实战实例
通常我们在服务还没正式起来时,会用brpc流式log打印,支持对日志输出到ostream对象中(默认std)。同时会在服务初始化时配置LogSink,实现自己的log,这样后续都可以将输出重定向至自己的log.
int init(int argc, char** argv, const char* product_name, const char* mod_name) {// 读日志文件配置(设置baidu-rpc底层使用com_log)logging::SetLogSink(logging::ComlogSink::GetInstance());google::SetCommandLineOption("flagfile", "conf/gflags.conf");// configstd::string conf_dir = "./conf";std::string conf_comlog = "log.conf";int ret = E_ERROR;do {// comlog加载std::string comlog_conf_file = conf_dir + "/" + conf_comlog;ret = logging::ComlogSink::GetInstance()->SetupFromConfig(comlog_conf_file.c_str());if (0 != ret) {LOG(FATAL) << "init log by conf:./conf/log.conf failed"; break;}//LogRecordFactory confcomcfg::Configure log_conf;int ret = log_conf.load(conf_dir.c_str(), conf_comlog.c_str());if (0 != ret) {LOG(FATAL) << "Fail to load log conf file:" << conf_dir << "/" << conf_comlog;break;}bus::log::LogRecordFactory local_data_factory;ret = local_data_factory.init(log_conf);if (0 != ret) {LOG(FATAL) << "Init LogRecordFactory failed";break;}LOG(NOTICE) << "Init LogRecordFactory Succeed";} while(false);Name
streaming_log - Print log to std::ostreams
SYNOPSIS
#include <butil/logging.h>LOG(FATAL) << "Fatal error occurred! contexts=" << ...;
LOG(WARNING) << "Unusual thing happened ..." << ...;
LOG(TRACE) << "Something just took place..." << ...;
LOG(TRACE) << "Items:" << noflush;
LOG_IF(NOTICE, n > 10) << "This log will only be printed when n > 10";
PLOG(FATAL) << "Fail to call function setting errno";
VLOG(1) << "verbose log tier 1";
CHECK_GT(1, 2) << "1 can't be greater than 2";LOG_EVERY_SECOND(INFO) << "High-frequent logs";
LOG_EVERY_N(ERROR, 10) << "High-frequent logs";
LOG_FIRST_N(INFO, 20) << "Logs that prints for at most 20 times";
LOG_ONCE(WARNING) << "Logs that only prints once";
DESCRIPTION
流式日志是打印复杂对象或模板对象的不二之选。大部分业务对象都很复杂,如果用printf形式的函数打印,你需要先把对象转成string,才能以%s输出。但string组合起来既不方便(比如没法append数字),还得分配大量的临时内存(string导致的)。C++中解决这个问题的方法便是“把日志流式地送入std::ostream对象”。比如为了打印对象A,那么我们得实现如下的函数:
std::ostream& operator<<(std::ostream& os, const A& a);
这个函数的意思是把对象a打印入os,并返回os。之所以返回os,是因为operator<<对应了二元操作 << (左结合),当我们写下os << a << b << c;时,它相当于operator<<(operator<<(operator<<(os, a), b), c); 很明显,operator<<需要不断地返回os(的引用),才能完成这个过程。这个过程一般称为chaining。在不支持重载二元运算符的语言中,你可能会看到一些更繁琐的形式,比如os.print(a).print(b).print©。
我们在operator<<的实现中也使用chaining。事实上,流式打印一个复杂对象就像DFS一棵树一样:逐个调用儿子节点的operator<<,儿子又逐个调用孙子节点的operator<<,以此类推。比如对象A有两个成员变量B和C,打印A的过程就是把其中的B和C对象送入ostream中:
struct A {B b;C c;
};
std::ostream& operator<<(std::ostream& os, const A& a) {return os << "A{b=" << a.b << ", c=" << a.c << "}";
}
B和C的结构及打印函数分别如下:
struct B {int value;
};
std::ostream& operator<<(std::ostream& os, const B& b) {return os << "B{value=" << b.value << "}";
}struct C {string name;
};
std::ostream& operator<<(std::ostream& os, const C& c) {return os << "C{name=" << c.name << "}";
}
那么打印某个A对象的结果可能是
A{b=B{value=10}, c=C{name=tom}}
在打印过程中,我们不需要分配临时内存,因为对象都被直接送入了最终要送入的那个ostream对象。当然ostream对象自身的内存管理是另一会儿事了。
OK,我们通过ostream把对象的打印过程串联起来了,最常见的std::cout和std::cerr都继承了ostream,所以实现了上面函数的对象就可以输出到std::cout和std::cerr了。换句话说如果日志流也继承了ostream,那么那些对象也可以打入日志了。流式日志正是通过继承std::ostream,把对象打入日志的,在目前的实现中,送入日志流的日志被记录在thread-local的缓冲中,在完成一条日志后会被刷入屏幕或logging::LogSink,这个实现是线程安全的。
LOG
如果你用过glog,应该是不用学习的,因为宏名称和glog是一致的,如下打印一条FATAL。注意不需要加上std::endl。
LOG(FATAL) << "Fatal error occurred! contexts=" << ...;
LOG(WARNING) << "Unusual thing happened ..." << ...;
LOG(TRACE) << "Something just took place..." << ...;
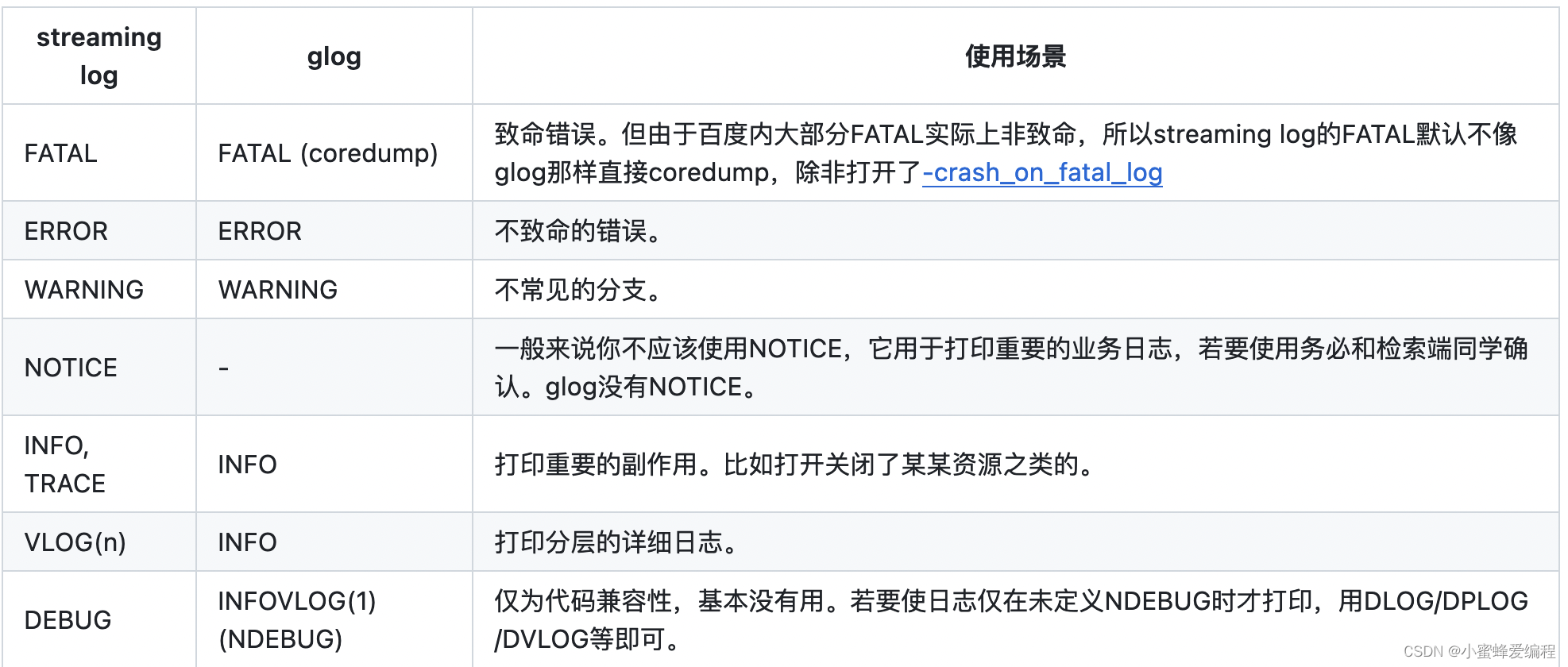
streaming log的日志等级与glog映射关系如下:
PLOG
PLOG和LOG的不同之处在于,它会在日志后加上错误码的信息,类似于printf中的%m。在posix系统中,错误码就是errno。
int fd = open("foo.conf", O_RDONLY); // foo.conf does not exist, errno was set to ENOENT
if (fd < 0) { PLOG(FATAL) << "Fail to open foo.conf"; // "Fail to open foo.conf: No such file or directory"return -1;
}
noflush
如果你暂时不希望刷到屏幕,加上noflush。这一般会用在打印循环中:
LOG(TRACE) << "Items:" << noflush;
for (iterator it = items.begin(); it != items.end(); ++it) {LOG(TRACE) << ' ' << *it << noflush;
}
LOG(TRACE);
前两次TRACE日志都没有刷到屏幕,而是还记录在thread-local缓冲中,第三次TRACE日志则把缓冲都刷入了屏幕。如果items里面有三个元素,不加noflush的打印结果可能是这样的:
TRACE: ... Items:
TRACE: ... item1
TRACE: ... item2
TRACE: ... item3
加了是这样的:
TRACE: ... Items: item1 item2 item3
noflush支持bthread,可以实现类似于UB的pushnotice的效果,即检索线程一路打印都暂不刷出(加上noflush),直到最后检索结束时再一次性刷出。注意,如果检索过程是异步的,就不应该使用noflush,因为异步显然会跨越bthread,使noflush仍然失效。
注意:如果编译时开启了glog选项,则不支持noflush。
LOG_IF
LOG_IF(log_level, condition)只有当condition成立时才会打印,相当于if (condition) { LOG() << …; },但更加简短。比如:
LOG_IF(NOTICE, n > 10) << "This log will only be printed when n > 10";
XXX_EVERY_SECOND
XXX可以是LOG,LOG_IF,PLOG,SYSLOG,VLOG,DLOG等。这类日志每秒最多打印一次,可放在频繁运行热点处探查运行状态。第一次必打印,比普通LOG增加调用一次gettimeofday(30ns左右)的开销。
LOG_EVERY_SECOND(INFO) << "High-frequent logs";
XXX_EVERY_N
XXX可以是LOG,LOG_IF,PLOG,SYSLOG,VLOG,DLOG等。这类日志每触发N次才打印一次,可放在频繁运行热点处探查运行状态。第一次必打印,比普通LOG增加一次relaxed原子加的开销。这个宏是线程安全的,即不同线程同时运行这段代码时对N的限制也是准确的,glog中的不是。
LOG_EVERY_N(ERROR, 10) << "High-frequent logs";
XXX_FIRST_N
XXX可以是LOG,LOG_IF,PLOG,SYSLOG,VLOG,DLOG等。这类日志最多打印N次。在N次前比普通LOG增加一次relaxed原子加的开销,N次后基本无开销。
LOG_FIRST_N(ERROR, 20) << "Logs that prints for at most 20 times";
XXX_ONCE
XXX可以是LOG,LOG_IF,PLOG,SYSLOG,VLOG,DLOG等。这类日志最多打印1次。等价于XXX_FIRST_N(…, 1)
LOG_ONCE(ERROR) << "Logs that only prints once";
VLOG
VLOG(verbose_level)是分层的详细日志,通过两个gflags:–verbose和*–verbose_module*控制需要打印的层(注意glog是–v和–vmodule)。只有当–verbose指定的值大于等于verbose_level时,对应的VLOG才会打印。比如
VLOG(0) << "verbose log tier 0";
VLOG(1) << "verbose log tier 1";
VLOG(2) << "verbose log tier 2";
当–verbose=1时,前两条会打印,最后一条不会。–verbose_module可以覆盖某个模块的级别,模块指去掉扩展名的文件名或文件路径。比如:
--verbose=1 --verbose_module="channel=2,server=3" # 打印channel.cpp中<=2,server.cpp中<=3,其他文件<=1的VLOG
–verbose=1 --verbose_module=“src/brpc/channel=2,server=3” # 当不同目录下有同名文件时,可以加上路径
–verbose和–verbose_module可以通过google::SetCommandLineOption动态设置。
VLOG有一个变种VLOG2让用户指定虚拟文件路径,比如:
// public/foo/bar.cpp
VLOG2("a/b/c", 2) << "being filtered by a/b/c rather than public/foo/bar";
VLOG和VLOG2也有相应的VLOG_IF和VLOG2_IF。
DLOG
所有的日志宏都有debug版本,以D开头,比如DLOG,DVLOG,当定义了NDEBUG后,这些日志不会打印。
千万别在D开头的日志流上有重要的副作用。
“不会打印”指的是连参数都不会评估。如果你的参数是有副作用的,那么当定义了NDEBUG后,这些副作用都不会发生。比如DLOG(FATAL) << foo(); 其中foo是一个函数,它修改一个字典,反正必不可少,但当定义了NDEBUG后,foo就运行不到了。
CHECK
日志另一个重要变种是CHECK(expression),当expression为false时,会打印一条FATAL日志。类似gtest中的ASSERT,也有CHECK_EQ, CHECK_GT等变种。当CHECK失败后,其后的日志流会被打印。
CHECK_LT(1, 2) << "This is definitely true, this log will never be seen";
CHECK_GT(1, 2) << "1 can't be greater than 2";
运行后你应该看到一条FATAL日志和调用处的call stack:
FATAL: ... Check failed: 1 > 2 (1 vs 2). 1 can't be greater than 2
#0 0x000000afaa23 butil::debug::StackTrace::StackTrace()
#1 0x000000c29fec logging::LogStream::FlushWithoutReset()
#2 0x000000c2b8e6 logging::LogStream::Flush()
#3 0x000000c2bd63 logging::DestroyLogStream()
#4 0x000000c2a52d logging::LogMessage::~LogMessage()
#5 0x000000a716b2 (anonymous namespace)::StreamingLogTest_check_Test::TestBody()
#6 0x000000d16d04 testing::internal::HandleSehExceptionsInMethodIfSupported<>()
#7 0x000000d19e96 testing::internal::HandleExceptionsInMethodIfSupported<>()
#8 0x000000d08cd4 testing::Test::Run()
#9 0x000000d08dfe testing::TestInfo::Run()
#10 0x000000d08ec4 testing::TestCase::Run()
#11 0x000000d123c7 testing::internal::UnitTestImpl::RunAllTests()
#12 0x000000d16d94 testing::internal::HandleSehExceptionsInMethodIfSupported<>()
callstack中的第二列是代码地址,你可以使用addr2line查看对应的文件行数:
$ addr2line -e ./test_base 0x000000a716b2
/home/gejun/latest_baidu_rpc/public/common/test/test_streaming_log.cpp:223
你应该根据比较关系使用具体的CHECK_XX,这样当出现错误时,你可以看到更详细的信息,比如:
int x = 1;
int y = 2;
CHECK_GT(x, y); // Check failed: x > y (1 vs 2).
CHECK(x > y); // Check failed: x > y.
和DLOG类似,你不应该在DCHECK的日志流中包含重要的副作用。
LogSink
streaming log通过logging::SetLogSink修改日志刷入的目标,默认是屏幕。用户可以继承LogSink,实现自己的日志打印逻辑。我们默认提供了个LogSink实现:
StringSink
同时继承了LogSink和string,把日志内容存放在string中,主要用于单测,这个case说明了StringSink的典型用法:
TEST_F(StreamingLogTest, log_at) {
::logging::StringSink log_str;
::logging::LogSink* old_sink = ::logging::SetLogSink(&log_str);
LOG_AT(FATAL, “specified_file.cc”, 12345) << “file/line is specified”;
// the file:line part should be using the argument given by us.
ASSERT_NE(std::string::npos, log_str.find(“specified_file.cc:12345”));
// restore the old sink.
::logging::SetLogSink(old_sink);
}









真题解析#中国电子学会#全国青少年软件编程等级考试)





方法在synchronized方法中调用的奥秘)



