
一、本文介绍
本文给大家带来的是我利用我自研的结构进行Attention-LSTM进行时间序列预测,该结构是我专门为新手和刚入门的读者设计,包括结果可视化、支持单元预测、多元预测、模型拟合效果检测、预测未知数据、以及滚动长期预测,大家不仅可以用来学习,用该结构可以发表论文我也觉得是可以并且不需要引用本篇博客。下面我们来介绍一下Attention-LSTM模型,这里提到的Attention是我自研的注意力机制(不是很复杂是一种比较简单的注意力机制但是我觉得效果还比较好),LSTM模型大家都很收悉了,其通过门控单元机制,能够有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一。
专栏目录:时间序列预测目录:深度学习、机器学习、融合模型、创新模型实战案例
专栏: 时间序列预测专栏:基础知识+数据分析+机器学习+深度学习+Transformer+创新模型
Attention-LSTM的预测效果图(这里我只预测了未来24个时间段的值因为LSTM本身存在能力限制一般超过20个时间段就会变得不准了)->

测试集上的表现(这个模型的测试集我还没有画图功能,如有需要请催更)->

目录
一、本文介绍
二、网络结构讲解
2.1 Attention
2.2 LSTM
2.2.1 忘记门
2.2.2 输入门
2.2.3 输出门
三、数据集介绍
四、模型参数讲解
五、模型训练
六、预测结果
七、检验模型拟合情况
八、完整代码
八、全文总结
二、网络结构讲解
2.1 Attention
我研究的这个注意力机制就是为了这篇博客内容不是很复杂,是一种自注意力机制,它允许模型在处理一系列数据点时,不仅仅关注这些点的顺序,而是更加深入地了解这些点之间的关联性。这一点对于理解可能不直观或隐藏在复杂数据结构中的模式至关重要。
它由以下几个部分组成:
1. 查询(Queries)、键(Keys)、值(Values):这三个组件是自注意力机制的核心。对于每个输入元素,模型生成对应的查询、键和值。这些是通过将输入数据通过线性变换(我通过nn.Linear层)获得的。
2. 打分函数:模型通过计算查询和键之间的相似度来生成注意力分数。这是通过`einsum`函数实现的,它执行批量矩阵乘法来计算这些分数。
3. 标准化:得到的注意力分数通过Softmax函数进行标准化,使得每个元素的注意力分数加起来等于1。这意味着模型可以决定将多少注意力分配给序列中的每个元素(可以理解为权重分配)。
4. 加权求和:最后,标准化后的注意力分数用于加权求和对应的值(Values),这样每个元素都得到一个加权的表示,这个表示是所有元素的信息的集合。
5. 结果输出:最后我通过一个全连接层将结果输出,保持输入和输出的一致性。
本来想画图来着但是想想算了,也没打算用其干什么,所以大家有兴趣可以进行研究和改进进行二次创作。
2.2 LSTM
LSTM(长短期记忆,Long Short-Term Memory)是一种用于处理序列数据的深度学习模型,属于循环神经网络(RNN)的一种变体,其使用一种类似于搭桥术结构的RNN单元。相对于普通的RNN,LSTM引入了门控机制,能够更有效地处理长期依赖和短期记忆问题,是RNN网络中最常使用的Cell之一。
LSTM通过刻意的设计来实现学习序列关系的同时,又能够避免长期依赖的问题。它的结构示意图如下所示。

在LSTM的结构示意图中,每一条黑线传输着一整个向量,从一个节点的输出到其他节点的输入。其中“+”号代表着运算操作(如矢量的和),而矩形代表着学习到的神经网络层。汇合在一起的线表示向量的连接,分叉的线表示内容被复制,然后分发到不同的位置。
如果上面的LSTM结构图你看着很难理解,但是其实LSTM的本质就是一个带有tanh激活函数的简单RNN,如下图所示。

LSTM这种结构的原理是引入一个称为细胞状态的连接。这个状态细胞用来存放想要的记忆的东西(对应简单LSTM结构中的h,只不过这里面不再只保存上一次状态了,而是通过网络学习存放那些有用的状态),同时在加入三个门,分别是。
忘记门:决定什么时候将以前的状态忘记。
输入门:决定什么时候将新的状态加进来。
输出门:决定什么时候需要把状态和输入放在一起输出。
从字面上可以看出,由于三个门的操作,LSTM在状态的更新和状态是否要作为输入,全部交给了神经网络的训练机制来选择。
下面分别来介绍一下三个门的结构和作用。
2.2.1 忘记门
下图所示为忘记门的操作,忘记门决定模型会从细胞状态中丢弃什么信息。
忘记门会读取前一序列模型的输出和当前模型的输入
来控制细胞状态中的每个数是否保留。
例如:在一个语言模型的例子中,假设细胞状态会包含当前主语的性别,于是根据这个状态便可以选择正确的代词。当我们看到新的主语时,应该把新的主语在记忆中更新。忘记们的功能就是先去记忆中找到一千那个旧的主语(并没有真正执行忘记的操作,只是找到而已。

在上图的LSTM的忘记门中,代表忘记门的输出, α代表激活函数,
代表忘记门的权重,
代表当前模型的输入,
代表前一个序列模型的输出,
代表忘记门的偏置。
2.2.2 输入门
输入门可以分为两部分功能,一部分是找到那些需要更新的细胞状态。另一部分是把需要更新的信息更新到细胞状态里
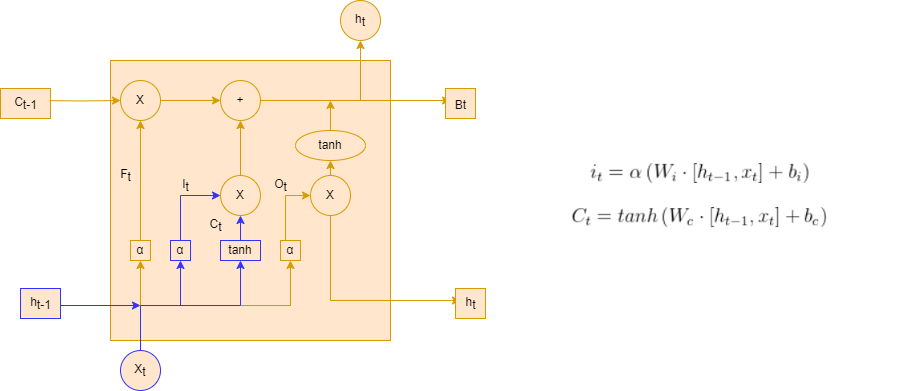
在上面输入门的结构中,代表要更新的细胞状态,α代表激活函数,
代表当前模型的输入,
代表前一个序列模型的输出,
代表计算
的权重,
代表计算
的偏置,
代表使用tanh所创建的新细胞状态,
代表计算
的权重,
代表计算
的偏置。
忘记门找到了需要忘掉的信息后,在将它与旧状态相乘,丢弃确定需要丢弃的信息。(如果需要丢弃对应位置权重设置为0),然后,将结果加上
*
使细胞状态获得新的信息。这样就完成了细胞状态的更新,如下图输入门的更新图所示。
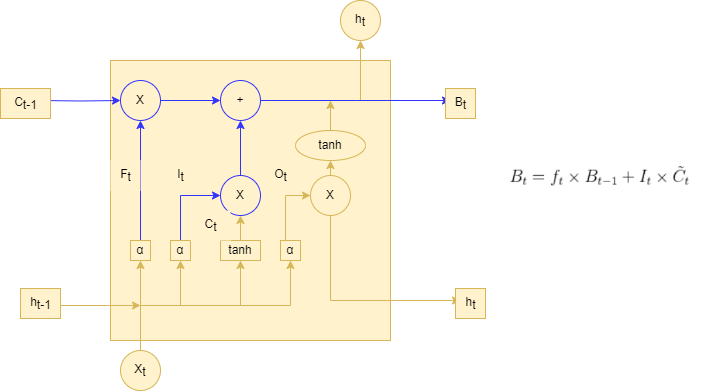
再上图LSTM输入门的更新图中,代表忘记门的输出结果,
代表忘记门的输出结果,
代表前一个序列模型的细胞状态,
代表要更新的细胞状态,
代表使用tanh所创建的新细胞状态。
2.2.3 输出门
如下图LSTM的输出门结构图所示,在输出门中,通过一个激活函数层(实际使用的是Sigmoid激活函数)来确定哪个部分的信息将输出,接着把细胞状态通过tanh进行处理(得到一个在-1~1的值),并将它和Sigmoid门的输出相乘,得出最终想要输出的那个部分,例如,在语言模型中,假设已经输入了一个代词,便会计算出需要输出一个与该代词相关的信息(词向量)

在LSTM的输出门结构图中,代表要输出的信息,α代表激活函数,
代表计算
的权重,
代表计算
的偏置,
代表更新后的细胞状态,
代表当前序列模型的输出结果。
三、数据集介绍
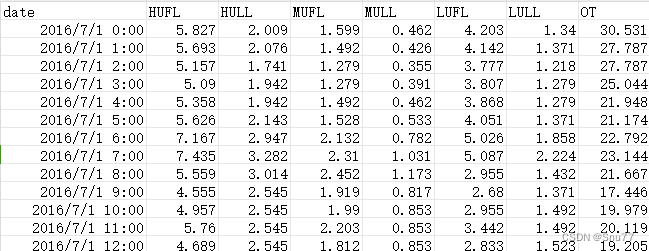
我们本文用到的数据集是官方的ETTh1.csv ,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、模型参数讲解
if __name__ == '__main__':parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='LSTM-GRU', help="模型持续更新")parser.add_argument('-window_size', type=int, default=128, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-output_size', type=int, default=1, help='输出特征个数只有两种选择和你的输入特征一样即输入多少输出多少,另一种就是多元预测单元')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=32, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden-size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel-sizes', type=str, default='3')parser.add_argument('-laryer_num', type=int, default=1)# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()为了大家方便理解,文章中的参数设置我都用的中文,所以大家应该能够更好的理解。下面我在进行一遍讲解。
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 1 | model | str | 模型名称 |
| 2 | window_size | int | 时间窗口大小,用多少条数据去预测未来的数据 |
| 3 | pre_len | int | 预测多少条未来的数据 |
| 4 | shuffle | store_true | 是否打乱输入dataloader中的数据,不是数据的顺序 |
| 5 | data_path | str | 你输入数据的地址 |
| 6 | target | str | 你想要预测的特征列 |
| 7 | input_size | int | 输入的特征数不包含时间那一列!!! |
| 8 | output_size | int | 输出的特征数只可以是1或者是等于你输入的特征数 |
| 9 | feature | str | [M, S, MS],多元预测多元,单元预测单元,多元预测单元 |
| 10 | lr | float | 学习率大小 |
| 11 | drop_out | float | 丢弃概率 |
| 12 | epochs | int | 训练轮次 |
| 13 | batch_size | int | 批次大小 |
| 14 | svae_path | str | 模型的保存路径 |
| 15 | hidden_size | int | 隐藏层大小 |
| 16 | kernel_size | int | 卷积核大小 |
| 17 | layer_num | int | lstm层数 |
| 18 | use_gpu | bool | 是否使用GPU |
| 19 | device | int | GPU编号 |
| 20 | train | bool | 是否进行训练 |
| 21 | predict | bool | 是否进行预测 |
| 22 | inspect_fit | bool | 是否进行检验模型 |
| 23 | lr_schduler | bool | 是否使用学习率计划 |
五、模型训练

六、预测结果
Attention-LSTM的预测效果图(这里我只预测了未来24个时间段的值因为LSTM本身存在能力限制一般超过20个时间段就会变得不准了)->

测试集上的表现(这个模型的测试集我还没有画图功能,如有需要请催更)->
同时我也可以将输出结果用csv文件保存,但是功能还没有做,我在另一篇informer的文章里实习了这个功能大家如果有需要可以评论区留言,有时间我会移植过来。
另一篇文章链接->时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本,结果可视化)
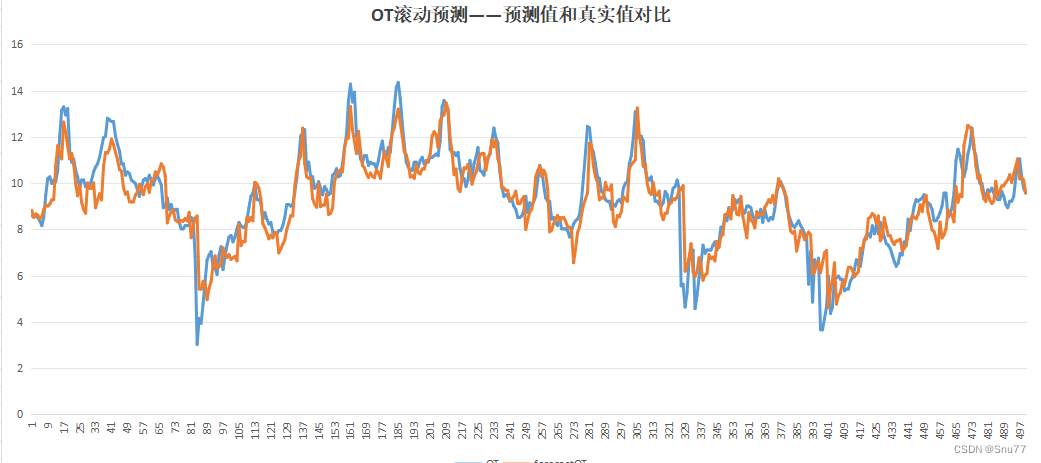
将滚动预测结果生成了csv文件方便大家对比和评估,以下是我生成的csv文件可以说是非常的直观。

我们可以利用其进行画图从而评估结果->
七、检验模型拟合情况
功能暂未推出,持续更新~
八、完整代码
import argparse
import numpy as np
import pandas as pd
import torch.nn as nn
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from torch.utils.data import DataLoader
import torch
from torch.utils.data import Dataset
from tqdm import tqdm
import time
# 随机数种子
np.random.seed(1)def plot_loss_data(data):# 使用Matplotlib绘制线图plt.figure()plt.plot(data)# 添加标题plt.title("loss results Plot")# 显示图例plt.legend(["Loss"])class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def create_inout_sequences(input_data, tw, pre_len, config):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + pre_len) > len(input_data):breakif config.feature == 'MS' or config.feature == 'S':train_label = input_data[:,-1:][i + tw:i + tw + pre_len]else:train_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seqdef calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return maedef create_dataloader(config, device):print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列pre_len = config.pre_len # 预测未来数据的长度train_window = config.window_size # 观测窗口# 将特征列移到末尾target_data = df[[config.target]]df = df.drop(config.target, axis=1)df = pd.concat((df, target_data), axis=1)cols_data = df.columns[1:]df_data = df[cols_data]# 这里加一些数据的预处理, 最后需要的格式是pd.seriestrue_data = df_data.values# 定义标准化优化器scaler_train = StandardScaler()scaler_valid = StandardScaler()scaler_test = StandardScaler()train_data = true_data[int(0.3 * len(true_data)):]valid_data = true_data[int(0.15 * len(true_data)):int(0.30 * len(true_data))]test_data = true_data[:int(0.15 * len(true_data))]print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))# 进行标准化处理train_data_normalized = scaler_train.fit_transform(train_data)test_data_normalized = scaler_test.fit_transform(test_data)valid_data_normalized = scaler_valid.fit_transform(valid_data)# 转化为深度学习模型需要的类型Tensortrain_data_normalized = torch.FloatTensor(train_data_normalized).to(device)test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)# 定义训练器的的输入train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len, config)test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len, config)valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len, config)# 创建数据集train_dataset = TimeSeriesDataset(train_inout_seq)test_dataset = TimeSeriesDataset(test_inout_seq)valid_dataset = TimeSeriesDataset(valid_inout_seq)# 创建 DataLoadertrain_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)print("通过滑动窗口共有训练集数据:", len(train_inout_seq), "转化为批次数据:", len(train_loader))print("通过滑动窗口共有测试集数据:", len(test_inout_seq), "转化为批次数据:", len(test_loader))print("通过滑动窗口共有验证集数据:", len(valid_inout_seq), "转化为批次数据:", len(valid_loader))print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")return train_loader, test_loader, valid_loader, scaler_train, scaler_test, scaler_validclass SelfAttention(nn.Module):def __init__(self, feature_size, heads):super(SelfAttention, self).__init__()self.feature_size = feature_sizeself.heads = headsself.head_dim = feature_size // headsassert (self.head_dim * heads == feature_size), "Feature size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, feature_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into self.heads different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# Einsum does matrix multiplication for query*keys for each training example# with every other training example, don't be confused by einsum# it's just a way to do batch matrix multiplicationenergy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.feature_size ** (1 / 2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return outclass TPALSTM(nn.Module):def __init__(self, input_size, output_horizon, hidden_size, obs_len, n_layers):super(TPALSTM, self).__init__()self.hidden = nn.Linear(input_size, hidden_size)self.relu = nn.ReLU()self.lstm = nn.LSTM(hidden_size, hidden_size, n_layers, \bias=True, batch_first=True) # output (batch_size, obs_len, hidden_size)self.hidden_size = hidden_sizeself.obs_len = obs_lenself.output_horizon = output_horizonself.attention = SelfAttention(input_size, output_horizon)self.linear = nn.Linear(hidden_size, output_horizon)self.n_layers = n_layersdef forward(self, x):x = self.attention(x, x, x, None)batch_size, obs_len, features_size = x.shape # (batch_size, obs_len, features_size)xconcat = self.hidden(x) # (batch_size, obs_len, hidden_size)H = torch.zeros(batch_size, obs_len - 1, self.hidden_size).to(device) # (batch_size, obs_len-1, hidden_size)ht = torch.zeros(self.n_layers, batch_size, self.hidden_size).to(device) # (num_layers, batch_size, hidden_size)ct = ht.clone()for t in range(obs_len):xt = xconcat[:, t, :].view(batch_size, 1, -1) # (batch_size, 1, hidden_size)out, (ht, ct) = self.lstm(xt, (ht, ct)) # ht size (num_layers, batch_size, hidden_size)htt = ht[-1, :, :] # (batch_size, hidden_size)if t != obs_len - 1:H[:, t, :] = httH = self.relu(H) # (batch_size, obs_len-1, hidden_size)ypred = self.linear(H) # (batch_size, output_horizon)ypred = ypred[:, -self.obs_len:, :]return ypreddef train(model, args, device):start_time = time.time() # 计算起始时间lstm_model = modelloss_function = nn.MSELoss()optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)epochs = args.epochslstm_model.train() # 训练模式results_loss = []for i in tqdm(range(epochs)):losss = []for seq, labels in train_loader:optimizer.zero_grad()lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()losss.append(single_loss.detach().cpu().numpy())tqdm.write(f"\t Epoch {i + 1} / {epochs}, Loss: {sum(losss) / len(losss)}")results_loss.append(sum(losss) / len(losss))save_loss = []if save_loss:valid_loss = valid(model, args, scaler_valid, valid_loader)# 尚未引入学习率计划后期补上torch.save(lstm_model.state_dict(), 'save_model.pth')time.sleep(0.1)# 保存模型print(f">>>>>>>>>>>>>>>>>>>>>>模型已保存,用时:{(time.time() - start_time) / 60:.4f} min<<<<<<<<<<<<<<<<<<")# plot_loss_data(results_loss)test(model, args, scaler_test, test_loader)return scaler_traindef valid(model, args, scaler, valid_loader):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式losss = []for seq, labels in valid_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().cpu().numpy(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)# print("验证集误差MAE:", losss)return sum(losss)/len(losss)def test(model, args, scaler, test_loader):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().cpu().numpy(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)# 此处缺少一个绘图功能后期补上,检验测试集情况print("测试集误差MAE:", losss)# 检验模型拟合情况
def inspect_model_fit(model, args, train_loader, scaler_train):# 后期完善print("模型拟合检验情况暂未完善,如有需要请催更博主")passdef predict(model, args, device, scaler):# 预测未知数据的功能# 重新读取数据df = pd.read_csv(args.data_path)train_data = df[[args.target]][int(0.3 * len(df)):]df = df.iloc[:, 1:][-args.window_size:].values # 转换为nadarryscaler_tr = StandardScaler()scaler_tr.fit_transform(train_data.values)pre_data = scaler.transform(df)tensor_pred = torch.FloatTensor(pre_data).to(device)tensor_pred = tensor_pred.unsqueeze(0) # 单次预测 , 滚动预测功能暂未开发后期补上model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式pred = model(tensor_pred)[0]if args.feature == 'M' or args.feature == 'S':pred = scaler.inverse_transform(pred.detach().cpu().numpy())else:pred = scaler_tr.inverse_transform(pred.detach().cpu().numpy())# 计算历史数据的长度history_length = len(df[:, -1])# 为历史数据生成x轴坐标history_x = range(history_length)# 为预测数据生成x轴坐标# 开始于历史数据的最后一个点的x坐标prediction_x = range(history_length - 1, history_length + len(pred[:, -1]) - 1)# 绘制历史数据plt.plot(history_x, df[:, -1], label='History')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(prediction_x, pred[:, -1], marker='o', label='Prediction')plt.axvline(history_length - 1, color='red') # 在图像的x位置处画一条红色竖线# 添加标题和图例plt.title("History and Prediction")plt.legend()if __name__ == '__main__':parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='LSTM-Attention', help="模型持续更新")parser.add_argument('-window_size', type=int, default=128, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-output_size', type=int, default=1, help='输出特征个数只有两种选择和你的输入特征一样即输入多少输出多少,另一种就是多元预测单元')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=16, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden-size', type=int, default=128, help="隐藏层单元数")parser.add_argument('-kernel-sizes', type=str, default='3')parser.add_argument('-laryer_num', type=int, default=1)# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()if isinstance(args.device, int) and args.use_gpu:device = torch.device("cuda:" + f'{args.device}')else:device = torch.device("cpu")print(device)train_loader, test_loader, valid_loader, scaler_train, scaler_test, scaler_valid = create_dataloader(args, device)# 实例化模型try:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型<<<<<<<<<<<<<<<<<<<<<<<<<<<")model = TPALSTM(args.input_size,args.output_size,args.hidden_size, args.pre_len, args.laryer_num).to(device)print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型成功<<<<<<<<<<<<<<<<<<<<<<<<<<<")except:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型失败<<<<<<<<<<<<<<<<<<<<<<<<<<<")# 训练模型if args.train:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<")train(model, args, device)if args.inspect_fit:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始检验{args.model}模型拟合情况<<<<<<<<<<<<<<<<<<<<<<<<<<<")inspect_model_fit(model, args, train_loader, scaler_train)if args.predict:print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<")predict(model, args, device, scaler_train)plt.show()八、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的时间序列专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的模型进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾: 时间序列预测专栏——持续复习各种顶会内容——科研必备
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!最后希望大家工作顺利学业有成!





)
:Shell scripts)













