这里写目录标题
- COCO-TEXT 英文
- Total-Text 英文+少量中文
- IIIT5K[50]、IC03[44]、IC13[34]、IC15[33]、CT80[56]
- MJSynth 英文
- SynthText
- 分层文本数据集 (HierText) 英文
- TextOCR和IntelOCR ???
- Multi-language dataset (IC19)
- RCTW17 主要中文
- MSRA-TD500 dataset 中英混合
- SCUT-CTW1500
TextZoom是用于英文超分算法的数据集,没有汉字字符。RealSR是为真实世界的自然图像超分辨率而构建。
此处
COCO-TEXT 英文
英文数据集,包括63686幅图像,173589个文本实例,包括手写版和打印版,清晰版和非清晰版。文件大小12.58GB,训练集:43686张,测试集:10000张,验证集:10000张。
下载地址:https://vision.cornell.edu/se3/coco-text-2/
Total-Text 英文+少量中文
Total-Text 是一个数据集, 其中包含各 种形状的文本, 包括水平的,多取向的和弯曲的. 这 3 个数据集包含了中文和英文的数据集共 6 万张, 用于 文字检测和识别
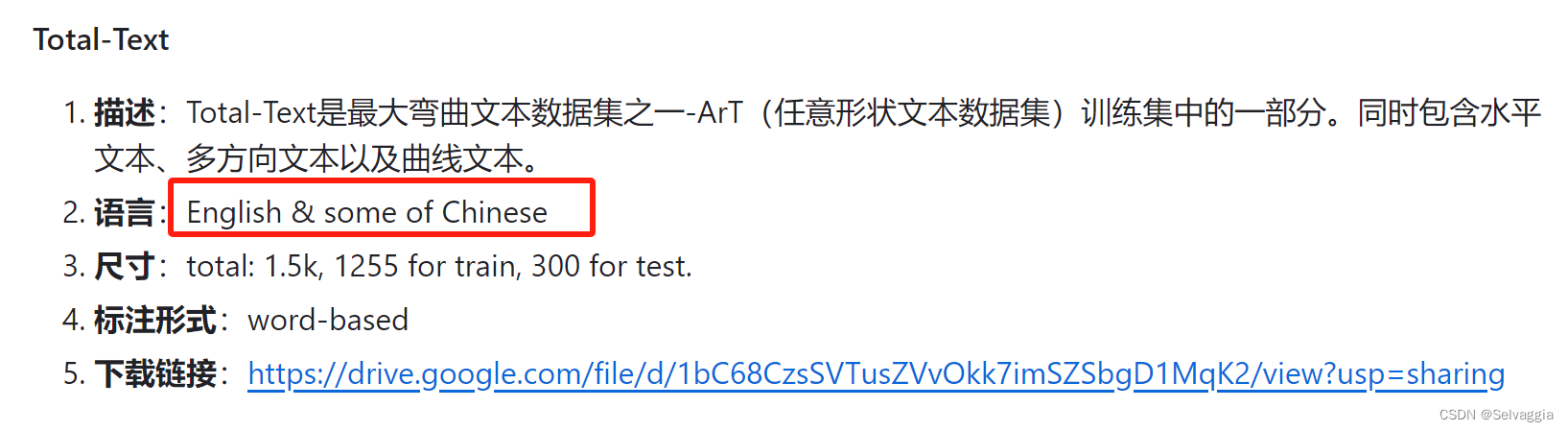
TotalText下载链接:https://opendatalab.com/TotalText Total-Text是最大弯曲文本数据集之一-ArT(任意形状文本数据集)训练集中的一部分。该数据集共1555张图像,11459文本行,包含水平文本,倾斜文本,弯曲文本。文件大小441MB。大部分为英文文本,少量中文文本。其中训练集有1255张图像,测试集有300张图像。
作者:OpenDataLab
链接:https://www.zhihu.com/question/349678421/answer/2620009371
MTWI [11] is a large-scale dataset for Chinese and English web text reading
MSRA-TD500 [47] is a multi-lingual text dataset in Chinese and English.
IIIT5K[50]、IC03[44]、IC13[34]、IC15[33]、CT80[56]
一方面,现有的文本识别方法主要在英文文本上进行评估,如IIIT5K[50]、IC03[44]、IC13[34]、IC15[33]、CT80[56]等。虽然很少有方法尝试在中文文本数据集上进行实验,但相应的论文中关于数据集构建的细节并不明确,这使得其他人很难将其作为CTR基线(见图1©)。另一方面,复制现有文本识别方法构建CTR基线的结果是一项费力的任务。它不仅耗费大量的时间,而且消耗大量的GPU资源,这确实降低了研究人员对中文文本识别的热情
中文文本识别Benchmarking

(a) Year 2011 (SVT) and (b) Year 2013 (IIIT, IC13): Most
of images are horizontal texts in the street.
© Year 2015 (IC15): Images captured by Google Glass
under movement of the wearer, and thus many are perspective texts, blurry, or low-resolution images.
(d) Year 2017 (COCO, RCTW, Uber):
COCO-Text (COCO) [49] is created from the MS
COCO dataset [25]. As the MS COCO dataset is not
intended to capture text, COCO contains many occluded or low-resolution texts.
RCTW [42] is created for Reading Chinese Text in
the Wild competition. Thus many are Chinese text.
Uber-Text (Uber) [62] is collected from Bing Maps
Streetside. Many are house number, and some are text
on signboards.
(e) Year 2019 (ArT, LSVT, MLT19, ReCTS):
ArT [6] is created to recognize Arbitrary-shaped Text.
Many are perspective or curved texts. It also includes
Totaltext [7] and CTW1500 [28], which contain many
rotated or curved texts.
LSVT [47, 46] is a Large-scale Street View Text
dataset, collected from streets in China, and thus many
are Chinese text.
MLT19 [34] is created to recognize Multi-Lingual
Text. It consists of seven languages: Arabic, Latin,
Chinese, Japanese, Korean, Bangla, and Hindi.
ReCTS [61] is created for the Reading Chinese Text
on Signboard competition. It contains many irregular
texts arranged in various layouts or written with unique
fonts.

We use a collection of Chinese text recognition
datasets [10, 28, 36, 38, 50] as the training set and the Japanese subset of MLT [28] as the testing set following
OSOCR [23], and all models are trained for 200k iterations.
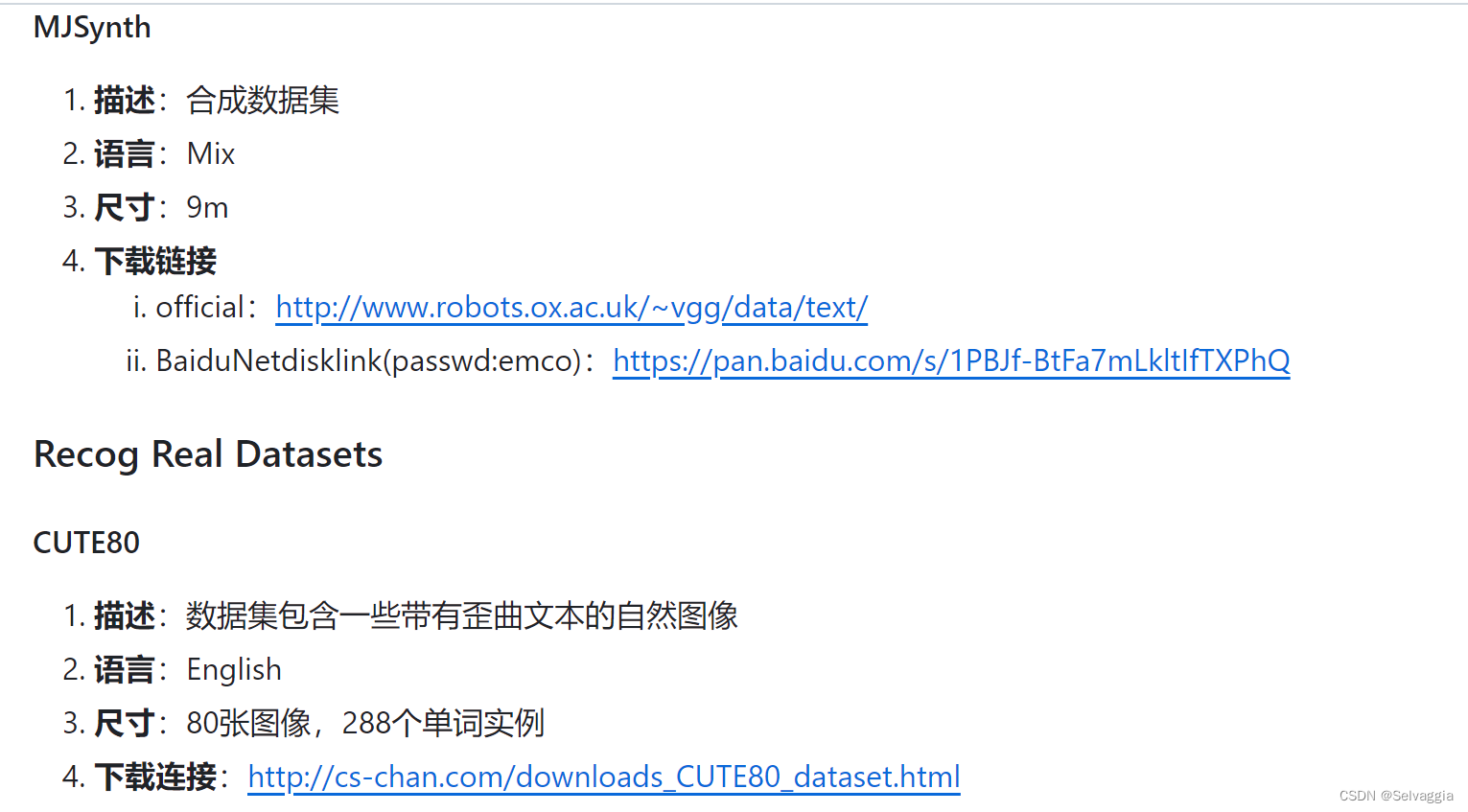
MJSynth 英文

SynthText

分层文本数据集 (HierText) 英文
数据采集
HierText 中的图像是从 Open Images v6 数据集 [24] 中收集的。 我们使用公共商业 OCR 引擎 Google Cloud Platform Text Detection API (GCP)1 扫描 Open Images,以搜索带有文本的图像。 我们过滤掉图像:a) 检测到的单词很少,b) 识别置信度低,c) 带有非英语主导文本。 最后,我们从剩余图像中随机抽取一个子集来构建我们的数据集。 获得了 11639 张图像,并进一步分为训练集、验证集和测试集。 HierText 图像具有更高的分辨率,其长边限制为 1600 像素,而之前基于 Open Images [22,48] 的数据集限制为 1024 像素,从而产生更清晰的文本。
————————————————
版权声明:本文为CSDN博主「studyeboy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/studyeboy/article/details/127652354
TextOCR和IntelOCR ???
姑且算作英文
Revisiting Scene Text Recognition: A Data Perspective,ICCV,2023
这篇
Multi-language dataset (IC19)
Evaluation on multiple languages is performed using IC19-MLT dataset. The output channel in the prediction layer
of the recognizer was expanded to 4267 to handle the characters in Arabic,
Latin, Chinese, Japanese, Korean, Bangladesh, and Hindi. However, occurrence
of characters in the dataset is not evenly distributed.
RCTW17 主要中文
《ICDAR2017 Competition on Reading Chinese Text in the Wild(RCTW-17)》
ICDAR2017RCTW-OCR
MSRA-TD500 dataset 中英混合
MSRA-TD500 dataset [45] is a multi-language scene text detection benchmark that contains English and Chinese text, including 300 training images and
200 testing images. Text instances are annotated in the text-line level, thus there
are many text instances of extreme aspect ratios. This dataset does not contain
recognition annotations.
SCUT-CTW1500
描述:针对弯曲文本检测的数据集
语言:mainly Chinese & English


)



)

)









