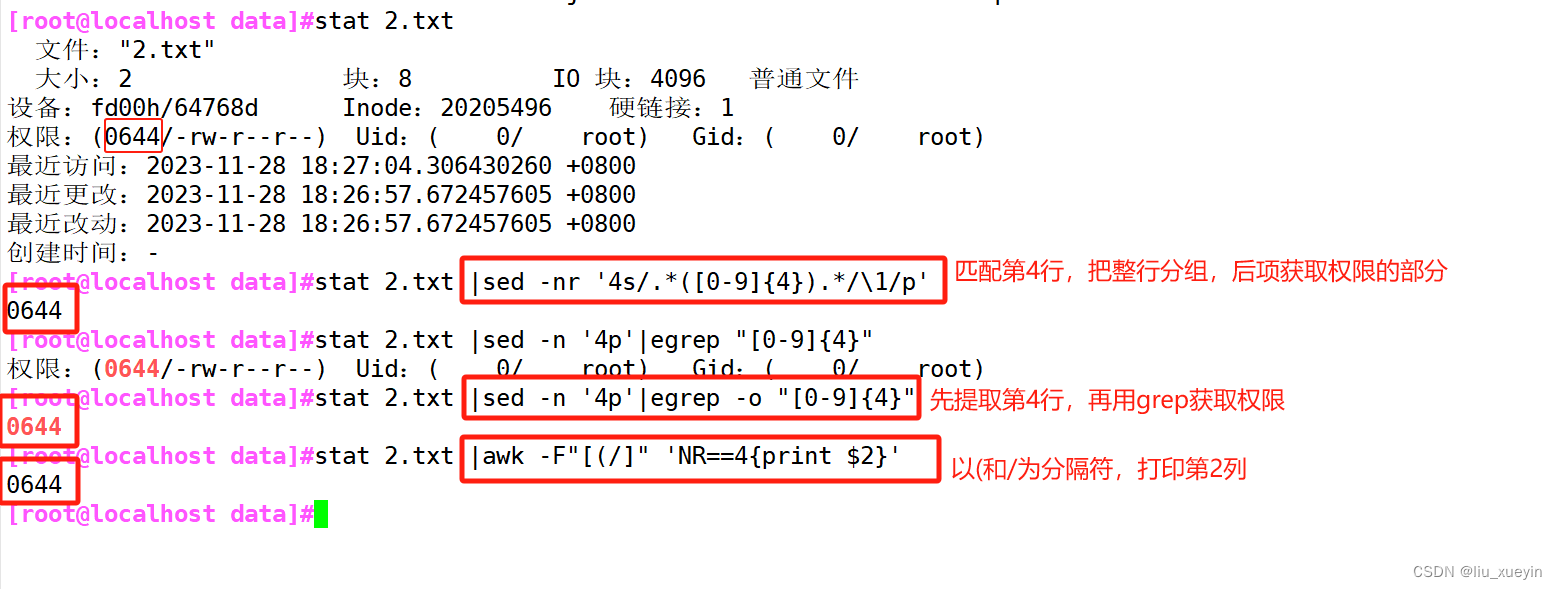
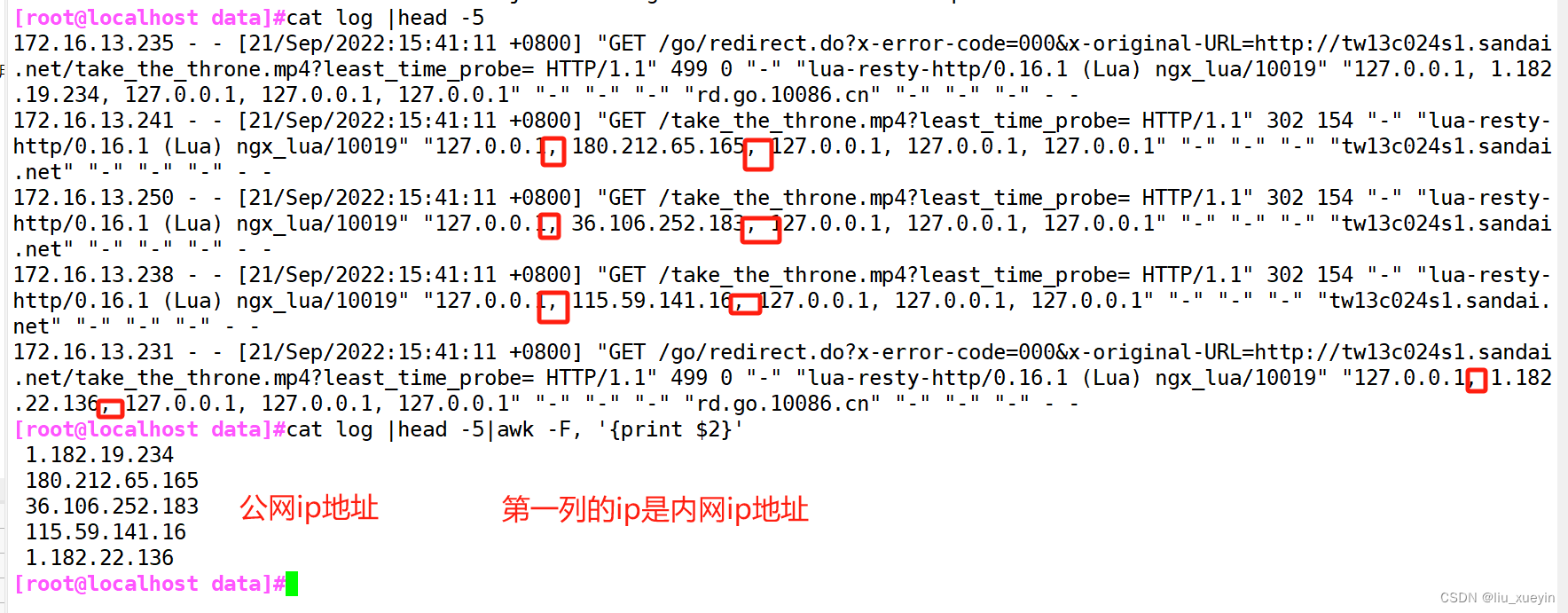
面试题五:提取访问日志中的状态码
[root@localhost data]#cat log |head -5|awk -F, '{print $2}'
面试题六、提取日志的状态码
[root@localhost data]#cat log |sed -nr 's/.*HTTP\/1.1" ([0-9]{3}) .*/\1/p'|sort|uniq -c|sort -nr48814 30227141 20020057 4991674 4041317 40397 2062 408
)








)



)




)