参考:【大模型-第一篇】在阿里云上部署ChatGLM3-CSDN博客
ChatGLM 是一个开源的、支持中英双语的对话语言模型,由智谱 AI 和清华大学 KEG 实验室联合发布,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM3-6B 更是在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上增加了更多特性。
虽然,目前 ChatGLM 比 GPT 稍有逊色,但是,在部署后可以完全本地运行,完全由自己掌控!
ChatGLM-6B 减少显存与内存占用
全量模型运行加载 GPU运行模式下需要13GB显存+14G内存,CPU运行模式下需要28GB内存,如果你电脑没这么大显存或者内存,可以通过加载量化模型减少显存与内存占用
参考:使用 CPU 本地安装部署运行 ChatGLM-6B 获得自己的专属 AI 猫娘 — 秋风于渭水 (tjsky.net)
硬件与软件准备
- 随便一个CPU(差不多就行,毕竟我看网友还有用赛扬N6210这种东西跑的)
- 至少32GB的内存(因为模型运行大概需要23~25GB内存)
- 大于30GB硬盘可用空间
- 最好有SSD(最开始要将模型读到内存中,模型本体大概就需要占用11GB内存,使用HDD会经历一个漫长的启动过程)

参考:https://blog.csdn.net/qq_41773806/article/details/134189261
1、在阿里云上申请注册及登录并完成认证
2、登录阿里云 免费试用 页面 https://free.aliyun.com/?product=1395&crowd=personal
3、 选择试用产品:
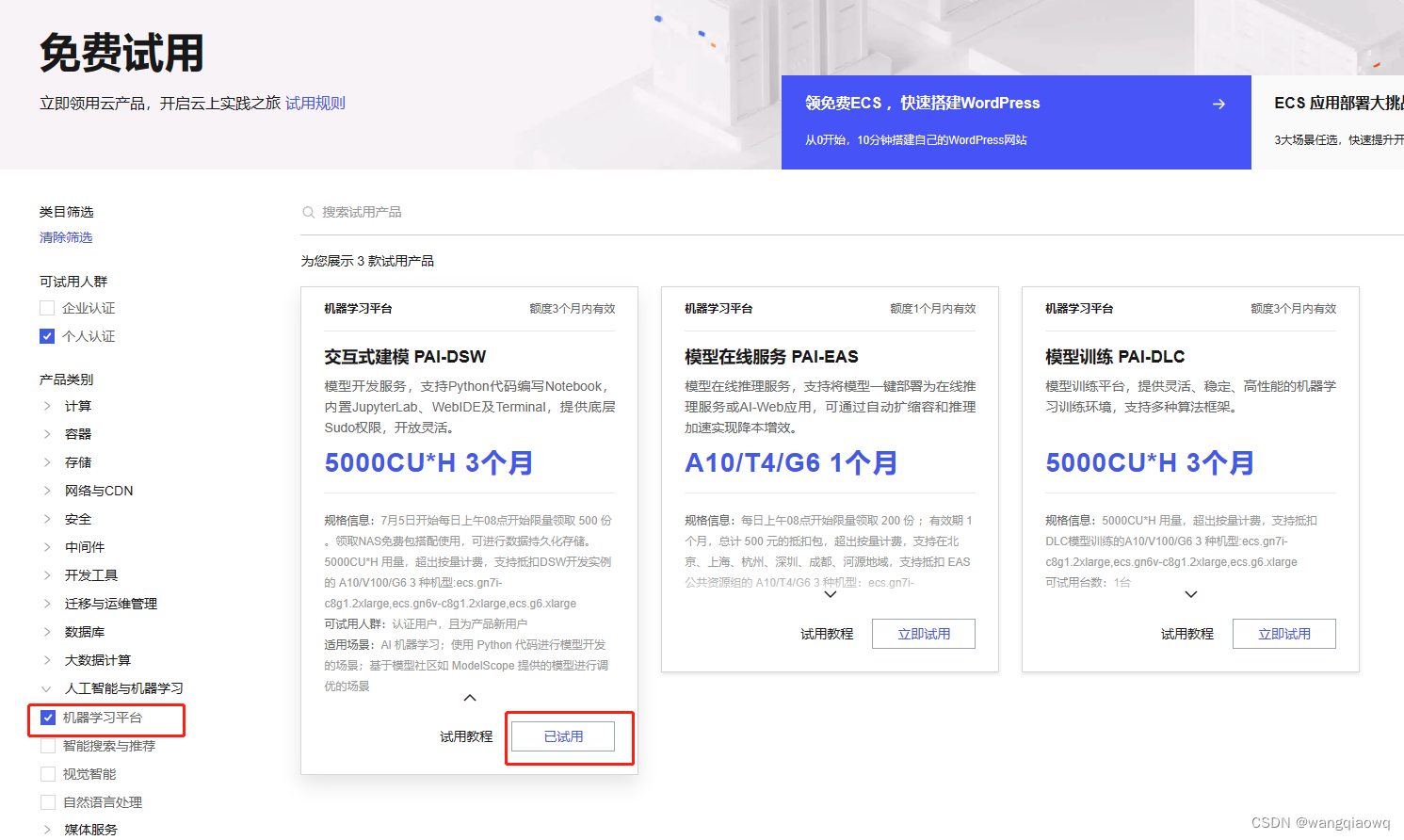
选择 立即试用

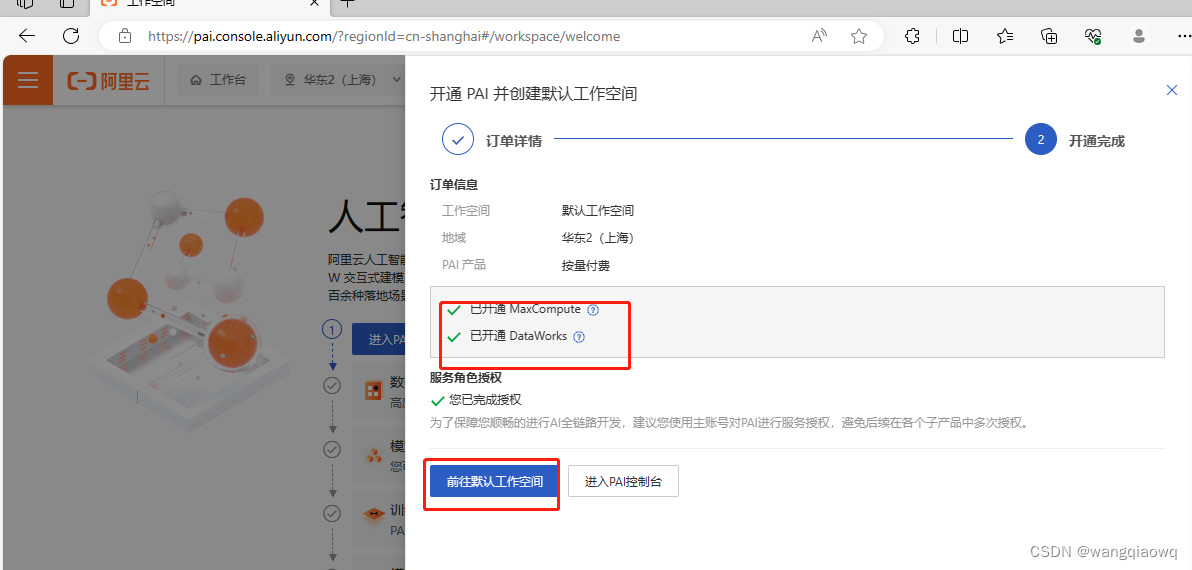
进入工作空间 宣交互式建模(DSW)

输入实例名称,就叫它 550W 吧~,GPU 选择 A10 或者 V100 都行,这俩是支持资源包抵扣的,其他的不支持,这里注意!V100 性能更好,但我们测试使用没必要,就选 A10 就行,A10 显卡每小时消耗6.991计算时,如果不关机持续使用大概可以使用30天。

我打开的时候只有V100 了 支持资源包抵扣
没选数据集 进入选择镜像

选择创建实例 点击下一步 耐心等待实例创建。

二、部署GLM3
部署GLM3,包括其它类似的开源大模型,步骤都是差不多的,毕竟这些高校/大厂都帮大家封装好了,所以并没有特别繁琐的步骤。
在我看来,主要就是三步:1、环境搭建;2、git下载GLM3(如果要本地化部署,还要下载模型);3、修改路径并启用
1、环境搭建
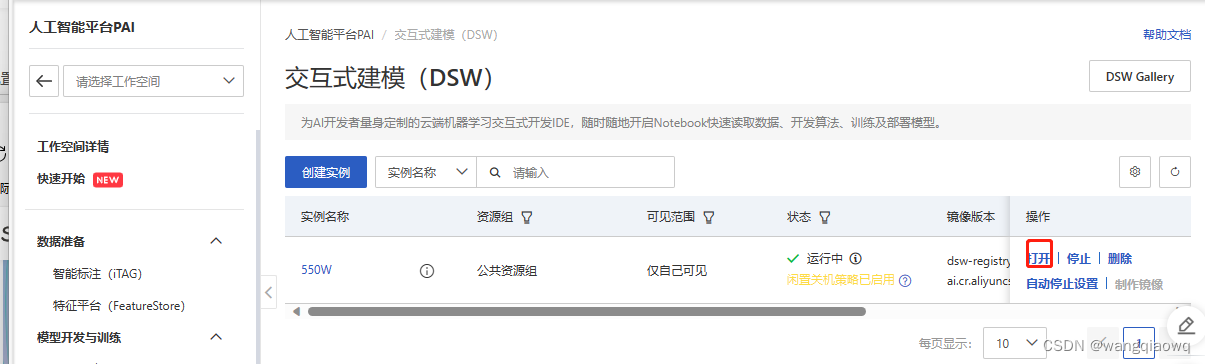
因为使用的是阿里云的PAI,默认已经帮我们配置好了环境变量、网络,装好了python甚至pytorch、tensorflow等等,点击打开后进入
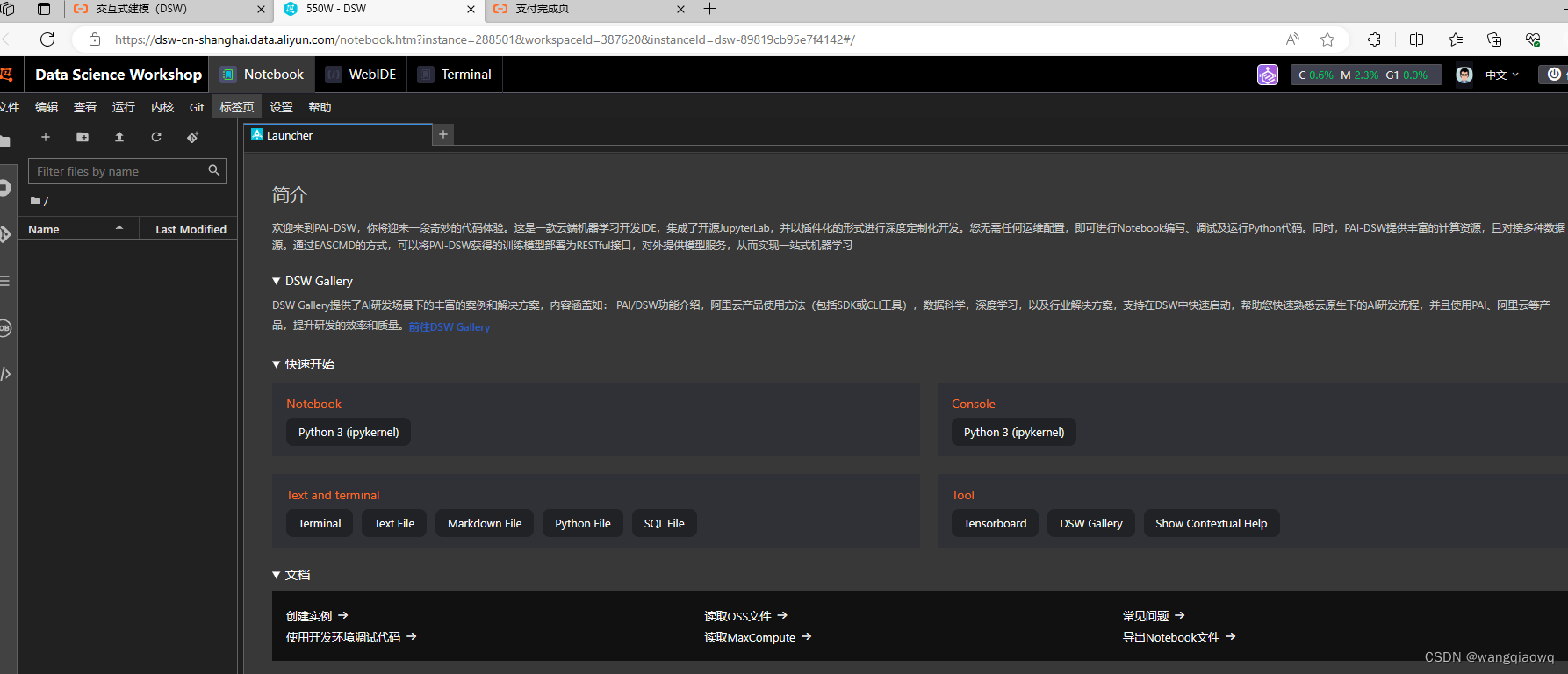
点击 terminal进入:
2、git下载GLM3
2.1 git clone下载GLM3仓库
2.1.1首先git clone下载GLM3仓库,并切换到这个文件夹下
git clone https://github.com/THUDM/ChatGLM3

- Transformers是一个自然语言处理(NLP)模型,由Google提出并广泛应用于各种NLP任务中,如机器翻译、文本分类、问答系统等。Transformers模型采用了一种称为“自注意力机制”(self-attention mechanism)的技术,可以有效地处理长序列的输入数据,并且并行计算能力强,因此在大规模数据集上训练效果优异。
- TransFlow则是一种基于流(flow)的编程模型和执行引擎,旨在简化分布式数据流应用程序的开发和部署。TransFlow通过将数据流编程模型和流处理引擎相结合,提供了一种高效、灵活和易用的方式来处理大规模数据流。
2.1.2 然后使用 pip 安装依赖:


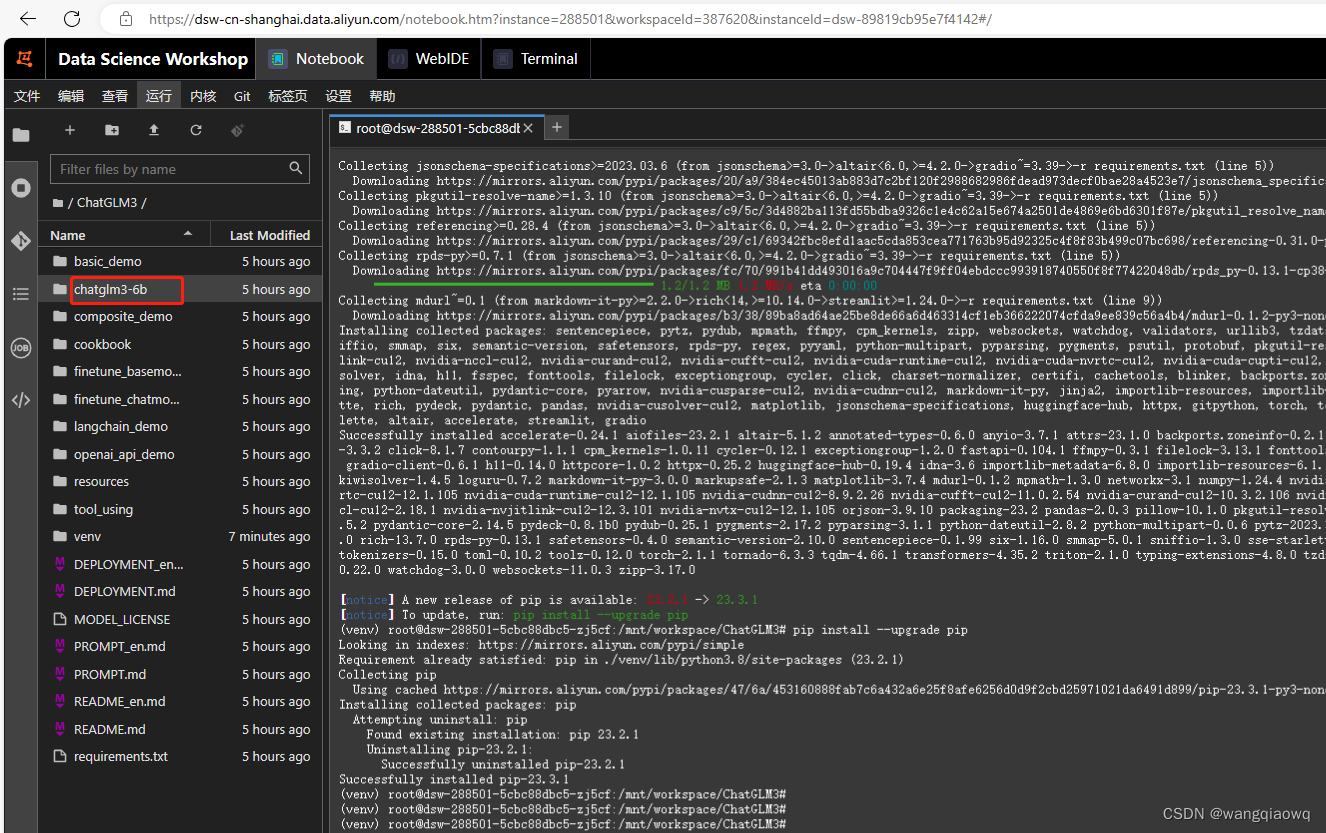
cd ChatGLM3
pip install --upgrade pytorch-lightning
pip install -r requirements.txt
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
pip install virtualenv

virtualenv venv
进入:source venv/bin/activate
停止:deactivate (参考)


pip install -r requirements.txt


安装完成:
pip install --upgrade pip

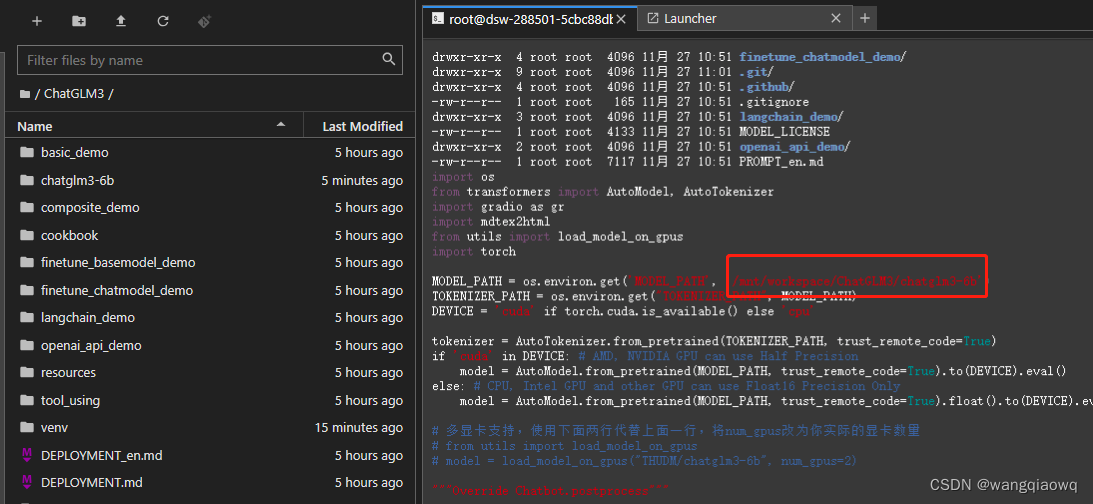
3、修改变量路径并启用
有2个文件需要修改变量路径,一个是/mnt/workspace/ChatGLM3/basic_demo下的“web_demo.py”,另一个是chatgm3-6b下的“config.json”,都是把默认的“THUDM/”修改为“/mnt/workspace/”
这里的修改,可以使用vim,也可以直接左边栏双击打开文件修改

pip install mdtex2html

启动后 问了一下 貌似卡住了。。。
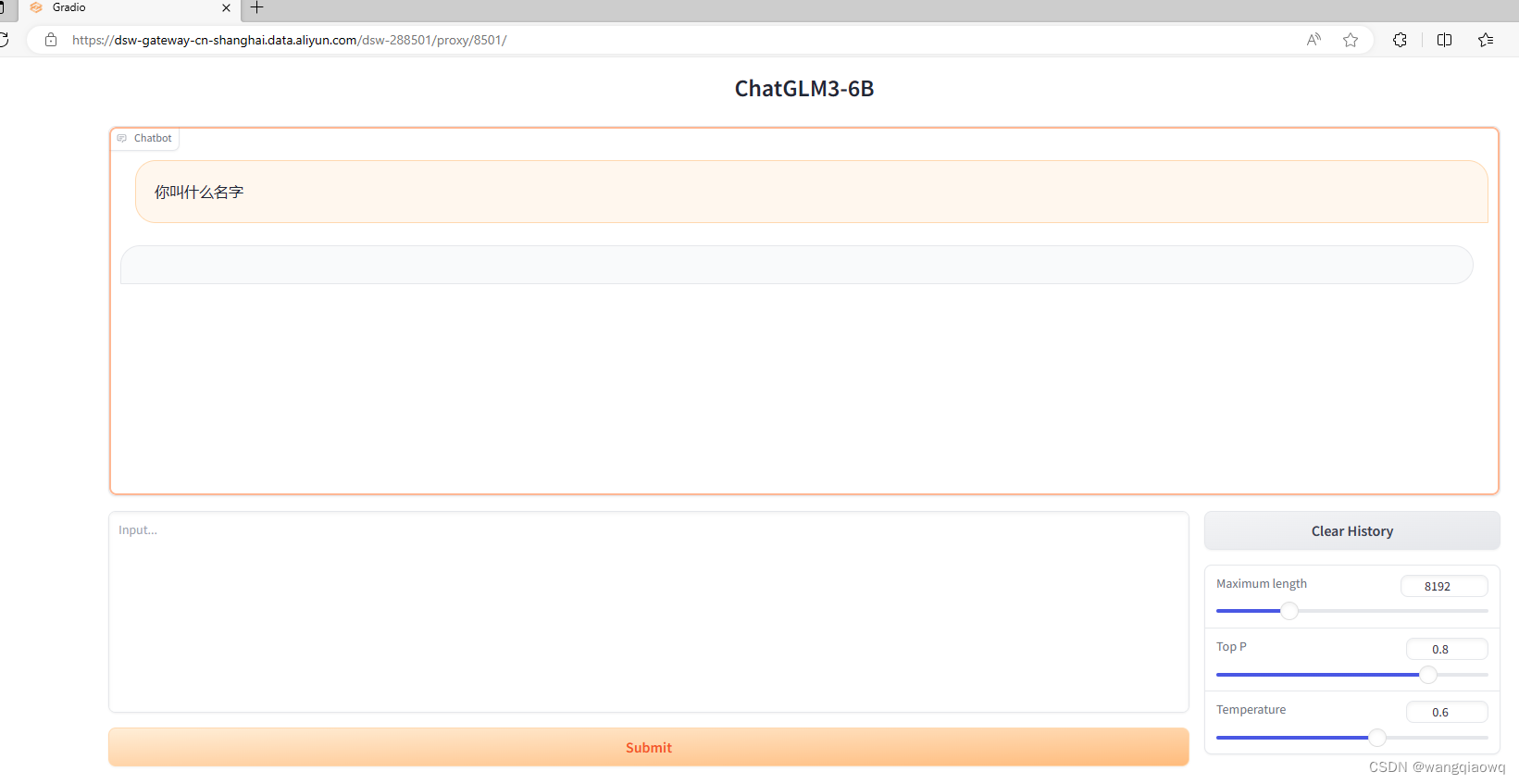
待研究。。。
修改 cli_demo.py

python cli_demo.py
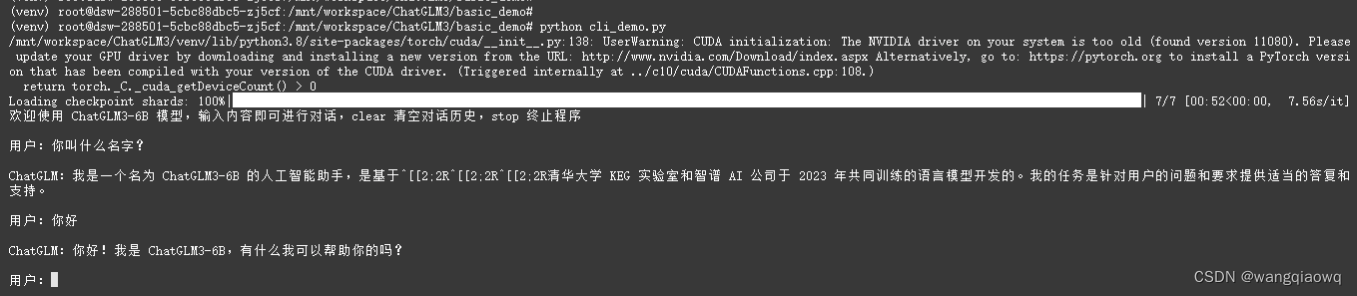
当前 GPU 没有被使用 还是使用的CPU







第十四章 软件维护与软件工程管理课后习题与解析)

机器学习类型和机器学习的主要概念)
)


或者Docker容器监控之 CAdvisor+InfluxDB+Granfana(重量))




)
